pytorch mixtures
1.0.0
وحدة التوصيل والتشغيل لخليط الخبراء والخليط من التعمق في Pytorch. الحل الخاص بك واحد لإدخال طبقات MOE/MOD في شبكات عصبية مخصصة دون عناء!
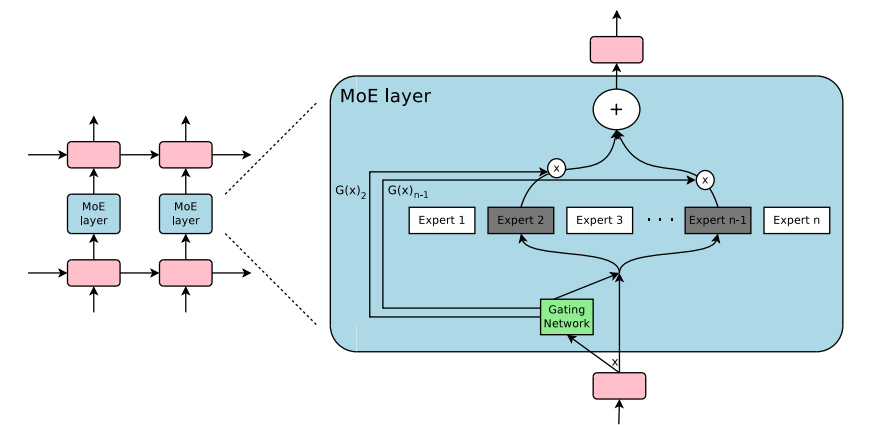 -
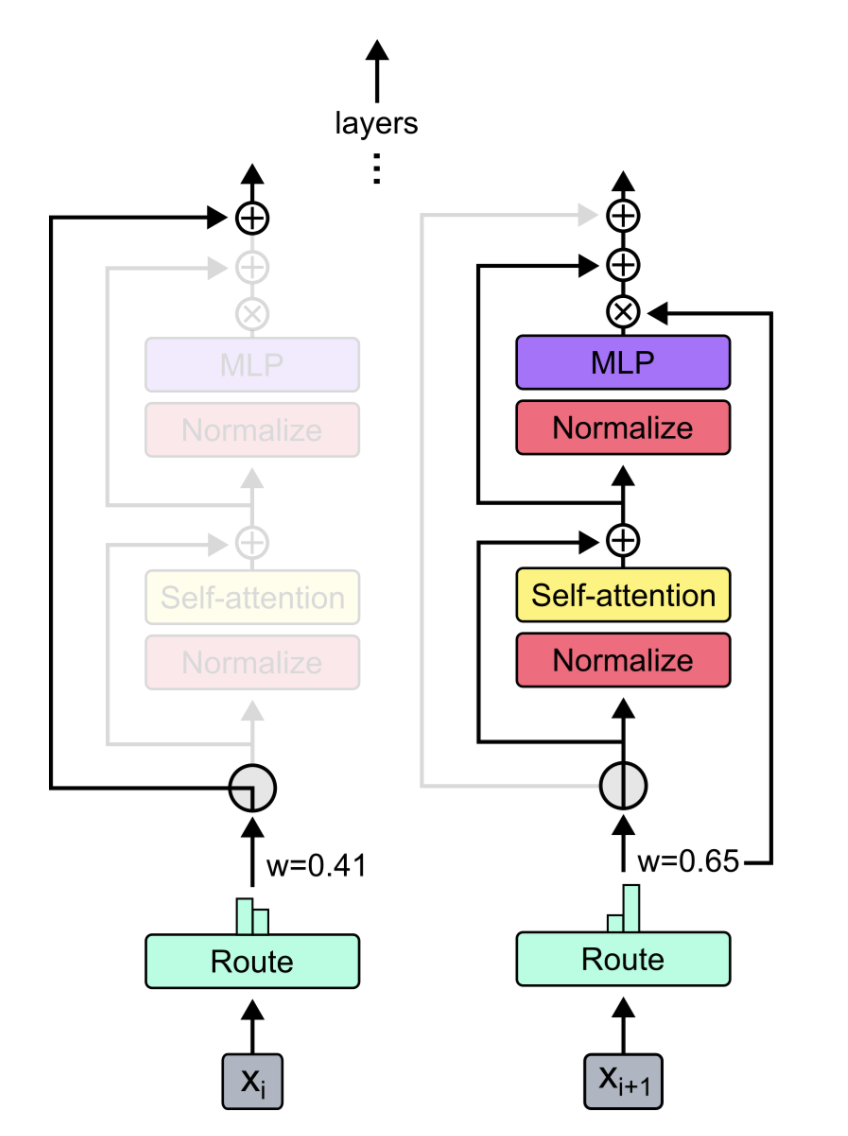
- 
مصادر:
ببساطة استخدام pip3 install pytorch-mixtures سوف يقوم بتثبيت هذه الحزمة. لاحظ أن هذا يتطلب من torch و einops تثبيتها مسبقًا على أنها تبعيات. إذا كنت ترغب في إنشاء هذه الحزمة من المصدر ، قم بتشغيل الأمر التالي:
git clone https://github.com/jaisidhsingh/pytorch-mixtures.git
cd pytorch-mixtures
pip3 install . تم تصميم pytorch-mixtures لتكاملها دون عناء في الكود الحالي لأي شبكة عصبية من اختيارك ، على سبيل المثال
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe_layer import MoELayer
import torch
import torch . nn as nn
# define some config
BATCH_SIZE = 16
SEQ_LEN = 128
DIM = 768
NUM_EXPERTS = 8
CAPACITY_FACTOR = 1.25
# first initialize the router
router = ExpertChoiceRouter ( dim = DIM , num_experts = NUM_EXPERTS )
# choose the experts you want: pytorch-mixtures just needs a list of `nn.Module` experts
# for e.g. our experts are just linear layers
experts = [ nn . Linear ( DIM , DIM ) for _ in range ( NUM_EXPERTS )]
# supply the router and experts to the MoELayer for modularity
moe = MoELayer (
num_experts = NUM_EXPERTS ,
router = router ,
experts = experts ,
capacity_factor = CAPACITY_FACTOR
)
# initialize some test input
x = torch . randn ( BATCH_SIZE , SEQ_LEN , DIM )
# pass through moe
moe_output , aux_loss , router_z_loss = moe ( x ) # shape: [BATCH_SIZE, SEQ_LEN, DIM] يمكنك أيضًا استخدام هذا بسهولة ضمن فصول nn.Module الخاصة بك
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe import MoELayer
from pytorch_mixtures . utils import MHSA # multi-head self-attention layer provided for ease
import torch
import torch . nn as nn
class CustomMoEAttentionBlock ( nn . Module ):
def __init__ ( self , dim , num_heads , num_experts , capacity_factor , experts ):
super (). __init__ ()
self . attn = MHSA ( dim , num_heads )
router = ExpertChoiceRouter ( dim , num_experts )
self . moe = MoELayer ( dim , router , experts , capacity_factor )
self . norm1 = nn . LayerNorm ( dim )
self . norm2 = nn . LayerNorm ( dim )
def forward ( self , x ):
x = self . norm1 ( self . attn ( x ) + x )
moe_output , aux_loss , router_z_loss = self . moe ( x )
x = self . norm2 ( moe_output + x )
return x , aux_loss , router_z_loss
experts = [ nn . Linear ( 768 , 768 ) for _ in range ( 8 )]
my_block = CustomMoEAttentionBlock (
dim = 768 ,
num_heads = 8 ,
num_experts = 8 ,
capacity_factor = 1.25 ,
experts = experts
)
# some test input
x = torch . randn ( 16 , 128 , 768 )
output , aux_loss , router_z_loss = my_block ( x ) # output shape: [16, 128, 768] توفر هذه الحزمة للمستخدم لتشغيل absl test بسيط ولكن موثوق به لرمز MOE. إذا تم تهيئة جميع الخبراء كوحدة نفس الوحدة ، فيجب أن يكون إخراج MoELayer مساويًا لمترات الإدخال التي تم تمريرها عبر أي خبير. يتم اختبار كل من ExpertChoiceRouter و TopkRouter على هذا النحو ، والنجاح في الاختبارات. يمكن للمستخدمين إجراء هذه الاختبارات لأنفسهم عن طريق تشغيل ما يلي:
from pytorch_mixtures import run_tests
run_tests ()ملاحظة: جميع الاختبارات تمر بشكل صحيح. إذا فشل الاختبار ، فمن المحتمل أن يكون ذلك بسبب حالة الحافة في التهيئة العشوائية. حاول مرة أخرى ، وسوف يمر.
إذا وجدت هذه الحزمة مفيدة ، فيرجى الاستشهاد بها في عملك:
@misc { JaisidhSingh2024 ,
author = { Singh, Jaisidh } ,
title = { pytorch-mixtures } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/jaisidhsingh/pytorch-mixtures} } ,
}تم تصميم هذه الحزمة بمساعدة رمز مفتوح المصدر المذكور أدناه:


