Torch Linguist
1.0.0

هذا المشروع هو دليل خطوة بخطوة لبناء نموذج لغة باستخدام Pytorch. ويهدف إلى توفير فهم شامل للعملية التي ينطوي عليها تطوير نموذج لغة وتطبيقاته.
نمذجة اللغة ، أو LM ، هي استخدام التقنيات الإحصائية والاحتمالية المختلفة لتحديد احتمال حدوث تسلسل معين من الكلمات التي تحدث في جملة. تحلل نماذج اللغة أجسام البيانات النصية لتوفير أساس لتنبؤات كلماتها.
يتم استخدام نمذجة اللغة في الذكاء الاصطناعي (AI) ، ومعالجة اللغة الطبيعية (NLP) ، وفهم اللغة الطبيعية (NLU) ، وأنظمة توليد اللغة الطبيعية (NLG) ، وخاصة تلك التي تؤدي توليد النص والترجمة الآلية والإجابة على الأسئلة.
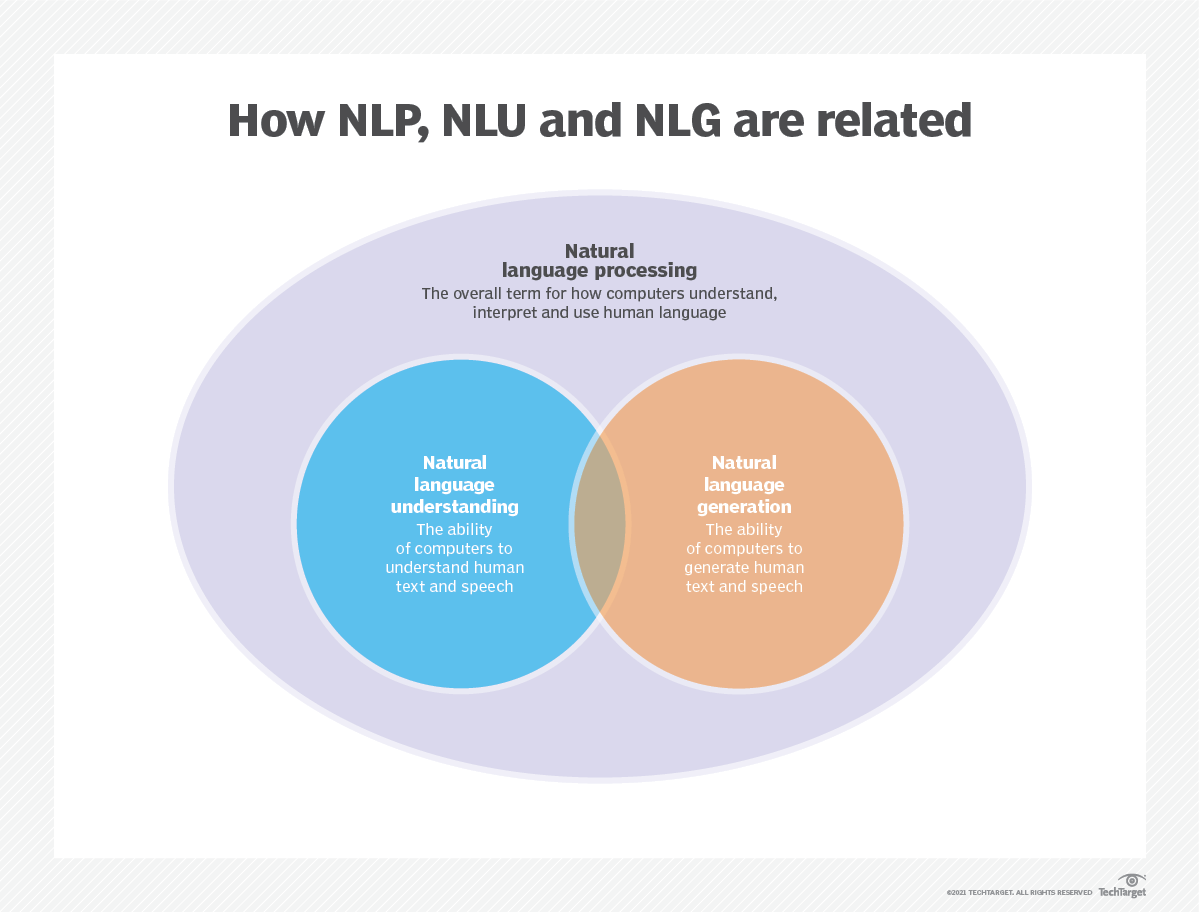
تستخدم نماذج اللغة الكبيرة (LLMS) أيضًا نمذجة اللغة. هذه نماذج لغة متقدمة ، مثل GPT-3 من Openai و Google Palm 2 ، والتي تتعامل مع مليارات من معلمات بيانات التدريب وإنشاء إخراج النص.
عادة ما يتم تقييم فعالية نموذج اللغة باستخدام مقاييس مثل الإدخال المتقاطع والحيرة ، والتي تقيس قدرة النموذج على التنبؤ بالكلمة التالية بدقة (سأغطيها في الخطوة 2 ). يتم استخدام العديد من مجموعات البيانات ، مثل Wikitext-2 و Wikitext-103 و مليار كلمة و Text8 و C4 ، من بين أمور أخرى ، لتقييم نماذج اللغة. ملاحظة : في هذا المشروع ، أستخدم Wikitext-2.
تلقى بحث LM اهتمامًا كبيرًا في الأدبيات ، والتي يمكن تقسيمها إلى أربع مراحل تنمية رئيسية:
تم تطوير SLMS بناءً على أساليب التعلم الإحصائية التي ارتفعت في التسعينيات. الفكرة الأساسية هي بناء نموذج التنبؤ كلمة بناءً على افتراض Markov ، على سبيل المثال ، التنبؤ بالكلمة التالية بناءً على سياق أحدث. تسمى SLMs ذات طول السياق الثابت N أيضًا نماذج لغة N-Gram ، على سبيل المثال ، نماذج لغة BigRam و Trigram. تم تطبيق SLMs على نطاق واسع لتعزيز أداء المهمة في استرجاع المعلومات (IR) ومعالجة اللغة الطبيعية (NLP). ومع ذلك ، فإنهم في كثير من الأحيان يعانون من لعنة الأبعاد:
من الصعب تقدير نماذج اللغة عالية الترتيب بدقة حيث يجب تقدير عدد كبير من احتمالات الانتقال. وبالتالي ، تم تقديم استراتيجيات تجانس مصممة خصيصًا مثل التقدير التراقي والتقدير الجيد للتخفيف من مشكلة تباين البيانات.
تميز NLMS احتمال تسلسل الكلمات بواسطة الشبكات العصبية ، مثل ، Perceptron متعدد الطبقات (MLP) والشبكات العصبية المتكررة (RNNs). كمساهمة ملحوظة ، هو مفهوم التمثيل الموزع . تمثل الفكرة أن التمثيلات الموزعة ، والمعروفة أيضًا باسم التضمينات ، هي أن "المعنى" أو "المحتوى الدلالي" لنقطة البيانات يتم توزيعه عبر أبعاد متعددة. على سبيل المثال ، في NLP ، يتم تعيين الكلمات ذات المعاني المماثلة إلى نقاط في مساحة المتجه القريبة من بعضها البعض. هذا التقارب ليس تعسفيًا ولكن يتم تعلمه من السياق الذي تظهر فيه الكلمات. غالبًا ما يتم تحقيق هذا التعلم المعتمد على السياق من خلال نماذج الشبكة العصبية ، مثل Word2Vec أو Glove ، والتي تعالج شركة كبيرة من النص لتعلم هذه العروض.
واحدة من المزايا الرئيسية للتمثيل الموزعة هي قدرتها على التقاط علاقات دلالية الحبيبات الدقيقة. على سبيل المثال ، في مساحة تضمين الكلمات المدربة جيدًا ، سيتم تمثيل المرادفات من قبل متجهات قريبة من بعضها البعض ، ومن الممكن حتى إجراء عمليات حسابية مع هذه المتجهات التي تتوافق مع العمليات الدلالية ذات معنى (على سبيل المثال ، "King" - "Man" + "المرأة" قد تؤدي إلى ناقل بالقرب من "الملكة").
تطبيقات التمثيل الموزع:
التمثيلات الموزعة لها مجموعة واسعة من التطبيقات ، وخاصة في المهام التي تنطوي على فهم اللغة الطبيعية. يتم استخدامها لـ:
تشابه الكلمة : قياس التشابه الدلالي بين الكلمات.
تصنيف النص : تصنيف المستندات في فصول محددة مسبقًا.
الترجمة الآلية : ترجمة النص من لغة إلى أخرى.
استرجاع المعلومات : العثور على المستندات ذات الصلة استجابةً للاستعلام.
تحليل المشاعر : تحديد المشاعر المعبر عنها في نص.
علاوة على ذلك ، لا تقتصر التمثيلات الموزعة على بيانات النص. يمكن أيضًا تطبيقها على أنواع أخرى من البيانات ، مثل الصور ، حيث تتعلم نماذج التعلم العميق تمثيل الصور كناقلات عالية الأبعاد تلتقط الميزات المرئية والدلالات.
تنشئ نماذج اللغة السببية ، والمعروفة أيضًا باسم النماذج التلقائية ، النص عن طريق التنبؤ بالكلمة التالية في تسلسل بالنظر إلى الكلمات السابقة. يتم تدريب هذه النماذج على زيادة احتمالية الكلمة التالية باستخدام تقنيات مثل بنية المحولات. أثناء التدريب ، يكون المدخلات في النموذج هو التسلسل بالكامل حتى رمزًا معينًا ، وهدف النموذج هو التنبؤ بالرمز التالي. هذا النوع من النماذج مفيد للمهام مثل توليد النص والإنجاز والتلخيص .
تم تصميم نماذج اللغة المقنعة (MLMs) لتعلم تمثيلات السياق للكلمات من خلال التنبؤ بالكلمات المقنعة أو المفقودة في جملة. أثناء التدريب ، يتم حجب جزء من تسلسل الإدخال بشكل عشوائي ، ويتم تدريب النموذج على التنبؤ بالكلمات الأصلية بالنظر إلى السياق. تستخدم MLMs هياكل ثنائية الاتجاه مثل المحولات لالتقاط التبعيات بين الكلمات المقنعة وبقية الجملة. تتفوق هذه النماذج في مهام مثل تصنيف النص ، والتعرف على الكيان المسمى ، والإجابة على الأسئلة .
يتم تدريب نماذج التسلسل إلى التسلسل (SEQ2SEQ) على تعيين تسلسل الإدخال لتسلسل الإخراج. وهي تتألف من تشفير يعالج تسلسل الإدخال وفتحار ترميز يولد تسلسل الإخراج. تستخدم نماذج SEQ2Seq على نطاق واسع في مهام مثل ترجمة الآلة ، وتلخيص النص ، وأنظمة الحوار . يمكن تدريبها باستخدام تقنيات مثل الشبكات العصبية المتكررة (RNNs) أو المحولات. الهدف من التدريب هو زيادة احتمال توليد تسلسل الإخراج الصحيح بالنظر إلى الإدخال.
من المهم أن نلاحظ أن أساليب التدريب هذه ليست حصرية بشكل متبادل ، وغالبًا ما يجمع الباحثون بينها أو يستخدمون اختلافات لتحقيق أهداف محددة. على سبيل المثال ، تجمع نماذج مثل T5 بين أهداف التدريب على نموذج اللغة التلقائية والمقنع لتعلم مجموعة متنوعة من المهام.
كل نهج تدريبي له نقاط القوة والضعف الخاصة به ، ويعتمد اختيار النموذج على متطلبات المهمة المحددة وبيانات التدريب المتاحة.
لمزيد من المعلومات ، يرجى الرجوع إلى الفصل A Guide to Model Training Cayment في موقع "medium.com".
تتضمن نمذجة اللغة بناء نماذج يمكنها توليد أو التنبؤ بسلسلة من الكلمات أو الأحرف. فيما يلي بعض الأنواع المختلفة من النماذج المستخدمة عادة لنمذجة اللغة:
في نموذج N-Gram ، يتم تقدير احتمال كلمة ما بناءً على حدوثها في بيانات التدريب بالنسبة إلى كلمات N-1 السابقة. على سبيل المثال ، في نموذج TRIGRAM (ن = 3) ، يتم تحديد احتمال كلمة ما بكلمتين تسبقها مباشرة. يفترض هذا النهج أن احتمال وجود كلمة يعتمد فقط على عدد ثابت من الكلمات السابقة ولا يعتبر تبعيات طويلة المدى.
فيما يلي بعض الأمثلة على n-grams:
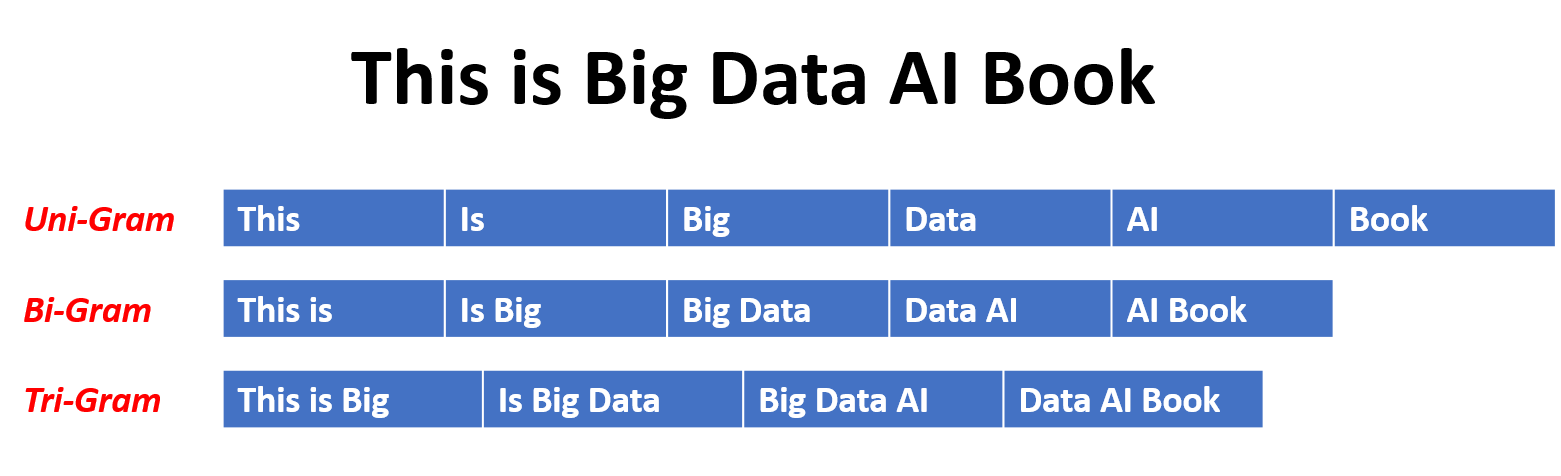
فيما يلي مزايا وعيوب نماذج لغة n-gram:
المزايا :
عيوب :
إليك مثال على استخدام n-grams في Torchtext:
import torchtext
from torchtext . data import get_tokenizer
from torchtext . data . utils import ngrams_iterator
tokenizer = get_tokenizer ( "basic_english" )
# Create a tokenizer object using the "basic_english" tokenizer provided by torchtext
# This tokenizer splits the input text into a list of tokens
tokens = tokenizer ( "I love to code in Python" )
# The result is a list of tokens, where each token represents a word or a punctuation mark
print ( list ( ngrams_iterator ( tokens , 3 )))
[ 'i' , 'love' , 'to' , 'code' , 'in' , 'python' , 'i love' , 'love to' , 'to code' , 'code in' , 'in python' , 'i love to' , 'love to code' , 'to code in' , 'code in python' ]ملحوظة :
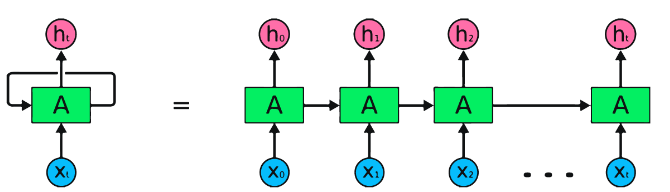
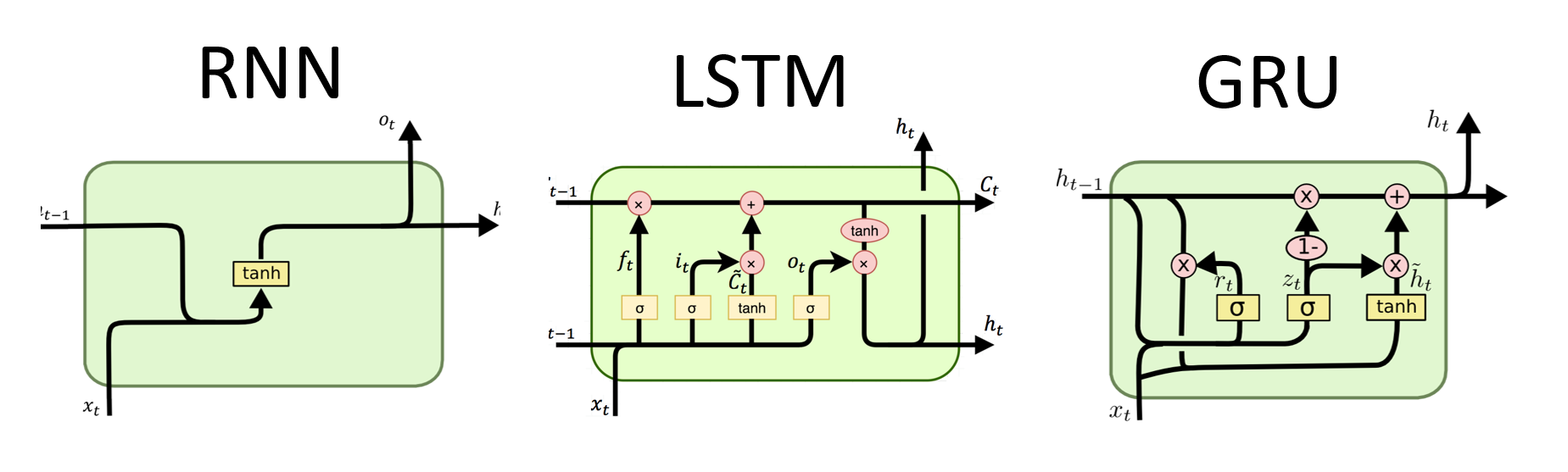
RNNs هي النوع الأساسي للشبكة العصبية لمعالجة البيانات المتسلسلة. لديهم اتصالات متكررة تسمح بتمرير المعلومات من خطوة إلى أخرى ، مما يتيح لهم التقاط التبعيات عبر الزمن. ومع ذلك ، فإن RNNs التقليدية تعاني من مشكلة التدرج المتفجر/الانفجار والصراع مع التبعيات طويلة الأجل.
مزايا RNNS :
عيوب RNNS :
قصاصة رمز Pytorch لتحديد RNN الأساسي في Pytorch:
import torch
import torch . nn as nn
rnn = nn . RNN ( input_size = 10 , hidden_size = 20 , num_layers = 2 )
# input_size – The number of expected features in the input x
# hidden_size – The number of features in the hidden state h
# num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together
# Create a randomly initialized input tensor
input = torch . randn ( 5 , 3 , 10 ) # (sequence length=5, batch size=3, input size=10)
# Create a randomly initialized hidden state tensor
h0 = torch . randn ( 2 , 3 , 20 ) # (num_layers=2, batch size=3, hidden size=20)
# Apply the RNN module to the input tensor and initial hidden state tensor
output , hn = rnn ( input , h0 )
print ( output . shape ) # torch.Size([5, 3, 20])
# (sequence length=5, batch size=3, hidden size=20)
print ( hn . shape ) # torch.Size([2, 3, 20])
# (num_layers=2, batch size=3, hidden size=20)مزايا LSTMS :
عيوب LSTMS :
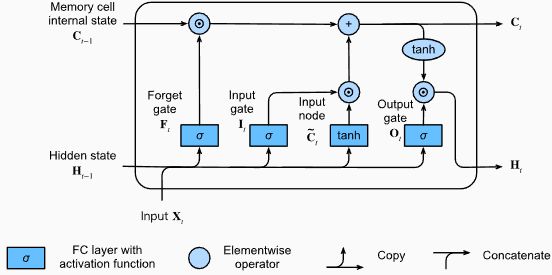
مقتطفات رمز Pytorch لتحديد LSTM الأساسي في Pytorch:
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
lstm = nn . LSTM ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
c0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , ( hn , cn ) = lstm ( input_data , ( h0 , c0 )) سيكون شكل إخراج طبقة LSTM أيضًا [seq_length, batch_size, hidden_size] . هذا يعني أنه لكل إدخال في التسلسل ، سيكون هناك حالة خفية مخرجات مقابلة. في المثال المقدم ، يكون شكل الإخراج torch.Size([10, 1, 64]) ، مما يشير إلى أن LSTM تم تطبيقه على تسلسل طول 10 ، بحجم دفعة 1 ، وحجم حالة مخفي 64.
الآن ، دعونا نناقش الموتر hn (الحالة الخفية). شكله هو torch.Size([2, 1, 64]) . يمثل البعد الأول ، 2 ، عدد الطبقات في LSTM. في هذه الحالة ، تم تعيين وسيطة num_layers على 2 ، لذلك هناك طبقتان في نموذج LSTM. البعد الثاني ، 1 ، يتوافق مع حجم الدُفعة ، وهو 1 في المثال المحدد. أخيرًا ، يمثل البعد الأخير ، 64 ، حجم الحالة المخفية.
لذلك ، يحتوي موتر hn على الحالة الخفية النهائية لكل طبقة من LSTM بعد معالجة تسلسل الإدخال بأكمله ، وبعد قدرة LSTM على الاحتفاظ التبعيات طويلة الأجل وتخفيف مشكلة التدرج التلاشي.
لمزيد من المعلومات ، يرجى الرجوع إلى الفصل الطويل على المدى القصير (LSTM) في وثائق "الغوص في التعلم العميق".
مزايا جروس :
عيوب جروس :
بشكل عام ، تتغلب نماذج LSTM و GRU على بعض القيود المفروضة على RNNs التقليدية ، وخاصة في التقاط التبعيات طويلة الأجل. تتفوق LSTMS في الحفاظ على المعلومات السياقية ، بينما توفر GRUS بديلاً أكثر فعالية من الناحية الحسابية. يعتمد الاختيار بين LSTM و GRU على المتطلبات المحددة للمهمة والموارد الحسابية المتاحة.
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
gru = nn . GRU ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , hn = gru ( input_data , h0 ) سيكون شكل إخراج طبقة GRU أيضًا [seq_length, batch_size, hidden_size] . هذا يعني أنه لكل إدخال في التسلسل ، سيكون هناك حالة خفية مخرجات مقابلة. في المثال المقدم ، يكون شكل الإخراج torch.Size([10, 1, 64]) ، مما يشير إلى أن GRU تم تطبيقه على تسلسل طول 10 ، بحجم دفعة 1 ، وحجم حالة مخفي 64.
الآن ، دعونا نناقش الموتر hn (الحالة الخفية). شكله هو torch.Size([2, 1, 64]) . يمثل البعد الأول ، 2 ، عدد الطبقات في GRU. في هذه الحالة ، تم تعيين وسيطة num_layers على 2 ، لذلك هناك طبقتان في نموذج GRU. البعد الثاني ، 1 ، يتوافق مع حجم الدُفعة ، وهو 1 في المثال المحدد. أخيرًا ، يمثل البعد الأخير ، 64 ، حجم الحالة المخفية.
لذلك ، يحتوي موتر hn على الحالة الخفية النهائية لكل طبقة من GRU بعد معالجة تسلسل الإدخال بأكمله ، واتباع قدرة GRU على التقاط المعلومات والاحتفاظ بها على تسلسلات طويلة مع التخفيف من مشكلة التدرج المتلازم.
لمزيد من المعلومات ، يرجى الرجوع إلى فصل الوحدات المتكررة بوابات (GRU) في وثائق "الغوص في التعلم العميق".
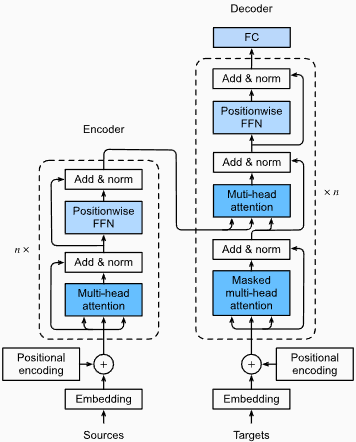
المزايا :
التقاط تبعيات طويلة المدى: تتفوق المحولات في التقاط تبعيات طويلة المدى في التسلسلات باستخدام آليات الاهتمام الذاتي. يتيح لهم ذلك النظر في جميع المواضع في تسلسل الإدخال عند إجراء التنبؤات ، مما يتيح فهمًا أفضل للسياق وتحسين جودة النص الذي تم إنشاؤه.
المعالجة الموازية: على عكس النماذج المتكررة ، يمكن للمحولات معالجة تسلسل الإدخال بالتوازي ، مما يجعلها فعالة للغاية وتقلل من أوقات التدريب والاستدلال. هذا التوازي ممكن بسبب عدم وجود تبعيات متسلسلة في الهندسة المعمارية.
قابلية التوسع: المحولات قابلة للتطوير للغاية ويمكنها التعامل مع تسلسلات الإدخال الكبيرة بشكل فعال. يمكنهم معالجة تسلسل الأطوال التعسفية دون الحاجة إلى الاقتطاع أو الحشو ، وهو مفيد بشكل خاص للمهام التي تنطوي على مستندات أو جمل طويلة.
فهم السياق: يمكن للمحولات التقاط المعلومات السياقية الغنية من خلال الاهتمام بأجزاء ذات صلة من تسلسل الإدخال. يتيح لهم ذلك فهم الهياكل اللغوية المعقدة ، والعلاقات الدلالية ، والتبعيات بين الكلمات ، مما يؤدي إلى توليد لغة أكثر تماسكًا ومناسبة للسياق.
عيوب نماذج المحولات :
المتطلبات الحسابية العالية: تتطلب المحولات عادة موارد حسابية كبيرة مقارنة بالنماذج الأكثر بساطة مثل N-Grams أو RNNs التقليدية. يمكن أن يكون تدريب نماذج المحولات الكبيرة مع مجموعات بيانات واسعة مكلفة من الناحية الحسابية وتستغرق وقتًا طويلاً.
عدم وجود نمذجة متسلسلة: في حين أن المحولات تتفوق في التقاط التبعيات العالمية ، فقد لا تكون فعالة في نمذجة البيانات المتسلسلة بدقة. في الحالات التي يكون فيها ترتيب تسلسل الإدخال أمرًا بالغ الأهمية ، كما هو الحال في المهام التي تنطوي على بيانات السلسلة الزمنية ، قد تكون RNNs التقليدية أو الشبكات العصبية التلافيفية (CNNs) أكثر ملاءمة.
تعقيد آلية الانتباه: تقدم آلية الاهتمام الذاتي في Transformers تعقيدًا إضافيًا للهندسة المعمارية النموذجية. يمكن أن يكون فهم آليات الانتباه وتنفيذها بشكل صحيح أمرًا صعبًا ، ويمكن أن يكون ضبط فرط الأطراف المتعلقة بالانتباه غير تافهة.
متطلبات البيانات: غالبًا ما تتطلب المحولات كميات كبيرة من بيانات التدريب لتحقيق الأداء الأمثل. يعد التدريب على الشركات على نطاق واسع ، كما هو الحال في نماذج المحولات المسبقة مثل GPT و BERT ، شائعًا في الاستفادة من قوة المحولات بشكل فعال.
لمزيد من المعلومات ، يرجى الرجوع إلى الفصل المعماري المحول في وثائق "الغوص في التعلم العميق".
على الرغم من هذه القيود ، أحدثت نماذج المحولات ثورة في مجال معالجة اللغة الطبيعية ونمذجة اللغة. لقد تطورت قدرتهم على التقاط تبعيات طويلة المدى وفهم السياق بشكل كبير على الحالة الفنية في مختلف المهام المتعلقة باللغة ، مما يجعلها خيارًا بارزًا للعديد من التطبيقات.
الحيرة ، في سياق نمذجة اللغة ، هي مقياس يحدد كيف يتنبأ نموذج اللغة بمجموعة اختبار معينة ، مع انخفاض الحيرة التي تشير إلى أداء تنبؤي أفضل. بعبارات أبسط ، يتم حساب الحيرة من خلال أخذ الاحتمال العكسي لمجموعة الاختبار ثم تطبيعها بعدد الكلمات.
كلما انخفضت قيمة الحيرة ، كان نموذج اللغة أفضل في التنبؤ بمجموعة الاختبار. تقليل الحيرة هو نفسه تعظيم الاحتمال
إن صيغة الحيرة مثل الاحتمال العكسي لمجموعة الاختبار ، التي يتم تطبيعها بعدد الكلمات ، هي كما يلي:
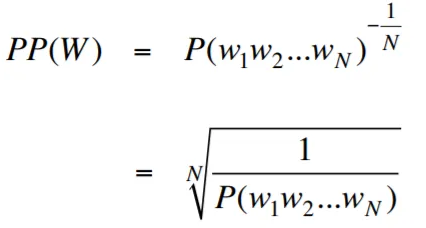

يمكن تفسير الحيرة على أنها مقياس لعامل المتفرعة في نموذج اللغة. يمثل عامل المتفرعة متوسط عدد الكلمات التالية أو الرموز الممكنة التي تعطى سياقًا أو تسلسلًا معينًا للكلمات.
العامل المتفرعة للغة هو عدد الكلمات التالية المحتملة التي يمكن أن تتبع أي كلمة. يمكننا أن نفكر في الحيرة باعتبارها العامل المتفرعة المتوسط المرجح للغة.
تعتبر نمذجة اللغة مع تضمين طبقة ورمز LSTM أداة قوية لبناء نماذج لغة وتدريب. يجمع تطبيق الكود هذا بين مكونين أساسيين في معالجة اللغة الطبيعية: طبقة التضمين وشبكة ذاكرة طويلة الأجل طويلة الأجل (LSTM) .
طبقة التضمين هي المسؤولة عن تحويل البيانات النصية إلى تمثيلات موزعة ، والمعروفة أيضًا باسم تضمينات الكلمات . تلتقط هذه التضمينات الخواص الدلالية والبنية للكلمات ، مما يسمح للنموذج بفهم المعنى وسياق نص الإدخال. تقوم طبقة التضمين بتعيين كل كلمة في تسلسل الإدخال إلى متجه عالي الأبعاد ، والذي يعمل كمدخل للطبقات اللاحقة في النموذج.
تقوم طبقة LSTM في تنفيذ الكود بمعالجة كلمة تضمينات الناتجة عن طبقة التضمين ، والتقاط معلومات التسلسل وتعلم الأنماط والهياكل الأساسية في النص.
من خلال الجمع بين طبقة التضمين وشبكة LSTM ، يتيح الكود بناء نموذج لغة يمكن أن يولد نصًا متماسكًا ومناسبًا سياقًا. يمكن تدريب نماذج اللغة المصممة باستخدام هذا النهج على مجموعات بيانات نصية كبيرة وقادرة على توليد جمل واقعية وذات مغزى ، مما يجعلها أدوات قيمة لمهام معالجة اللغة الطبيعية المختلفة مثل توليد النص والترجمة الآلية وتحليل المشاعر.
يوفر تطبيق الرمز هذا أساسًا بسيطًا وواضحًا وموجزًا لبناء نماذج اللغة استنادًا إلى طبقة التضمين والهندسة المعمارية LSTM. إنه بمثابة نقطة انطلاق للباحثين والمطورين والعشاق المهتمين باستكشاف وتجربة تقنيات نمذجة اللغة الحديثة.
من خلال هذا الرمز ، يمكنك الحصول على فهم أعمق لكيفية عمل طبقات التضمين و LSTMS معًا لالتقاط الأنماط المعقدة والتبعيات ضمن بيانات النص. مع هذه المعرفة ، يمكنك زيادة تمديد الكود واستكشاف التقنيات المتقدمة ، مثل دمج آليات الانتباه أو بنيات المحولات ، لتعزيز أداء وقدرات نماذج لغتك.
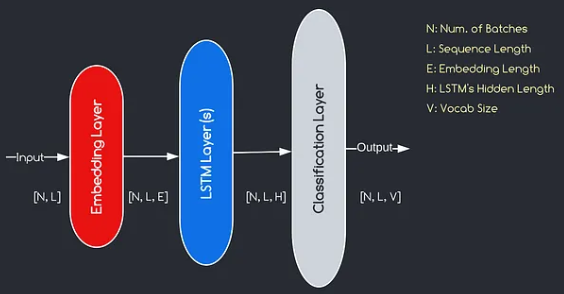
يتوافق النموذج الذي سنبنيه مع الرسم البياني الوارد أعلاه ، مما يوضح المكونات الرئيسية الثلاثة: طبقة التضمين ، طبقات LSTM ، وطبقة التصنيف. في حين أن أهداف LSTM وطبقات التصنيف مألوفة بالفعل بالنسبة لنا ، دعنا نتعمق في أهمية طبقة التضمين.
تلعب طبقة التضمين دورًا حاسمًا في النموذج من خلال تحويل كل كلمة ، ممثلة كفهرس ، إلى متجه من أبعاد E. يتيح تمثيل المتجه هذا الطبقات اللاحقة تعلم واستخراج معلومات ذات معنى من المدخلات. تجدر الإشارة إلى أن استخدام المؤشرات أو المتجهات ذات الساخنة الواحدة لتمثيل الكلمات يمكن أن يكون غير كافٍ لأنها لا تفترض أي علاقات بين الكلمات المختلفة.
عملية التعيين التي تنفذها طبقة التضمين هي إجراء مستفاد يحدث أثناء التدريب. من خلال مرحلة التدريب هذه ، يكتسب النموذج القدرة على ربط الكلمات مع متجهات محددة بطريقة تجسد العلاقات الدلالية والبنية ، وبالتالي تعزيز فهم النموذج للبنية الأساسية الأساسية.
تحتوي مجموعة بيانات WKITEXT-103 ، التي تم تطويرها بواسطة Salesforce ، على أكثر من 100 مليون رمز تم استخلاصه من مجموعة مقالات جيدة ومميزة على ويكيبيديا. لديها 267340 الرموز الفريدة التي تظهر 3 مرات على الأقل في مجموعة البيانات. نظرًا لأنه يحتوي على مقالات ويكيبيديا كاملة الطول ، فإن مجموعة البيانات مناسبة تمامًا للمهام التي يمكن أن تستفيد من التبعيات طويلة الأجل ، مثل نمذجة اللغة.
مجموعة بيانات Wikitext-2 هي نسخة صغيرة من مجموعة بيانات Wikitext-103 حيث تحتوي على 2 مليون رمز فقط. هذه المجموعة الصغيرة مناسبة لاختبار نموذج لغتك.

يحتوي هذا المستودع على رمز لإجراء تحليل البيانات الاستكشافية على مجموعة بيانات UTK ، والتي تتكون من الصور المصنفة حسب العمر والجنس والعرق.
لتنزيل مجموعة بيانات باستخدام TorchText ، يمكنك استخدام وحدة torchtext.datasets . إليك مثال على كيفية تنزيل مجموعة بيانات Wikitext-2 باستخدام TorchText:
import torchtext
from torchtext . datasets import WikiText2
data_path = "data"
train_iter , valid_iter , test_iter = WikiText2 ( root = data_path ) في البداية ، حاولت استخدام الرمز المقدم لتحميل مجموعة بيانات Wikitext-2 ، لكنني واجهت مشكلة مع عنوان URL (https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip) لا يعمل معي. للتغلب على هذا ، قررت الاستفادة من مكتبة torchtext وإنشاء تطبيق مخصص لعملية لوادر مجموعة البيانات.
نظرًا لأن عنوان URL الأصلي لم يكن يعمل ، فقد قمت بتنزيل مجموعات البيانات والتحقق من الصحة والاختبار من مستودع GitHub ووضعها في دليل 'data/datasets/WikiText2' .
إليك انهيار الرمز:
import os
from typing import Union , Tuple
from torchdata . datapipes . iter import FileOpener , IterableWrapper
from torchtext . data . datasets_utils import _wrap_split_argument , _create_dataset_directory
DATA_DIR = "data"
NUM_LINES = {
"train" : 36718 ,
"valid" : 3760 ,
"test" : 4358 ,
}
DATASET_NAME = "WikiText2"
_EXTRACTED_FILES = {
"train" : "wiki.train.tokens" ,
"test" : "wiki.test.tokens" ,
"valid" : "wiki.valid.tokens" ,
}
def _filepath_fn ( root , split ):
return os . path . join ( root , _EXTRACTED_FILES [ split ])
@ _create_dataset_directory ( dataset_name = DATASET_NAME )
@ _wrap_split_argument (( "train" , "valid" , "test" ))
def WikiText2 ( root : str , split : Union [ Tuple [ str ], str ]):
url_dp = IterableWrapper ([ _filepath_fn ( DATA_DIR , split )])
data_dp = FileOpener ( url_dp , encoding = "utf-8" ). readlines ( strip_newline = False , return_path = False ). shuffle (). set_shuffle ( False ). sharding_filter ()
return data_dp لاستخدام محمل مجموعة بيانات Wikitext-2 ، ما عليك سوى استيراد وظيفة wikitext2 واتصل بها مع تقسيم البيانات المطلوب:
train_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "train" )
valid_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "valid" )
test_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "test" )هذا التنفيذ مستوحى من محملات مجموعة بيانات TorchText الرسمية ، ويستفيد من مكتبات Torchdata و Torchtext لتوفير تجربة تحميل بيانات سلسة وفعالة.
يعد بناء المفردات خطوة حاسمة في العديد من مهام معالجة اللغة الطبيعية ، حيث يتيح لك تمثيل الكلمات كمعرفات فريدة يمكن استخدامها في نماذج التعلم الآلي. توضح وثيقة Markdown هذه كيفية بناء مفردات من مجموعة من بيانات التدريب وحفظها للاستخدام في المستقبل.
فيما يلي وظيفة تغلف عملية بناء وحفظ المفردات:
import torch
from torchtext . data . utils import get_tokenizer
from torchtext . vocab import build_vocab_from_iterator
def build_and_save_vocabulary ( train_iter , vocab_path = 'vocab.pt' , min_freq = 4 ):
"""
Build a vocabulary from the training data iterator and save it to a file.
Args:
train_iter (iterator): An iterator over the training data.
vocab_path (str, optional): The path to save the vocabulary file. Defaults to 'vocab.pt'.
min_freq (int, optional): The minimum frequency of a word to be included in the vocabulary. Defaults to 4.
Returns:
torchtext.vocab.Vocab: The built vocabulary.
"""
# Get the tokenizer
tokenizer = get_tokenizer ( "basic_english" )
# Build the vocabulary
vocab = build_vocab_from_iterator ( map ( tokenizer , train_iter ), specials = [ '<unk>' ], min_freq = min_freq )
# Set the default index to the unknown token
vocab . set_default_index ( vocab [ '<unk>' ])
# Save the vocabulary
torch . save ( vocab , vocab_path )
return vocabإليك كيفية استخدام هذه الوظيفة:
# Assuming you have a training data iterator named `train_iter`
vocab = build_and_save_vocabulary ( train_iter , vocab_path = 'my_vocab.pt' )
# You can now use the vocabulary
print ( len ( vocab )) # 23652
print ( vocab ([ 'ebi' , 'AI' . lower (), 'qwerty' ])) # [0, 1973, 0] build_and_save_vocabulary ثلاث وسيطات: train_iter (مؤلف على بيانات التدريب) ، و vocab_path (المسار لحفظ ملف المفردات ، مع افتراضي "vocab.pt ') ، و min_freq (الحد الأدنى لتواتر كلمة يتم تضمينه في المركز ، مع default of 4).basic_english ، الذي يؤدي الرمز المميز الأساسي على النص الإنجليزي.build_vocab_from_iterator ، وتمرير مؤلف بيانات التدريب (بعد الرمز المميز) وتحديد الرمز المميز الخاص '<unk>' وحد الحد الأدنى للتردد.'<unk>' ، مما يعني أن أي كلمة لم يتم العثور عليها في المفردات سيتم تعيينها إلى الرمز المميز غير المعروف. لاستخدام هذه الوظيفة ، تحتاج إلى الحصول على مؤلف بيانات تدريب اسمه train_iter . بعد ذلك ، يمكنك الاتصال بوظيفة build_and_save_vocabulary ، وتمرير train_iter وتحديد مسار ملف المفردات المطلوب والحد الأدنى من عتبة التردد.
ستقوم الوظيفة ببناء المفردات ، وحفظها في الملف المحدد ، وإرجاع كائن Vocab ، والذي يمكنك استخدامه بعد ذلك في مهام المصب.
يوفر هذا الرمز وسيلة لتحليل متوسط طول الجملة في مجموعة بيانات Wikitext-2. إليك انهيار الرمز:
import matplotlib . pyplot as plt
def compute_mean_sentence_length ( data_iter ):
"""
Computes the mean sentence length for the given data iterator.
Args:
data_iter (iterable): An iterable of text data, where each element is a string representing a line of text.
Returns:
float: The mean sentence length.
"""
total_sentence_count = 0
total_sentence_length = 0
for line in data_iter :
sentences = line . split ( '.' ) # Split the line into individual sentences
for sentence in sentences :
tokens = sentence . strip (). split () # Tokenize the sentence
sentence_length = len ( tokens )
if sentence_length > 0 :
total_sentence_count += 1
total_sentence_length += sentence_length
mean_sentence_length = total_sentence_length / total_sentence_count
return mean_sentence_length
# Compute mean sentence length for each dataset
train_mean = compute_mean_sentence_length ( train_iter )
valid_mean = compute_mean_sentence_length ( valid_iter )
test_mean = compute_mean_sentence_length ( test_iter )
# Plot the results
datasets = [ 'Train' , 'Valid' , 'Test' ]
means = [ train_mean , valid_mean , test_mean ]
plt . figure ( figsize = ( 6 , 4 ))
plt . bar ( datasets , means )
plt . xlabel ( 'Dataset' )
plt . ylabel ( 'Mean Sentence Length' )
plt . title ( 'Mean Sentence Length in Wikitext-2' )
plt . grid ( True )
plt . show ()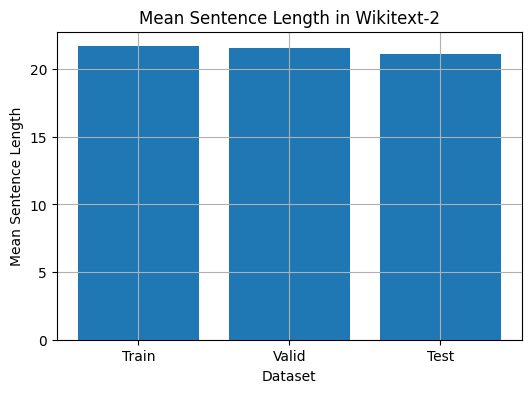
from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Find the 10 least common words
least_common_words = freqs . most_common ()[: - 11 : - 1 ]
print ( "Least Common Words:" )
for word , count in least_common_words :
print ( f" { word } : { count } " )
# Find the 10 most common words
most_common_words = freqs . most_common ( 10 )
print ( " n Most Common Words:" )
for word , count in most_common_words :
print ( f" { word } : { count } " ) from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Count the number of words that repeat 3, 4, and 5 times
count_3 = count_4 = count_5 = 0
for word , freq in freqs . items ():
if freq == 3 :
count_3 += 1
elif freq == 4 :
count_4 += 1
elif freq == 5 :
count_5 += 1
print ( f"Number of words that appear 3 times: { count_3 } " ) # 5130
print ( f"Number of words that appear 4 times: { count_4 } " ) # 3243
print ( f"Number of words that appear 5 times: { count_5 } " ) # 2261 from collections import Counter
import matplotlib . pyplot as plt
# Compute the word lengths in the training dataset
word_lengths = []
for tokens in map ( tokenizer , train_iter ):
word_lengths . extend ( len ( word ) for word in tokens )
# Create a frequency distribution of word lengths
word_length_counts = Counter ( word_lengths )
# Plot the word length distribution
plt . figure ( figsize = ( 10 , 6 ))
plt . bar ( word_length_counts . keys (), word_length_counts . values ())
plt . xlabel ( "Word Length" )
plt . ylabel ( "Frequency" )
plt . title ( "Word Length Distribution in Wikitext-2 Dataset" )
plt . show ()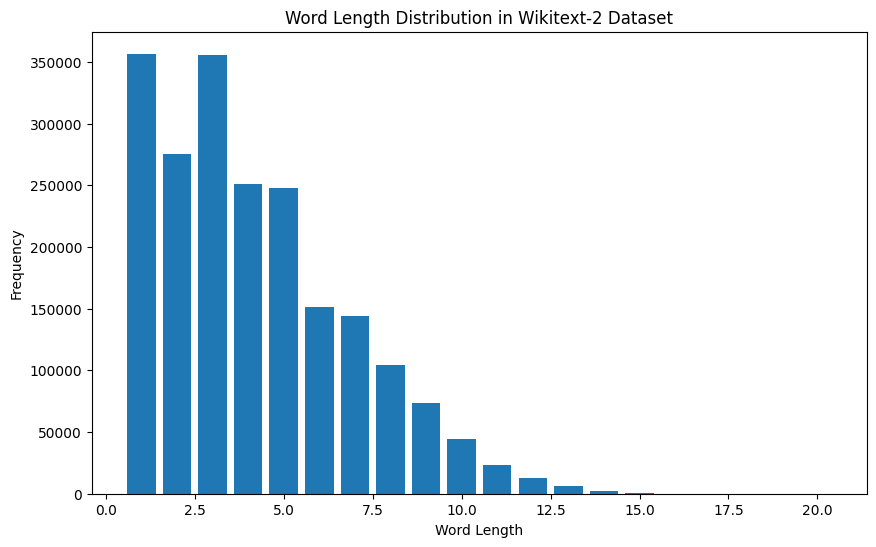
import spacy
import en_core_web_sm
# Load the small English language model from SpaCy
nlp = spacy . load ( "en_core_web_sm" )
# Alternatively, you can use the en_core_web_sm module to load the model
nlp = en_core_web_sm . load ()
# Process the given sentence using the loaded language model
doc = nlp ( "This is a sentence." )
# Print the text and part-of-speech tag for each token in the sentence
print ([( w . text , w . pos_ ) for w in doc ])
# [('This', 'PRON'), ('is', 'AUX'), ('a', 'DET'), ('sentence', 'NOUN'), ('.', 'PUNCT')]لمجموعة بيانات Wikitext-2:
import spacy
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform POS tagging on the training dataset
pos_tags = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
pos_tags . extend ([( token . text , token . pos_ ) for token in doc ])
# Count the frequency of each POS tag
pos_tag_counts = Counter ( tag for _ , tag in pos_tags )
# Print the most common POS tags
print ( "Most Common Part-of-Speech Tags:" )
for tag , count in pos_tag_counts . most_common ( 10 ):
print ( f" { tag } : { count } " )
# Visualize the POS tag distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( pos_tag_counts . keys (), pos_tag_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Part-of-Speech Tag" )
plt . ylabel ( "Frequency" )
plt . title ( "Part-of-Speech Tag Distribution in Wikitext-2 Dataset" )
plt . show ()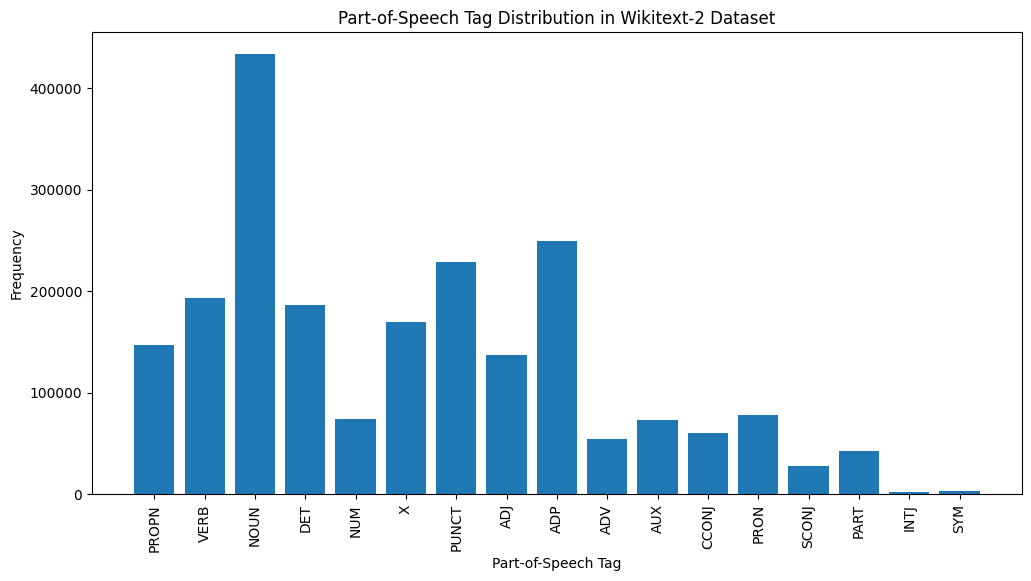
إليك شرح موجز لعلامات نقاط البيع الأكثر شيوعًا في الإخراج المقدم:
الأسماء : الأسماء تمثل الناس أو الأماكن أو الأشياء أو الأفكار.
ADP : يتم استخدام adpositions ، مثل حروف الجر وتدخلات ، للتعبير عن العلاقات بين الكلمات أو العبارات.
عائق : علامات الترقيم ، والتي تعتبر ضرورية لفصل الجمل والنص على هيكلة.
الأفعال : تصف الأفعال الإجراءات أو الحالات أو الأحداث في النص.
Det : المحددات ، مثل المقالات (على سبيل المثال ، "،" A ، "" A ") ، يقدمون معلومات إضافية حول الأسماء.
X : غالبًا ما يتم استخدام هذه العلامة للكلمات الأجنبية أو الاختصارات أو الرموز الأخرى الخاصة باللغة التي لا تتناسب مع فئات نقاط البيع القياسية.
Propn : الأسماء المناسبة ، التي تمثل أسماء محددة للأشخاص أو الأماكن أو المنظمات أو الكيانات الأخرى.
adj : الصفات تعدل أو تصف الأسماء والضمائر.
PRON : الضمائر بديلاً عن الأسماء ، مما يجعل النص أكثر إيجازًا وأقل تكرارًا.
NUM : الأرقام ، التي تمثل الكميات أو التواريخ أو المعلومات العددية الأخرى.
يمكن أن يوفر توزيع علامات نقاط البيع نظرة ثاقبة على الخصائص اللغوية للنص ، مثل غلبة الأسماء ، أو انتشار المواقف ، أو استخدام الأسماء المناسبة ، والتي يمكن أن تكون مفيدة في مهام مثل تصنيف النص ، أو استخراج المعلومات ، أو التحليل الأنثوي.
import spacy
import matplotlib . pyplot as plt
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform NER on the training dataset
named_entities = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
named_entities . extend ([( ent . text , ent . label_ ) for ent in doc . ents ])
# Count the frequency of each named entity type
ner_counts = Counter ( label for _ , label in named_entities )
# Print the most common named entity types
print ( "Most Common Named Entity Types:" )
for label , count in ner_counts . most_common ( 10 ):
print ( f" { label } : { count } " )
# Visualize the named entity distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( ner_counts . keys (), ner_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Named Entity Type" )
plt . ylabel ( "Frequency" )
plt . title ( "Named Entity Distribution in Wikitext-2 Dataset" )
plt . show ()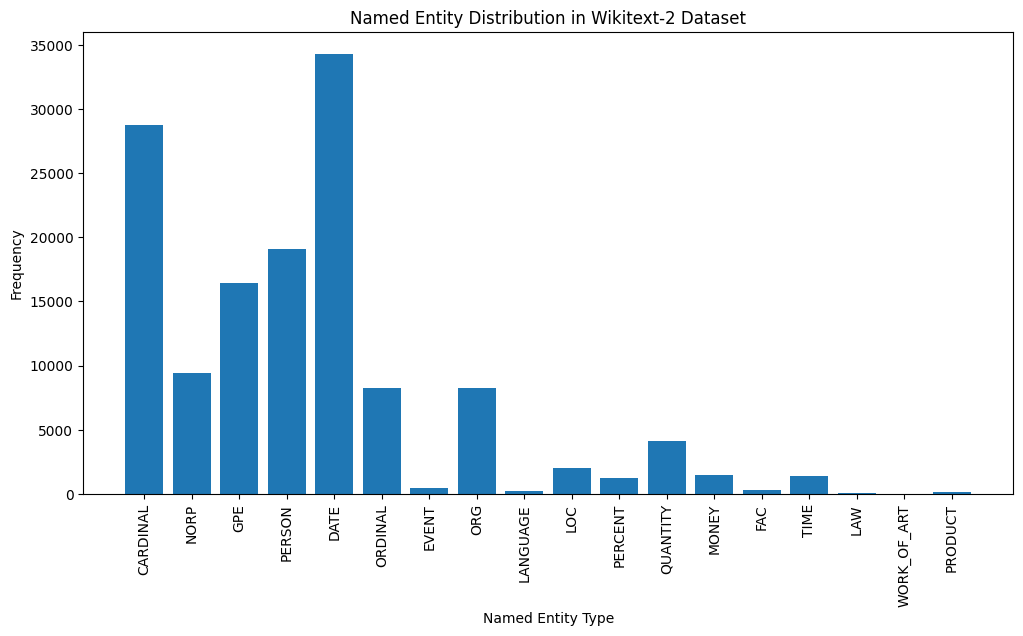
Here's a brief explanation of the most common named entity types in the output:
DATE : Represents specific dates, time periods, or temporal expressions, such as "June 15, 2024" or "last year".
CARDINAL : Includes numerical values, such as quantities, ages, or measurements.
PERSON : Identifies the names of individual people.
GPE (Geopolitical Entity): This entity type represents named geographical locations, such as countries, cities, or states.
NORP (Nationalities, Religious, or Political Groups): This entity type includes named groups or affiliations based on nationality, religion, or political ideology.
ORDINAL : Represents ordinal numbers, such as "first," "second," or "3rd".
ORG (Organization): The names of companies, institutions, or other organized groups.
QUANTITY : Includes non-numeric quantities, such as "a few" or "several".
LOC (Location): Represents named geographical locations, such as continents, regions, or landforms.
MONEY : Identifies monetary values, such as dollar amounts or currency names.
This distribution of named entity types can provide valuable insights into the content and focus of the text. For example, the prominence of DATE and CARDINAL entities may suggest a text that deals with numerical or temporal information, while the prevalence of PERSON, ORG, and GPE entities could indicate a text that discusses people, organizations, and geographical locations.
Understanding the named entity distribution can be useful in a variety of applications, such as information extraction, question answering, and text summarization, where identifying and categorizing key named entities is crucial for understanding the context and content of the text.
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the training dataset
with open ( "data/wiki.train.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Create a string from the entire training dataset
text = " " . join ( train_text )
# Generate the word cloud
wordcloud = WordCloud ( width = 800 , height = 400 , background_color = 'white' ). generate ( text )
# Plot the word cloud
plt . figure ( figsize = ( 12 , 8 ))
plt . imshow ( wordcloud , interpolation = 'bilinear' )
plt . axis ( 'off' )
plt . title ( 'Word Cloud for Wikitext-2 Training Dataset' )
plt . show ()
from sentence_transformers import SentenceTransformer
from sklearn . cluster import KMeans
from collections import defaultdict
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the BERT-based sentence transformer model
model = SentenceTransformer ( 'bert-base-nli-mean-tokens' )
# Load the training dataset
with open ( "data/wiki.valid.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Compute the BERT embeddings for each unique word in the dataset
unique_words = set ( train_text )
word_embeddings = model . encode ( list ( unique_words ))
# Cluster the words using K-Means
num_clusters = 5
kmeans = KMeans ( n_clusters = num_clusters , random_state = 42 )
clusters = kmeans . fit_predict ( word_embeddings )
# Group the words by cluster
word_clusters = defaultdict ( list )
for i , word in enumerate ( unique_words ):
word_clusters [ clusters [ i ]]. append ( word )
# Create a word cloud for each cluster
fig , axes = plt . subplots ( 1 , 5 , figsize = ( 14 , 12 ))
axes = axes . flatten ()
for cluster_id , cluster_words in word_clusters . items ():
word_cloud = WordCloud ( width = 400 , height = 200 , background_color = 'white' ). generate ( ' ' . join ( cluster_words ))
axes [ cluster_id ]. imshow ( word_cloud , interpolation = 'bilinear' )
axes [ cluster_id ]. set_title ( f"Cluster { cluster_id } " )
axes [ cluster_id ]. axis ( 'off' )
plt . subplots_adjust ( wspace = 0.4 , hspace = 0.6 )
plt . tight_layout ()
plt . show ()
The two data formats, N x B x L and M x L , are commonly used in language modeling tasks, particularly in the context of neural network-based models.
N x B x L format:
N represents the number of batches. In this case, the dataset is divided into N smaller batches, which is a common practice to improve the efficiency and stability of the training process.B is the batch size, which represents the number of samples (eg, sentences, paragraphs, or documents) within each batch.L is the length of a sample within each batch, which typically corresponds to the number of tokens (words) in a sample. M x L format:
N x B x L format.M is equal to N x B , which represents the total number of samples (eg, sentences, paragraphs, or documents) in the dataset.L is the length of each sample, which corresponds to the number of tokens (words) in the sample. The choice between these two formats depends on the specific requirements of your language modeling task and the capabilities of the neural network architecture you're working with. If you're training a neural network-based language model, the N x B x L format is typically preferred, as it allows for efficient batch-based training and can lead to faster convergence and better performance. However, if your task doesn't involve neural networks or if the dataset is relatively small, the M x L format may be more suitable.
def prepare_language_model_data ( raw_text_iterator , sequence_length ):
"""
Prepare PyTorch tensors for a language model.
Args:
raw_text_iterator (iterable): An iterator of raw text data.
sequence_length (int): The length of the input and target sequences.
Returns:
tuple: A tuple containing two PyTorch tensors:
- inputs (torch.Tensor): A tensor of input sequences.
- targets (torch.Tensor): A tensor of target sequences.
"""
# Convert the raw text iterator into a single PyTorch tensor
data = torch . cat ([ torch . LongTensor ( vocab ( tokenizer ( line ))) for line in raw_text_iterator ])
# Calculate the number of complete sequences that can be formed
num_sequences = len ( data ) // sequence_length
# Calculate the remainder of the data length divided by the sequence length
remainder = len ( data ) % sequence_length
# If the remainder is 0, add a single <unk> token to the end of the data tensor
if remainder == 0 :
unk_tokens = torch . LongTensor ([ vocab [ '<unk>' ]])
data = torch . cat ([ data , unk_tokens ])
# Extract the input and target sequences from the data tensor
inputs = data [: num_sequences * sequence_length ]. reshape ( - 1 , sequence_length )
targets = data [ 1 : num_sequences * sequence_length + 1 ]. reshape ( - 1 , sequence_length )
print ( len ( inputs ), len ( targets ))
return inputs , targets sequence_length = 30
X_train , y_train = prepare_language_model_data ( train_iter , sequence_length )
X_valid , y_valid = prepare_language_model_data ( valid_iter , sequence_length )
X_test , y_test = prepare_language_model_data ( test_iter , sequence_length )
X_train . shape , y_train . shape , X_valid . shape , y_valid . shape , X_test . shape , y_test . shape
( torch . Size ([ 68333 , 30 ]),
torch . Size ([ 68333 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 8061 , 30 ]),
torch . Size ([ 8061 , 30 ])) This code defines a PyTorch Dataset class for working with language model data. The LanguageModelDataset class takes in input and target tensors and provides the necessary methods for accessing the data.
class LanguageModelDataset ( Dataset ):
def __init__ ( self , inputs , targets ):
self . inputs = inputs
self . targets = targets
def __len__ ( self ):
return self . inputs . shape [ 0 ]
def __getitem__ ( self , idx ):
return self . inputs [ idx ], self . targets [ idx ] The LanguageModelDataset class can be used as follows:
# Create the datasets
train_set = LanguageModelDataset ( X_train , y_train )
valid_set = LanguageModelDataset ( X_valid , y_valid )
test_set = LanguageModelDataset ( X_test , y_test )
# Create data loaders (optional)
train_loader = DataLoader ( train_set , batch_size = 32 , shuffle = True )
valid_loader = DataLoader ( valid_set , batch_size = 32 )
test_loader = DataLoader ( test_set , batch_size = 32 )
# Access the data
x_batch , y_batch = next ( iter ( train_loader ))
print ( f"Input batch shape: { x_batch . shape } " ) # Input batch shape: torch.Size([32, 30])
print ( f"Target batch shape: { y_batch . shape } " ) # Target batch shape: torch.Size([32, 30]) The code defines a custom PyTorch language model that allows you to use different types of word embeddings, including randomly initialized embeddings, pre-trained GloVe embeddings, pre-trained FastText embeddings, by simply specifying the embedding_type argument when creating the model instance.
import torch . nn as nn
from torchtext . vocab import GloVe , FastText
class LanguageModel ( nn . Module ):
def __init__ ( self , vocab_size , embedding_dim ,
hidden_dim , num_layers , dropout_embd = 0.5 ,
dropout_rnn = 0.5 , embedding_type = 'random' ):
super (). __init__ ()
self . num_layers = num_layers
self . hidden_dim = hidden_dim
self . embedding_dim = embedding_dim
self . embedding_type = embedding_type
if embedding_type == 'random' :
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . uniform_ ( - 0.1 , 0.1 )
elif embedding_type == 'glove' :
self . glove = GloVe ( name = '6B' , dim = embedding_dim )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . glove . vectors )
self . embedding . weight . requires_grad = False
elif embedding_type == 'fasttext' :
self . glove = FastText ( language = 'en' )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . fasttext . vectors )
self . embedding . weight . requires_grad = False
else :
raise ValueError ( "Invalid embedding_type. Choose from 'random', 'glove', 'fasttext'." )
self . dropout = nn . Dropout ( p = dropout_embd )
self . lstm = nn . LSTM ( embedding_dim , hidden_dim , num_layers = num_layers ,
dropout = dropout_rnn , batch_first = True )
self . fc = nn . Linear ( hidden_dim , vocab_size )
def forward ( self , src ):
embedding = self . dropout ( self . embedding ( src ))
output , hidden = self . lstm ( embedding )
prediction = self . fc ( output )
return prediction model = LanguageModel ( vocab_size = len ( vocab ),
embedding_dim = 300 ,
hidden_dim = 512 ,
num_layers = 2 ,
dropout_embd = 0.65 ,
dropout_rnn = 0.5 ,
embedding_type = 'glove' ) def num_trainable_params ( model ):
nums = sum ( p . numel () for p in model . parameters () if p . requires_grad ) / 1e6
return nums
# Calculate the number of trainable parameters in the embedding, LSTM, and fully connected layers of the LanguageModel instance 'model'
num_trainable_params ( model . embedding ) # (7.0956)
num_trainable_params ( model . lstm ) # (3.76832)
num_trainable_params ( model . fc ) # (12.133476)

