Torch Linguist
1.0.0

Dieses Projekt ist eine Schritt-für-Schritt-Anleitung zum Erstellen eines Sprachmodells mit Pytorch. Ziel ist es, ein umfassendes Verständnis des Prozesses zu vermitteln, der mit der Entwicklung eines Sprachmodells und seiner Anwendungen verbunden ist.
Die Sprachmodellierung oder LM ist die Verwendung verschiedener statistischer und probabilistischer Techniken, um die Wahrscheinlichkeit einer bestimmten Abfolge von Wörtern zu bestimmen, die in einem Satz auftreten. Sprachmodelle analysieren Textdaten, um eine Grundlage für ihre Wortvorhersagen zu liefern.
Die Sprachmodellierung wird in der künstlichen Intelligenz (KI), der natürlichen Sprachverarbeitung (NLP), der natürlichen Sprachverständnis (NLU) und der natürlichen Sprachgenerierung (NLG) verwendet, insbesondere in denjenigen, die Textgenerierung, maschinelle Übersetzung und Fragen beantworten.
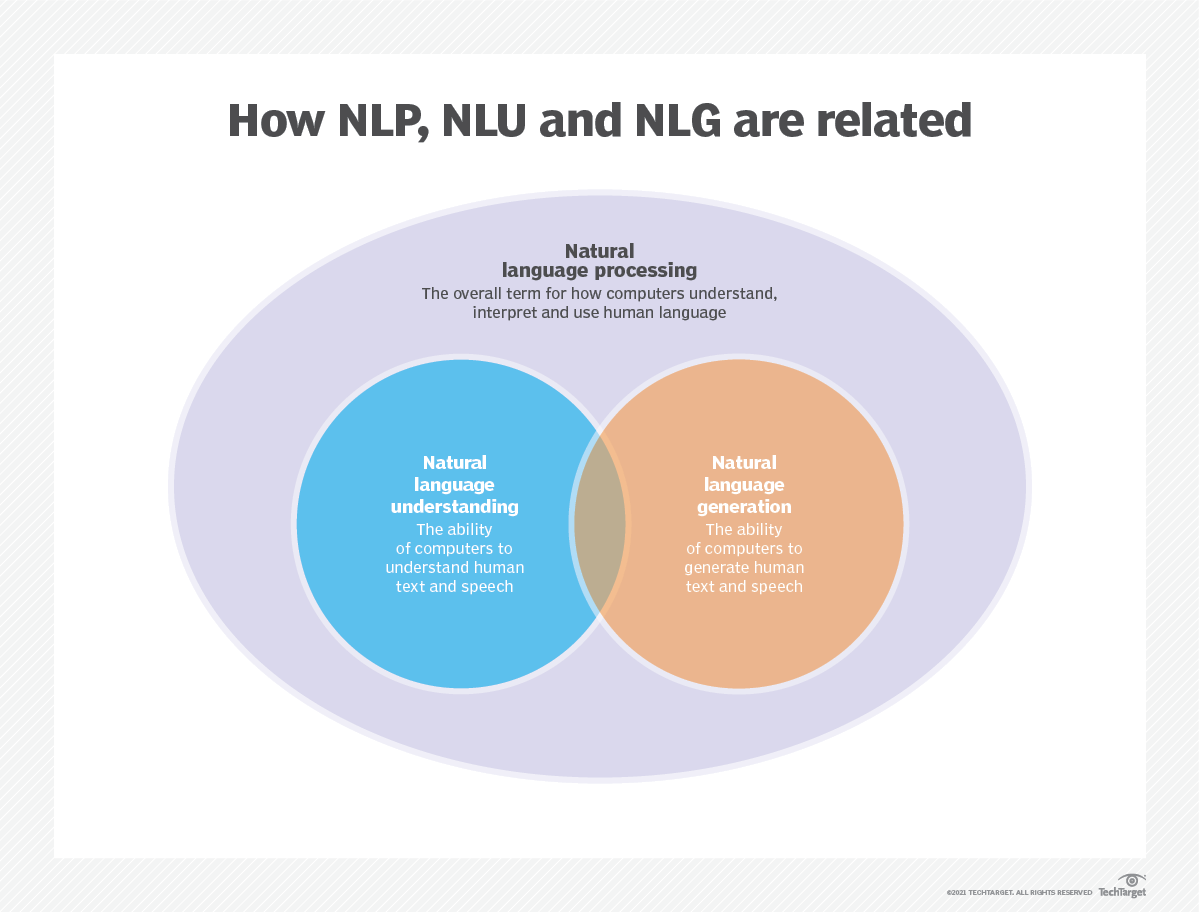
Große Sprachmodelle (LLMs) verwenden auch Sprachmodellierung. Dies sind erweiterte Sprachmodelle wie OpenAIs GPT-3 und Google Palm 2, die Milliarden von Trainingsdatenparametern verarbeiten und Textausgaben generieren.
Die Wirksamkeit eines Sprachmodells wird typischerweise unter Verwendung von Metriken wie Kreuzentropie und Verwirrung bewertet, wodurch die Fähigkeit des Modells misst, das nächste Wort genau vorherzusagen (ich werde sie in Schritt 2 abdecken). Mehrere Datensätze wie Wikitext-2, Wikitext-103, ein Milliarde Wort, Text8 und C4 werden häufig zur Bewertung von Sprachmodellen verwendet. Hinweis : In diesem Projekt verwende ich Wikitext-2.
Die Forschung von LM hat in der Literatur umfangreiche Aufmerksamkeit erhalten, die in vier Hauptentwicklungsphasen unterteilt werden kann:
SLMs werden basierend auf statistischen Lernmethoden entwickelt, die in den neunziger Jahren anstanden. Die Grundidee besteht darin, das Wort Vorhersagemodell basierend auf der Markov -Annahme zu erstellen, z. B. das nächste Wort, das auf dem neuesten Kontext basiert. Die SLMs mit einer festen Kontextlänge N werden auch als N-Gram-Sprachmodelle , z. B. Modelle mit Bigram und Trigramm, bezeichnet. SLMs wurden häufig angewendet, um die Aufgabenleistung bei Informationsabruf (IR) und natürliche Sprachverarbeitung (NLP) zu verbessern. Sie leiden jedoch häufig unter dem Fluch der Dimensionalität:
Es ist schwierig, Sprachmodelle mit hoher Ordnung genau zu schätzen, da eine exponentielle Anzahl von Übergangswahrscheinlichkeiten geschätzt werden muss. Daher wurden speziell entwickelte Glättungsstrategien wie Back-Off-Schätzungen und gute Schätzungen eingeführt, um das Problem der Datensparsamkeit zu lindern.
NLMs charakterisieren die Wahrscheinlichkeit von Wortsequenzen durch neuronale Netzwerke, z. B. Multi-Layer Perceptron (MLP) und wiederkehrende neuronale Netzwerke (RNNs). Als bemerkenswerter Beitrag ist das Konzept der verteilten Darstellung . Verteilte Darstellungen, auch als Einbettungen bezeichnet, ist die Idee, dass der "Bedeutung" oder "semantische Inhalt" eines Datenpunkts über mehrere Dimensionen verteilt ist. Zum Beispiel werden in NLP Wörter mit ähnlichen Bedeutungen auf Punkte im Vektorraum zugeordnet, die nahe beieinander liegen. Diese Nähe ist nicht willkürlich, sondern aus dem Kontext, in dem Wörter erscheinen. Dieses kontextabhängige Lernen wird häufig durch neuronale Netzwerkmodelle wie Word2VEC oder Handschuh erreicht, die große Textkorpora verarbeiten, um diese Darstellungen zu erlernen.
Einer der wichtigsten Vorteile verteilter Darstellungen ist ihre Fähigkeit, feinkörnige semantische Beziehungen aufzunehmen. Zum Beispiel würden in einem gut ausgebildeten Wort, das Raum einbettet, Synonyme durch Vektoren dargestellt, die nahe beieinander liegen, und es ist sogar möglich, arithmetische Operationen mit diesen Vektoren durchzuführen, die sinnvolle semantische Operationen entsprechen (z. B. "König" - "Mann" + "Frau" könnte zu einem Vektor in der Nähe von "Queen" führen.
Anwendungen verteilter Darstellungen:
Verteilte Darstellungen haben eine breite Palette von Anwendungen, insbesondere bei Aufgaben, die das Verständnis der natürlichen Sprache beinhalten. Sie werden verwendet für:
Wort Ähnlichkeit : Messung der semantischen Ähnlichkeit zwischen Wörtern.
Textklassifizierung : Kategorisierung von Dokumenten in vordefinierte Klassen.
Maschinelle Übersetzung : Text von einer Sprache in eine andere übersetzen.
Informationsabruf : Finden relevanter Dokumente als Antwort auf eine Abfrage.
Stimmungsanalyse : Bestimmung des in einem Textstück ausgedrückten Gefühl.
Darüber hinaus sind verteilte Darstellungen nicht auf Textdaten beschränkt. Sie können auch auf andere Arten von Daten angewendet werden, wie z. B. Bilder, bei denen Deep Learning-Modelle lernen, Bilder als hochdimensionale Vektoren darzustellen, die visuelle Merkmale und Semantik erfassen.
Kausalsprachmodelle, auch autoregressive Modelle bekannt, erzeugen Text, indem das nächste Wort in einer Sequenz bei den vorherigen Wörtern vorhergesagt wird. Diese Modelle sind geschult, um die Wahrscheinlichkeit des nächsten Wortes mithilfe von Techniken wie der Transformer -Architektur zu maximieren. Während des Trainings ist der Eingang zum Modell die gesamte Sequenz bis zu einem bestimmten Token, und das Ziel des Modells ist es, das nächste Token vorherzusagen. Diese Art von Modell ist nützlich für Aufgaben wie Textgenerierung , Abschluss und Zusammenfassung .
Maskierte Sprachmodelle (MLMs) sollen kontextbezogene Darstellungen von Wörtern lernen, indem maskierte oder fehlende Wörter in einem Satz vorhergesagt werden. Während des Trainings wird ein Teil der Eingabesequenz zufällig maskiert, und das Modell wird geschult, um die ursprünglichen Wörter im Kontext vorherzusagen. MLMs verwenden bidirektionale Architekturen wie Transformatoren, um die Abhängigkeiten zwischen den maskierten Wörtern und dem Rest des Satzes zu erfassen. Diese Modelle zeichnen sich in Aufgaben wie Textklassifizierung , mit dem Namen Entitätserkennung und Beantwortung von Fragen aus.
Sequence-to-Sequence (SEQ2SEQ) -Modelle werden geschult, um eine Eingangssequenz auf eine Ausgangssequenz zuzuordnen. Sie bestehen aus einem Encoder , der die Eingabesequenz verarbeitet, und aus einem Decoder , der die Ausgangssequenz erzeugt. SEQ2SEQ -Modelle werden in Aufgaben wie maschineller Übersetzung , Textübersicht und Dialogsystemen häufig verwendet. Sie können mit Techniken wie wiederkehrenden neuronalen Netzwerken (RNNs) oder Transformatoren ausgebildet werden. Das Trainingsziel besteht darin, die Wahrscheinlichkeit zu maximieren, die korrekte Ausgangssequenz bei der Eingabe zu erzeugen.
Es ist wichtig zu beachten, dass sich diese Schulungsansätze nicht gegenseitig ausschließen , und Forscher kombinieren sie häufig oder verwenden Variationen, um spezifische Ziele zu erreichen. Beispielsweise kombinieren Modelle wie T5 die autoregressiven und maskierten Sprachmodell -Trainingsziele, um eine Vielzahl von Aufgaben zu lernen.
Jeder Trainingsansatz hat seine eigenen Stärken und Schwächen, und die Auswahl des Modells hängt von den spezifischen Aufgabenanforderungen und den verfügbaren Schulungsdaten ab.
Weitere Informationen finden Sie im Kapitel "Medium.com" finden Sie auf der Website "Medium.com".
Die Sprachmodellierung beinhaltet das Erstellen von Modellen, die Sequenzen von Wörtern oder Zeichen erzeugen oder vorhergesagt werden können. Hier sind einige verschiedene Arten von Modellen, die üblicherweise für die Sprachmodellierung verwendet werden:
In einem N-Gramm-Modell wird die Wahrscheinlichkeit eines Wortes auf der Grundlage seines Auftretens in den Trainingsdaten im Vergleich zu seinen vorhergehenden N-1-Wörtern geschätzt. Zum Beispiel wird in einem Trigrammmodell (n = 3) die Wahrscheinlichkeit eines Wortes durch die beiden Wörter bestimmt, die es unmittelbar vorangehen. Dieser Ansatz geht davon aus, dass die Wahrscheinlichkeit eines Wortes nur von einer festen Anzahl vorhergehender Wörter abhängt und keine langfristigen Abhängigkeiten berücksichtigt.
Hier sind einige Beispiele für N-Gramm:
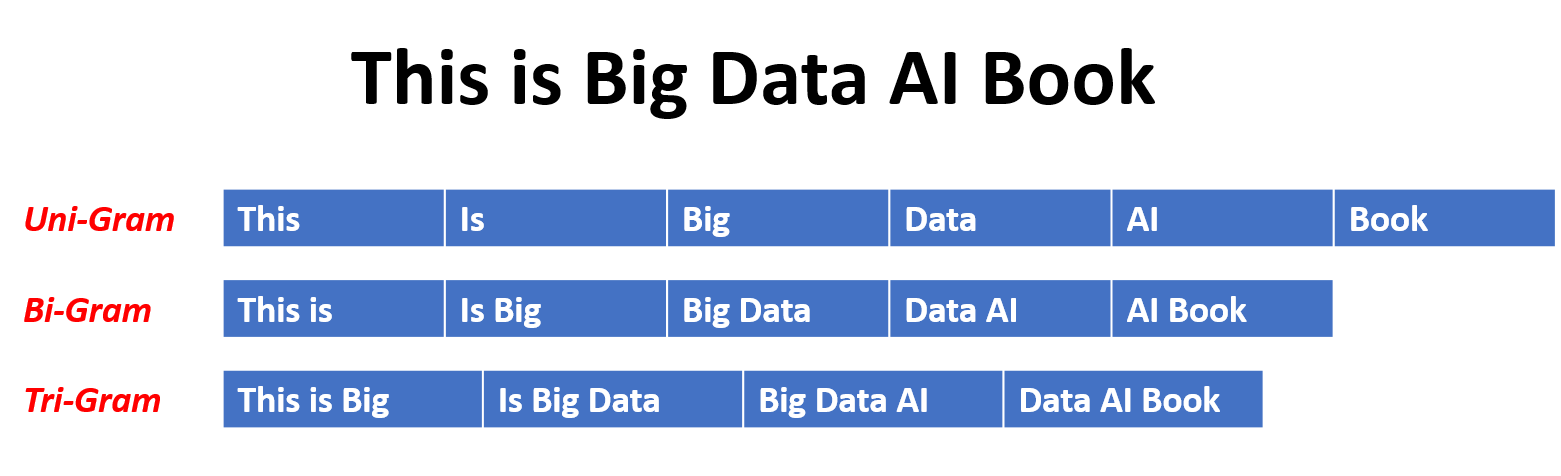
Hier sind die Vor- und Nachteile von N-Gram-Sprachmodellen:
Vorteile :
Nachteile :
Hier ist ein Beispiel für die Verwendung von N-Gramm in Torchtext:
import torchtext
from torchtext . data import get_tokenizer
from torchtext . data . utils import ngrams_iterator
tokenizer = get_tokenizer ( "basic_english" )
# Create a tokenizer object using the "basic_english" tokenizer provided by torchtext
# This tokenizer splits the input text into a list of tokens
tokens = tokenizer ( "I love to code in Python" )
# The result is a list of tokens, where each token represents a word or a punctuation mark
print ( list ( ngrams_iterator ( tokens , 3 )))
[ 'i' , 'love' , 'to' , 'code' , 'in' , 'python' , 'i love' , 'love to' , 'to code' , 'code in' , 'in python' , 'i love to' , 'love to code' , 'to code in' , 'code in python' ]Notiz :
RNNs sind die grundlegende Art des neuronalen Netzwerks für die sequentielle Datenverarbeitung. Sie haben wiederkehrende Verbindungen, mit denen Informationen von einem Schritt zum nächsten weitergegeben werden können, sodass sie Abhängigkeiten über die Zeit erfassen können. Traditionelle RNNs leiden jedoch unter dem verschwindenden/explodierenden Gradientenproblem und kämpfen mit langfristigen Abhängigkeiten.
Vorteile von RNNs :
Nachteile von RNNs :
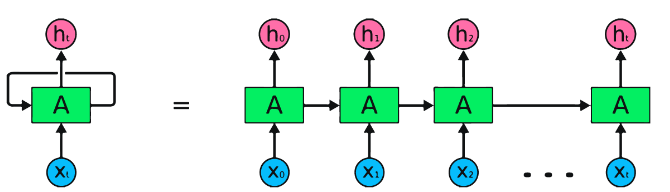
Pytorch -Code -Snippet zum Definieren eines Basic RNN in Pytorch:
import torch
import torch . nn as nn
rnn = nn . RNN ( input_size = 10 , hidden_size = 20 , num_layers = 2 )
# input_size – The number of expected features in the input x
# hidden_size – The number of features in the hidden state h
# num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together
# Create a randomly initialized input tensor
input = torch . randn ( 5 , 3 , 10 ) # (sequence length=5, batch size=3, input size=10)
# Create a randomly initialized hidden state tensor
h0 = torch . randn ( 2 , 3 , 20 ) # (num_layers=2, batch size=3, hidden size=20)
# Apply the RNN module to the input tensor and initial hidden state tensor
output , hn = rnn ( input , h0 )
print ( output . shape ) # torch.Size([5, 3, 20])
# (sequence length=5, batch size=3, hidden size=20)
print ( hn . shape ) # torch.Size([2, 3, 20])
# (num_layers=2, batch size=3, hidden size=20)Vorteile von LSTMs :
Nachteile von LSTMs :
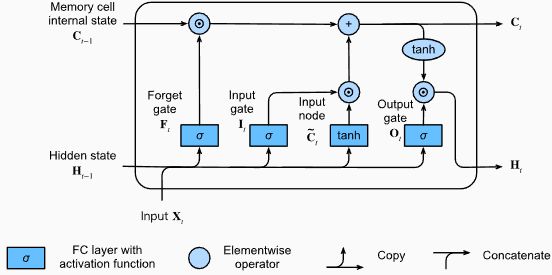
Pytorch -Code -Snippet zum Definieren eines Basic LSTM in Pytorch:
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
lstm = nn . LSTM ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
c0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , ( hn , cn ) = lstm ( input_data , ( h0 , c0 )) Die Ausgangsform der LSTM -Schicht ist auch [seq_length, batch_size, hidden_size] . Dies bedeutet, dass für jeden Eingang in der Sequenz ein entsprechender Ausgang versteckt wird. In dem vorgesehenen Beispiel ist die Ausgangsform die torch.Size([10, 1, 64]) , was darauf hinweist, dass die LSTM auf eine Sequenz von Länge 10 mit einer Chargengröße von 1 und einer versteckten Zustandsgröße von 64 angewendet wurde.
Lassen Sie uns nun den Tensor hn (Hidden State) besprechen. Seine Form ist torch.Size([2, 1, 64]) . Die erste Dimension, 2, repräsentiert die Anzahl der Schichten im LSTM. In diesem Fall wurde das Argument num_layers auf 2 gesetzt, sodass im LSTM -Modell 2 Ebenen enthalten sind. Die zweite Dimension 1 entspricht der Chargengröße, die 1 im angegebenen Beispiel ist. Schließlich repräsentiert die letzte Dimension, 64, die Größe des verborgenen Zustands.
Daher enthält der hn -Tensor den endgültigen verborgenen Zustand für jede Schicht der LSTM nach der Verarbeitung der gesamten Eingangssequenz, nachdem die Fähigkeit des LSTM nach langfristigen Abhängigkeiten beibehalten und das Problem des Flüstungsgradienten gemindert wird.
Weitere Informationen finden Sie im Kapitel "Long Short-Term Memory) (LSTM) in der Dokumentation" Tauchung in Deep Learning ".
Vorteile von Grus :
Nachteile von Grus :
Insgesamt überwinden LSTM- und GRU-Modelle einige der Einschränkungen traditioneller RNNs, insbesondere bei der Erfassung langfristiger Abhängigkeiten. LSTMS übertreffen die Kontextinformationen, während Grus eine rechnerisch effizientere Alternative bietet. Die Wahl zwischen LSTM und GRU hängt von den spezifischen Anforderungen der Aufgabe und den verfügbaren Rechenressourcen ab.
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
gru = nn . GRU ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , hn = gru ( input_data , h0 ) Die Ausgangsform der GRU -Schicht ist auch [seq_length, batch_size, hidden_size] . Dies bedeutet, dass für jeden Eingang in der Sequenz ein entsprechender Ausgang versteckt wird. In dem vorgesehenen Beispiel ist die Ausgangsform die torch.Size([10, 1, 64]) , was darauf hinweist, dass die GRU auf eine Sequenz von Länge 10 mit einer Chargengröße von 1 und einer versteckten Zustandsgröße von 64 angewendet wurde.
Lassen Sie uns nun den Tensor hn (Hidden State) besprechen. Seine Form ist torch.Size([2, 1, 64]) . Die erste Dimension, 2, repräsentiert die Anzahl der Schichten in der Gru. In diesem Fall wurde das Argument num_layers auf 2 gesetzt, sodass im Gru -Modell 2 Ebenen enthalten sind. Die zweite Dimension 1 entspricht der Chargengröße, die 1 im angegebenen Beispiel ist. Schließlich repräsentiert die letzte Dimension, 64, die Größe des verborgenen Zustands.
Daher enthält der hn -Tensor den endgültigen verborgenen Zustand für jede Schicht der GRU nach der Verarbeitung der gesamten Eingangssequenz, wobei die Fähigkeit des Gru, Informationen über lange Sequenzen zu erfassen und zu behalten und gleichzeitig das Problem der Fluchtgradienten zu mildern.
Weitere Informationen finden Sie in der Dokumentation "Tauchung in Deep Learning" finden Sie in der Kapitel "Tauchung in Deep Learning".
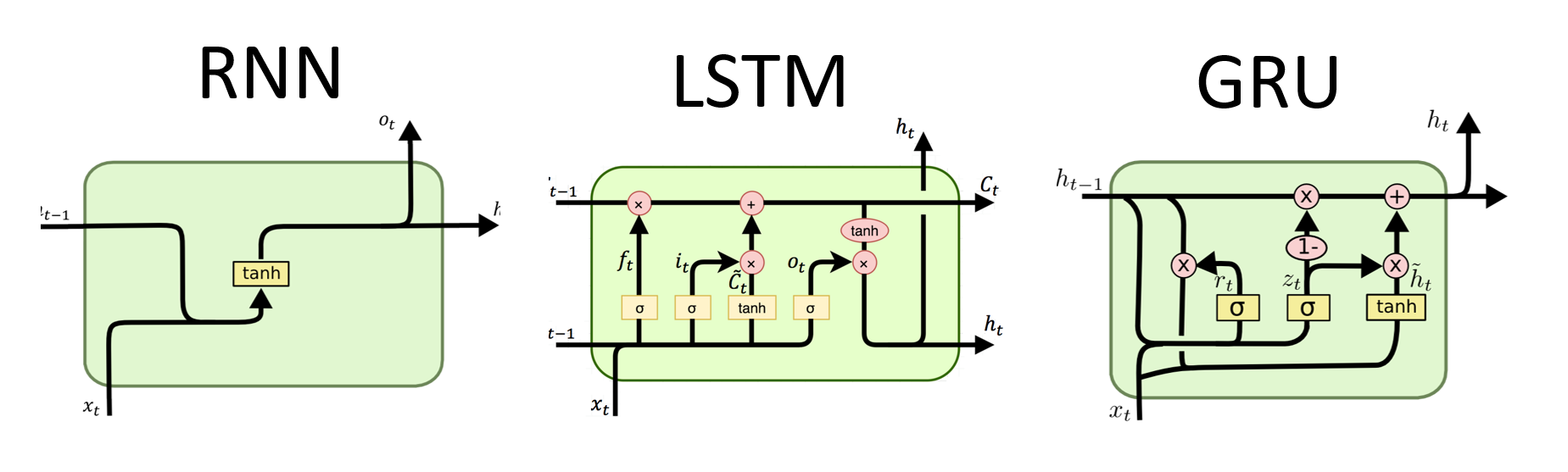
Vorteile :
Erfassen von Abhängigkeiten mit Langstrecken: Transformatoren sind hervorragend bei der Erfassung von Abhängigkeiten von Langstrecken in Sequenzen durch Verwendung von Selbstbewegungsmechanismen. Dies ermöglicht es ihnen, alle Positionen in der Eingabesequenz bei Vorhersagen zu berücksichtigen, wodurch ein besseres Verständnis des Kontextes ermöglicht und die Qualität des generierten Textes verbessert wird.
Parallele Verarbeitung: Im Gegensatz zu wiederkehrenden Modellen können Transformatoren die Eingangssequenz parallel verarbeiten, wodurch sie hocheffizient und die Trainings- und Inferenzzeiten reduziert werden. Diese Parallelisierung ist aufgrund des Fehlens sequentieller Abhängigkeiten in der Architektur möglich.
Skalierbarkeit: Transformatoren sind hoch skalierbar und können große Eingangssequenzen effektiv verarbeiten. Sie können Sequenzen von willkürlichen Längen verarbeiten, ohne dass Abkürzung oder Polsterung erforderlich ist, was für Aufgaben, die lange Dokumente oder Sätze beinhalten, besonders vorteilhaft ist.
Kontextverständnis: Transformatoren können umfangreiche kontextbezogene Informationen erfassen, indem sie sich um relevante Teile der Eingabesequenz kümmern. Dies ermöglicht es ihnen, komplexe sprachliche Strukturen, semantische Beziehungen und Abhängigkeiten zwischen Wörtern zu verstehen, was zu einer kohärenten und kontextbezogeneren Spracherzeugung führt.
Nachteile von Transformatormodellen :
Hohe Rechenanforderungen: Transformatoren erfordern in der Regel signifikante Rechenressourcen im Vergleich zu einfacheren Modellen wie N-Gramm oder herkömmlichen RNNs. Das Training großer Transformatormodelle mit umfangreichen Datensätzen kann rechnerisch teuer und zeitaufwändig sein.
Mangel an sequentieller Modellierung: Während Transformatoren sich bei der Erfassung globaler Abhängigkeiten übertreffen, können sie möglicherweise nicht so effektiv bei der Modellierung streng sequentieller Daten sind. In Fällen, in denen die Reihenfolge der Eingangssequenz von entscheidender Bedeutung ist, z.
Aufmerksamkeitsmechanismus Komplexität: Der Selbstbekämpfungsmechanismus in Transformatoren führt zu einer zusätzlichen Komplexität der Modellarchitektur. Das korrekte Verständnis und Umsetzung von Aufmerksamkeitsmechanismen kann herausfordernd sein, und das Tuning von Hyperparametern im Zusammenhang mit der Aufmerksamkeit kann nicht trivial sein.
Datenanforderungen: Transformatoren benötigen häufig große Mengen an Schulungsdaten, um eine optimale Leistung zu erzielen. Vorbereitungen in groß angelegten Korpora, beispielsweise bei vorbereiteten Transformatormodellen wie GPT und Bert, können die Leistung von Transformatoren effektiv nutzen.
Weitere Informationen finden Sie im Kapitel "The Transformator Architecture" in der Dokumentation "Tauchgang in Deep Learning".
Trotz dieser Einschränkungen haben Transformatormodelle das Gebiet der natürlichen Sprachverarbeitung und der Sprachmodellierung revolutioniert. Ihre Fähigkeit, langfristige Abhängigkeiten und kontextbezogenes Verständnis zu erfassen, hat den Kunststillstand in verschiedenen sprachbezogenen Aufgaben erheblich weiterentwickelt und sie für viele Anwendungen zu einer herausragenden Wahl gemacht.
Verwirrung ist im Kontext der Sprachmodellierung eine Maßnahme, die quantifiziert, wie gut ein Sprachmodell einen bestimmten Testsatz vorhersagt, wobei eine geringere Verwirrung auf eine bessere Vorhersageleistung hinweist. Einfacher wird die Verwirrung berechnet, indem die inverse Wahrscheinlichkeit des Testsatzes eingenommen und dann durch die Anzahl der Wörter normalisiert wird.
Je niedriger der Verwirrungswert ist, desto besser ist das Sprachmodell bei der Vorhersage des Testsatzes. Das Minimieren der Verwirrung ist das gleiche wie die Maximierung der Wahrscheinlichkeit
Die Formel für Verwirrung als inverse Wahrscheinlichkeit des Testsatzes, normalisiert durch die Anzahl der Wörter, lautet wie folgt:
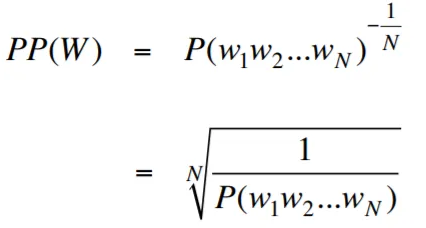

Verwirrung kann als Maß für den Verzweigungsfaktor in einem Sprachmodell interpretiert werden. Der Verzweigungsfaktor repräsentiert die durchschnittliche Anzahl möglicher nächster Wörter oder Token, die einen bestimmten Kontext oder eine bestimmte Reihenfolge von Wörtern erhalten.
Der Verzweigungsfaktor einer Sprache ist die Anzahl der möglichen nächsten Wörter, die jedem Wort folgen können. Wir können uns Verwirrung als den gewichteten durchschnittlichen Verzweigungsfaktor einer Sprache vorstellen.
Die Sprachmodellierung mit Einbettungsschicht und LSTM -Code ist ein leistungsstarkes Werkzeug zum Aufbau und Trainingssprachmodellen. Diese Code-Implementierung kombiniert zwei grundlegende Komponenten in der Verarbeitung natürlicher Sprache: eine Einbettungsschicht und ein langes Kurzzeitgedächtnisnetzwerk (LSTM) .
Die Einbettungsschicht ist für die Konvertierung von Textdaten in verteilte Darstellungen verantwortlich, die auch als Worteinbettungen bezeichnet werden. Diese Einbettungen erfassen semantische und syntaktische Eigenschaften von Wörtern und ermöglichen es dem Modell, die Bedeutung und den Kontext des Eingabetxtes zu verstehen. Die Einbettungsschicht birgt jedes Wort in der Eingangssequenz zu einem hochdimensionalen Vektor, der als Eingabe für nachfolgende Schichten im Modell dient.
Die LSTM -Ebene in der Code -Implementierung verarbeitet das Wort ein, das von der Einbettungsschicht erzeugt wird, wodurch die Sequenzinformationen erfasst und die zugrunde liegenden Muster und Strukturen im Text gelernt werden.
Durch die Kombination der Einbettungsschicht und des LSTM -Netzwerks ermöglicht der Code die Konstruktion eines Sprachmodells, mit dem kohärenten und kontextbezogenen Text erzeugt werden kann. Sprachmodelle, die mit diesem Ansatz erstellt wurden, können in großen Textdatensätzen trainiert werden und können realistische und aussagekräftige Sätze generieren, wodurch sie wertvolle Werkzeuge für verschiedene Aufgaben zur Verarbeitung natürlicher Sprache wie Textgenerierung, maschinelle Übersetzung und Sentimentanalyse machen können.
Diese Code -Implementierung bietet eine einfache, klare und prägnante Grundlage für den Aufbau von Sprachmodellen, die auf der Einbettungsschicht und der LSTM -Architektur basieren. Es dient als Ausgangspunkt für Forscher, Entwickler und Enthusiasten, die daran interessiert sind, hochmoderne Sprachmodellierungstechniken zu erforschen und zu experimentieren.
Durch diesen Code können Sie ein tieferes Verständnis dafür erlangen, wie die Einbettung von Schichten und LSTMs zusammenarbeiten, um die komplexen Muster und Abhängigkeiten in Textdaten zu erfassen. Mit diesem Wissen können Sie den Code weiter erweitern und erweiterte Techniken untersuchen, z.
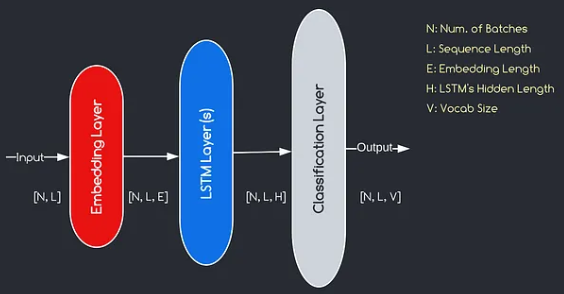
Das von uns konstruierte Modell entspricht dem oben angegebenen Diagramm und zeigt die drei Schlüsselkomponenten: eine Einbettungsschicht, LSTM -Ebenen und eine Klassifizierungsschicht. Während uns die Ziele der LSTM- und Klassifizierungsschichten bereits bekannt sind, lassen Sie uns mit der Bedeutung der Einbettungsschicht befassen.
Die Einbettungsschicht spielt eine entscheidende Rolle im Modell, indem jedes als Index dargestellte Wort in einen Vektor von E -Dimensionen umgewandelt wird. Diese Vektordarstellung ermöglicht es nachfolgenden Schichten, aus der Eingabe aussagekräftige Informationen zu lernen und zu extrahieren. Es ist erwähnenswert, dass die Verwendung von Indizes oder One-Hot-Vektoren zur Darstellung von Wörtern unzureichend sein kann, da sie keine Beziehungen zwischen verschiedenen Wörtern annehmen.
Der von der Einbettungsschicht durchgeführte Zuordnungsprozess ist ein erlerntes Verfahren, das während des Trainings stattfindet. Durch diese Trainingsphase erlangt das Modell die Fähigkeit, Wörter mit bestimmten Vektoren auf eine Weise zu verbinden, die semantische und syntaktische Beziehungen erfasst und damit das Verständnis des Modells für die zugrunde liegende Sprachstruktur verbessert.
Der von Salesforce entwickelte WKitext-103-Datensatz enthält über 100 Millionen Token, die aus dem Satz verifiziertes Gut und ausgestellten Artikeln über Wikipedia extrahiert wurden. Es hat 267.340 einzigartige Token, die mindestens dreimal im Datensatz erscheinen. Da es sich um Wikipedia-Artikel in voller Länge handelt, ist der Datensatz für Aufgaben gut geeignet, die langfristige Abhängigkeiten wie Sprachmodellierung profitieren können.
Der Wikitext-2- Datensatz ist eine kleine Version des Wikitext-103- Datensatzes, da er nur 2 Millionen Token enthält. Dieser kleine Datensatz eignet sich zum Testen Ihres Sprachmodells.

Dieses Repository enthält Code zur Durchführung von explorativen Datenanalysen im UTK -Datensatz, das aus Bildern besteht, die nach Alter, Geschlecht und ethnischer Zugehörigkeit kategorisiert sind.
Um einen Datensatz mit Torchtext herunterzuladen, können Sie das Modul torchtext.datasets verwenden. Hier ist ein Beispiel dafür, wie Sie den Wikitext-2-Datensatz mit Torchtext herunterladen:
import torchtext
from torchtext . datasets import WikiText2
data_path = "data"
train_iter , valid_iter , test_iter = WikiText2 ( root = data_path ) Zunächst habe ich versucht, den angegebenen Code zum Laden des Wikitext-2-Datensatzes zu verwenden, stieß jedoch auf ein Problem mit der URL (https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip), die für mich nicht funktionieren. Um dies zu überwinden, habe ich beschlossen, die torchtext -Bibliothek zu nutzen und eine benutzerdefinierte Implementierung des Datensatzladers zu erstellen.
Da die ursprüngliche URL nicht funktionierte, habe ich die Zug-, Validierung und Testdatensätze aus einem Github -Repository heruntergeladen und in das Verzeichnis 'data/datasets/WikiText2' platziert.
Hier ist eine Aufschlüsselung des Codes:
import os
from typing import Union , Tuple
from torchdata . datapipes . iter import FileOpener , IterableWrapper
from torchtext . data . datasets_utils import _wrap_split_argument , _create_dataset_directory
DATA_DIR = "data"
NUM_LINES = {
"train" : 36718 ,
"valid" : 3760 ,
"test" : 4358 ,
}
DATASET_NAME = "WikiText2"
_EXTRACTED_FILES = {
"train" : "wiki.train.tokens" ,
"test" : "wiki.test.tokens" ,
"valid" : "wiki.valid.tokens" ,
}
def _filepath_fn ( root , split ):
return os . path . join ( root , _EXTRACTED_FILES [ split ])
@ _create_dataset_directory ( dataset_name = DATASET_NAME )
@ _wrap_split_argument (( "train" , "valid" , "test" ))
def WikiText2 ( root : str , split : Union [ Tuple [ str ], str ]):
url_dp = IterableWrapper ([ _filepath_fn ( DATA_DIR , split )])
data_dp = FileOpener ( url_dp , encoding = "utf-8" ). readlines ( strip_newline = False , return_path = False ). shuffle (). set_shuffle ( False ). sharding_filter ()
return data_dp Um den Wikitext-2-Dataset-Loader zu verwenden, importieren Sie einfach die Wikitext2-Funktion und rufen Sie sie mit dem gewünschten Datensplit auf:
train_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "train" )
valid_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "valid" )
test_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "test" )Diese Implementierung ist von den offiziellen Torchtext -Datensatzladern inspiriert und nutzt die Torchdata- und Torchtext -Bibliotheken, um ein nahtloses und effizientes Datenbeladungserlebnis bereitzustellen.
Das Aufbau eines Wortschatzes ist ein entscheidender Schritt bei vielen Aufgaben mit natürlicher Sprache, da Sie Wörter als eindeutige Kennungen darstellen, die in maschinellen Lernmodellen verwendet werden können. In diesem Markdown -Dokument wird gezeigt, wie ein Vokabular aus einer Reihe von Trainingsdaten erstellt und für die zukünftige Verwendung gespeichert wird.
Hier ist eine Funktion, die den Prozess des Aufbaus und Speicherns eines Wortschatzes zusammenfasst:
import torch
from torchtext . data . utils import get_tokenizer
from torchtext . vocab import build_vocab_from_iterator
def build_and_save_vocabulary ( train_iter , vocab_path = 'vocab.pt' , min_freq = 4 ):
"""
Build a vocabulary from the training data iterator and save it to a file.
Args:
train_iter (iterator): An iterator over the training data.
vocab_path (str, optional): The path to save the vocabulary file. Defaults to 'vocab.pt'.
min_freq (int, optional): The minimum frequency of a word to be included in the vocabulary. Defaults to 4.
Returns:
torchtext.vocab.Vocab: The built vocabulary.
"""
# Get the tokenizer
tokenizer = get_tokenizer ( "basic_english" )
# Build the vocabulary
vocab = build_vocab_from_iterator ( map ( tokenizer , train_iter ), specials = [ '<unk>' ], min_freq = min_freq )
# Set the default index to the unknown token
vocab . set_default_index ( vocab [ '<unk>' ])
# Save the vocabulary
torch . save ( vocab , vocab_path )
return vocabSo können Sie diese Funktion verwenden:
# Assuming you have a training data iterator named `train_iter`
vocab = build_and_save_vocabulary ( train_iter , vocab_path = 'my_vocab.pt' )
# You can now use the vocabulary
print ( len ( vocab )) # 23652
print ( vocab ([ 'ebi' , 'AI' . lower (), 'qwerty' ])) # [0, 1973, 0] build_and_save_vocabulary enthält drei Argumente: train_iter (ein Iterator über die Trainingsdaten), vocab_path (der Weg zum Speichern der Vokabulardatei mit einem Standard von 'Vocab') und min_freq (minimaler Häufigkeit eines Wortes, das in das Vokabel mit einem Default mit 4) mit einem Abschluss des Vokabulary mit 4) ein Word einbezogen wird.basic_english Tokenizer, der grundlegende Tokenisierung im englischen Text ausführt.build_vocab_from_iterator , überträgt den Trainingsdaten -Iterator (nach Tokenisierung) und gibt das Spezial -Token '<unk>' und den Schwellenwert der Mindestfrequenz an.'<unk>' -Tokens fest, was bedeutet, dass jedes im Wortschatz nicht gefundene Wort dem unbekannten Token zugeordnet wird. Um diese Funktion zu verwenden, müssen Sie einen Trainingsdaten -Iterator namens train_iter haben. Anschließend können Sie die Funktion build_and_save_vocabulary aufrufen, den train_iter übergeben und den gewünschten Vokabular -Dateipfad und den minimalen Frequenzschwellenwert angeben.
Die Funktion erstellt das Wortschatz, speichern Sie es in der angegebenen Datei und gibt das Vocab -Objekt zurück, das Sie dann in Ihren nachgelagerten Aufgaben verwenden können.
Dieser Code bietet eine Möglichkeit, die mittlere Satzlänge im Wikitext-2-Datensatz zu analysieren. Hier ist eine Aufschlüsselung des Codes:
import matplotlib . pyplot as plt
def compute_mean_sentence_length ( data_iter ):
"""
Computes the mean sentence length for the given data iterator.
Args:
data_iter (iterable): An iterable of text data, where each element is a string representing a line of text.
Returns:
float: The mean sentence length.
"""
total_sentence_count = 0
total_sentence_length = 0
for line in data_iter :
sentences = line . split ( '.' ) # Split the line into individual sentences
for sentence in sentences :
tokens = sentence . strip (). split () # Tokenize the sentence
sentence_length = len ( tokens )
if sentence_length > 0 :
total_sentence_count += 1
total_sentence_length += sentence_length
mean_sentence_length = total_sentence_length / total_sentence_count
return mean_sentence_length
# Compute mean sentence length for each dataset
train_mean = compute_mean_sentence_length ( train_iter )
valid_mean = compute_mean_sentence_length ( valid_iter )
test_mean = compute_mean_sentence_length ( test_iter )
# Plot the results
datasets = [ 'Train' , 'Valid' , 'Test' ]
means = [ train_mean , valid_mean , test_mean ]
plt . figure ( figsize = ( 6 , 4 ))
plt . bar ( datasets , means )
plt . xlabel ( 'Dataset' )
plt . ylabel ( 'Mean Sentence Length' )
plt . title ( 'Mean Sentence Length in Wikitext-2' )
plt . grid ( True )
plt . show ()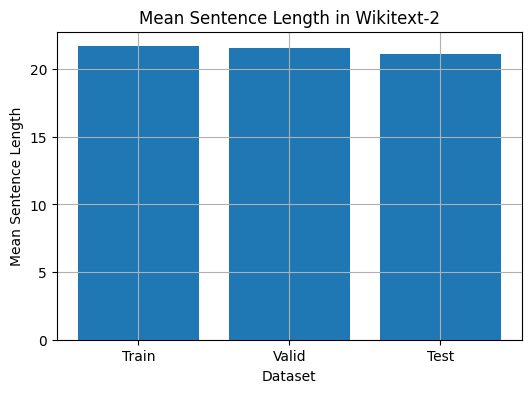
from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Find the 10 least common words
least_common_words = freqs . most_common ()[: - 11 : - 1 ]
print ( "Least Common Words:" )
for word , count in least_common_words :
print ( f" { word } : { count } " )
# Find the 10 most common words
most_common_words = freqs . most_common ( 10 )
print ( " n Most Common Words:" )
for word , count in most_common_words :
print ( f" { word } : { count } " ) from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Count the number of words that repeat 3, 4, and 5 times
count_3 = count_4 = count_5 = 0
for word , freq in freqs . items ():
if freq == 3 :
count_3 += 1
elif freq == 4 :
count_4 += 1
elif freq == 5 :
count_5 += 1
print ( f"Number of words that appear 3 times: { count_3 } " ) # 5130
print ( f"Number of words that appear 4 times: { count_4 } " ) # 3243
print ( f"Number of words that appear 5 times: { count_5 } " ) # 2261 from collections import Counter
import matplotlib . pyplot as plt
# Compute the word lengths in the training dataset
word_lengths = []
for tokens in map ( tokenizer , train_iter ):
word_lengths . extend ( len ( word ) for word in tokens )
# Create a frequency distribution of word lengths
word_length_counts = Counter ( word_lengths )
# Plot the word length distribution
plt . figure ( figsize = ( 10 , 6 ))
plt . bar ( word_length_counts . keys (), word_length_counts . values ())
plt . xlabel ( "Word Length" )
plt . ylabel ( "Frequency" )
plt . title ( "Word Length Distribution in Wikitext-2 Dataset" )
plt . show ()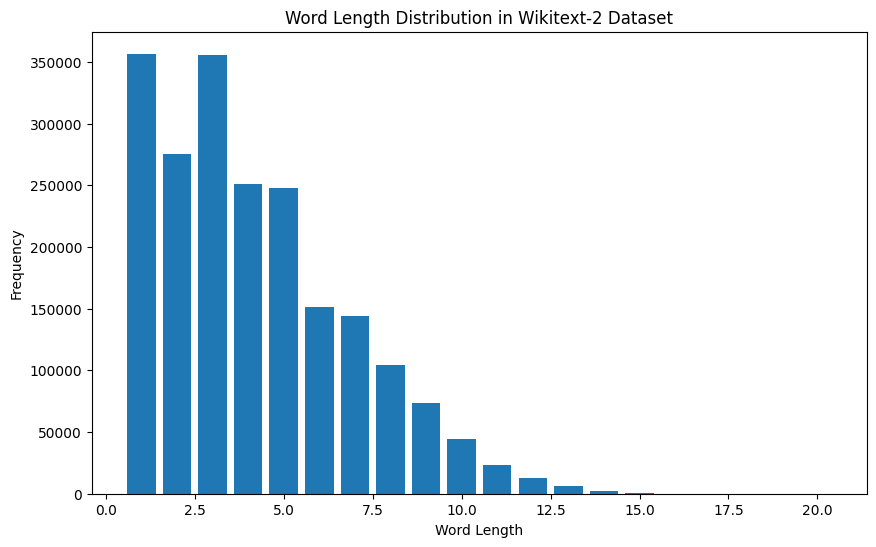
import spacy
import en_core_web_sm
# Load the small English language model from SpaCy
nlp = spacy . load ( "en_core_web_sm" )
# Alternatively, you can use the en_core_web_sm module to load the model
nlp = en_core_web_sm . load ()
# Process the given sentence using the loaded language model
doc = nlp ( "This is a sentence." )
# Print the text and part-of-speech tag for each token in the sentence
print ([( w . text , w . pos_ ) for w in doc ])
# [('This', 'PRON'), ('is', 'AUX'), ('a', 'DET'), ('sentence', 'NOUN'), ('.', 'PUNCT')]Für Wikitext-2-Datensatz:
import spacy
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform POS tagging on the training dataset
pos_tags = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
pos_tags . extend ([( token . text , token . pos_ ) for token in doc ])
# Count the frequency of each POS tag
pos_tag_counts = Counter ( tag for _ , tag in pos_tags )
# Print the most common POS tags
print ( "Most Common Part-of-Speech Tags:" )
for tag , count in pos_tag_counts . most_common ( 10 ):
print ( f" { tag } : { count } " )
# Visualize the POS tag distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( pos_tag_counts . keys (), pos_tag_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Part-of-Speech Tag" )
plt . ylabel ( "Frequency" )
plt . title ( "Part-of-Speech Tag Distribution in Wikitext-2 Dataset" )
plt . show ()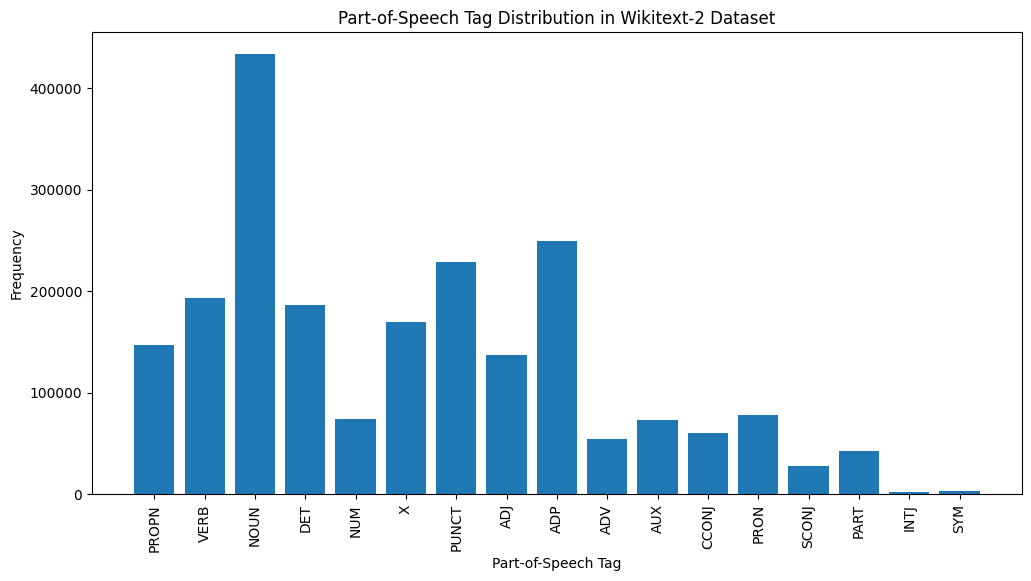
Hier finden Sie eine kurze Erklärung der häufigsten POS -Tags in der bereitgestellten Ausgabe:
Substantiv : Substantive repräsentieren Menschen, Orte, Dinge oder Ideen.
ADP : Adpositionen wie Präpositionen und Postpositionen werden verwendet, um Beziehungen zwischen Wörtern oder Phrasen auszudrücken.
PUNKT : Satzzeichenmarken, die für die Trennung und Strukturierung von Sätzen und Text unerlässlich sind.
Verb : Verben beschreiben Aktionen, Zustände oder Vorkommen im Text.
DET : Determiner wie Artikel (z. B. "The" "A", "A") geben zusätzliche Informationen zu Substantiven an.
X : Dieses Tag wird häufig für fremde Wörter, Abkürzungen oder andere sprachspezifische Token verwendet, die nicht in die Standard-POS-Kategorien passen.
Propn : Angemessene Substantive, die bestimmte Namen von Personen, Orten, Organisationen oder anderen Unternehmen darstellen.
Adj : Adjektive modifizieren oder beschreiben Substantive und Pronomen.
Pron : Pronomen ersetzen Substantive, wodurch der Text präzise und weniger wiederholt wird.
NUM : Ziffern, die Größen, Daten oder andere numerische Informationen darstellen.
Diese Verteilung von POS -Tags kann Einblicke in die sprachlichen Eigenschaften des Textes liefern, wie z.
import spacy
import matplotlib . pyplot as plt
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform NER on the training dataset
named_entities = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
named_entities . extend ([( ent . text , ent . label_ ) for ent in doc . ents ])
# Count the frequency of each named entity type
ner_counts = Counter ( label for _ , label in named_entities )
# Print the most common named entity types
print ( "Most Common Named Entity Types:" )
for label , count in ner_counts . most_common ( 10 ):
print ( f" { label } : { count } " )
# Visualize the named entity distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( ner_counts . keys (), ner_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Named Entity Type" )
plt . ylabel ( "Frequency" )
plt . title ( "Named Entity Distribution in Wikitext-2 Dataset" )
plt . show ()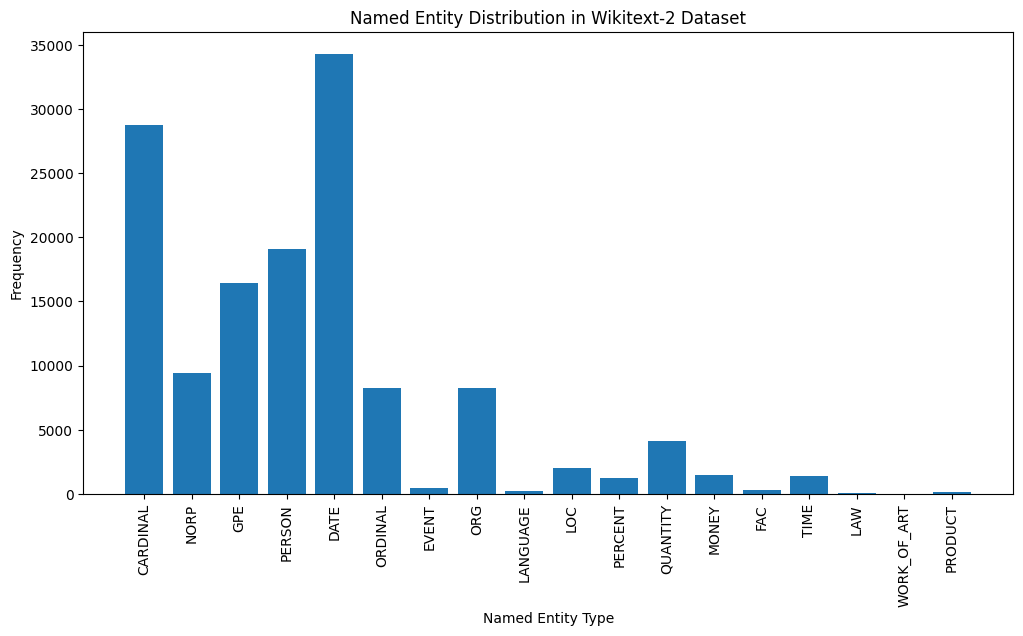
Here's a brief explanation of the most common named entity types in the output:
DATE : Represents specific dates, time periods, or temporal expressions, such as "June 15, 2024" or "last year".
CARDINAL : Includes numerical values, such as quantities, ages, or measurements.
PERSON : Identifies the names of individual people.
GPE (Geopolitical Entity): This entity type represents named geographical locations, such as countries, cities, or states.
NORP (Nationalities, Religious, or Political Groups): This entity type includes named groups or affiliations based on nationality, religion, or political ideology.
ORDINAL : Represents ordinal numbers, such as "first," "second," or "3rd".
ORG (Organization): The names of companies, institutions, or other organized groups.
QUANTITY : Includes non-numeric quantities, such as "a few" or "several".
LOC (Location): Represents named geographical locations, such as continents, regions, or landforms.
MONEY : Identifies monetary values, such as dollar amounts or currency names.
This distribution of named entity types can provide valuable insights into the content and focus of the text. For example, the prominence of DATE and CARDINAL entities may suggest a text that deals with numerical or temporal information, while the prevalence of PERSON, ORG, and GPE entities could indicate a text that discusses people, organizations, and geographical locations.
Understanding the named entity distribution can be useful in a variety of applications, such as information extraction, question answering, and text summarization, where identifying and categorizing key named entities is crucial for understanding the context and content of the text.
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the training dataset
with open ( "data/wiki.train.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Create a string from the entire training dataset
text = " " . join ( train_text )
# Generate the word cloud
wordcloud = WordCloud ( width = 800 , height = 400 , background_color = 'white' ). generate ( text )
# Plot the word cloud
plt . figure ( figsize = ( 12 , 8 ))
plt . imshow ( wordcloud , interpolation = 'bilinear' )
plt . axis ( 'off' )
plt . title ( 'Word Cloud for Wikitext-2 Training Dataset' )
plt . show ()
from sentence_transformers import SentenceTransformer
from sklearn . cluster import KMeans
from collections import defaultdict
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the BERT-based sentence transformer model
model = SentenceTransformer ( 'bert-base-nli-mean-tokens' )
# Load the training dataset
with open ( "data/wiki.valid.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Compute the BERT embeddings for each unique word in the dataset
unique_words = set ( train_text )
word_embeddings = model . encode ( list ( unique_words ))
# Cluster the words using K-Means
num_clusters = 5
kmeans = KMeans ( n_clusters = num_clusters , random_state = 42 )
clusters = kmeans . fit_predict ( word_embeddings )
# Group the words by cluster
word_clusters = defaultdict ( list )
for i , word in enumerate ( unique_words ):
word_clusters [ clusters [ i ]]. append ( word )
# Create a word cloud for each cluster
fig , axes = plt . subplots ( 1 , 5 , figsize = ( 14 , 12 ))
axes = axes . flatten ()
for cluster_id , cluster_words in word_clusters . items ():
word_cloud = WordCloud ( width = 400 , height = 200 , background_color = 'white' ). generate ( ' ' . join ( cluster_words ))
axes [ cluster_id ]. imshow ( word_cloud , interpolation = 'bilinear' )
axes [ cluster_id ]. set_title ( f"Cluster { cluster_id } " )
axes [ cluster_id ]. axis ( 'off' )
plt . subplots_adjust ( wspace = 0.4 , hspace = 0.6 )
plt . tight_layout ()
plt . show ()
The two data formats, N x B x L and M x L , are commonly used in language modeling tasks, particularly in the context of neural network-based models.
N x B x L format:
N represents the number of batches. In this case, the dataset is divided into N smaller batches, which is a common practice to improve the efficiency and stability of the training process.B is the batch size, which represents the number of samples (eg, sentences, paragraphs, or documents) within each batch.L is the length of a sample within each batch, which typically corresponds to the number of tokens (words) in a sample. M x L format:
N x B x L format.M is equal to N x B , which represents the total number of samples (eg, sentences, paragraphs, or documents) in the dataset.L is the length of each sample, which corresponds to the number of tokens (words) in the sample. The choice between these two formats depends on the specific requirements of your language modeling task and the capabilities of the neural network architecture you're working with. If you're training a neural network-based language model, the N x B x L format is typically preferred, as it allows for efficient batch-based training and can lead to faster convergence and better performance. However, if your task doesn't involve neural networks or if the dataset is relatively small, the M x L format may be more suitable.
def prepare_language_model_data ( raw_text_iterator , sequence_length ):
"""
Prepare PyTorch tensors for a language model.
Args:
raw_text_iterator (iterable): An iterator of raw text data.
sequence_length (int): The length of the input and target sequences.
Returns:
tuple: A tuple containing two PyTorch tensors:
- inputs (torch.Tensor): A tensor of input sequences.
- targets (torch.Tensor): A tensor of target sequences.
"""
# Convert the raw text iterator into a single PyTorch tensor
data = torch . cat ([ torch . LongTensor ( vocab ( tokenizer ( line ))) for line in raw_text_iterator ])
# Calculate the number of complete sequences that can be formed
num_sequences = len ( data ) // sequence_length
# Calculate the remainder of the data length divided by the sequence length
remainder = len ( data ) % sequence_length
# If the remainder is 0, add a single <unk> token to the end of the data tensor
if remainder == 0 :
unk_tokens = torch . LongTensor ([ vocab [ '<unk>' ]])
data = torch . cat ([ data , unk_tokens ])
# Extract the input and target sequences from the data tensor
inputs = data [: num_sequences * sequence_length ]. reshape ( - 1 , sequence_length )
targets = data [ 1 : num_sequences * sequence_length + 1 ]. reshape ( - 1 , sequence_length )
print ( len ( inputs ), len ( targets ))
return inputs , targets sequence_length = 30
X_train , y_train = prepare_language_model_data ( train_iter , sequence_length )
X_valid , y_valid = prepare_language_model_data ( valid_iter , sequence_length )
X_test , y_test = prepare_language_model_data ( test_iter , sequence_length )
X_train . shape , y_train . shape , X_valid . shape , y_valid . shape , X_test . shape , y_test . shape
( torch . Size ([ 68333 , 30 ]),
torch . Size ([ 68333 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 8061 , 30 ]),
torch . Size ([ 8061 , 30 ])) This code defines a PyTorch Dataset class for working with language model data. The LanguageModelDataset class takes in input and target tensors and provides the necessary methods for accessing the data.
class LanguageModelDataset ( Dataset ):
def __init__ ( self , inputs , targets ):
self . inputs = inputs
self . targets = targets
def __len__ ( self ):
return self . inputs . shape [ 0 ]
def __getitem__ ( self , idx ):
return self . inputs [ idx ], self . targets [ idx ] The LanguageModelDataset class can be used as follows:
# Create the datasets
train_set = LanguageModelDataset ( X_train , y_train )
valid_set = LanguageModelDataset ( X_valid , y_valid )
test_set = LanguageModelDataset ( X_test , y_test )
# Create data loaders (optional)
train_loader = DataLoader ( train_set , batch_size = 32 , shuffle = True )
valid_loader = DataLoader ( valid_set , batch_size = 32 )
test_loader = DataLoader ( test_set , batch_size = 32 )
# Access the data
x_batch , y_batch = next ( iter ( train_loader ))
print ( f"Input batch shape: { x_batch . shape } " ) # Input batch shape: torch.Size([32, 30])
print ( f"Target batch shape: { y_batch . shape } " ) # Target batch shape: torch.Size([32, 30]) The code defines a custom PyTorch language model that allows you to use different types of word embeddings, including randomly initialized embeddings, pre-trained GloVe embeddings, pre-trained FastText embeddings, by simply specifying the embedding_type argument when creating the model instance.
import torch . nn as nn
from torchtext . vocab import GloVe , FastText
class LanguageModel ( nn . Module ):
def __init__ ( self , vocab_size , embedding_dim ,
hidden_dim , num_layers , dropout_embd = 0.5 ,
dropout_rnn = 0.5 , embedding_type = 'random' ):
super (). __init__ ()
self . num_layers = num_layers
self . hidden_dim = hidden_dim
self . embedding_dim = embedding_dim
self . embedding_type = embedding_type
if embedding_type == 'random' :
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . uniform_ ( - 0.1 , 0.1 )
elif embedding_type == 'glove' :
self . glove = GloVe ( name = '6B' , dim = embedding_dim )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . glove . vectors )
self . embedding . weight . requires_grad = False
elif embedding_type == 'fasttext' :
self . glove = FastText ( language = 'en' )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . fasttext . vectors )
self . embedding . weight . requires_grad = False
else :
raise ValueError ( "Invalid embedding_type. Choose from 'random', 'glove', 'fasttext'." )
self . dropout = nn . Dropout ( p = dropout_embd )
self . lstm = nn . LSTM ( embedding_dim , hidden_dim , num_layers = num_layers ,
dropout = dropout_rnn , batch_first = True )
self . fc = nn . Linear ( hidden_dim , vocab_size )
def forward ( self , src ):
embedding = self . dropout ( self . embedding ( src ))
output , hidden = self . lstm ( embedding )
prediction = self . fc ( output )
return prediction model = LanguageModel ( vocab_size = len ( vocab ),
embedding_dim = 300 ,
hidden_dim = 512 ,
num_layers = 2 ,
dropout_embd = 0.65 ,
dropout_rnn = 0.5 ,
embedding_type = 'glove' ) def num_trainable_params ( model ):
nums = sum ( p . numel () for p in model . parameters () if p . requires_grad ) / 1e6
return nums
# Calculate the number of trainable parameters in the embedding, LSTM, and fully connected layers of the LanguageModel instance 'model'
num_trainable_params ( model . embedding ) # (7.0956)
num_trainable_params ( model . lstm ) # (3.76832)
num_trainable_params ( model . fc ) # (12.133476)

