Torch Linguist
1.0.0

Этот проект является пошаговым руководством по созданию языковой модели с использованием Pytorch. Он направлен на то, чтобы обеспечить исчерпывающее понимание процесса, связанного с разработкой языковой модели и ее приложений.
Языковое моделирование, или LM, представляет собой использование различных статистических и вероятностных методов для определения вероятности данной последовательности слов, возникающих в предложении. Языковые модели анализируют тела текстовых данных, чтобы обеспечить основу для их прогнозов слова.
Языковое моделирование используется в системах искусственного интеллекта (AI), обработке естественного языка (NLP), естественном языковом понимании (NLU) и системах генерации естественного языка (NLG), особенно тех, которые выполняют генерацию текста, машинный перевод и ответ на вопрос.
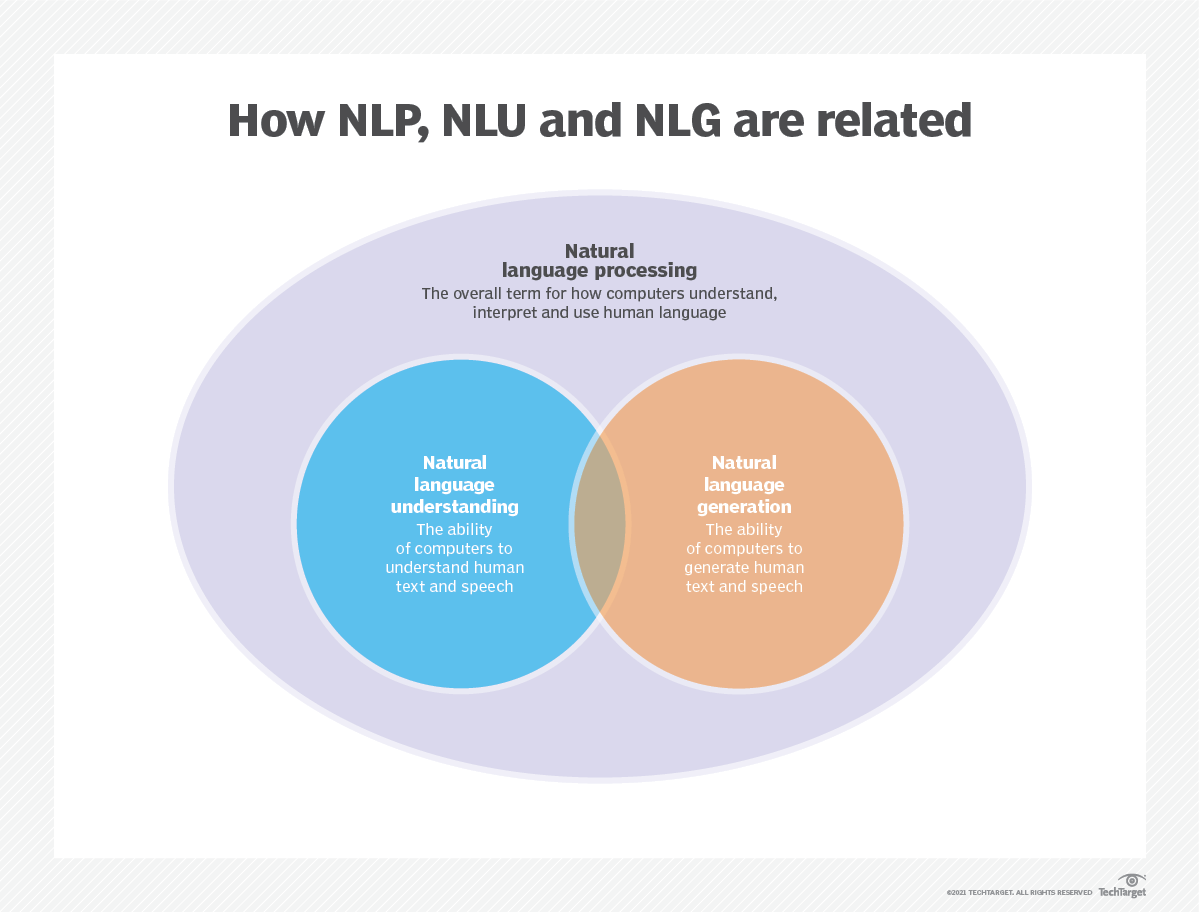
Большие языковые модели (LLMS) также используют языковое моделирование. Это расширенные языковые модели, такие как GPT-3 OpenAI и Palm 2 Google, которые обрабатывают миллиарды параметров учебных данных и генерируют вывод текста.
Эффективность языковой модели обычно оценивается с использованием таких метрик, как перекрестная энтропия и недоумение , которые измеряют способность модели точно прогнозировать следующее слово (я расскажу о них на шаге 2 ). Несколько наборов данных, такие как Wikitext-2, Wikitext-103, один миллиард слов, текст8 и C4, среди прочих, обычно используются для оценки языковых моделей. Примечание . В этом проекте я использую Wikitext-2.
Исследование LM получило обширное внимание в литературе, которое можно разделить на четыре основных этапа развития:
SLM разрабатываются на основе статистических методов обучения, которые выросли в 1990 -х годах. Основная идея состоит в том, чтобы построить модель прогнозирования слов, основанную на предположении Маркова , например, прогнозирование следующего слова, основанного на самом последнем контексте. SLMS с фиксированной длиной контекста N также называются моделями N-грамма языка , например, моделей Bigram и Trigram. SLM широко применялись для повышения производительности задач при поиске информации (IR) и обработке естественного языка (NLP). Однако они часто страдают от проклятия размерности:
Трудно точно оценить языковые модели высокого порядка, поскольку необходимо оценить экспоненциальное количество вероятностей перехода. Таким образом, были введены специально разработанные стратегии сглаживания, такие как оценка отступления и оценка хороших результатов, чтобы облегчить проблему разреженности данных.
NLMS характеризует вероятность последовательностей слов с помощью нейронных сетей, например, многослойного персептрона (MLP) и повторяющихся нейронных сетей (RNN). В качестве замечательного вклада является концепция распределенного представления . Распределенные представления, также известные как встраиваемые , идея заключается в том, что «значение» или «семантическое содержание» точки данных распределяется по нескольким измерениям. Например, в NLP слова с аналогичными значениями отображаются с точками в векторном пространстве, которые близки друг к другу. Эта близость не является произвольной, но извлечена из контекста, в котором появляются слова. Это зависимое от контекста обучение часто достигается с помощью моделей нейронной сети, таких как Word2VEC или Glove , которые обрабатывают большие корпусы текста для изучения этих представлений.
Одним из ключевых преимуществ распределенных представлений является их способность захватывать мелкозернистые семантические отношения. Например, в хорошо обученном пространстве встраивания слов синонимы будут представлены векторами, которые находятся близко друг к другу, и даже можно выполнить арифметические операции с этими векторами, которые соответствуют значимым семантическим операциям (например, «Король» - «Человек» + «Женщина» может привести к вектору близко к «королеве»).
Приложения распределенных представлений:
Распределенные представления имеют широкий спектр приложений, особенно в задачах, которые включают понимание естественного языка. Они используются для:
Сходство слова : измерение семантического сходства между словами.
Текстовая классификация : категоризация документов на предопределенные классы.
Машинный перевод : перевод текста с одного языка на другой.
Поиск информации : поиск соответствующих документов в ответ на запрос.
Анализ настроений : определение чувства, выраженного в кусочке текста.
Кроме того, распределенные представления не ограничиваются текстовыми данными. Они также могут быть применены к другим типам данных, таким как изображения, где модели глубокого обучения учатся представлять изображения в качестве высокоразмерных векторов, которые отражают визуальные особенности и семантику.
Модели причинного языка, также известные как авторегрессивные модели , генерируют текст, предсказав следующее слово в последовательности, учитывая предыдущие слова. Эти модели обучены максимизировать вероятность следующего слова, используя такие методы, как архитектура трансформатора. Во время обучения ввод в модель - это целая последовательность до заданного токена, и цель модели - предсказать следующий токен. Этот тип модели полезен для таких задач, как генерация текста , завершение и суммирование .
Модели в масках (MLMS) предназначены для изучения контекстных представлений слов путем прогнозирования маскированных или отсутствующих слов в предложении. Во время тренировки часть входной последовательности случайным образом маскируется, и модель обучена прогнозировать исходные слова, учитывая контекст. MLM используют двунаправленные архитектуры, такие как трансформаторы, чтобы захватить зависимости между словами в масках и остальной частью предложения. Эти модели преуспевают в таких задачах, как классификация текста , признание объектов и ответ на вопросы .
Модели последовательности к последовательности (SEQ2SEQ) обучаются отображать входную последовательность в выходной последовательности. Они состоят из кодера , который обрабатывает входную последовательность и декодер , который генерирует выходную последовательность. Модели SEQ2SEQ широко используются в таких задачах, как машинный перевод , текстовое обобщение и системы диалога . Их можно обучать, используя такие методы, как рецидивирующие нейронные сети (RNN) или трансформаторы. Цель обучения состоит в том, чтобы максимизировать вероятность генерации правильной выходной последовательности с учетом ввода.
Важно отметить, что эти подходы к обучению не являются взаимоисключающими , и исследователи часто объединяют их или используют вариации для достижения конкретных целей. Например, такие модели, как T5, сочетают в себе целей обучения авторегрессии и маскированной модели языка, чтобы изучить разнообразные задачи.
Каждый подход к обучению имеет свои сильные и слабые стороны, а выбор модели зависит от конкретных требований задачи и доступных данных обучения.
Для получения дополнительной информации, пожалуйста, обратитесь к главе «Руководство по подходам к обучению языковой модели» на веб -сайте Medium.com.
Языковое моделирование включает в себя создание моделей, которые могут генерировать или предсказать последовательности слов или символов. Вот несколько различных типов моделей, обычно используемых для языкового моделирования:
В модели N-граммы вероятность слова оценивается на основе его возникновения в учебных данных относительно его предыдущих слов N-1. Например, в модели триграммы (n = 3) вероятность слова определяется двумя словами, которые немедленно предшествуют ее. Этот подход предполагает, что вероятность слова зависит только от фиксированного числа предыдущих слов и не учитывает зависимости дальнего действия.
Вот несколько примеров N-граммов:
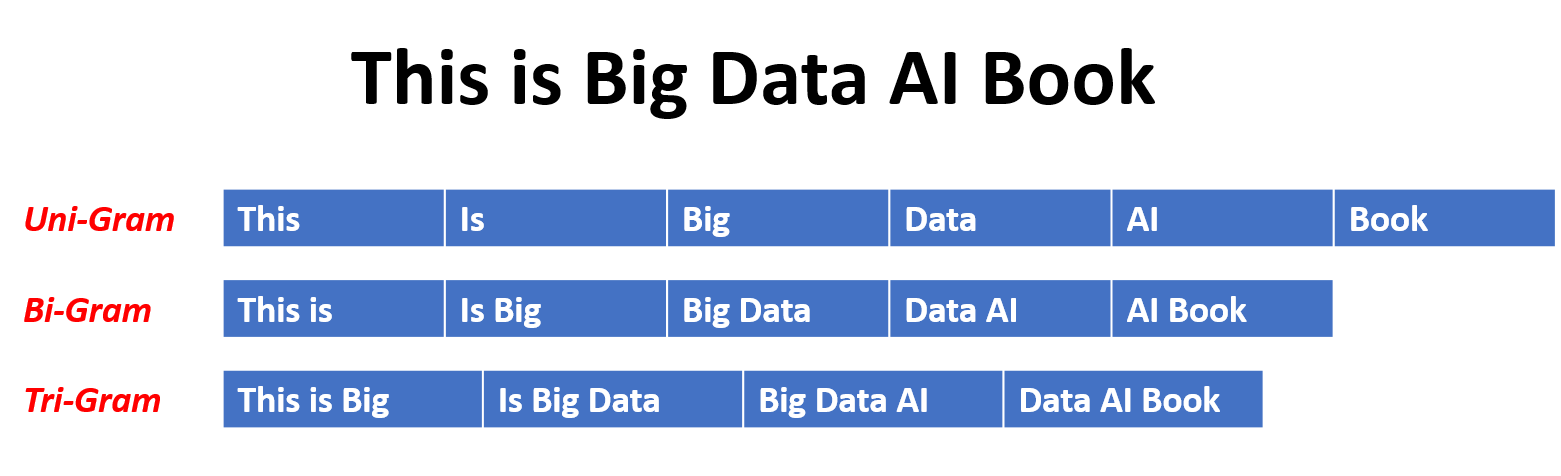
Вот преимущества и недостатки моделей N-грамм языка:
Преимущества :
Недостатки :
Вот пример использования N-граммов в Torchext:
import torchtext
from torchtext . data import get_tokenizer
from torchtext . data . utils import ngrams_iterator
tokenizer = get_tokenizer ( "basic_english" )
# Create a tokenizer object using the "basic_english" tokenizer provided by torchtext
# This tokenizer splits the input text into a list of tokens
tokens = tokenizer ( "I love to code in Python" )
# The result is a list of tokens, where each token represents a word or a punctuation mark
print ( list ( ngrams_iterator ( tokens , 3 )))
[ 'i' , 'love' , 'to' , 'code' , 'in' , 'python' , 'i love' , 'love to' , 'to code' , 'code in' , 'in python' , 'i love to' , 'love to code' , 'to code in' , 'code in python' ]Примечание :
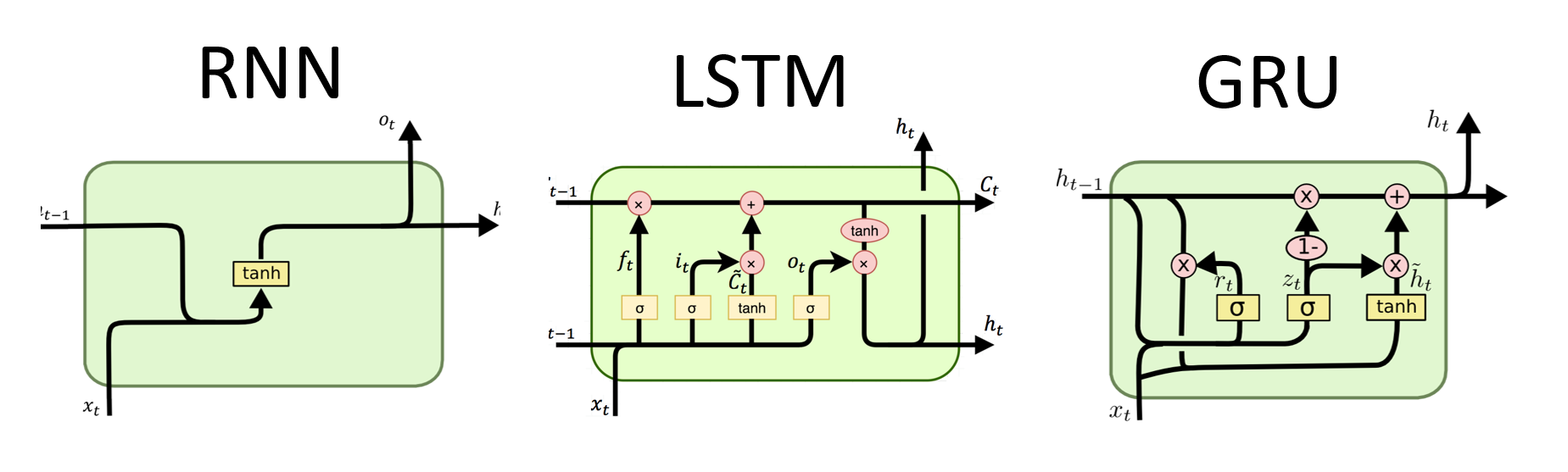
RNN являются фундаментальным типом нейронной сети для последовательной обработки данных. У них есть повторяющиеся соединения, которые позволяют передавать информацию от одного шага к следующему, что позволяет им захватывать зависимости во времени. Тем не менее, традиционные RNN страдают от проблемы исчезновения/взрыва градиента и борьбы с долгосрочными зависимостями.
Преимущества RNNS :
Недостатки RNNS :
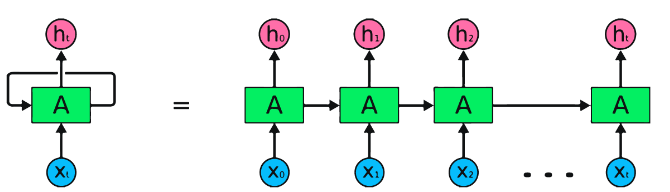
Фрагмент кода Pytorch для определения базового RNN в Pytorch:
import torch
import torch . nn as nn
rnn = nn . RNN ( input_size = 10 , hidden_size = 20 , num_layers = 2 )
# input_size – The number of expected features in the input x
# hidden_size – The number of features in the hidden state h
# num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together
# Create a randomly initialized input tensor
input = torch . randn ( 5 , 3 , 10 ) # (sequence length=5, batch size=3, input size=10)
# Create a randomly initialized hidden state tensor
h0 = torch . randn ( 2 , 3 , 20 ) # (num_layers=2, batch size=3, hidden size=20)
# Apply the RNN module to the input tensor and initial hidden state tensor
output , hn = rnn ( input , h0 )
print ( output . shape ) # torch.Size([5, 3, 20])
# (sequence length=5, batch size=3, hidden size=20)
print ( hn . shape ) # torch.Size([2, 3, 20])
# (num_layers=2, batch size=3, hidden size=20)Преимущества LSTM :
Недостатки LSTM :
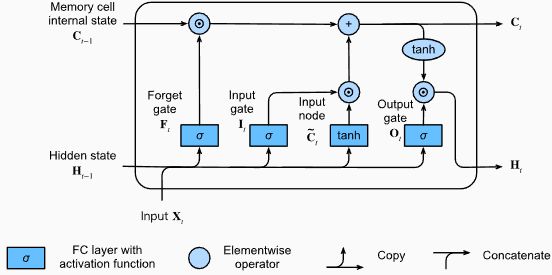
Спрыги для кода Pytorch для определения основного LSTM в Pytorch:
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
lstm = nn . LSTM ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
c0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , ( hn , cn ) = lstm ( input_data , ( h0 , c0 )) Выходная форма слоя LSTM также будет [seq_length, batch_size, hidden_size] . Это означает, что для каждого ввода в последовательности будет соответствующее скрытое выходное состояние. В приведенном примере выходной форме является torch.Size([10, 1, 64]) , указывая на то, что LSTM применяется к последовательности длины 10, с размером партии 1 и скрытым размером состояния 64.
Теперь давайте обсудим тензор hn (скрытое состояние). Его форма - torch.Size([2, 1, 64]) . Первое измерение, 2, представляет количество слоев в LSTM. В этом случае аргумент num_layers был установлен на 2, поэтому в модели LSTM есть 2 слоя. Второе измерение, 1, соответствует размеру партии, который составляет 1 в данном примере. Наконец, последнее измерение, 64 года, представляет размер скрытого состояния.
Следовательно, тензор hn содержит окончательное скрытое состояние для каждого уровня LSTM после обработки всей входной последовательности, следуя способности LSTM сохранять долгосрочные зависимости и смягчить проблему градиента исчезновения.
Для получения дополнительной информации, пожалуйста, обратитесь к главе длинной кратковременной памяти (LSTM) в документации «Погружение в глубокое обучение».
Преимущества Grus :
Недостатки Груса :
В целом, модели LSTM и GRU преодолевают некоторые ограничения традиционных RNN, особенно при захвате долгосрочных зависимостей. LSTM преуспевают в сохранении контекстной информации, в то время как Grus предлагает более эффективную вычислительную альтернативу. Выбор между LSTM и GRU зависит от конкретных требований задачи и доступных вычислительных ресурсов.
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
gru = nn . GRU ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , hn = gru ( input_data , h0 ) Выходная форма слоя GRU также будет [seq_length, batch_size, hidden_size] . Это означает, что для каждого ввода в последовательности будет соответствующее скрытое выходное состояние. В приведенном примере выходной форме является torch.Size([10, 1, 64]) , что указывает на то, что GRU был применен к последовательности длины 10, с размером партии 1 и скрытым размером состояния 64.
Теперь давайте обсудим тензор hn (скрытое состояние). Его форма - torch.Size([2, 1, 64]) . Первое измерение, 2, представляет количество слоев в GRU. В этом случае аргумент num_layers был установлен на 2, поэтому в модели GRU есть 2 слоя. Второе измерение, 1, соответствует размеру партии, который составляет 1 в данном примере. Наконец, последнее измерение, 64 года, представляет размер скрытого состояния.
Следовательно, тензор hn содержит окончательное скрытое состояние для каждого слоя GRU после обработки всей входной последовательности, следуя способности GRU охватить и сохранять информацию в длинных последовательностях, смягчая задачу исчезающего градиента.
Для получения дополнительной информации, пожалуйста, обратитесь к главе зарегистрированных единиц (GRU) в документации «Погружение в глубокое обучение».
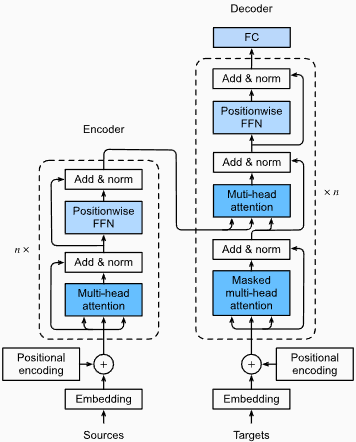
Преимущества :
Захват долгосрочных зависимостей: трансформаторы преуспевают при захвате зависимостей дальнего действия в последовательностях с использованием механизмов самосознания. Это позволяет им учитывать все позиции в входной последовательности при создании прогнозов, что позволяет лучше понять контекст и улучшать качество генерируемого текста.
Параллельная обработка: в отличие от повторяющихся моделей, трансформаторы могут обрабатывать входную последовательность параллельно, делая их высокоэффективными и сокращающими время обучения и вывода. Эта параллелизация возможна из -за отсутствия последовательных зависимостей в архитектуре.
Масштабируемость: трансформаторы очень масштабируются и могут эффективно обрабатывать большие входные последовательности. Они могут обрабатывать последовательности произвольной длины без необходимости усечения или прокладки, что особенно выгодно для задач, связанных с длинными документами или предложениями.
Контекстуальное понимание: трансформаторы могут получать богатую контекстную информацию, посещая соответствующие части входной последовательности. Это позволяет им понимать сложные лингвистические структуры, семантические отношения и зависимости между словами, что приводит к более согласованному и контекстуально подходящему генерации языка.
Недостатки моделей трансформаторов :
Высокие вычислительные требования: трансформаторы обычно требуют значительных вычислительных ресурсов по сравнению с более простыми моделями, такими как N-граммы или традиционные RNN. Обучение больших моделей трансформаторов с обширными наборами данных может быть вычислительно дорогим и трудоемким.
Отсутствие последовательного моделирования: в то время как трансформаторы преуспевают при захвате глобальных зависимостей, они могут быть не так эффективны при моделировании строго последовательных данных. В тех случаях, когда порядок входной последовательности имеет решающее значение, например, в задачах, включающих данные временных рядов, традиционные RNN или сверточные нейронные сети (CNN) могут быть более подходящими.
Сложность механизма внимания: механизм самоуправления в трансформаторах вносит дополнительную сложность в модельную архитектуру. Правильное понимание и реализацию механизмов внимания может быть сложным, а настройка гиперпараметров, связанных с вниманием, может быть нетривиальной.
Требования к данным: трансформаторы часто требуют больших объемов обучающих данных для достижения оптимальной производительности. Предварительная подготовка к крупномасштабным корпусам, например, в случае предварительных трансформаторных моделей, таких как GPT и BERT, является обычной для эффективного использования силы трансформаторов.
Для получения дополнительной информации, пожалуйста, обратитесь к главе архитектуры трансформатора в документации «Погружение в глубокое обучение».
Несмотря на эти ограничения, модели трансформаторов произвели революцию в области обработки естественного языка и языкового моделирования. Их способность улавливать долгосрочные зависимости и контекстуальное понимание значительно продвинула состояние искусства в различных языковых задачах, что делает их выдающимся выбором для многих приложений.
Смущение, в контексте языкового моделирования, является мерой, которая количественно определяет, насколько хорошо языковая модель предсказывает заданный тестовый набор, с более низкой недоумением, что указывает на лучшую прогнозирующую производительность. Проще говоря, недоумение рассчитывается путем принятия обратной вероятности испытательного набора, а затем нормализации его по количеству слов.
Чем ниже ценность недоумения, тем лучше языковая модель прогнозирует тестовый набор. Минимизация недоумения - это то же самое, что максимизация вероятности
Формула для недоумения как обратная вероятность испытательного набора, нормализованная по количеству слов, заключается в следующем:
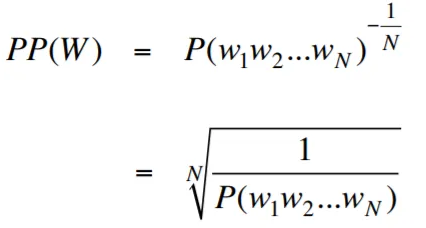

Смущение можно интерпретировать как меру ветвления в языковой модели. Коэффициент ветвления представляет среднее количество возможных следующих слов или токенов, которые дают конкретный контекст или последовательность слов.
Фактор ветвления языка - это количество возможных следующих слов, которые могут следовать любому слову. Мы можем думать о недоумении как об взвешенном факторе ветвления языка.
Языковое моделирование с помощью встроенного уровня и кода LSTM является мощным инструментом для создания и обучения. Эта реализация кода объединяет два фундаментальных компонента в обработке естественного языка: встраивающий уровень и сеть длинной кратковременной памяти (LSTM) .
Встроенный уровень отвечает за преобразование текстовых данных в распределенные представления, также известные как вставки Word . Эти встраиваемые встроены семантические и синтаксические свойства слов, позволяя модели понять значение и контекст входного текста. Встроенный слой отображает каждое слово в входную последовательность на высокомерный вектор, который служит входным вводом для последующих слоев в модели.
Уровень LSTM в реализации кода обрабатывает слово встроения, сгенерированное слоем встраивания, захватывая информацию о последовательности и изучая базовые шаблоны и структуры в тексте.
Объединив встроенный уровень и сеть LSTM, код позволяет создавать языковую модель, которая может генерировать когерентный и контекстуально подходящий текст. Языковые модели, созданные с использованием этого подхода, могут быть обучены крупным текстовым наборам данных и способны создавать реалистичные и значимые предложения, что делает их ценными инструментами для различных задач обработки естественного языка, таких как генерация текста, машинный перевод и анализ настроений.
Эта реализация кода предоставляет простую, четкую и краткую основу для создания языковых моделей на основе встроенного уровня и архитектуры LSTM. Он служит отправной точкой для исследователей, разработчиков и энтузиастов, которые заинтересованы в изучении и экспериментах с современными методами моделирования языка.
Благодаря этому коду вы можете получить более глубокое понимание того, как встраиваемые слои и LSTM работают вместе, чтобы захватить сложные закономерности и зависимости в текстовых данных. С помощью этих знаний вы можете дополнительно расширить код и изучить передовые методы, такие как включение механизмов внимания или архитектуры трансформатора, для повышения производительности и возможностей ваших языковых моделей.
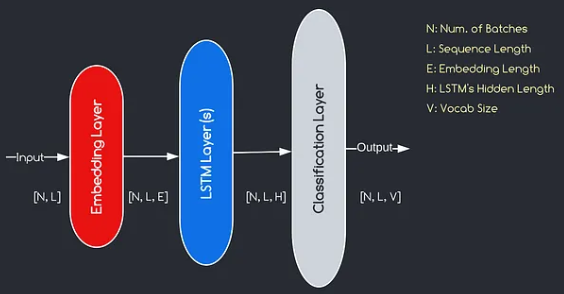
Модель, которую мы будем построить, соответствует приведенной выше диаграмме, иллюстрируя три ключевых компонента: встроенный слой, слои LSTM и классификационный слой. Хотя цели слоев LSTM и классификации уже знакомы нам, давайте углубимся в значимость встроенного слоя.
Встроенный слой играет решающую роль в модели, преобразуя каждое слово, представленное как индекс, в вектор измерений . Это векторное представление позволяет последующим слоям изучать и извлекать значимую информацию из ввода. Стоит отметить, что использование индексов или одножелательных векторов для представления слов может быть неадекватным, поскольку они не предполагают никаких отношений между разными словами.
Процесс картирования, проведенный слоем встраивания, представляет собой изученную процедуру, которая происходит во время обучения. На этом этапе обучения модель получает способность связывать слова с конкретными векторами таким образом, чтобы улавливать семантические и синтаксические отношения, тем самым улучшая понимание модели основной языковой структуры.
Набор данных WKITEXT-103, разработанный Salesforce, содержит более 100 миллионов токенов, извлеченных из набора проверенных хороших и представленных статей о Википедии. Он имеет 267 340 уникальных токенов, которые появляются по крайней мере 3 раза в наборе данных. Поскольку в нем есть полнометражные статьи в Википедии, набор данных хорошо подходит для задач, которые могут извлечь выгоду из долгосрочных зависимостей, таких как языковое моделирование.
Набор данных Wikitext-2 представляет собой небольшую версию набора данных Wikitext-103, поскольку он содержит только 2 миллиона токенов. Этот небольшой набор данных подходит для тестирования вашей языковой модели.

Этот репозиторий содержит код для проведения исследовательского анализа данных в наборе данных UTK, который состоит из изображений, классифицированных по возрасту, полу и этнической принадлежности.
Чтобы загрузить набор данных с использованием Torchtext, вы можете использовать модуль torchtext.datasets . Вот пример того, как загрузить набор данных Wikitext-2, используя Torchtext:
import torchtext
from torchtext . datasets import WikiText2
data_path = "data"
train_iter , valid_iter , test_iter = WikiText2 ( root = data_path ) Первоначально я пытался использовать предоставленный код для загрузки набора данных Wikitext-2, но столкнулся с проблемой с URL (https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2v1.zip) не работает для меня. Чтобы преодолеть это, я решил использовать библиотеку torchtext и создать пользовательскую реализацию загрузчика набора данных.
Поскольку оригинальный URL не работал, я загрузил наборы данных поезда, проверки и тестирования из репозитория GitHub и поместил их в каталог 'data/datasets/WikiText2' .
Вот разбивка кода:
import os
from typing import Union , Tuple
from torchdata . datapipes . iter import FileOpener , IterableWrapper
from torchtext . data . datasets_utils import _wrap_split_argument , _create_dataset_directory
DATA_DIR = "data"
NUM_LINES = {
"train" : 36718 ,
"valid" : 3760 ,
"test" : 4358 ,
}
DATASET_NAME = "WikiText2"
_EXTRACTED_FILES = {
"train" : "wiki.train.tokens" ,
"test" : "wiki.test.tokens" ,
"valid" : "wiki.valid.tokens" ,
}
def _filepath_fn ( root , split ):
return os . path . join ( root , _EXTRACTED_FILES [ split ])
@ _create_dataset_directory ( dataset_name = DATASET_NAME )
@ _wrap_split_argument (( "train" , "valid" , "test" ))
def WikiText2 ( root : str , split : Union [ Tuple [ str ], str ]):
url_dp = IterableWrapper ([ _filepath_fn ( DATA_DIR , split )])
data_dp = FileOpener ( url_dp , encoding = "utf-8" ). readlines ( strip_newline = False , return_path = False ). shuffle (). set_shuffle ( False ). sharding_filter ()
return data_dp Чтобы использовать загрузчик набора данных Wikitext-2, просто импортируйте функцию wikitext2 и вызовите ее с помощью желаемого разделения данных:
train_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "train" )
valid_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "valid" )
test_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "test" )Эта реализация вдохновлена официальными погрузчиками набора данных TorchText и использует библиотеки TorchData и TorchText для предоставления бесшовного и эффективного опыта загрузки данных.
Создание словарного запаса является важным шагом во многих задачах обработки естественного языка, поскольку он позволяет вам представлять слова как уникальные идентификаторы, которые можно использовать в моделях машинного обучения. Этот документ Markdown демонстрирует, как создать словарный запас из набора учебных данных и сохранить его для будущего использования.
Вот функция, которая инкапсулирует процесс построения и сохранения словаря:
import torch
from torchtext . data . utils import get_tokenizer
from torchtext . vocab import build_vocab_from_iterator
def build_and_save_vocabulary ( train_iter , vocab_path = 'vocab.pt' , min_freq = 4 ):
"""
Build a vocabulary from the training data iterator and save it to a file.
Args:
train_iter (iterator): An iterator over the training data.
vocab_path (str, optional): The path to save the vocabulary file. Defaults to 'vocab.pt'.
min_freq (int, optional): The minimum frequency of a word to be included in the vocabulary. Defaults to 4.
Returns:
torchtext.vocab.Vocab: The built vocabulary.
"""
# Get the tokenizer
tokenizer = get_tokenizer ( "basic_english" )
# Build the vocabulary
vocab = build_vocab_from_iterator ( map ( tokenizer , train_iter ), specials = [ '<unk>' ], min_freq = min_freq )
# Set the default index to the unknown token
vocab . set_default_index ( vocab [ '<unk>' ])
# Save the vocabulary
torch . save ( vocab , vocab_path )
return vocabВот как вы можете использовать эту функцию:
# Assuming you have a training data iterator named `train_iter`
vocab = build_and_save_vocabulary ( train_iter , vocab_path = 'my_vocab.pt' )
# You can now use the vocabulary
print ( len ( vocab )) # 23652
print ( vocab ([ 'ebi' , 'AI' . lower (), 'qwerty' ])) # [0, 1973, 0] build_and_save_vocabulary принимает три аргумента: train_iter (итератор по данным обучения), vocab_path (путь к сохранению словарного файла, с дефолтом «Vocab.pt ') и min_freq (минимальная частота слова, которая должна быть включена в Vocabulary, с защитой 4).basic_english , который выполняет базовую токенизацию на английском тексту.build_vocab_from_iterator , передавая итератор обучающих данных (после токенизации) и указав специальный токен '<unk>' и минимальный порог частоты.'<unk>' , что означает, что любое слово, не найденное в словаре, будет сопоставлено с неизвестным токеном. Чтобы использовать эту функцию, вам нужен итератор обучающих данных с именем train_iter . Затем вы можете вызвать функцию build_and_save_vocabulary , передавая train_iter и указав желаемый путь словарного файла и минимальный порог частоты.
Функция будет создавать словарный запас, сохранить его в указанный файл и вернет объект Vocab , который затем вы можете использовать в своих задачах вниз по течению.
Этот код предоставляет способ проанализировать среднюю длину предложения в наборе данных Wikitext-2. Вот разбивка кода:
import matplotlib . pyplot as plt
def compute_mean_sentence_length ( data_iter ):
"""
Computes the mean sentence length for the given data iterator.
Args:
data_iter (iterable): An iterable of text data, where each element is a string representing a line of text.
Returns:
float: The mean sentence length.
"""
total_sentence_count = 0
total_sentence_length = 0
for line in data_iter :
sentences = line . split ( '.' ) # Split the line into individual sentences
for sentence in sentences :
tokens = sentence . strip (). split () # Tokenize the sentence
sentence_length = len ( tokens )
if sentence_length > 0 :
total_sentence_count += 1
total_sentence_length += sentence_length
mean_sentence_length = total_sentence_length / total_sentence_count
return mean_sentence_length
# Compute mean sentence length for each dataset
train_mean = compute_mean_sentence_length ( train_iter )
valid_mean = compute_mean_sentence_length ( valid_iter )
test_mean = compute_mean_sentence_length ( test_iter )
# Plot the results
datasets = [ 'Train' , 'Valid' , 'Test' ]
means = [ train_mean , valid_mean , test_mean ]
plt . figure ( figsize = ( 6 , 4 ))
plt . bar ( datasets , means )
plt . xlabel ( 'Dataset' )
plt . ylabel ( 'Mean Sentence Length' )
plt . title ( 'Mean Sentence Length in Wikitext-2' )
plt . grid ( True )
plt . show ()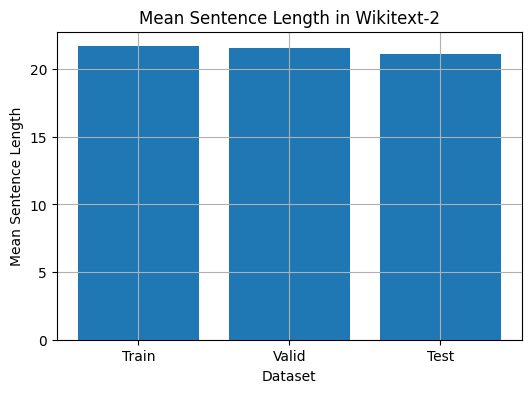
from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Find the 10 least common words
least_common_words = freqs . most_common ()[: - 11 : - 1 ]
print ( "Least Common Words:" )
for word , count in least_common_words :
print ( f" { word } : { count } " )
# Find the 10 most common words
most_common_words = freqs . most_common ( 10 )
print ( " n Most Common Words:" )
for word , count in most_common_words :
print ( f" { word } : { count } " ) from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Count the number of words that repeat 3, 4, and 5 times
count_3 = count_4 = count_5 = 0
for word , freq in freqs . items ():
if freq == 3 :
count_3 += 1
elif freq == 4 :
count_4 += 1
elif freq == 5 :
count_5 += 1
print ( f"Number of words that appear 3 times: { count_3 } " ) # 5130
print ( f"Number of words that appear 4 times: { count_4 } " ) # 3243
print ( f"Number of words that appear 5 times: { count_5 } " ) # 2261 from collections import Counter
import matplotlib . pyplot as plt
# Compute the word lengths in the training dataset
word_lengths = []
for tokens in map ( tokenizer , train_iter ):
word_lengths . extend ( len ( word ) for word in tokens )
# Create a frequency distribution of word lengths
word_length_counts = Counter ( word_lengths )
# Plot the word length distribution
plt . figure ( figsize = ( 10 , 6 ))
plt . bar ( word_length_counts . keys (), word_length_counts . values ())
plt . xlabel ( "Word Length" )
plt . ylabel ( "Frequency" )
plt . title ( "Word Length Distribution in Wikitext-2 Dataset" )
plt . show ()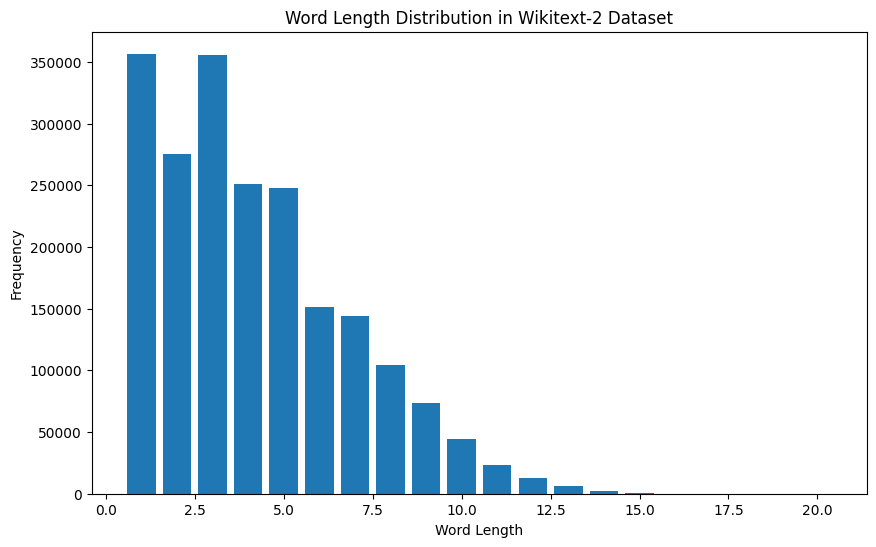
import spacy
import en_core_web_sm
# Load the small English language model from SpaCy
nlp = spacy . load ( "en_core_web_sm" )
# Alternatively, you can use the en_core_web_sm module to load the model
nlp = en_core_web_sm . load ()
# Process the given sentence using the loaded language model
doc = nlp ( "This is a sentence." )
# Print the text and part-of-speech tag for each token in the sentence
print ([( w . text , w . pos_ ) for w in doc ])
# [('This', 'PRON'), ('is', 'AUX'), ('a', 'DET'), ('sentence', 'NOUN'), ('.', 'PUNCT')]Для набора данных Wikitext-2:
import spacy
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform POS tagging on the training dataset
pos_tags = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
pos_tags . extend ([( token . text , token . pos_ ) for token in doc ])
# Count the frequency of each POS tag
pos_tag_counts = Counter ( tag for _ , tag in pos_tags )
# Print the most common POS tags
print ( "Most Common Part-of-Speech Tags:" )
for tag , count in pos_tag_counts . most_common ( 10 ):
print ( f" { tag } : { count } " )
# Visualize the POS tag distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( pos_tag_counts . keys (), pos_tag_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Part-of-Speech Tag" )
plt . ylabel ( "Frequency" )
plt . title ( "Part-of-Speech Tag Distribution in Wikitext-2 Dataset" )
plt . show ()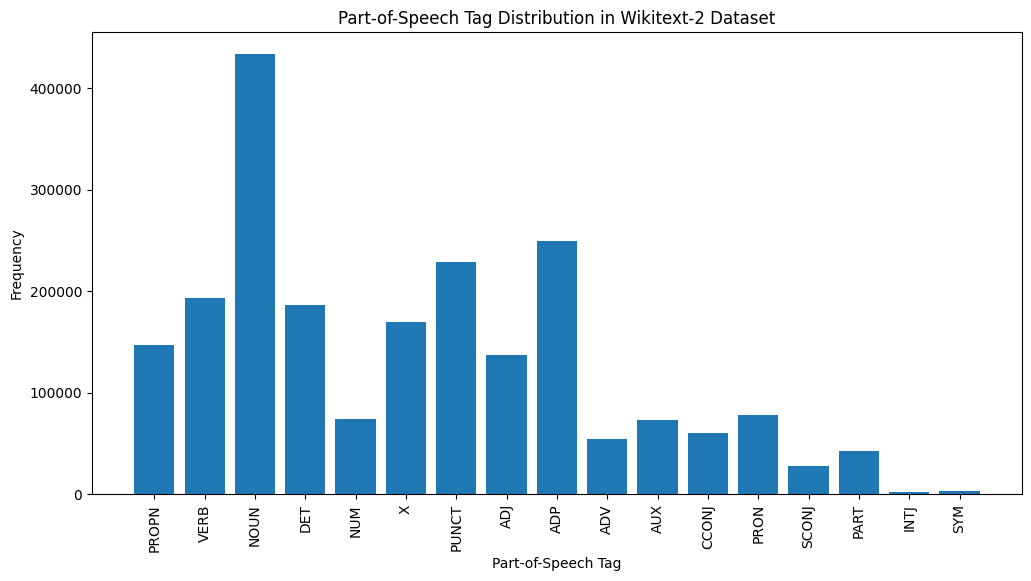
Вот краткое объяснение наиболее распространенных метров POS в предоставленном выходе:
Существительное : существительные представляют людей, места, вещи или идеи.
ADP : Адпозиции, такие как предлоги и постпозиции, используются для выражения отношений между словами или фразами.
Пункт : знаки препинания, которые необходимы для разделения и структурирования предложений и текста.
Глагол : глаголы описывают действия, состояния или происшествия в тексте.
DET : Детерминаторы, такие как статьи (например, «The» «A», «AN»), предоставляют дополнительную информацию о существительных.
X : Этот тег часто используется для иностранных слов, сокращений или других специфичных для языка токенов, которые не вписываются в стандартные категории POS.
Propn : Правильные существительные, которые представляют конкретные имена людей, мест, организаций или других сущностей.
Прил : прилагательные изменяют или описывают существительные и местоимения.
Прон : местоимения заменяют существительные, что делает текст более кратким и менее повторяющимся.
Num : цифры, которые представляют величины, даты или другую численную информацию.
Это распределение POS -тегов может дать представление о лингвистических характеристиках текста, таких как преобладание существительных, распространенность адпозиции или использование правильных существительных, которые могут быть полезны в таких задачах, как классификация текста, извлечение информации или стилометрический анализ.
import spacy
import matplotlib . pyplot as plt
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform NER on the training dataset
named_entities = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
named_entities . extend ([( ent . text , ent . label_ ) for ent in doc . ents ])
# Count the frequency of each named entity type
ner_counts = Counter ( label for _ , label in named_entities )
# Print the most common named entity types
print ( "Most Common Named Entity Types:" )
for label , count in ner_counts . most_common ( 10 ):
print ( f" { label } : { count } " )
# Visualize the named entity distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( ner_counts . keys (), ner_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Named Entity Type" )
plt . ylabel ( "Frequency" )
plt . title ( "Named Entity Distribution in Wikitext-2 Dataset" )
plt . show ()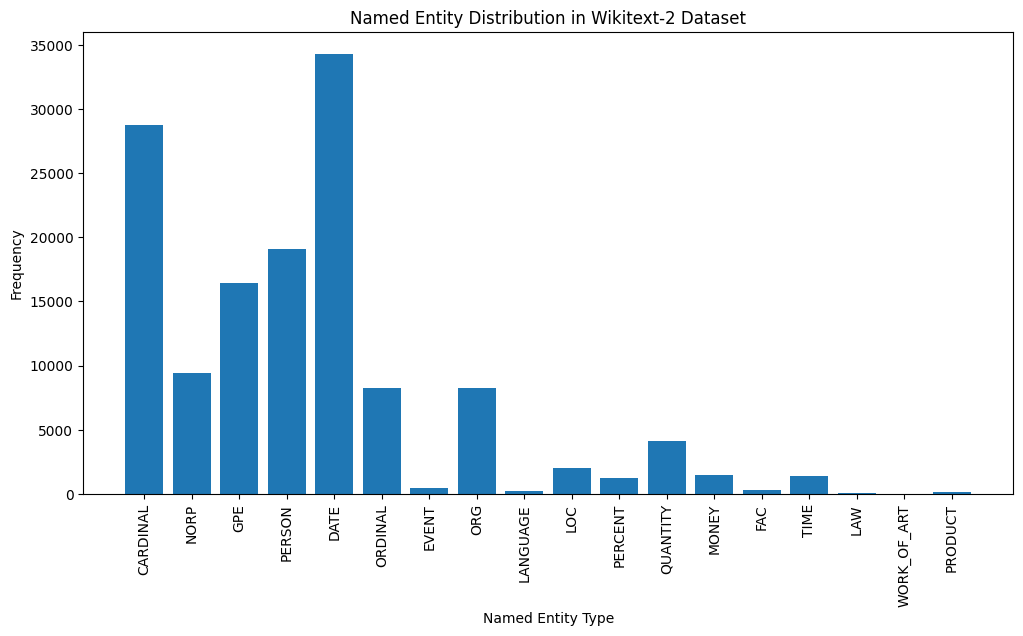
Here's a brief explanation of the most common named entity types in the output:
DATE : Represents specific dates, time periods, or temporal expressions, such as "June 15, 2024" or "last year".
CARDINAL : Includes numerical values, such as quantities, ages, or measurements.
PERSON : Identifies the names of individual people.
GPE (Geopolitical Entity): This entity type represents named geographical locations, such as countries, cities, or states.
NORP (Nationalities, Religious, or Political Groups): This entity type includes named groups or affiliations based on nationality, religion, or political ideology.
ORDINAL : Represents ordinal numbers, such as "first," "second," or "3rd".
ORG (Organization): The names of companies, institutions, or other organized groups.
QUANTITY : Includes non-numeric quantities, such as "a few" or "several".
LOC (Location): Represents named geographical locations, such as continents, regions, or landforms.
MONEY : Identifies monetary values, such as dollar amounts or currency names.
This distribution of named entity types can provide valuable insights into the content and focus of the text. For example, the prominence of DATE and CARDINAL entities may suggest a text that deals with numerical or temporal information, while the prevalence of PERSON, ORG, and GPE entities could indicate a text that discusses people, organizations, and geographical locations.
Understanding the named entity distribution can be useful in a variety of applications, such as information extraction, question answering, and text summarization, where identifying and categorizing key named entities is crucial for understanding the context and content of the text.
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the training dataset
with open ( "data/wiki.train.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Create a string from the entire training dataset
text = " " . join ( train_text )
# Generate the word cloud
wordcloud = WordCloud ( width = 800 , height = 400 , background_color = 'white' ). generate ( text )
# Plot the word cloud
plt . figure ( figsize = ( 12 , 8 ))
plt . imshow ( wordcloud , interpolation = 'bilinear' )
plt . axis ( 'off' )
plt . title ( 'Word Cloud for Wikitext-2 Training Dataset' )
plt . show ()
from sentence_transformers import SentenceTransformer
from sklearn . cluster import KMeans
from collections import defaultdict
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the BERT-based sentence transformer model
model = SentenceTransformer ( 'bert-base-nli-mean-tokens' )
# Load the training dataset
with open ( "data/wiki.valid.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Compute the BERT embeddings for each unique word in the dataset
unique_words = set ( train_text )
word_embeddings = model . encode ( list ( unique_words ))
# Cluster the words using K-Means
num_clusters = 5
kmeans = KMeans ( n_clusters = num_clusters , random_state = 42 )
clusters = kmeans . fit_predict ( word_embeddings )
# Group the words by cluster
word_clusters = defaultdict ( list )
for i , word in enumerate ( unique_words ):
word_clusters [ clusters [ i ]]. append ( word )
# Create a word cloud for each cluster
fig , axes = plt . subplots ( 1 , 5 , figsize = ( 14 , 12 ))
axes = axes . flatten ()
for cluster_id , cluster_words in word_clusters . items ():
word_cloud = WordCloud ( width = 400 , height = 200 , background_color = 'white' ). generate ( ' ' . join ( cluster_words ))
axes [ cluster_id ]. imshow ( word_cloud , interpolation = 'bilinear' )
axes [ cluster_id ]. set_title ( f"Cluster { cluster_id } " )
axes [ cluster_id ]. axis ( 'off' )
plt . subplots_adjust ( wspace = 0.4 , hspace = 0.6 )
plt . tight_layout ()
plt . show ()
The two data formats, N x B x L and M x L , are commonly used in language modeling tasks, particularly in the context of neural network-based models.
N x B x L format:
N represents the number of batches. In this case, the dataset is divided into N smaller batches, which is a common practice to improve the efficiency and stability of the training process.B is the batch size, which represents the number of samples (eg, sentences, paragraphs, or documents) within each batch.L is the length of a sample within each batch, which typically corresponds to the number of tokens (words) in a sample. M x L format:
N x B x L format.M is equal to N x B , which represents the total number of samples (eg, sentences, paragraphs, or documents) in the dataset.L is the length of each sample, which corresponds to the number of tokens (words) in the sample. The choice between these two formats depends on the specific requirements of your language modeling task and the capabilities of the neural network architecture you're working with. If you're training a neural network-based language model, the N x B x L format is typically preferred, as it allows for efficient batch-based training and can lead to faster convergence and better performance. However, if your task doesn't involve neural networks or if the dataset is relatively small, the M x L format may be more suitable.
def prepare_language_model_data ( raw_text_iterator , sequence_length ):
"""
Prepare PyTorch tensors for a language model.
Args:
raw_text_iterator (iterable): An iterator of raw text data.
sequence_length (int): The length of the input and target sequences.
Returns:
tuple: A tuple containing two PyTorch tensors:
- inputs (torch.Tensor): A tensor of input sequences.
- targets (torch.Tensor): A tensor of target sequences.
"""
# Convert the raw text iterator into a single PyTorch tensor
data = torch . cat ([ torch . LongTensor ( vocab ( tokenizer ( line ))) for line in raw_text_iterator ])
# Calculate the number of complete sequences that can be formed
num_sequences = len ( data ) // sequence_length
# Calculate the remainder of the data length divided by the sequence length
remainder = len ( data ) % sequence_length
# If the remainder is 0, add a single <unk> token to the end of the data tensor
if remainder == 0 :
unk_tokens = torch . LongTensor ([ vocab [ '<unk>' ]])
data = torch . cat ([ data , unk_tokens ])
# Extract the input and target sequences from the data tensor
inputs = data [: num_sequences * sequence_length ]. reshape ( - 1 , sequence_length )
targets = data [ 1 : num_sequences * sequence_length + 1 ]. reshape ( - 1 , sequence_length )
print ( len ( inputs ), len ( targets ))
return inputs , targets sequence_length = 30
X_train , y_train = prepare_language_model_data ( train_iter , sequence_length )
X_valid , y_valid = prepare_language_model_data ( valid_iter , sequence_length )
X_test , y_test = prepare_language_model_data ( test_iter , sequence_length )
X_train . shape , y_train . shape , X_valid . shape , y_valid . shape , X_test . shape , y_test . shape
( torch . Size ([ 68333 , 30 ]),
torch . Size ([ 68333 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 8061 , 30 ]),
torch . Size ([ 8061 , 30 ])) This code defines a PyTorch Dataset class for working with language model data. The LanguageModelDataset class takes in input and target tensors and provides the necessary methods for accessing the data.
class LanguageModelDataset ( Dataset ):
def __init__ ( self , inputs , targets ):
self . inputs = inputs
self . targets = targets
def __len__ ( self ):
return self . inputs . shape [ 0 ]
def __getitem__ ( self , idx ):
return self . inputs [ idx ], self . targets [ idx ] The LanguageModelDataset class can be used as follows:
# Create the datasets
train_set = LanguageModelDataset ( X_train , y_train )
valid_set = LanguageModelDataset ( X_valid , y_valid )
test_set = LanguageModelDataset ( X_test , y_test )
# Create data loaders (optional)
train_loader = DataLoader ( train_set , batch_size = 32 , shuffle = True )
valid_loader = DataLoader ( valid_set , batch_size = 32 )
test_loader = DataLoader ( test_set , batch_size = 32 )
# Access the data
x_batch , y_batch = next ( iter ( train_loader ))
print ( f"Input batch shape: { x_batch . shape } " ) # Input batch shape: torch.Size([32, 30])
print ( f"Target batch shape: { y_batch . shape } " ) # Target batch shape: torch.Size([32, 30]) The code defines a custom PyTorch language model that allows you to use different types of word embeddings, including randomly initialized embeddings, pre-trained GloVe embeddings, pre-trained FastText embeddings, by simply specifying the embedding_type argument when creating the model instance.
import torch . nn as nn
from torchtext . vocab import GloVe , FastText
class LanguageModel ( nn . Module ):
def __init__ ( self , vocab_size , embedding_dim ,
hidden_dim , num_layers , dropout_embd = 0.5 ,
dropout_rnn = 0.5 , embedding_type = 'random' ):
super (). __init__ ()
self . num_layers = num_layers
self . hidden_dim = hidden_dim
self . embedding_dim = embedding_dim
self . embedding_type = embedding_type
if embedding_type == 'random' :
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . uniform_ ( - 0.1 , 0.1 )
elif embedding_type == 'glove' :
self . glove = GloVe ( name = '6B' , dim = embedding_dim )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . glove . vectors )
self . embedding . weight . requires_grad = False
elif embedding_type == 'fasttext' :
self . glove = FastText ( language = 'en' )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . fasttext . vectors )
self . embedding . weight . requires_grad = False
else :
raise ValueError ( "Invalid embedding_type. Choose from 'random', 'glove', 'fasttext'." )
self . dropout = nn . Dropout ( p = dropout_embd )
self . lstm = nn . LSTM ( embedding_dim , hidden_dim , num_layers = num_layers ,
dropout = dropout_rnn , batch_first = True )
self . fc = nn . Linear ( hidden_dim , vocab_size )
def forward ( self , src ):
embedding = self . dropout ( self . embedding ( src ))
output , hidden = self . lstm ( embedding )
prediction = self . fc ( output )
return prediction model = LanguageModel ( vocab_size = len ( vocab ),
embedding_dim = 300 ,
hidden_dim = 512 ,
num_layers = 2 ,
dropout_embd = 0.65 ,
dropout_rnn = 0.5 ,
embedding_type = 'glove' ) def num_trainable_params ( model ):
nums = sum ( p . numel () for p in model . parameters () if p . requires_grad ) / 1e6
return nums
# Calculate the number of trainable parameters in the embedding, LSTM, and fully connected layers of the LanguageModel instance 'model'
num_trainable_params ( model . embedding ) # (7.0956)
num_trainable_params ( model . lstm ) # (3.76832)
num_trainable_params ( model . fc ) # (12.133476)

