Torch Linguist
1.0.0

Proyek ini adalah panduan langkah demi langkah untuk membangun model bahasa menggunakan pytorch. Ini bertujuan untuk memberikan pemahaman yang komprehensif tentang proses yang terlibat dalam pengembangan model bahasa dan aplikasinya.
Pemodelan bahasa, atau LM, adalah penggunaan berbagai teknik statistik dan probabilistik untuk menentukan probabilitas urutan kata yang diberikan dalam kalimat. Model bahasa menganalisis badan data teks untuk memberikan dasar prediksi kata mereka.
Pemodelan bahasa digunakan dalam kecerdasan buatan (AI), pemrosesan bahasa alami (NLP), pemahaman bahasa alami (NLU), dan sistem generasi bahasa alami (NLG), terutama yang melakukan pembuatan teks, terjemahan mesin, dan menjawab pertanyaan.
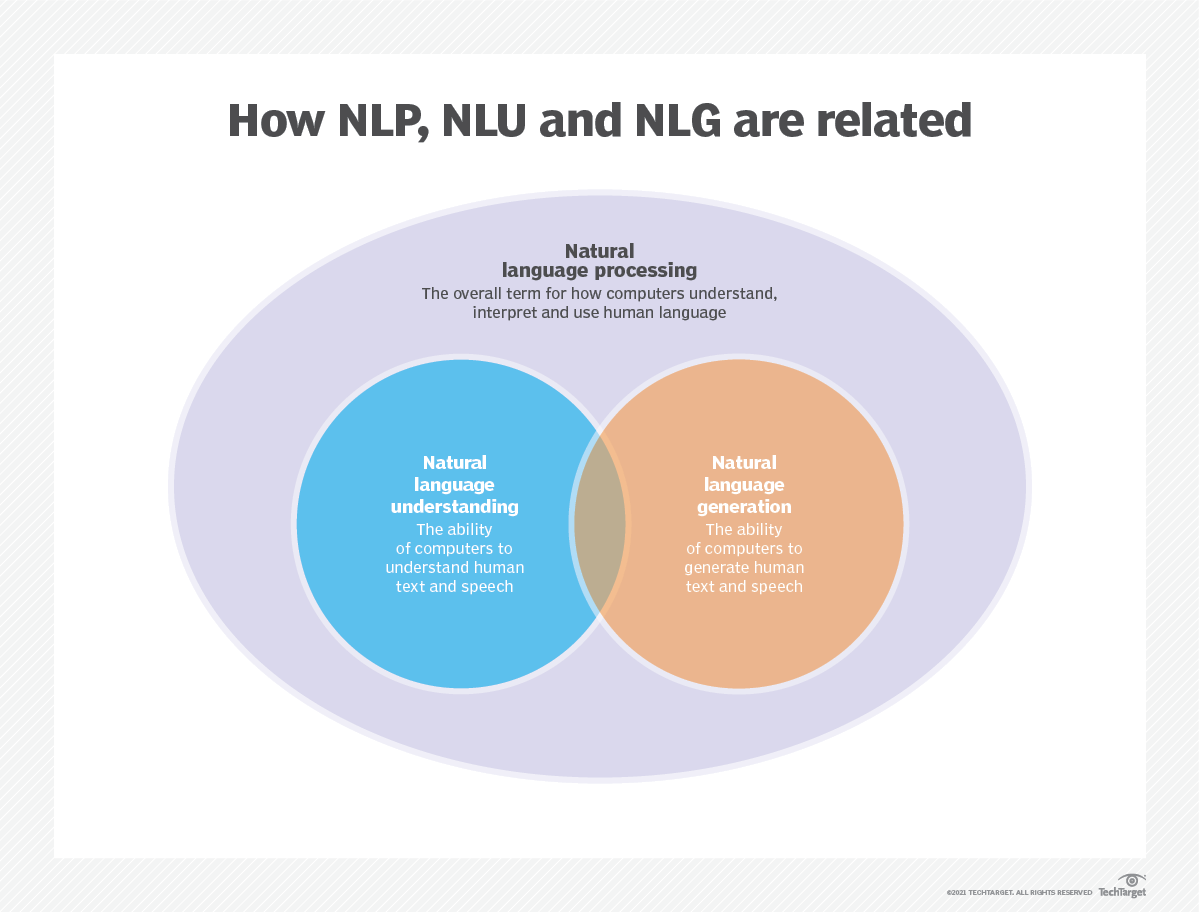
Model bahasa besar (LLM) juga menggunakan pemodelan bahasa. Ini adalah model bahasa canggih, seperti Openai's GPT-3 dan Google Palm 2, yang menangani miliaran parameter data pelatihan dan menghasilkan output teks.
Efektivitas model bahasa biasanya dievaluasi menggunakan metrik seperti cross-entropy dan kebingungan , yang mengukur kemampuan model untuk memprediksi kata berikutnya secara akurat (saya akan membahasnya pada langkah 2 ). Beberapa set data, seperti Wikuxt-2, Wikuxt-103, satu miliar kata, teks8, dan C4, antara lain, umumnya digunakan untuk mengevaluasi model bahasa. CATATAN : Dalam proyek ini, saya menggunakan Wikuxt-2.
Penelitian LM telah menerima perhatian luas dalam literatur, yang dapat dibagi menjadi empat tahap pembangunan utama:
SLM dikembangkan berdasarkan metode pembelajaran statistik yang naik pada 1990 -an. Ide dasarnya adalah untuk membangun model prediksi kata berdasarkan asumsi Markov , misalnya, memprediksi kata berikutnya berdasarkan konteks terbaru. SLM dengan panjang konteks tetap n juga disebut model bahasa n-gram , misalnya model bahasa bigram dan trigram. SLM telah banyak diterapkan untuk meningkatkan kinerja tugas dalam pengambilan informasi (IR) dan pemrosesan bahasa alami (NLP). Namun, mereka sering menderita kutukan dimensi:
Sulit untuk secara akurat memperkirakan model bahasa tingkat tinggi karena jumlah probabilitas transisi yang eksponensial perlu diperkirakan. Dengan demikian, strategi smoothing yang dirancang khusus seperti estimasi back-off dan estimasi yang baik telah diperkenalkan untuk mengurangi masalah sparsity data.
NLMS mencirikan probabilitas sekuens kata oleh jaringan saraf, misalnya, multi-lapisan Perceptron (MLP) dan Recurrent Neural Networks (RNNS). Sebagai kontribusi yang luar biasa, adalah konsep representasi terdistribusi . Representasi terdistribusi, juga dikenal sebagai embeddings , idenya adalah bahwa "makna" atau "konten semantik" dari titik data didistribusikan di berbagai dimensi. Misalnya, dalam NLP, kata -kata dengan makna yang sama dipetakan ke titik -titik di ruang vektor yang dekat satu sama lain. Kedekatan ini tidak sewenang -wenang tetapi dipelajari dari konteks di mana kata -kata muncul. Pembelajaran yang bergantung pada konteks ini sering dicapai melalui model jaringan saraf, seperti Word2Vec atau Glove , yang memproses korpora besar teks untuk mempelajari representasi ini.
Salah satu keuntungan utama dari representasi terdistribusi adalah kemampuan mereka untuk menangkap hubungan semantik berbutir halus. Misalnya, dalam kata embedding kata yang terlatih, sinonim akan diwakili oleh vektor yang berdekatan, dan bahkan mungkin untuk melakukan operasi aritmatika dengan vektor -vektor ini yang sesuai dengan operasi semantik yang bermakna (misalnya, "raja" - "pria" + "wanita" mungkin menghasilkan vektor yang dekat dengan "ratu").
Aplikasi representasi terdistribusi:
Representasi terdistribusi memiliki berbagai aplikasi, terutama dalam tugas yang melibatkan pemahaman bahasa alami. Mereka digunakan untuk:
Kesamaan kata : Mengukur kesamaan semantik antara kata -kata.
Klasifikasi Teks : Mengategorikan dokumen ke dalam kelas yang telah ditentukan.
Terjemahan Mesin : Menerjemahkan teks dari satu bahasa ke bahasa lain.
Pengambilan informasi : Menemukan dokumen yang relevan sebagai tanggapan terhadap kueri.
Analisis Sentimen : Menentukan sentimen yang dinyatakan dalam sepotong teks.
Selain itu, representasi terdistribusi tidak terbatas pada data teks. Mereka juga dapat diterapkan pada jenis data lain, seperti gambar, di mana model pembelajaran mendalam belajar mewakili gambar sebagai vektor dimensi tinggi yang menangkap fitur visual dan semantik.
Model bahasa kausal, juga dikenal sebagai model autoregresif , menghasilkan teks dengan memprediksi kata berikutnya dalam urutan yang diberikan kata -kata sebelumnya. Model -model ini dilatih untuk memaksimalkan kemungkinan kata berikutnya menggunakan teknik seperti arsitektur transformator. Selama pelatihan, input ke model adalah seluruh urutan hingga token yang diberikan, dan tujuan model adalah untuk memprediksi token berikutnya. Jenis model ini berguna untuk tugas -tugas seperti pembuatan teks , penyelesaian , dan ringkasan .
Model Bahasa bertopeng (MLM) dirancang untuk mempelajari representasi kata -kata kontekstual dengan memprediksi kata -kata bertopeng atau hilang dalam sebuah kalimat. Selama pelatihan, sebagian dari urutan input ditutup secara acak, dan model dilatih untuk memprediksi kata -kata asli yang diberikan konteksnya. MLM menggunakan arsitektur dua arah seperti transformator untuk menangkap ketergantungan antara kata -kata bertopeng dan sisa kalimat. Model -model ini unggul dalam tugas -tugas seperti klasifikasi teks , pengakuan entitas yang disebutkan , dan menjawab pertanyaan .
Model Sequence-to-Sequence (SEQ2SEQ) dilatih untuk memetakan urutan input ke urutan output. Mereka terdiri dari enkoder yang memproses urutan input dan dekoder yang menghasilkan urutan output. Model SEQ2SEQ banyak digunakan dalam tugas seperti terjemahan mesin , ringkasan teks , dan sistem dialog . Mereka dapat dilatih menggunakan teknik seperti jaringan saraf berulang (RNNs) atau transformer. Tujuan pelatihan adalah untuk memaksimalkan kemungkinan menghasilkan urutan output yang benar yang diberikan input.
Penting untuk dicatat bahwa pendekatan pelatihan ini tidak saling eksklusif , dan para peneliti sering menggabungkannya atau menggunakan variasi untuk mencapai tujuan spesifik. Misalnya, model seperti T5 menggabungkan tujuan pelatihan model bahasa autoregresif dan bertopeng untuk mempelajari beragam tugas.
Setiap pendekatan pelatihan memiliki kekuatan dan kelemahannya sendiri, dan pilihan model tergantung pada persyaratan tugas spesifik dan data pelatihan yang tersedia.
Untuk informasi lebih lanjut, silakan merujuk ke Panduan A Panduan untuk Model Bahasa Pendekatan Pelatihan Model Bahasa di situs web "Medium.com".
Pemodelan bahasa melibatkan pembuatan model yang dapat menghasilkan atau memprediksi urutan kata atau karakter. Berikut adalah beberapa jenis model yang biasa digunakan untuk pemodelan bahasa:
Dalam model N-gram, probabilitas kata diperkirakan berdasarkan kejadiannya dalam data pelatihan relatif terhadap kata-kata N-1 sebelumnya. Misalnya, dalam model trigram (n = 3), probabilitas sebuah kata ditentukan oleh dua kata yang segera mendahuluinya. Pendekatan ini mengasumsikan bahwa probabilitas sebuah kata hanya bergantung pada sejumlah kata sebelumnya dan tidak mempertimbangkan ketergantungan jarak jauh.
Berikut adalah beberapa contoh n-gram:
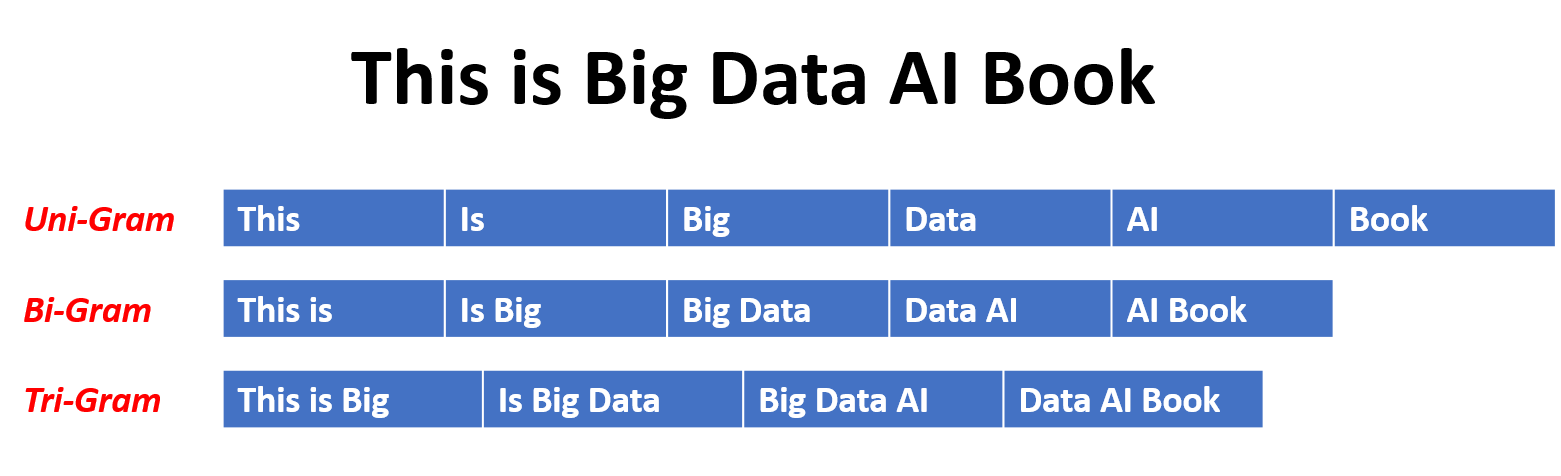
Berikut adalah keuntungan dan kerugian dari model bahasa N-gram:
Keuntungan :
Kerugian :
Berikut adalah contoh menggunakan N-gram di TorchText:
import torchtext
from torchtext . data import get_tokenizer
from torchtext . data . utils import ngrams_iterator
tokenizer = get_tokenizer ( "basic_english" )
# Create a tokenizer object using the "basic_english" tokenizer provided by torchtext
# This tokenizer splits the input text into a list of tokens
tokens = tokenizer ( "I love to code in Python" )
# The result is a list of tokens, where each token represents a word or a punctuation mark
print ( list ( ngrams_iterator ( tokens , 3 )))
[ 'i' , 'love' , 'to' , 'code' , 'in' , 'python' , 'i love' , 'love to' , 'to code' , 'code in' , 'in python' , 'i love to' , 'love to code' , 'to code in' , 'code in python' ]Catatan :
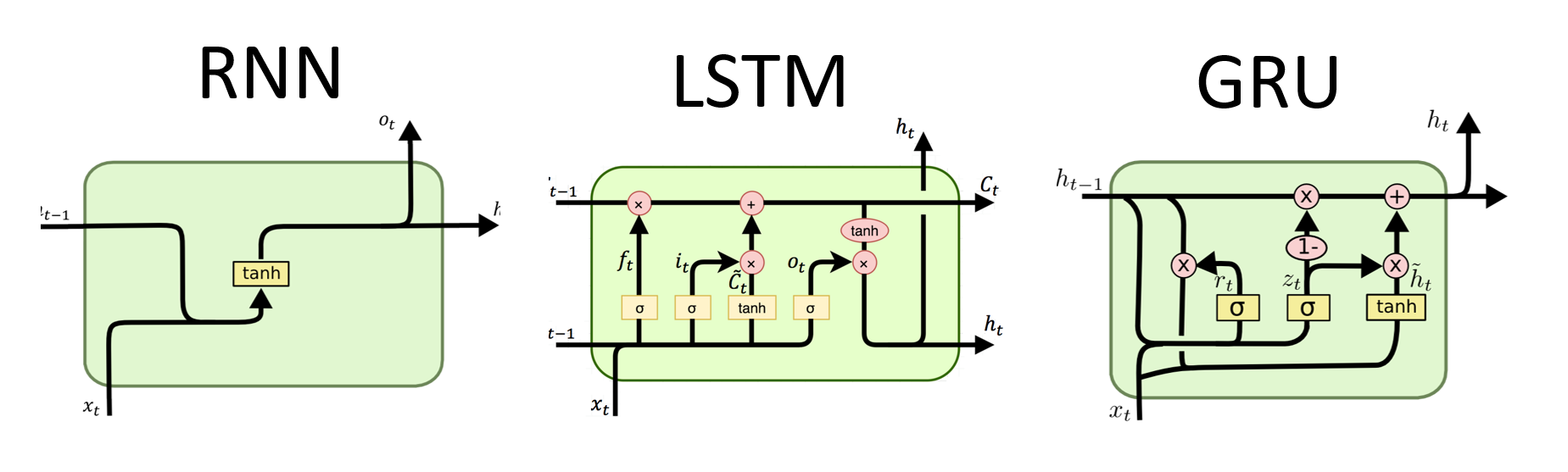
RNN adalah tipe dasar jaringan saraf untuk pemrosesan data berurutan. Mereka memiliki koneksi berulang yang memungkinkan informasi untuk diteruskan dari satu langkah ke langkah berikutnya, memungkinkan mereka untuk menangkap ketergantungan sepanjang waktu. Namun, RNN tradisional menderita masalah gradien menghilang/meledak dan berjuang dengan ketergantungan jangka panjang.
Keuntungan RNNs :
Kerugian RNNs :
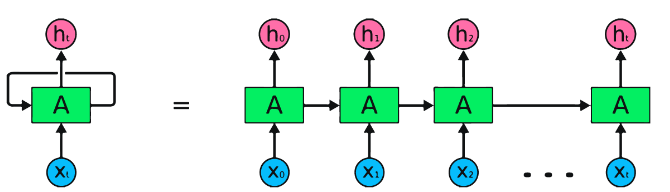
Cuplikan Kode Pytorch untuk mendefinisikan RNN dasar di Pytorch:
import torch
import torch . nn as nn
rnn = nn . RNN ( input_size = 10 , hidden_size = 20 , num_layers = 2 )
# input_size – The number of expected features in the input x
# hidden_size – The number of features in the hidden state h
# num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together
# Create a randomly initialized input tensor
input = torch . randn ( 5 , 3 , 10 ) # (sequence length=5, batch size=3, input size=10)
# Create a randomly initialized hidden state tensor
h0 = torch . randn ( 2 , 3 , 20 ) # (num_layers=2, batch size=3, hidden size=20)
# Apply the RNN module to the input tensor and initial hidden state tensor
output , hn = rnn ( input , h0 )
print ( output . shape ) # torch.Size([5, 3, 20])
# (sequence length=5, batch size=3, hidden size=20)
print ( hn . shape ) # torch.Size([2, 3, 20])
# (num_layers=2, batch size=3, hidden size=20)Keuntungan LSTMS :
Kerugian LSTMS :
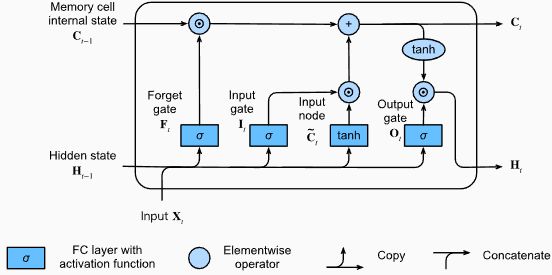
Cuplikan Kode Pytorch untuk mendefinisikan LSTM dasar di Pytorch:
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
lstm = nn . LSTM ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
c0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , ( hn , cn ) = lstm ( input_data , ( h0 , c0 )) Bentuk output dari lapisan LSTM juga akan [seq_length, batch_size, hidden_size] . Ini berarti bahwa untuk setiap input dalam urutan, akan ada keadaan tersembunyi output yang sesuai. Dalam contoh yang disediakan, bentuk output adalah torch.Size([10, 1, 64])
Sekarang, mari kita bahas tensor hn (Hidden State). Bentuknya adalah torch.Size([2, 1, 64]) . Dimensi pertama, 2, mewakili jumlah lapisan di LSTM. Dalam hal ini, argumen num_layers diatur ke 2, jadi ada 2 lapisan dalam model LSTM. Dimensi kedua, 1, sesuai dengan ukuran batch, yaitu 1 dalam contoh yang diberikan. Akhirnya, dimensi terakhir, 64, mewakili ukuran keadaan tersembunyi.
Oleh karena itu, tensor hn berisi keadaan tersembunyi akhir untuk setiap lapisan LSTM setelah memproses seluruh urutan input, mengikuti kemampuan LSTM untuk mempertahankan ketergantungan jangka panjang dan mengurangi masalah gradien menghilang.
Untuk informasi lebih lanjut, silakan merujuk ke bab memori jangka pendek (LSTM) dalam dokumentasi "menyelam ke dalam pembelajaran mendalam".
Keuntungan Grus :
Kerugian Grus :
Secara keseluruhan, model LSTM dan GRU mengatasi beberapa keterbatasan RNN tradisional, terutama dalam menangkap ketergantungan jangka panjang. LSTMS Excel dalam melestarikan informasi kontekstual, sementara Grus menawarkan alternatif yang lebih efisien secara komputasi. Pilihan antara LSTM dan GRU tergantung pada persyaratan spesifik tugas dan sumber daya komputasi yang tersedia.
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
gru = nn . GRU ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , hn = gru ( input_data , h0 ) Bentuk output dari lapisan gru juga akan [seq_length, batch_size, hidden_size] . Ini berarti bahwa untuk setiap input dalam urutan, akan ada keadaan tersembunyi output yang sesuai. Dalam contoh yang disediakan, bentuk output adalah torch.Size([10, 1, 64])
Sekarang, mari kita bahas tensor hn (Hidden State). Bentuknya adalah torch.Size([2, 1, 64]) . Dimensi pertama, 2, mewakili jumlah lapisan dalam gru. Dalam hal ini, argumen num_layers diatur ke 2, jadi ada 2 lapisan dalam model GRU. Dimensi kedua, 1, sesuai dengan ukuran batch, yaitu 1 dalam contoh yang diberikan. Akhirnya, dimensi terakhir, 64, mewakili ukuran keadaan tersembunyi.
Oleh karena itu, tensor hn berisi keadaan tersembunyi akhir untuk setiap lapisan GRU setelah memproses seluruh urutan input, mengikuti kemampuan GRU untuk menangkap dan menyimpan informasi dalam urutan panjang sambil mengurangi masalah gradien menghilang.
Untuk informasi lebih lanjut, silakan merujuk ke bab unit berulang yang terjaga keamanannya (GRU) dalam dokumentasi "menyelam ke dalam pembelajaran yang mendalam".
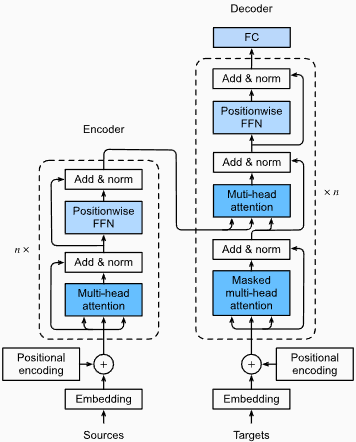
Keuntungan :
Menangkap dependensi jarak jauh: Transformers Excel dalam menangkap ketergantungan jarak jauh dalam urutan dengan menggunakan mekanisme perhatian diri. Ini memungkinkan mereka untuk mempertimbangkan semua posisi dalam urutan input saat membuat prediksi, memungkinkan pemahaman yang lebih baik tentang konteks dan meningkatkan kualitas teks yang dihasilkan.
Pemrosesan Paralel: Tidak seperti model berulang, Transformers dapat memproses urutan input secara paralel, membuatnya sangat efisien dan mengurangi waktu pelatihan dan inferensi. Paralelisasi ini dimungkinkan karena tidak adanya ketergantungan berurutan dalam arsitektur.
Skalabilitas: Transformer sangat terukur dan dapat menangani urutan input yang besar secara efektif. Mereka dapat memproses urutan panjang sewenang -wenang tanpa perlu pemotongan atau bantalan, yang sangat menguntungkan untuk tugas yang melibatkan dokumen atau kalimat panjang.
Pemahaman Kontekstual: Transformers dapat menangkap informasi kontekstual yang kaya dengan menghadiri bagian -bagian yang relevan dari urutan input. Ini memungkinkan mereka untuk memahami struktur linguistik yang kompleks, hubungan semantik, dan ketergantungan antara kata -kata, menghasilkan generasi bahasa yang lebih koheren dan sesuai kontekstual.
Kerugian model transformator :
Persyaratan komputasi yang tinggi: Transformer biasanya membutuhkan sumber daya komputasi yang signifikan dibandingkan dengan model yang lebih sederhana seperti N-gram atau RNN tradisional. Melatih model transformator besar dengan set data yang luas dapat mahal secara komputasi dan memakan waktu.
Kurangnya pemodelan berurutan: Sementara Transformers Excel dalam menangkap ketergantungan global, mereka mungkin tidak seefektif dalam pemodelan data sekuensial yang ketat. Dalam kasus di mana urutan urutan input sangat penting, seperti dalam tugas yang melibatkan data seri-waktu, RNN tradisional atau jaringan saraf konvolusional (CNNs) mungkin lebih cocok.
Kompleksitas mekanisme perhatian: Mekanisme perhatian diri dalam transformer memperkenalkan kompleksitas tambahan pada arsitektur model. Memahami dan menerapkan mekanisme perhatian dengan benar dapat menjadi tantangan, dan tuning hyperparameters yang terkait dengan perhatian bisa non-sepele.
Persyaratan Data: Transformer sering membutuhkan sejumlah besar data pelatihan untuk mencapai kinerja yang optimal. Pretraining pada korpora skala besar, seperti dalam kasus model transformator pretrained seperti GPT dan Bert, adalah umum untuk memanfaatkan kekuatan transformator secara efektif.
Untuk informasi lebih lanjut, silakan merujuk ke bab Arsitektur Transformer dalam dokumentasi "menyelam ke dalam pembelajaran mendalam".
Terlepas dari keterbatasan ini, model transformator telah merevolusi bidang pemrosesan bahasa alami dan pemodelan bahasa. Kemampuan mereka untuk menangkap ketergantungan jarak jauh dan pemahaman kontekstual telah secara signifikan meningkatkan keadaan seni dalam berbagai tugas yang berhubungan dengan bahasa, menjadikan mereka pilihan yang menonjol untuk banyak aplikasi.
Kebingungan, dalam konteks pemodelan bahasa, adalah ukuran yang mengukur seberapa baik model bahasa memprediksi himpunan tes yang diberikan, dengan kebingungan yang lebih rendah menunjukkan kinerja prediktif yang lebih baik. Dalam istilah yang lebih sederhana, kebingungan dihitung dengan mengambil probabilitas terbalik dari set tes dan kemudian menormalkannya dengan jumlah kata.
Semakin rendah nilai kebingungan, semakin baik model bahasa dalam memprediksi set tes. Meminimalkan kebingungan adalah sama dengan memaksimalkan probabilitas
Rumus untuk kebingungan sebagai probabilitas terbalik dari set tes, dinormalisasi dengan jumlah kata, adalah sebagai berikut:
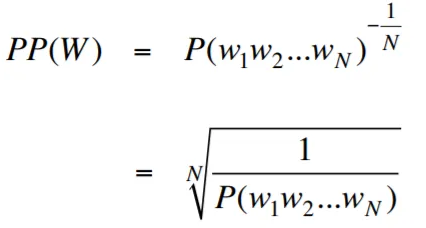

Kebingungan dapat diartikan sebagai ukuran faktor percabangan dalam model bahasa. Faktor percabangan mewakili jumlah rata -rata kata atau token berikutnya yang diberikan konteks atau urutan kata tertentu.
Faktor percabangan suatu bahasa adalah jumlah kata -kata berikutnya yang mungkin yang dapat mengikuti kata apa pun. Kita dapat menganggap kebingungan sebagai faktor percabangan rata -rata berbobot suatu bahasa.
Pemodelan bahasa dengan embedding layer dan kode LSTM adalah alat yang ampuh untuk membangun dan melatih model bahasa. Implementasi kode ini menggabungkan dua komponen mendasar dalam pemrosesan bahasa alami: lapisan penyematan dan jaringan memori jangka pendek (LSTM) yang panjang .
Lapisan embedding bertanggung jawab untuk mengubah data teks menjadi representasi terdistribusi, juga dikenal sebagai kata embeddings . Embeddings ini menangkap sifat semantik dan sintaksis dari kata -kata, yang memungkinkan model untuk memahami makna dan konteks teks input. Lapisan embedding memetakan setiap kata dalam urutan input ke vektor dimensi tinggi, yang berfungsi sebagai input untuk lapisan berikutnya dalam model.
Lapisan LSTM dalam proses implementasi kode kata embeddings yang dihasilkan oleh lapisan embedding, menangkap informasi urutan dan mempelajari pola dan struktur yang mendasari dalam teks.
Dengan menggabungkan jaringan embedding dan jaringan LSTM, kode memungkinkan konstruksi model bahasa yang dapat menghasilkan teks yang koheren dan sesuai kontekstual. Model bahasa yang dibangun menggunakan pendekatan ini dapat dilatih pada set data tekstual besar dan mampu menghasilkan kalimat yang realistis dan bermakna, menjadikannya alat yang berharga untuk berbagai tugas pemrosesan bahasa alami seperti pembuatan teks, terjemahan mesin, dan analisis sentimen.
Implementasi kode ini memberikan fondasi yang sederhana, jelas, dan ringkas untuk membangun model bahasa berdasarkan lapisan embedding dan arsitektur LSTM. Ini berfungsi sebagai titik awal bagi para peneliti, pengembang, dan penggemar yang tertarik untuk mengeksplorasi dan bereksperimen dengan teknik pemodelan bahasa yang canggih.
Melalui kode ini, Anda dapat memperoleh pemahaman yang lebih dalam tentang bagaimana embedding lapisan dan LSTM bekerja bersama untuk menangkap pola dan ketergantungan yang kompleks dalam data teks. Dengan pengetahuan ini, Anda dapat memperluas kode lebih lanjut dan mengeksplorasi teknik canggih, seperti menggabungkan mekanisme perhatian atau arsitektur transformator, untuk meningkatkan kinerja dan kemampuan model bahasa Anda.
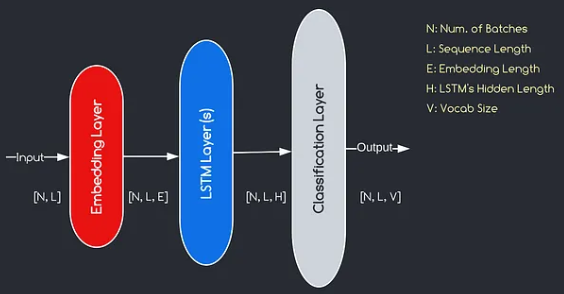
Model yang akan kami buat sesuai dengan diagram yang disediakan di atas, menggambarkan tiga komponen kunci: lapisan penyematan, lapisan LSTM, dan lapisan klasifikasi. Sementara tujuan dari LSTM dan lapisan klasifikasi sudah akrab bagi kita, mari kita selam tentang pentingnya lapisan penyematan.
Lapisan embedding memainkan peran penting dalam model dengan mengubah setiap kata, diwakili sebagai indeks, menjadi vektor dimensi E. Representasi vektor ini memungkinkan lapisan selanjutnya untuk mempelajari dan mengekstrak informasi yang bermakna dari input. Perlu dicatat bahwa menggunakan indeks atau vektor satu-panas untuk mewakili kata-kata bisa tidak memadai karena mereka menganggap tidak ada hubungan antara kata-kata yang berbeda.
Proses pemetaan yang dilakukan oleh lapisan embedding adalah prosedur yang dipelajari yang terjadi selama pelatihan. Melalui fase pelatihan ini, model ini memperoleh kemampuan untuk mengaitkan kata -kata dengan vektor spesifik dengan cara yang menangkap hubungan semantik dan sintaksis, sehingga meningkatkan pemahaman model tentang struktur bahasa yang mendasarinya.
Dataset WKitext-103, yang dikembangkan oleh Salesforce, berisi lebih dari 100 juta token yang diekstraksi dari set artikel yang baik dan unggulan di Wikipedia. Ini memiliki 267.340 token unik yang muncul setidaknya 3 kali dalam dataset. Karena memiliki artikel Wikipedia penuh, dataset sangat cocok untuk tugas yang dapat menguntungkan dependensi jangka panjang, seperti pemodelan bahasa.
Dataset Wikuxt-2 adalah versi kecil dari dataset Wikuxt-103 karena hanya berisi 2 juta token. Dataset kecil ini cocok untuk menguji model bahasa Anda.

Repositori ini berisi kode untuk melakukan analisis data eksplorasi pada dataset UTK, yang terdiri dari gambar yang dikategorikan berdasarkan usia, jenis kelamin, dan etnis.
Untuk mengunduh dataset menggunakan TorchText, Anda dapat menggunakan modul torchtext.datasets . Berikut adalah contoh cara mengunduh dataset wikitext-2 menggunakan TorchText:
import torchtext
from torchtext . datasets import WikiText2
data_path = "data"
train_iter , valid_iter , test_iter = WikiText2 ( root = data_path ) Awalnya, saya mencoba menggunakan kode yang disediakan untuk memuat dataset Wikuxt-2, tetapi mengalami masalah dengan URL (https://s3.amazonaws-2-v1.zip) tidak berfungsi untuk saya. Untuk mengatasi ini, saya memutuskan untuk memanfaatkan Pustaka torchtext dan membuat implementasi kustom dari dataset loader.
Karena URL asli tidak berfungsi, saya mengunduh kereta, validasi, dan pengujian set data dari repositori GitHub dan menempatkannya di direktori 'data/datasets/WikiText2' .
Berikut ini rincian kode:
import os
from typing import Union , Tuple
from torchdata . datapipes . iter import FileOpener , IterableWrapper
from torchtext . data . datasets_utils import _wrap_split_argument , _create_dataset_directory
DATA_DIR = "data"
NUM_LINES = {
"train" : 36718 ,
"valid" : 3760 ,
"test" : 4358 ,
}
DATASET_NAME = "WikiText2"
_EXTRACTED_FILES = {
"train" : "wiki.train.tokens" ,
"test" : "wiki.test.tokens" ,
"valid" : "wiki.valid.tokens" ,
}
def _filepath_fn ( root , split ):
return os . path . join ( root , _EXTRACTED_FILES [ split ])
@ _create_dataset_directory ( dataset_name = DATASET_NAME )
@ _wrap_split_argument (( "train" , "valid" , "test" ))
def WikiText2 ( root : str , split : Union [ Tuple [ str ], str ]):
url_dp = IterableWrapper ([ _filepath_fn ( DATA_DIR , split )])
data_dp = FileOpener ( url_dp , encoding = "utf-8" ). readlines ( strip_newline = False , return_path = False ). shuffle (). set_shuffle ( False ). sharding_filter ()
return data_dp Untuk menggunakan witurext-2 dataset loader, cukup impor fungsi wikitext2 dan panggil dengan data yang diinginkan split:
train_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "train" )
valid_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "valid" )
test_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "test" )Implementasi ini terinspirasi oleh loader Dataset TorchText resmi, dan memanfaatkan pustaka TorchData dan TorchText untuk memberikan pengalaman pemuatan data yang mulus dan efisien.
Membangun kosakata adalah langkah penting dalam banyak tugas pemrosesan bahasa alami, karena memungkinkan Anda untuk mewakili kata -kata sebagai pengidentifikasi unik yang dapat digunakan dalam model pembelajaran mesin. Dokumen Markdown ini menunjukkan cara membangun kosakata dari serangkaian data pelatihan dan menyimpannya untuk penggunaan di masa depan.
Berikut adalah fungsi yang merangkum proses membangun dan menyimpan kosakata:
import torch
from torchtext . data . utils import get_tokenizer
from torchtext . vocab import build_vocab_from_iterator
def build_and_save_vocabulary ( train_iter , vocab_path = 'vocab.pt' , min_freq = 4 ):
"""
Build a vocabulary from the training data iterator and save it to a file.
Args:
train_iter (iterator): An iterator over the training data.
vocab_path (str, optional): The path to save the vocabulary file. Defaults to 'vocab.pt'.
min_freq (int, optional): The minimum frequency of a word to be included in the vocabulary. Defaults to 4.
Returns:
torchtext.vocab.Vocab: The built vocabulary.
"""
# Get the tokenizer
tokenizer = get_tokenizer ( "basic_english" )
# Build the vocabulary
vocab = build_vocab_from_iterator ( map ( tokenizer , train_iter ), specials = [ '<unk>' ], min_freq = min_freq )
# Set the default index to the unknown token
vocab . set_default_index ( vocab [ '<unk>' ])
# Save the vocabulary
torch . save ( vocab , vocab_path )
return vocabInilah cara Anda dapat menggunakan fungsi ini:
# Assuming you have a training data iterator named `train_iter`
vocab = build_and_save_vocabulary ( train_iter , vocab_path = 'my_vocab.pt' )
# You can now use the vocabulary
print ( len ( vocab )) # 23652
print ( vocab ([ 'ebi' , 'AI' . lower (), 'qwerty' ])) # [0, 1973, 0] build_and_save_vocabulary mengambil tiga argumen: train_iter (iterator atas data pelatihan), vocab_path (jalur untuk menyimpan file kosa kata, dengan default 'vocab.pt'), dan min_freq (frekuensi minimum dari kata yang akan dimasukkan dalam vocabulary, dengan default 4).basic_english , yang melakukan tokenisasi dasar pada teks bahasa Inggris.build_vocab_from_iterator , melewati Iterator Data Pelatihan (setelah tokenisasi) dan menentukan token khusus '<unk>' dan ambang batas frekuensi minimum.'<unk>' , yang berarti bahwa kata apa pun yang tidak ditemukan dalam kosa kata akan dipetakan ke token yang tidak diketahui. Untuk menggunakan fungsi ini, Anda perlu memiliki iterator data pelatihan bernama train_iter . Kemudian, Anda dapat memanggil fungsi build_and_save_vocabulary , melewati train_iter dan menentukan jalur file kosa kata yang diinginkan dan ambang batas frekuensi minimum.
Fungsi ini akan membangun kosa kata, menyimpannya ke file yang ditentukan, dan mengembalikan objek Vocab , yang kemudian dapat Anda gunakan dalam tugas hilir Anda.
Kode ini menyediakan cara untuk menganalisis panjang kalimat rata-rata dalam dataset Wikuxt-2. Berikut ini rincian kode:
import matplotlib . pyplot as plt
def compute_mean_sentence_length ( data_iter ):
"""
Computes the mean sentence length for the given data iterator.
Args:
data_iter (iterable): An iterable of text data, where each element is a string representing a line of text.
Returns:
float: The mean sentence length.
"""
total_sentence_count = 0
total_sentence_length = 0
for line in data_iter :
sentences = line . split ( '.' ) # Split the line into individual sentences
for sentence in sentences :
tokens = sentence . strip (). split () # Tokenize the sentence
sentence_length = len ( tokens )
if sentence_length > 0 :
total_sentence_count += 1
total_sentence_length += sentence_length
mean_sentence_length = total_sentence_length / total_sentence_count
return mean_sentence_length
# Compute mean sentence length for each dataset
train_mean = compute_mean_sentence_length ( train_iter )
valid_mean = compute_mean_sentence_length ( valid_iter )
test_mean = compute_mean_sentence_length ( test_iter )
# Plot the results
datasets = [ 'Train' , 'Valid' , 'Test' ]
means = [ train_mean , valid_mean , test_mean ]
plt . figure ( figsize = ( 6 , 4 ))
plt . bar ( datasets , means )
plt . xlabel ( 'Dataset' )
plt . ylabel ( 'Mean Sentence Length' )
plt . title ( 'Mean Sentence Length in Wikitext-2' )
plt . grid ( True )
plt . show ()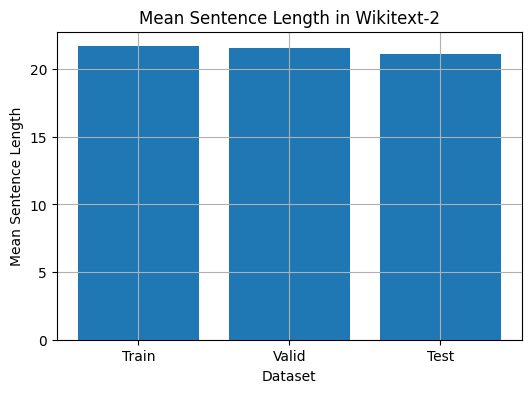
from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Find the 10 least common words
least_common_words = freqs . most_common ()[: - 11 : - 1 ]
print ( "Least Common Words:" )
for word , count in least_common_words :
print ( f" { word } : { count } " )
# Find the 10 most common words
most_common_words = freqs . most_common ( 10 )
print ( " n Most Common Words:" )
for word , count in most_common_words :
print ( f" { word } : { count } " ) from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Count the number of words that repeat 3, 4, and 5 times
count_3 = count_4 = count_5 = 0
for word , freq in freqs . items ():
if freq == 3 :
count_3 += 1
elif freq == 4 :
count_4 += 1
elif freq == 5 :
count_5 += 1
print ( f"Number of words that appear 3 times: { count_3 } " ) # 5130
print ( f"Number of words that appear 4 times: { count_4 } " ) # 3243
print ( f"Number of words that appear 5 times: { count_5 } " ) # 2261 from collections import Counter
import matplotlib . pyplot as plt
# Compute the word lengths in the training dataset
word_lengths = []
for tokens in map ( tokenizer , train_iter ):
word_lengths . extend ( len ( word ) for word in tokens )
# Create a frequency distribution of word lengths
word_length_counts = Counter ( word_lengths )
# Plot the word length distribution
plt . figure ( figsize = ( 10 , 6 ))
plt . bar ( word_length_counts . keys (), word_length_counts . values ())
plt . xlabel ( "Word Length" )
plt . ylabel ( "Frequency" )
plt . title ( "Word Length Distribution in Wikitext-2 Dataset" )
plt . show ()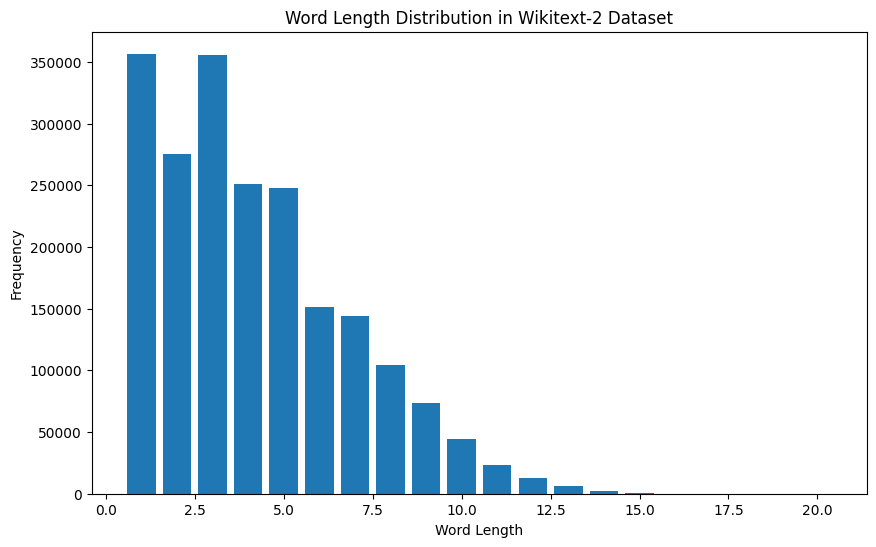
import spacy
import en_core_web_sm
# Load the small English language model from SpaCy
nlp = spacy . load ( "en_core_web_sm" )
# Alternatively, you can use the en_core_web_sm module to load the model
nlp = en_core_web_sm . load ()
# Process the given sentence using the loaded language model
doc = nlp ( "This is a sentence." )
# Print the text and part-of-speech tag for each token in the sentence
print ([( w . text , w . pos_ ) for w in doc ])
# [('This', 'PRON'), ('is', 'AUX'), ('a', 'DET'), ('sentence', 'NOUN'), ('.', 'PUNCT')]Untuk dataset wikitext-2:
import spacy
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform POS tagging on the training dataset
pos_tags = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
pos_tags . extend ([( token . text , token . pos_ ) for token in doc ])
# Count the frequency of each POS tag
pos_tag_counts = Counter ( tag for _ , tag in pos_tags )
# Print the most common POS tags
print ( "Most Common Part-of-Speech Tags:" )
for tag , count in pos_tag_counts . most_common ( 10 ):
print ( f" { tag } : { count } " )
# Visualize the POS tag distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( pos_tag_counts . keys (), pos_tag_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Part-of-Speech Tag" )
plt . ylabel ( "Frequency" )
plt . title ( "Part-of-Speech Tag Distribution in Wikitext-2 Dataset" )
plt . show ()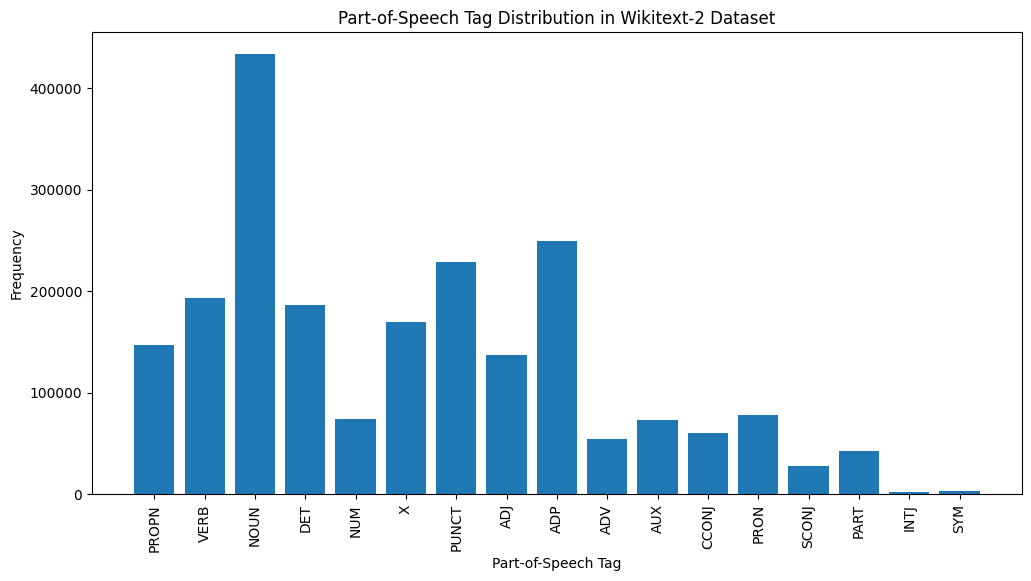
Berikut penjelasan singkat tentang tag POS yang paling umum dalam output yang disediakan:
Kata benda : Kata benda mewakili orang, tempat, benda, atau ide.
ADP : Adposisi, seperti preposisi dan postposisi, digunakan untuk mengekspresikan hubungan antara kata atau frasa.
Punct : Tanda baca, yang penting untuk memisahkan dan menyusun kalimat dan teks.
Kata kerja : Kata kerja menggambarkan tindakan, negara, atau kejadian dalam teks.
DET : Penentu, seperti artikel (misalnya, "The," "a," "an"), memberikan informasi tambahan tentang kata benda.
X : Tag ini sering digunakan untuk kata-kata asing, singkatan, atau token khusus bahasa lainnya yang tidak cocok dengan kategori POS standar.
Propn : Kata benda yang tepat, yang mewakili nama orang, tempat, organisasi, atau entitas lainnya.
Adj : Kata sifat memodifikasi atau menjelaskan kata benda dan kata ganti.
Pron : Pronoun menggantikan kata benda, membuat teks lebih ringkas dan kurang berulang.
NUM : Angka, yang mewakili jumlah, tanggal, atau informasi numerik lainnya.
Distribusi tag POS ini dapat memberikan wawasan tentang karakteristik linguistik teks, seperti dominasi kata benda, prevalensi adposisi, atau penggunaan kata benda yang tepat, yang dapat membantu dalam tugas -tugas seperti klasifikasi teks, ekstraksi informasi, atau analisis stylometrik.
import spacy
import matplotlib . pyplot as plt
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform NER on the training dataset
named_entities = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
named_entities . extend ([( ent . text , ent . label_ ) for ent in doc . ents ])
# Count the frequency of each named entity type
ner_counts = Counter ( label for _ , label in named_entities )
# Print the most common named entity types
print ( "Most Common Named Entity Types:" )
for label , count in ner_counts . most_common ( 10 ):
print ( f" { label } : { count } " )
# Visualize the named entity distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( ner_counts . keys (), ner_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Named Entity Type" )
plt . ylabel ( "Frequency" )
plt . title ( "Named Entity Distribution in Wikitext-2 Dataset" )
plt . show ()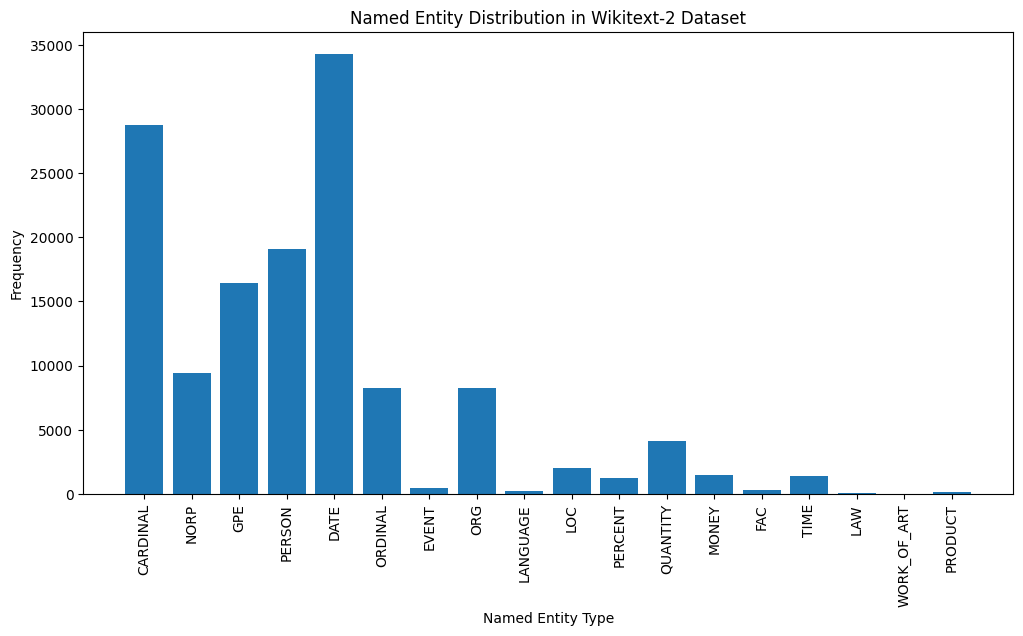
Here's a brief explanation of the most common named entity types in the output:
DATE : Represents specific dates, time periods, or temporal expressions, such as "June 15, 2024" or "last year".
CARDINAL : Includes numerical values, such as quantities, ages, or measurements.
PERSON : Identifies the names of individual people.
GPE (Geopolitical Entity): This entity type represents named geographical locations, such as countries, cities, or states.
NORP (Nationalities, Religious, or Political Groups): This entity type includes named groups or affiliations based on nationality, religion, or political ideology.
ORDINAL : Represents ordinal numbers, such as "first," "second," or "3rd".
ORG (Organization): The names of companies, institutions, or other organized groups.
QUANTITY : Includes non-numeric quantities, such as "a few" or "several".
LOC (Location): Represents named geographical locations, such as continents, regions, or landforms.
MONEY : Identifies monetary values, such as dollar amounts or currency names.
This distribution of named entity types can provide valuable insights into the content and focus of the text. For example, the prominence of DATE and CARDINAL entities may suggest a text that deals with numerical or temporal information, while the prevalence of PERSON, ORG, and GPE entities could indicate a text that discusses people, organizations, and geographical locations.
Understanding the named entity distribution can be useful in a variety of applications, such as information extraction, question answering, and text summarization, where identifying and categorizing key named entities is crucial for understanding the context and content of the text.
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the training dataset
with open ( "data/wiki.train.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Create a string from the entire training dataset
text = " " . join ( train_text )
# Generate the word cloud
wordcloud = WordCloud ( width = 800 , height = 400 , background_color = 'white' ). generate ( text )
# Plot the word cloud
plt . figure ( figsize = ( 12 , 8 ))
plt . imshow ( wordcloud , interpolation = 'bilinear' )
plt . axis ( 'off' )
plt . title ( 'Word Cloud for Wikitext-2 Training Dataset' )
plt . show ()
from sentence_transformers import SentenceTransformer
from sklearn . cluster import KMeans
from collections import defaultdict
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the BERT-based sentence transformer model
model = SentenceTransformer ( 'bert-base-nli-mean-tokens' )
# Load the training dataset
with open ( "data/wiki.valid.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Compute the BERT embeddings for each unique word in the dataset
unique_words = set ( train_text )
word_embeddings = model . encode ( list ( unique_words ))
# Cluster the words using K-Means
num_clusters = 5
kmeans = KMeans ( n_clusters = num_clusters , random_state = 42 )
clusters = kmeans . fit_predict ( word_embeddings )
# Group the words by cluster
word_clusters = defaultdict ( list )
for i , word in enumerate ( unique_words ):
word_clusters [ clusters [ i ]]. append ( word )
# Create a word cloud for each cluster
fig , axes = plt . subplots ( 1 , 5 , figsize = ( 14 , 12 ))
axes = axes . flatten ()
for cluster_id , cluster_words in word_clusters . items ():
word_cloud = WordCloud ( width = 400 , height = 200 , background_color = 'white' ). generate ( ' ' . join ( cluster_words ))
axes [ cluster_id ]. imshow ( word_cloud , interpolation = 'bilinear' )
axes [ cluster_id ]. set_title ( f"Cluster { cluster_id } " )
axes [ cluster_id ]. axis ( 'off' )
plt . subplots_adjust ( wspace = 0.4 , hspace = 0.6 )
plt . tight_layout ()
plt . show ()
The two data formats, N x B x L and M x L , are commonly used in language modeling tasks, particularly in the context of neural network-based models.
N x B x L format:
N represents the number of batches. In this case, the dataset is divided into N smaller batches, which is a common practice to improve the efficiency and stability of the training process.B is the batch size, which represents the number of samples (eg, sentences, paragraphs, or documents) within each batch.L is the length of a sample within each batch, which typically corresponds to the number of tokens (words) in a sample. M x L format:
N x B x L format.M is equal to N x B , which represents the total number of samples (eg, sentences, paragraphs, or documents) in the dataset.L is the length of each sample, which corresponds to the number of tokens (words) in the sample. The choice between these two formats depends on the specific requirements of your language modeling task and the capabilities of the neural network architecture you're working with. If you're training a neural network-based language model, the N x B x L format is typically preferred, as it allows for efficient batch-based training and can lead to faster convergence and better performance. However, if your task doesn't involve neural networks or if the dataset is relatively small, the M x L format may be more suitable.
def prepare_language_model_data ( raw_text_iterator , sequence_length ):
"""
Prepare PyTorch tensors for a language model.
Args:
raw_text_iterator (iterable): An iterator of raw text data.
sequence_length (int): The length of the input and target sequences.
Returns:
tuple: A tuple containing two PyTorch tensors:
- inputs (torch.Tensor): A tensor of input sequences.
- targets (torch.Tensor): A tensor of target sequences.
"""
# Convert the raw text iterator into a single PyTorch tensor
data = torch . cat ([ torch . LongTensor ( vocab ( tokenizer ( line ))) for line in raw_text_iterator ])
# Calculate the number of complete sequences that can be formed
num_sequences = len ( data ) // sequence_length
# Calculate the remainder of the data length divided by the sequence length
remainder = len ( data ) % sequence_length
# If the remainder is 0, add a single <unk> token to the end of the data tensor
if remainder == 0 :
unk_tokens = torch . LongTensor ([ vocab [ '<unk>' ]])
data = torch . cat ([ data , unk_tokens ])
# Extract the input and target sequences from the data tensor
inputs = data [: num_sequences * sequence_length ]. reshape ( - 1 , sequence_length )
targets = data [ 1 : num_sequences * sequence_length + 1 ]. reshape ( - 1 , sequence_length )
print ( len ( inputs ), len ( targets ))
return inputs , targets sequence_length = 30
X_train , y_train = prepare_language_model_data ( train_iter , sequence_length )
X_valid , y_valid = prepare_language_model_data ( valid_iter , sequence_length )
X_test , y_test = prepare_language_model_data ( test_iter , sequence_length )
X_train . shape , y_train . shape , X_valid . shape , y_valid . shape , X_test . shape , y_test . shape
( torch . Size ([ 68333 , 30 ]),
torch . Size ([ 68333 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 8061 , 30 ]),
torch . Size ([ 8061 , 30 ])) This code defines a PyTorch Dataset class for working with language model data. The LanguageModelDataset class takes in input and target tensors and provides the necessary methods for accessing the data.
class LanguageModelDataset ( Dataset ):
def __init__ ( self , inputs , targets ):
self . inputs = inputs
self . targets = targets
def __len__ ( self ):
return self . inputs . shape [ 0 ]
def __getitem__ ( self , idx ):
return self . inputs [ idx ], self . targets [ idx ] The LanguageModelDataset class can be used as follows:
# Create the datasets
train_set = LanguageModelDataset ( X_train , y_train )
valid_set = LanguageModelDataset ( X_valid , y_valid )
test_set = LanguageModelDataset ( X_test , y_test )
# Create data loaders (optional)
train_loader = DataLoader ( train_set , batch_size = 32 , shuffle = True )
valid_loader = DataLoader ( valid_set , batch_size = 32 )
test_loader = DataLoader ( test_set , batch_size = 32 )
# Access the data
x_batch , y_batch = next ( iter ( train_loader ))
print ( f"Input batch shape: { x_batch . shape } " ) # Input batch shape: torch.Size([32, 30])
print ( f"Target batch shape: { y_batch . shape } " ) # Target batch shape: torch.Size([32, 30]) The code defines a custom PyTorch language model that allows you to use different types of word embeddings, including randomly initialized embeddings, pre-trained GloVe embeddings, pre-trained FastText embeddings, by simply specifying the embedding_type argument when creating the model instance.
import torch . nn as nn
from torchtext . vocab import GloVe , FastText
class LanguageModel ( nn . Module ):
def __init__ ( self , vocab_size , embedding_dim ,
hidden_dim , num_layers , dropout_embd = 0.5 ,
dropout_rnn = 0.5 , embedding_type = 'random' ):
super (). __init__ ()
self . num_layers = num_layers
self . hidden_dim = hidden_dim
self . embedding_dim = embedding_dim
self . embedding_type = embedding_type
if embedding_type == 'random' :
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . uniform_ ( - 0.1 , 0.1 )
elif embedding_type == 'glove' :
self . glove = GloVe ( name = '6B' , dim = embedding_dim )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . glove . vectors )
self . embedding . weight . requires_grad = False
elif embedding_type == 'fasttext' :
self . glove = FastText ( language = 'en' )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . fasttext . vectors )
self . embedding . weight . requires_grad = False
else :
raise ValueError ( "Invalid embedding_type. Choose from 'random', 'glove', 'fasttext'." )
self . dropout = nn . Dropout ( p = dropout_embd )
self . lstm = nn . LSTM ( embedding_dim , hidden_dim , num_layers = num_layers ,
dropout = dropout_rnn , batch_first = True )
self . fc = nn . Linear ( hidden_dim , vocab_size )
def forward ( self , src ):
embedding = self . dropout ( self . embedding ( src ))
output , hidden = self . lstm ( embedding )
prediction = self . fc ( output )
return prediction model = LanguageModel ( vocab_size = len ( vocab ),
embedding_dim = 300 ,
hidden_dim = 512 ,
num_layers = 2 ,
dropout_embd = 0.65 ,
dropout_rnn = 0.5 ,
embedding_type = 'glove' ) def num_trainable_params ( model ):
nums = sum ( p . numel () for p in model . parameters () if p . requires_grad ) / 1e6
return nums
# Calculate the number of trainable parameters in the embedding, LSTM, and fully connected layers of the LanguageModel instance 'model'
num_trainable_params ( model . embedding ) # (7.0956)
num_trainable_params ( model . lstm ) # (3.76832)
num_trainable_params ( model . fc ) # (12.133476)

