Torch Linguist
1.0.0

Este projeto é um guia passo a passo sobre a construção de um modelo de idioma usando Pytorch. O objetivo é fornecer uma compreensão abrangente do processo envolvido no desenvolvimento de um modelo de idioma e seus aplicativos.
A modelagem de idiomas, ou LM, é o uso de várias técnicas estatísticas e probabilísticas para determinar a probabilidade de uma determinada sequência de palavras que ocorrem em uma frase. Os modelos de idiomas analisam corpos de dados de texto para fornecer uma base para suas previsões de palavras.
A modelagem de idiomas é usada na inteligência artificial (IA), no processamento de linguagem natural (PNL), no entendimento da linguagem natural (NLU) e nos sistemas de geração de linguagem natural (NLG), particularmente aqueles que executam geração de texto, tradução de máquinas e resposta a perguntas.
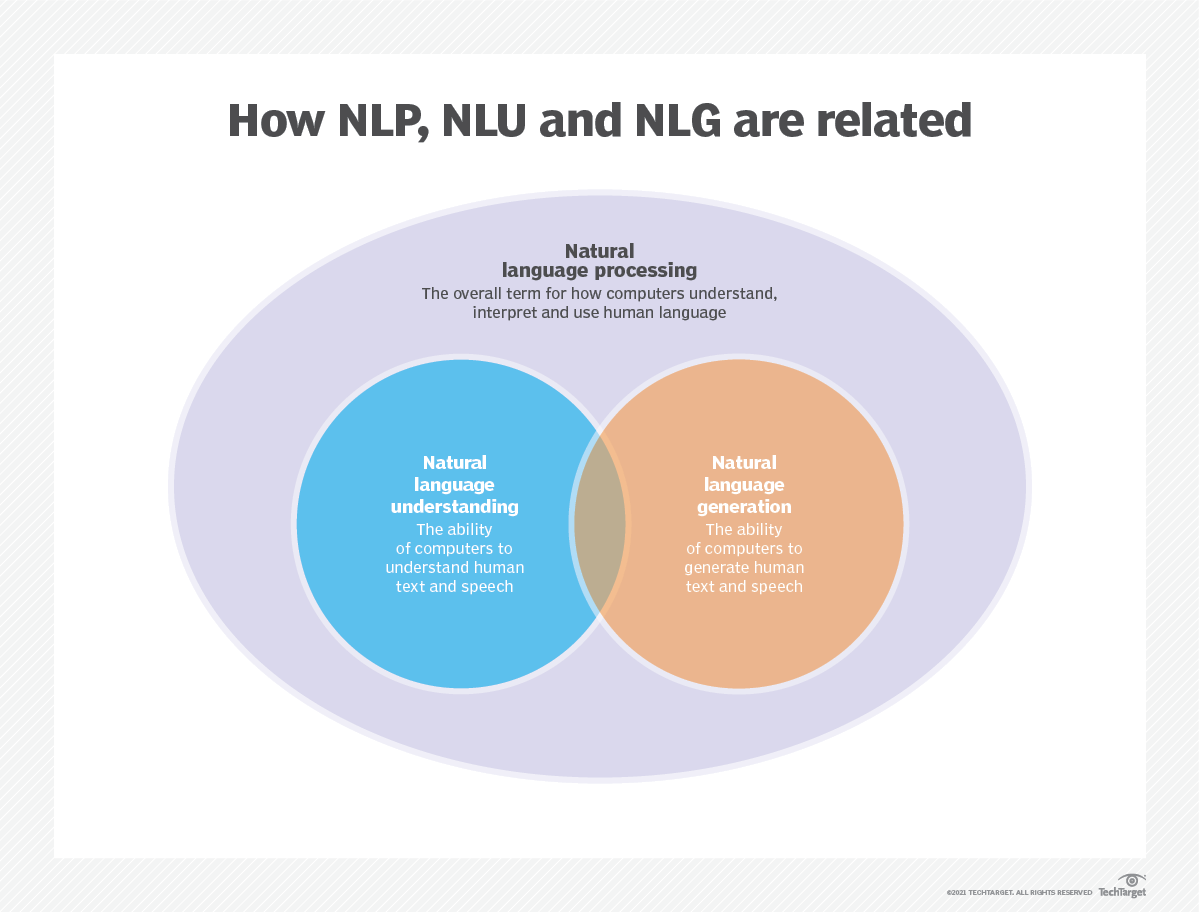
Os grandes modelos de linguagem (LLMS) também usam modelagem de idiomas. Estes são modelos de linguagem avançada, como o GPT-3 do OpenAI e o Palm 2 do Google, que lidam com bilhões de parâmetros de dados de treinamento e geram saída de texto.
A eficácia de um modelo de idioma é normalmente avaliada usando métricas como entropia cruzada e perplexidade , que medem a capacidade do modelo de prever a próxima palavra com precisão (vou cobri-los na etapa 2 ). Vários conjuntos de dados, como Wikitext-2, Wikitext-103, um bilhão de palavras, Text8 e C4, entre outros, são comumente usados para avaliar modelos de linguagem. Nota : Neste projeto, eu uso o Wikitext-2.
A pesquisa de LM recebeu muita atenção na literatura, que pode ser dividida em quatro grandes etapas de desenvolvimento:
Os SLMs são desenvolvidos com base em métodos de aprendizado estatístico que aumentaram nos anos 90. A idéia básica é criar o modelo de previsão de palavras com base na suposição de Markov , por exemplo, prevendo a próxima palavra com base no contexto mais recente. Os SLMs com um comprimento de contexto fixo n também são chamados de modelos de idiomas n-Gram , por exemplo, modelos de idiomas BigRAM e TriGram. Os SLMs têm sido amplamente aplicados para aprimorar o desempenho da tarefa na recuperação de informações (IR) e no processamento de linguagem natural (PNL). No entanto, eles geralmente sofrem da maldição da dimensionalidade:
É difícil estimar com precisão modelos de linguagem de alta ordem, pois um número exponencial de probabilidades de transição precisa ser estimado. Assim, foram introduzidas estratégias de suavização especialmente projetadas, como estimativa de back-off e estimativa de boa e aprovação, para aliviar o problema de escassez de dados.
Os NLMs caracterizam a probabilidade de sequências de palavras por redes neurais, por exemplo, perceptron de várias camadas (MLP) e redes neurais recorrentes (RNNs). Como uma contribuição notável, é o conceito de representação distribuída . Representações distribuídas, também conhecidas como incorporações , a idéia é que o "significado" ou o "conteúdo semântico" de um ponto de dados seja distribuído em várias dimensões. Por exemplo, na PNL, palavras com significados semelhantes são mapeadas para pontos no espaço vetorial que estão próximos um do outro. Essa proximidade não é arbitrária, mas é aprendida com o contexto em que as palavras aparecem. Esse aprendizado dependente do contexto é frequentemente alcançado por meio de modelos de rede neural, como Word2Vec ou Glove , que processam grandes corpora de texto para aprender essas representações.
Uma das principais vantagens das representações distribuídas é a capacidade de capturar relacionamentos semânticos de refrigeração fina. Por exemplo, em um espaço de incorporação de palavras bem treinado, os sinônimos seriam representados por vetores próximos, e é possível executar operações aritméticas com esses vetores que correspondem a operações semânticas significativas (por exemplo, "rei" - "homem" + "mulher" pode resultar em um vetor próximo da "rainha").
Aplicações de representações distribuídas:
Representações distribuídas têm uma ampla gama de aplicações, principalmente em tarefas que envolvem o entendimento da linguagem natural. Eles são usados para:
Similaridade das palavras : medindo a similaridade semântica entre as palavras.
Classificação de texto : categorizando documentos em classes predefinidas.
Tradução da máquina : traduzindo texto de um idioma para outro.
Recuperação de informações : encontrando documentos relevantes em resposta a uma consulta.
Análise de sentimentos : determinar o sentimento expresso em um texto.
Além disso, as representações distribuídas não se limitam aos dados de texto. Eles também podem ser aplicados a outros tipos de dados, como imagens, onde os modelos de aprendizado profundo aprendem a representar imagens como vetores de alta dimensão que capturam recursos visuais e semântica.
Modelos de linguagem causal, também conhecidos como modelos autoregressivos , geram texto prevendo a próxima palavra em uma sequência dadas as palavras anteriores. Esses modelos são treinados para maximizar a probabilidade da próxima palavra usando técnicas como a arquitetura do transformador. Durante o treinamento, a entrada para o modelo é toda a sequência até um determinado token, e o objetivo do modelo é prever o próximo token. Esse tipo de modelo é útil para tarefas como geração de texto , conclusão e resumo .
Os modelos de idiomas mascarados (MLMs) são projetados para aprender representações contextuais de palavras prevendo palavras mascaradas ou ausentes em uma frase. Durante o treinamento, uma parte da sequência de entrada é mascarada aleatoriamente e o modelo é treinado para prever as palavras originais, dado o contexto. Os MLMs usam arquiteturas bidirecionais como Transformers para capturar as dependências entre as palavras mascaradas e o restante da frase. Esses modelos se destacam em tarefas como classificação de texto , reconhecimento de entidade denominado e resposta a perguntas .
Os modelos de sequência para sequência (SEQ2SEQ) são treinados para mapear uma sequência de entrada para uma sequência de saída. Eles consistem em um codificador que processa a sequência de entrada e um decodificador que gera a sequência de saída. Os modelos SEQ2SEQ são amplamente utilizados em tarefas como tradução de máquinas , resumo de texto e sistemas de diálogo . Eles podem ser treinados usando técnicas como redes neurais recorrentes (RNNs) ou transformadores. O objetivo do treinamento é maximizar a probabilidade de gerar a sequência de saída correta, dada a entrada.
É importante observar que essas abordagens de treinamento não são mutuamente exclusivas , e os pesquisadores geralmente os combinam ou empregam variações para atingir objetivos específicos. Por exemplo, modelos como o T5 combinam os objetivos de treinamento de modelos de idiomas autorregressivos e mascarados para aprender uma gama diversificada de tarefas.
Cada abordagem de treinamento tem seus próprios pontos fortes e fracos, e a escolha do modelo depende dos requisitos específicos da tarefa e dos dados de treinamento disponíveis.
Para obter mais informações, consulte o capítulo de abordagens de treinamento de modelos de modelos de idiomas no site "médio.com".
A modelagem de idiomas envolve a construção de modelos que podem gerar ou prever sequências de palavras ou caracteres. Aqui estão alguns tipos diferentes de modelos comumente usados para modelagem de idiomas:
Em um modelo N-Gram, a probabilidade de uma palavra é estimada com base em sua ocorrência nos dados de treinamento em relação às suas palavras N-1 anterior. Por exemplo, em um modelo de trigrama (n = 3), a probabilidade de uma palavra é determinada pelas duas palavras que a precedem imediatamente. Essa abordagem assume que a probabilidade de uma palavra depende apenas de um número fixo de palavras anteriores e não considera dependências de longo alcance.
Aqui estão alguns exemplos de n grama:
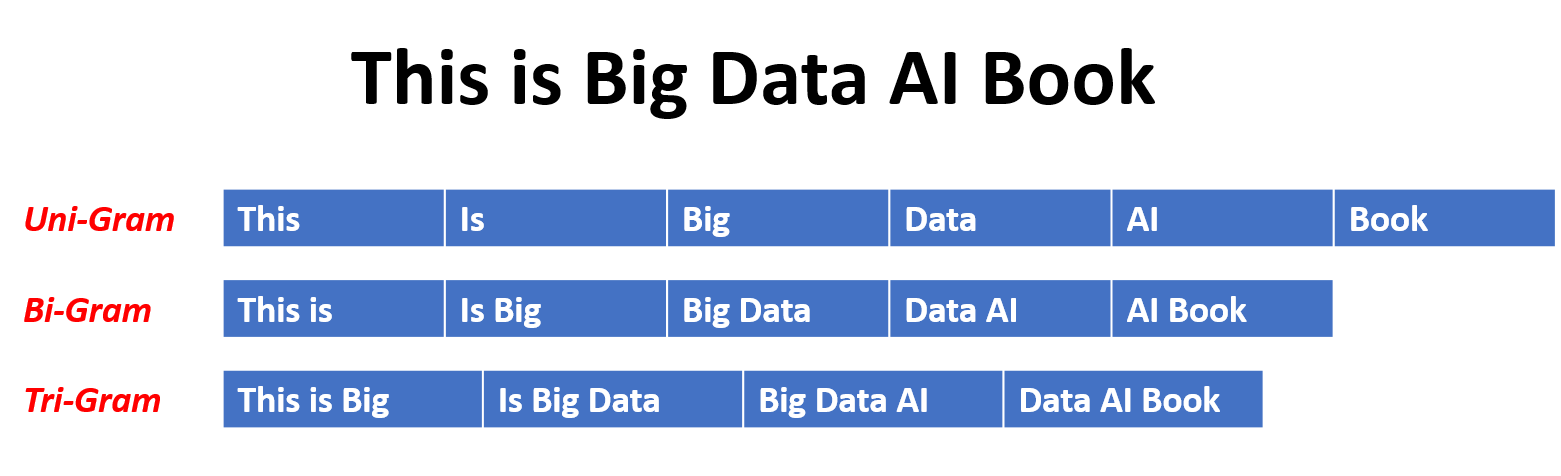
Aqui estão as vantagens e desvantagens dos modelos de idiomas N-Gram:
Vantagens :
Desvantagens :
Aqui está um exemplo de uso de n-gramas no Torchtext:
import torchtext
from torchtext . data import get_tokenizer
from torchtext . data . utils import ngrams_iterator
tokenizer = get_tokenizer ( "basic_english" )
# Create a tokenizer object using the "basic_english" tokenizer provided by torchtext
# This tokenizer splits the input text into a list of tokens
tokens = tokenizer ( "I love to code in Python" )
# The result is a list of tokens, where each token represents a word or a punctuation mark
print ( list ( ngrams_iterator ( tokens , 3 )))
[ 'i' , 'love' , 'to' , 'code' , 'in' , 'python' , 'i love' , 'love to' , 'to code' , 'code in' , 'in python' , 'i love to' , 'love to code' , 'to code in' , 'code in python' ]Observação :
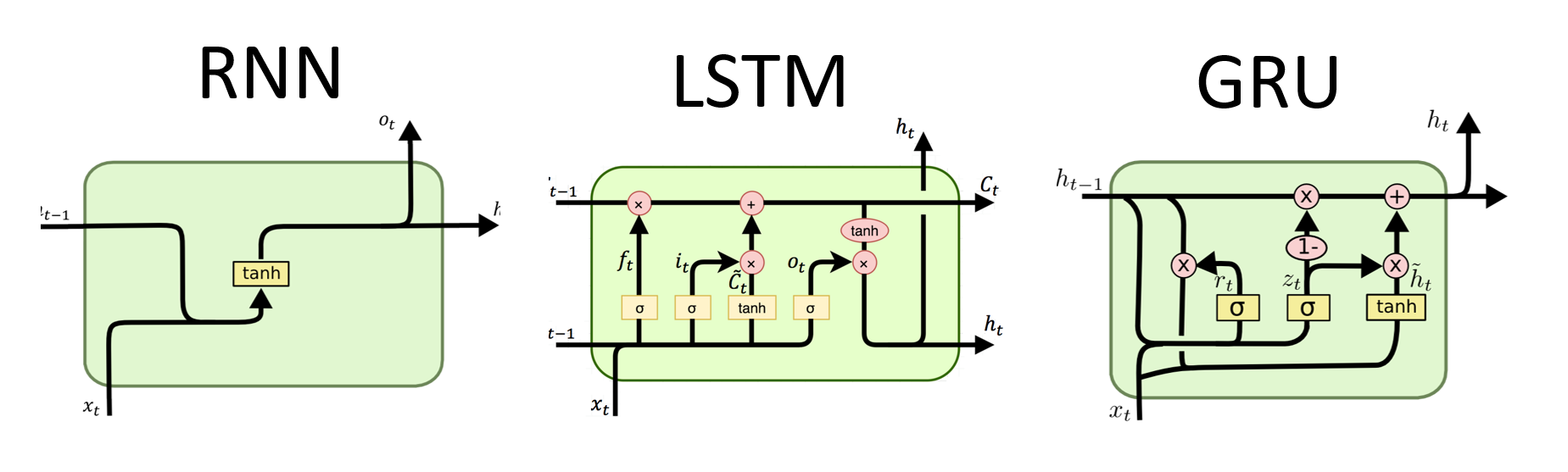
RNNs são o tipo fundamental de rede neural para processamento de dados seqüenciais. Eles têm conexões recorrentes que permitem que as informações sejam passadas de uma etapa para a seguinte, permitindo capturar dependências ao longo do tempo. No entanto, os RNNs tradicionais sofrem com o problema de gradiente de desaparecimento/explosão e lutam com dependências de longo prazo.
Vantagens dos RNNs :
Desvantagens dos RNNs :
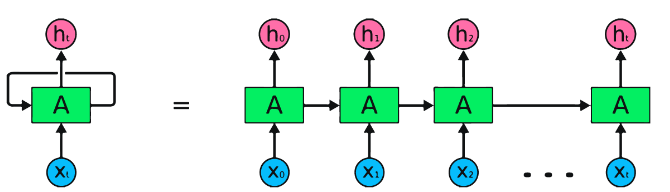
Snippet de código Pytorch para definir um RNN básico em Pytorch:
import torch
import torch . nn as nn
rnn = nn . RNN ( input_size = 10 , hidden_size = 20 , num_layers = 2 )
# input_size – The number of expected features in the input x
# hidden_size – The number of features in the hidden state h
# num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together
# Create a randomly initialized input tensor
input = torch . randn ( 5 , 3 , 10 ) # (sequence length=5, batch size=3, input size=10)
# Create a randomly initialized hidden state tensor
h0 = torch . randn ( 2 , 3 , 20 ) # (num_layers=2, batch size=3, hidden size=20)
# Apply the RNN module to the input tensor and initial hidden state tensor
output , hn = rnn ( input , h0 )
print ( output . shape ) # torch.Size([5, 3, 20])
# (sequence length=5, batch size=3, hidden size=20)
print ( hn . shape ) # torch.Size([2, 3, 20])
# (num_layers=2, batch size=3, hidden size=20)Vantagens do LSTMS :
Desvantagens dos LSTMs :
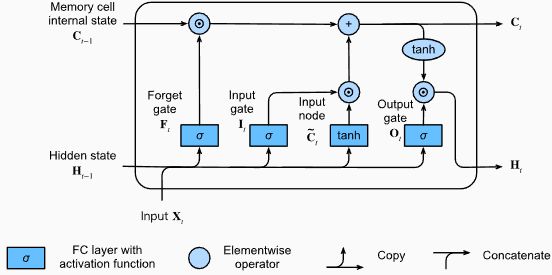
Snippet de código Pytorch para definir um LSTM básico em Pytorch:
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
lstm = nn . LSTM ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
c0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , ( hn , cn ) = lstm ( input_data , ( h0 , c0 )) A forma de saída da camada LSTM também será [seq_length, batch_size, hidden_size] . Isso significa que, para cada entrada na sequência, haverá um estado oculto de saída correspondente. No exemplo fornecido, a forma de saída é torch.Size([10, 1, 64]) , indicando que o LSTM foi aplicado a uma sequência de comprimento 10, com um tamanho de lotes de 1 e um tamanho de estado oculto de 64.
Agora, vamos discutir o tensor hn (estado oculto). Sua forma é torch.Size([2, 1, 64]) . A primeira dimensão, 2, representa o número de camadas no LSTM. Nesse caso, o argumento num_layers foi definido como 2, então existem 2 camadas no modelo LSTM. A segunda dimensão, 1, corresponde ao tamanho do lote, que é 1 no exemplo dado. Finalmente, a última dimensão, 64, representa o tamanho do estado oculto.
Portanto, o tensor hn contém o estado oculto final para cada camada do LSTM após o processamento de toda a sequência de entrada, seguindo a capacidade do LSTM de reter dependências de longo prazo e mitigar o problema do gradiente de fuga.
Para obter mais informações, consulte o capítulo de Memória de curto prazo (LSTM) de longo prazo na documentação "mergulhar em aprendizado profundo".
Vantagens do Grus :
Desvantagens do Grus :
No geral, os modelos LSTM e GRU superam algumas das limitações dos RNNs tradicionais, particularmente na captura de dependências de longo prazo. O LSTMS se destaca na preservação de informações contextuais, enquanto o Grus oferece uma alternativa mais eficiente computacionalmente. A escolha entre LSTM e GRU depende dos requisitos específicos da tarefa e dos recursos computacionais disponíveis.
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
gru = nn . GRU ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , hn = gru ( input_data , h0 ) A forma de saída da camada GRU também será [seq_length, batch_size, hidden_size] . Isso significa que, para cada entrada na sequência, haverá um estado oculto de saída correspondente. No exemplo fornecido, a forma de saída é torch.Size([10, 1, 64]) , indicando que o GRU foi aplicado a uma sequência de comprimento 10, com um tamanho de lotes de 1 e um tamanho oculto de 64.
Agora, vamos discutir o tensor hn (estado oculto). Sua forma é torch.Size([2, 1, 64]) . A primeira dimensão, 2, representa o número de camadas no GRU. Nesse caso, o argumento num_layers foi definido como 2, então existem 2 camadas no modelo GRU. A segunda dimensão, 1, corresponde ao tamanho do lote, que é 1 no exemplo dado. Finalmente, a última dimensão, 64, representa o tamanho do estado oculto.
Portanto, o tensor hn contém o estado oculto final para cada camada do GRU após o processamento de toda a sequência de entrada, seguindo a capacidade do GRU de capturar e reter informações sobre sequências longas e mitigando o problema do gradiente de fuga.
Para obter mais informações, consulte o capítulo unidades recorrentes (GRU) fechado (GRU) no documentação "mergulhar em aprendizado profundo".
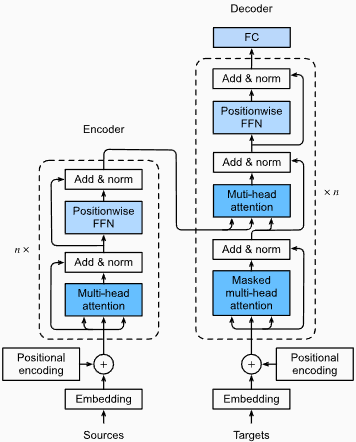
Vantagens :
Captura de dependências de longo alcance: Transformers Excel na captura de dependências de longo alcance em sequências usando mecanismos de auto-ataque. Isso lhes permite considerar todas as posições na sequência de entrada ao fazer previsões, permitindo uma melhor compreensão do contexto e melhorando a qualidade do texto gerado.
Processamento paralelo: Ao contrário dos modelos recorrentes, os transformadores podem processar a sequência de entrada em paralelo, tornando -os tempo altamente eficientes e reduzindo os tempos de treinamento e inferência. Essa paralelização é possível devido à ausência de dependências seqüenciais na arquitetura.
Escalabilidade: os transformadores são altamente escaláveis e podem lidar com grandes sequências de entrada de maneira eficaz. Eles podem processar sequências de comprimentos arbitrários sem a necessidade de truncamento ou preenchimento, o que é particularmente vantajoso para tarefas que envolvem documentos ou frases longas.
Entendimento contextual: os transformadores podem capturar informações contextuais ricas, participando de partes relevantes da sequência de entrada. Isso lhes permite entender estruturas lingüísticas complexas, relações semânticas e dependências entre palavras, resultando em geração de idiomas mais coerente e contextualmente apropriada.
Desvantagens dos modelos de transformadores :
Requisitos computacionais altos: os transformadores normalmente requerem recursos computacionais significativos em comparação com modelos mais simples, como n-gramas ou RNNs tradicionais. O treinamento de grandes modelos de transformadores com extensos conjuntos de dados pode ser computacionalmente caro e demorado.
Falta de modelagem seqüencial: enquanto os Transformers se destacam na captura de dependências globais, eles podem não ser tão eficazes na modelagem de dados estritamente seqüenciais. Nos casos em que a ordem da sequência de entrada é crucial, como em tarefas que envolvem dados de séries temporais, RNNs tradicionais ou redes neurais convolucionais (CNNs) podem ser mais adequadas.
Complexidade do mecanismo de atenção: o mecanismo de auto-atimento nos transformadores introduz complexidade adicional na arquitetura do modelo. Compreender e implementar mecanismos de atenção corretamente pode ser um desafio, e ajustar os hiperparâmetros relacionados à atenção pode ser não trivial.
Requisitos de dados: os transformadores geralmente exigem grandes quantidades de dados de treinamento para obter desempenho ideal. Pré-treinamento em corpora em larga escala, como no caso de modelos de transformadores pré-treinados como GPT e Bert, são comuns para alavancar o poder dos transformadores de maneira eficaz.
Para obter mais informações, consulte o capítulo da arquitetura do transformador na documentação "mergulhar em aprendizado profundo".
Apesar dessas limitações, os modelos de transformadores revolucionaram o campo do processamento de linguagem natural e modelagem de idiomas. Sua capacidade de capturar dependências de longo alcance e entendimento contextual avançaram significativamente o estado da arte em várias tarefas relacionadas à linguagem, tornando-as uma escolha proeminente para muitas aplicações.
A perplexidade, no contexto da modelagem de idiomas, é uma medida que quantifica o quão bem um modelo de idioma prevê um determinado conjunto de testes, com menor perplexidade indicando um melhor desempenho preditivo. Em termos mais simples, a perplexidade é calculada tomando a probabilidade inversa do conjunto de testes e normalizando -a pelo número de palavras.
Quanto menor o valor da perplexidade, melhor o modelo de idioma está na previsão do conjunto de testes. Minimizar a perplexidade é a mesma que maximizar a probabilidade
A fórmula de perplexidade como a probabilidade inversa do conjunto de testes, normalizada pelo número de palavras, é a seguinte:
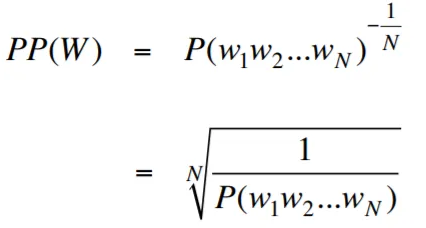

A perplexidade pode ser interpretada como uma medida do fator de ramificação em um modelo de idioma. O fator de ramificação representa o número médio de próximas palavras ou tokens possíveis, dado um contexto ou sequência específica de palavras.
O fator de ramificação de um idioma é o número de próximas palavras possíveis que podem seguir qualquer palavra. Podemos pensar em perplexidade como o fator de ramificação média ponderado de um idioma.
A modelagem de idiomas com a camada de incorporação e o código LSTM é uma ferramenta poderosa para criar e treinar modelos de idiomas. Essa implementação de código combina dois componentes fundamentais no processamento de linguagem natural: uma camada de incorporação e uma rede de memória de curto prazo (LSTM) .
A camada de incorporação é responsável por converter dados de texto em representações distribuídas, também conhecidas como incorporações de palavras . Essas incorporações capturam propriedades semânticas e sintáticas das palavras, permitindo que o modelo compreenda o significado e o contexto do texto de entrada. A camada de incorporação mapeia cada palavra na sequência de entrada para um vetor de alta dimensão, que serve como entrada para camadas subsequentes no modelo.
A camada LSTM nos processos de implementação do código processam as incorporações de palavras geradas pela camada de incorporação, capturando as informações da sequência e aprendendo os padrões e estruturas subjacentes no texto.
Ao combinar a camada de incorporação e a rede LSTM, o código permite a construção de um modelo de idioma que pode gerar texto coerente e contextualmente apropriado. Os modelos de idiomas criados usando essa abordagem podem ser treinados em grandes conjuntos de dados textuais e são capazes de gerar frases realistas e significativas, tornando -as ferramentas valiosas para várias tarefas de processamento de linguagem natural, como geração de texto, tradução para a máquina e análise de sentimentos.
Essa implementação de código fornece uma base simples, clara e concisa para criar modelos de linguagem com base na camada de incorporação e na arquitetura LSTM. Serve como ponto de partida para pesquisadores, desenvolvedores e entusiastas que estão interessados em explorar e experimentar técnicas de modelagem de idiomas de última geração.
Através deste código, você pode obter uma compreensão mais profunda de como as camadas de incorporação e os LSTMs funcionam juntos para capturar os padrões e dependências complexos nos dados de texto. Com esse conhecimento, você pode estender ainda mais o código e explorar técnicas avançadas, como incorporar mecanismos de atenção ou arquiteturas de transformadores, para aprimorar o desempenho e as capacidades de seus modelos de idiomas.
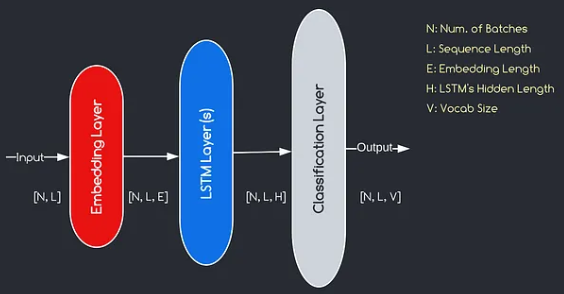
O modelo que construiremos corresponde ao diagrama fornecido acima, ilustrando os três componentes principais: uma camada de incorporação, camadas LSTM e uma camada de classificação. Embora os objetivos das camadas de LSTM e classificação já estejam familiarizados para nós, vamos nos aprofundar no significado da camada de incorporação.
A camada de incorporação desempenha um papel crucial no modelo, transformando cada palavra, representada como um índice, em um vetor de dimensões E. Essa representação vetorial permite que as camadas subsequentes aprendam e extraem informações significativas da entrada. Vale a pena notar que o uso de índices ou vetores de um hot para representar palavras pode ser inadequado, pois não assumem relacionamentos entre palavras diferentes.
O processo de mapeamento realizado pela camada de incorporação é um procedimento instruído que ocorre durante o treinamento. Através dessa fase de treinamento, o modelo ganha a capacidade de associar palavras a vetores específicos de uma maneira que captura relacionamentos semânticos e sintáticos, melhorando assim o entendimento do modelo da estrutura da linguagem subjacente.
O conjunto de dados WKITEXT-103, desenvolvido pelo Salesforce, contém mais de 100 milhões de tokens extraídos do conjunto de artigos bem verificados e apresentados na Wikipedia. Possui 267.340 tokens exclusivos que aparecem pelo menos 3 vezes no conjunto de dados. Como possui artigos completos da Wikipedia, o conjunto de dados é adequado para tarefas que podem se beneficiar de dependências de longo prazo, como modelagem de idiomas.
O conjunto de dados Wikitext-2 é uma pequena versão do conjunto de dados Wikitext-103, pois contém apenas 2 milhões de tokens. Este pequeno conjunto de dados é adequado para testar seu modelo de idioma.

Esse repositório contém código para executar a análise de dados exploratórios no conjunto de dados UTK, que consiste em imagens categorizadas por idade, sexo e etnia.
Para baixar um conjunto de dados usando o TorchText, você pode usar o módulo torchtext.datasets . Aqui está um exemplo de como baixar o conjunto de dados Wikitext-2 usando a TorchText:
import torchtext
from torchtext . datasets import WikiText2
data_path = "data"
train_iter , valid_iter , test_iter = WikiText2 ( root = data_path ) Inicialmente, tentei usar o código fornecido para carregar o conjunto de dados Wikitext-2, mas encontrei um problema com o URL (https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip) não está funcionando para mim. Para superar isso, decidi aproveitar a biblioteca torchtext e criar uma implementação personalizada do carregador de dados.
Como o URL original não estava funcionando, baixei os conjuntos de dados de trem, validação e teste de um repositório do GitHub e os coloquei no diretório 'data/datasets/WikiText2' .
Aqui está um detalhamento do código:
import os
from typing import Union , Tuple
from torchdata . datapipes . iter import FileOpener , IterableWrapper
from torchtext . data . datasets_utils import _wrap_split_argument , _create_dataset_directory
DATA_DIR = "data"
NUM_LINES = {
"train" : 36718 ,
"valid" : 3760 ,
"test" : 4358 ,
}
DATASET_NAME = "WikiText2"
_EXTRACTED_FILES = {
"train" : "wiki.train.tokens" ,
"test" : "wiki.test.tokens" ,
"valid" : "wiki.valid.tokens" ,
}
def _filepath_fn ( root , split ):
return os . path . join ( root , _EXTRACTED_FILES [ split ])
@ _create_dataset_directory ( dataset_name = DATASET_NAME )
@ _wrap_split_argument (( "train" , "valid" , "test" ))
def WikiText2 ( root : str , split : Union [ Tuple [ str ], str ]):
url_dp = IterableWrapper ([ _filepath_fn ( DATA_DIR , split )])
data_dp = FileOpener ( url_dp , encoding = "utf-8" ). readlines ( strip_newline = False , return_path = False ). shuffle (). set_shuffle ( False ). sharding_filter ()
return data_dp Para usar o carregador de dados Wikitext-2, basta importar a função Wikitext2 e chamá-lo com a divisão de dados desejada:
train_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "train" )
valid_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "valid" )
test_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "test" )Essa implementação é inspirada nos carregadores oficiais de dados da TorchText e aproveita as bibliotecas Torchdata e Torchtext para fornecer uma experiência de carregamento de dados perfeita e eficiente.
Construir um vocabulário é uma etapa crucial em muitas tarefas de processamento de linguagem natural, pois permite representar palavras como identificadores exclusivos que podem ser usados nos modelos de aprendizado de máquina. Este documento de marcação demonstra como criar um vocabulário a partir de um conjunto de dados de treinamento e salvá -los para uso futuro.
Aqui está uma função que encapsula o processo de construção e salvamento de um vocabulário:
import torch
from torchtext . data . utils import get_tokenizer
from torchtext . vocab import build_vocab_from_iterator
def build_and_save_vocabulary ( train_iter , vocab_path = 'vocab.pt' , min_freq = 4 ):
"""
Build a vocabulary from the training data iterator and save it to a file.
Args:
train_iter (iterator): An iterator over the training data.
vocab_path (str, optional): The path to save the vocabulary file. Defaults to 'vocab.pt'.
min_freq (int, optional): The minimum frequency of a word to be included in the vocabulary. Defaults to 4.
Returns:
torchtext.vocab.Vocab: The built vocabulary.
"""
# Get the tokenizer
tokenizer = get_tokenizer ( "basic_english" )
# Build the vocabulary
vocab = build_vocab_from_iterator ( map ( tokenizer , train_iter ), specials = [ '<unk>' ], min_freq = min_freq )
# Set the default index to the unknown token
vocab . set_default_index ( vocab [ '<unk>' ])
# Save the vocabulary
torch . save ( vocab , vocab_path )
return vocabVeja como você pode usar esta função:
# Assuming you have a training data iterator named `train_iter`
vocab = build_and_save_vocabulary ( train_iter , vocab_path = 'my_vocab.pt' )
# You can now use the vocabulary
print ( len ( vocab )) # 23652
print ( vocab ([ 'ebi' , 'AI' . lower (), 'qwerty' ])) # [0, 1973, 0] build_and_save_vocabulary leva três argumentos: train_iter (um iterador sobre os dados de treinamento), vocab_path (o caminho para salvar o arquivo de vocabulário, com uma inadimplência de 'vocab.pt') e min_freq (a frequência mínima de uma palavra a ser incluída no vocabulário, com um defensor de 4).basic_english , que executa tokenização básica no texto em inglês.build_vocab_from_iterator , passando o iterador de dados de treinamento (após a tokenização) e especificando o token especial '<unk>' e o limite mínimo de frequência.'<unk>' , o que significa que qualquer palavra não encontrada no vocabulário será mapeada para o token desconhecido. Para usar essa função, você precisa ter um iterador de dados de treinamento chamado train_iter . Em seguida, você pode chamar a função build_and_save_vocabulary , passando o train_iter e especificando o caminho do arquivo de vocabulário desejado e o limite mínimo de frequência.
A função criará o vocabulário, salvará -a no arquivo especificado e retornará o objeto Vocab , que você pode usar em suas tarefas a jusante.
Este código fornece uma maneira de analisar o comprimento médio da frase no conjunto de dados Wikitext-2. Aqui está um detalhamento do código:
import matplotlib . pyplot as plt
def compute_mean_sentence_length ( data_iter ):
"""
Computes the mean sentence length for the given data iterator.
Args:
data_iter (iterable): An iterable of text data, where each element is a string representing a line of text.
Returns:
float: The mean sentence length.
"""
total_sentence_count = 0
total_sentence_length = 0
for line in data_iter :
sentences = line . split ( '.' ) # Split the line into individual sentences
for sentence in sentences :
tokens = sentence . strip (). split () # Tokenize the sentence
sentence_length = len ( tokens )
if sentence_length > 0 :
total_sentence_count += 1
total_sentence_length += sentence_length
mean_sentence_length = total_sentence_length / total_sentence_count
return mean_sentence_length
# Compute mean sentence length for each dataset
train_mean = compute_mean_sentence_length ( train_iter )
valid_mean = compute_mean_sentence_length ( valid_iter )
test_mean = compute_mean_sentence_length ( test_iter )
# Plot the results
datasets = [ 'Train' , 'Valid' , 'Test' ]
means = [ train_mean , valid_mean , test_mean ]
plt . figure ( figsize = ( 6 , 4 ))
plt . bar ( datasets , means )
plt . xlabel ( 'Dataset' )
plt . ylabel ( 'Mean Sentence Length' )
plt . title ( 'Mean Sentence Length in Wikitext-2' )
plt . grid ( True )
plt . show ()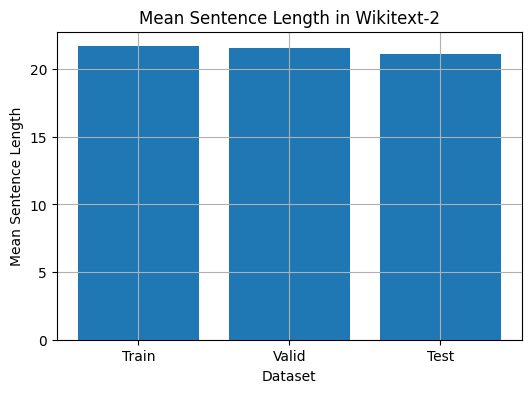
from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Find the 10 least common words
least_common_words = freqs . most_common ()[: - 11 : - 1 ]
print ( "Least Common Words:" )
for word , count in least_common_words :
print ( f" { word } : { count } " )
# Find the 10 most common words
most_common_words = freqs . most_common ( 10 )
print ( " n Most Common Words:" )
for word , count in most_common_words :
print ( f" { word } : { count } " ) from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Count the number of words that repeat 3, 4, and 5 times
count_3 = count_4 = count_5 = 0
for word , freq in freqs . items ():
if freq == 3 :
count_3 += 1
elif freq == 4 :
count_4 += 1
elif freq == 5 :
count_5 += 1
print ( f"Number of words that appear 3 times: { count_3 } " ) # 5130
print ( f"Number of words that appear 4 times: { count_4 } " ) # 3243
print ( f"Number of words that appear 5 times: { count_5 } " ) # 2261 from collections import Counter
import matplotlib . pyplot as plt
# Compute the word lengths in the training dataset
word_lengths = []
for tokens in map ( tokenizer , train_iter ):
word_lengths . extend ( len ( word ) for word in tokens )
# Create a frequency distribution of word lengths
word_length_counts = Counter ( word_lengths )
# Plot the word length distribution
plt . figure ( figsize = ( 10 , 6 ))
plt . bar ( word_length_counts . keys (), word_length_counts . values ())
plt . xlabel ( "Word Length" )
plt . ylabel ( "Frequency" )
plt . title ( "Word Length Distribution in Wikitext-2 Dataset" )
plt . show ()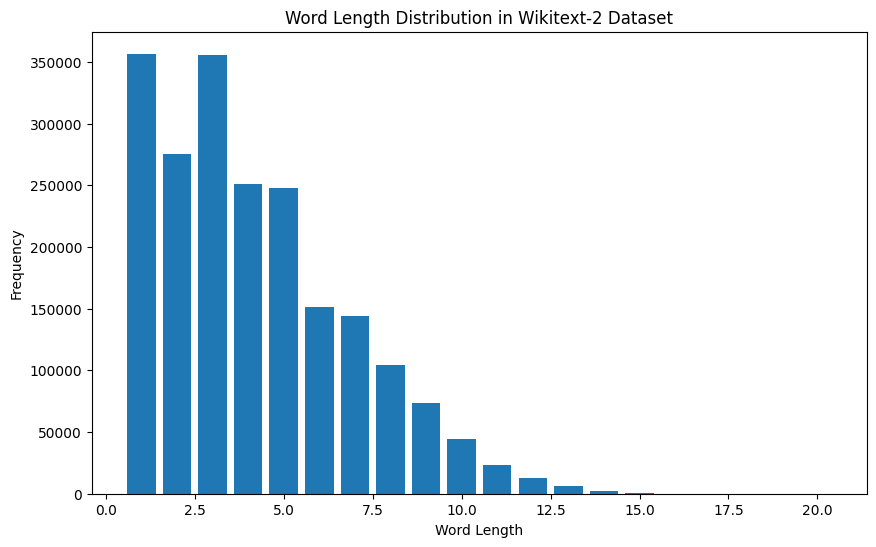
import spacy
import en_core_web_sm
# Load the small English language model from SpaCy
nlp = spacy . load ( "en_core_web_sm" )
# Alternatively, you can use the en_core_web_sm module to load the model
nlp = en_core_web_sm . load ()
# Process the given sentence using the loaded language model
doc = nlp ( "This is a sentence." )
# Print the text and part-of-speech tag for each token in the sentence
print ([( w . text , w . pos_ ) for w in doc ])
# [('This', 'PRON'), ('is', 'AUX'), ('a', 'DET'), ('sentence', 'NOUN'), ('.', 'PUNCT')]Para o conjunto de dados Wikitext-2:
import spacy
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform POS tagging on the training dataset
pos_tags = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
pos_tags . extend ([( token . text , token . pos_ ) for token in doc ])
# Count the frequency of each POS tag
pos_tag_counts = Counter ( tag for _ , tag in pos_tags )
# Print the most common POS tags
print ( "Most Common Part-of-Speech Tags:" )
for tag , count in pos_tag_counts . most_common ( 10 ):
print ( f" { tag } : { count } " )
# Visualize the POS tag distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( pos_tag_counts . keys (), pos_tag_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Part-of-Speech Tag" )
plt . ylabel ( "Frequency" )
plt . title ( "Part-of-Speech Tag Distribution in Wikitext-2 Dataset" )
plt . show ()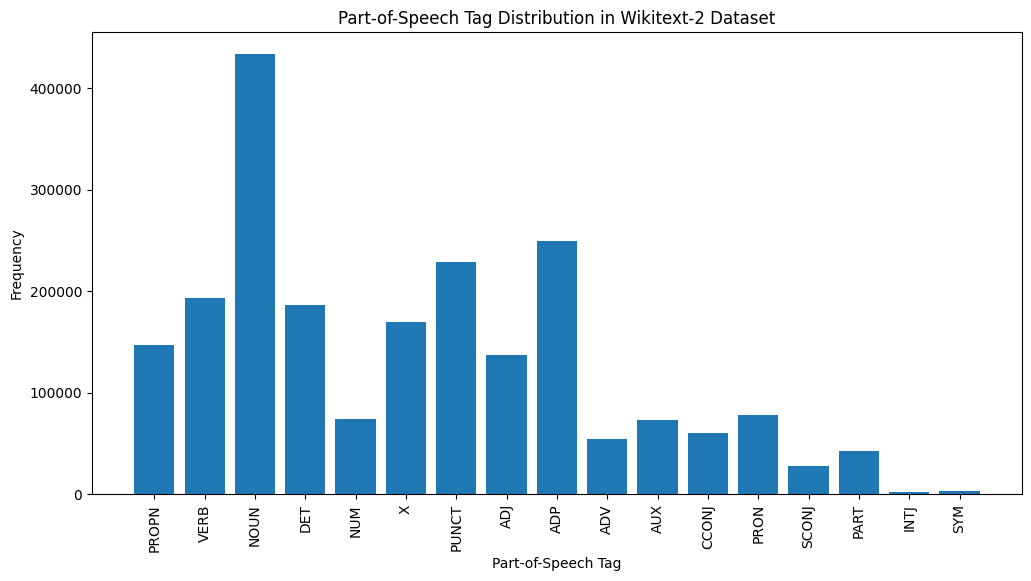
Aqui está uma breve explicação das tags de POS mais comuns na saída fornecida:
Substantivo : substantivos representam pessoas, lugares, coisas ou idéias.
ADP : Adposições, como preposições e pós -posições, são usadas para expressar relações entre palavras ou frases.
Pontuação : marcas de pontuação, essenciais para separar e estruturar frases e texto.
Verbo : verbos descrevem ações, estados ou ocorrências no texto.
Det : Determinantes, como artigos (por exemplo, "the," A "A", "An"), fornecem informações adicionais sobre substantivos.
X : Esta tag é frequentemente usada para palavras estrangeiras, abreviações ou outros tokens específicos de idiomas que não se encaixam nas categorias de POS padrão.
Propn : substantivos adequados, que representam nomes específicos de pessoas, lugares, organizações ou outras entidades.
Adj : adjetivos modificam ou descrevem substantivos e pronomes.
Pron : pronomes substituem substantivos, tornando o texto mais conciso e menos repetitivo.
NUM : Numerais, que representam quantidades, datas ou outras informações numéricas.
Essa distribuição de tags de POS pode fornecer informações sobre as características linguísticas do texto, como a predominância de substantivos, a prevalência de adposições ou o uso de substantivos adequados, que podem ser úteis em tarefas como classificação de texto, extração de informações ou análise estilométrica.
import spacy
import matplotlib . pyplot as plt
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform NER on the training dataset
named_entities = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
named_entities . extend ([( ent . text , ent . label_ ) for ent in doc . ents ])
# Count the frequency of each named entity type
ner_counts = Counter ( label for _ , label in named_entities )
# Print the most common named entity types
print ( "Most Common Named Entity Types:" )
for label , count in ner_counts . most_common ( 10 ):
print ( f" { label } : { count } " )
# Visualize the named entity distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( ner_counts . keys (), ner_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Named Entity Type" )
plt . ylabel ( "Frequency" )
plt . title ( "Named Entity Distribution in Wikitext-2 Dataset" )
plt . show ()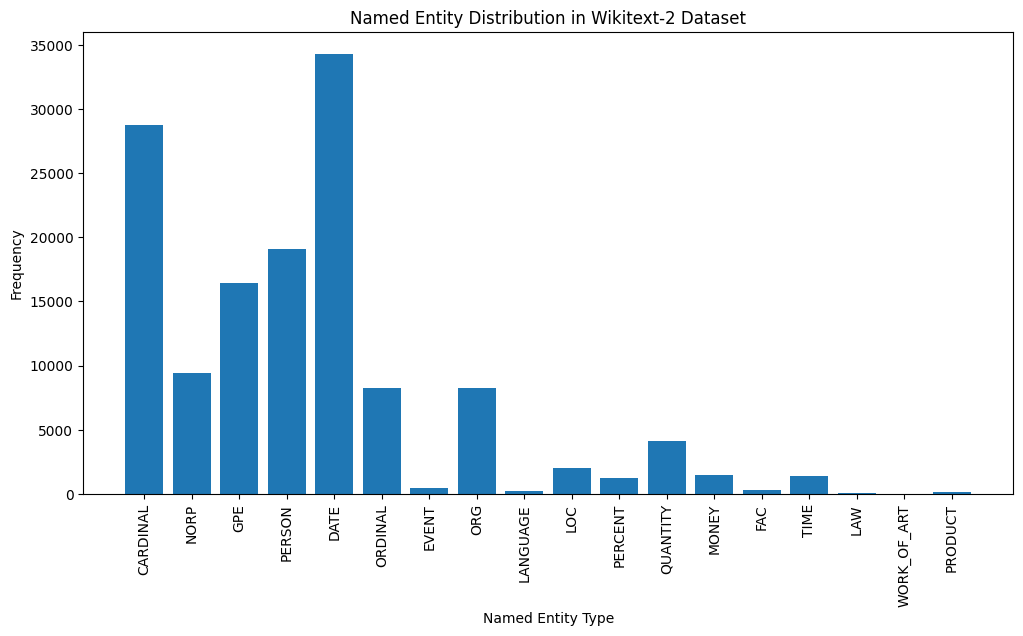
Here's a brief explanation of the most common named entity types in the output:
DATE : Represents specific dates, time periods, or temporal expressions, such as "June 15, 2024" or "last year".
CARDINAL : Includes numerical values, such as quantities, ages, or measurements.
PERSON : Identifies the names of individual people.
GPE (Geopolitical Entity): This entity type represents named geographical locations, such as countries, cities, or states.
NORP (Nationalities, Religious, or Political Groups): This entity type includes named groups or affiliations based on nationality, religion, or political ideology.
ORDINAL : Represents ordinal numbers, such as "first," "second," or "3rd".
ORG (Organization): The names of companies, institutions, or other organized groups.
QUANTITY : Includes non-numeric quantities, such as "a few" or "several".
LOC (Location): Represents named geographical locations, such as continents, regions, or landforms.
MONEY : Identifies monetary values, such as dollar amounts or currency names.
This distribution of named entity types can provide valuable insights into the content and focus of the text. For example, the prominence of DATE and CARDINAL entities may suggest a text that deals with numerical or temporal information, while the prevalence of PERSON, ORG, and GPE entities could indicate a text that discusses people, organizations, and geographical locations.
Understanding the named entity distribution can be useful in a variety of applications, such as information extraction, question answering, and text summarization, where identifying and categorizing key named entities is crucial for understanding the context and content of the text.
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the training dataset
with open ( "data/wiki.train.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Create a string from the entire training dataset
text = " " . join ( train_text )
# Generate the word cloud
wordcloud = WordCloud ( width = 800 , height = 400 , background_color = 'white' ). generate ( text )
# Plot the word cloud
plt . figure ( figsize = ( 12 , 8 ))
plt . imshow ( wordcloud , interpolation = 'bilinear' )
plt . axis ( 'off' )
plt . title ( 'Word Cloud for Wikitext-2 Training Dataset' )
plt . show ()
from sentence_transformers import SentenceTransformer
from sklearn . cluster import KMeans
from collections import defaultdict
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the BERT-based sentence transformer model
model = SentenceTransformer ( 'bert-base-nli-mean-tokens' )
# Load the training dataset
with open ( "data/wiki.valid.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Compute the BERT embeddings for each unique word in the dataset
unique_words = set ( train_text )
word_embeddings = model . encode ( list ( unique_words ))
# Cluster the words using K-Means
num_clusters = 5
kmeans = KMeans ( n_clusters = num_clusters , random_state = 42 )
clusters = kmeans . fit_predict ( word_embeddings )
# Group the words by cluster
word_clusters = defaultdict ( list )
for i , word in enumerate ( unique_words ):
word_clusters [ clusters [ i ]]. append ( word )
# Create a word cloud for each cluster
fig , axes = plt . subplots ( 1 , 5 , figsize = ( 14 , 12 ))
axes = axes . flatten ()
for cluster_id , cluster_words in word_clusters . items ():
word_cloud = WordCloud ( width = 400 , height = 200 , background_color = 'white' ). generate ( ' ' . join ( cluster_words ))
axes [ cluster_id ]. imshow ( word_cloud , interpolation = 'bilinear' )
axes [ cluster_id ]. set_title ( f"Cluster { cluster_id } " )
axes [ cluster_id ]. axis ( 'off' )
plt . subplots_adjust ( wspace = 0.4 , hspace = 0.6 )
plt . tight_layout ()
plt . show ()
The two data formats, N x B x L and M x L , are commonly used in language modeling tasks, particularly in the context of neural network-based models.
N x B x L format:
N represents the number of batches. In this case, the dataset is divided into N smaller batches, which is a common practice to improve the efficiency and stability of the training process.B is the batch size, which represents the number of samples (eg, sentences, paragraphs, or documents) within each batch.L is the length of a sample within each batch, which typically corresponds to the number of tokens (words) in a sample. M x L format:
N x B x L format.M is equal to N x B , which represents the total number of samples (eg, sentences, paragraphs, or documents) in the dataset.L is the length of each sample, which corresponds to the number of tokens (words) in the sample. The choice between these two formats depends on the specific requirements of your language modeling task and the capabilities of the neural network architecture you're working with. If you're training a neural network-based language model, the N x B x L format is typically preferred, as it allows for efficient batch-based training and can lead to faster convergence and better performance. However, if your task doesn't involve neural networks or if the dataset is relatively small, the M x L format may be more suitable.
def prepare_language_model_data ( raw_text_iterator , sequence_length ):
"""
Prepare PyTorch tensors for a language model.
Args:
raw_text_iterator (iterable): An iterator of raw text data.
sequence_length (int): The length of the input and target sequences.
Returns:
tuple: A tuple containing two PyTorch tensors:
- inputs (torch.Tensor): A tensor of input sequences.
- targets (torch.Tensor): A tensor of target sequences.
"""
# Convert the raw text iterator into a single PyTorch tensor
data = torch . cat ([ torch . LongTensor ( vocab ( tokenizer ( line ))) for line in raw_text_iterator ])
# Calculate the number of complete sequences that can be formed
num_sequences = len ( data ) // sequence_length
# Calculate the remainder of the data length divided by the sequence length
remainder = len ( data ) % sequence_length
# If the remainder is 0, add a single <unk> token to the end of the data tensor
if remainder == 0 :
unk_tokens = torch . LongTensor ([ vocab [ '<unk>' ]])
data = torch . cat ([ data , unk_tokens ])
# Extract the input and target sequences from the data tensor
inputs = data [: num_sequences * sequence_length ]. reshape ( - 1 , sequence_length )
targets = data [ 1 : num_sequences * sequence_length + 1 ]. reshape ( - 1 , sequence_length )
print ( len ( inputs ), len ( targets ))
return inputs , targets sequence_length = 30
X_train , y_train = prepare_language_model_data ( train_iter , sequence_length )
X_valid , y_valid = prepare_language_model_data ( valid_iter , sequence_length )
X_test , y_test = prepare_language_model_data ( test_iter , sequence_length )
X_train . shape , y_train . shape , X_valid . shape , y_valid . shape , X_test . shape , y_test . shape
( torch . Size ([ 68333 , 30 ]),
torch . Size ([ 68333 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 8061 , 30 ]),
torch . Size ([ 8061 , 30 ])) This code defines a PyTorch Dataset class for working with language model data. The LanguageModelDataset class takes in input and target tensors and provides the necessary methods for accessing the data.
class LanguageModelDataset ( Dataset ):
def __init__ ( self , inputs , targets ):
self . inputs = inputs
self . targets = targets
def __len__ ( self ):
return self . inputs . shape [ 0 ]
def __getitem__ ( self , idx ):
return self . inputs [ idx ], self . targets [ idx ] The LanguageModelDataset class can be used as follows:
# Create the datasets
train_set = LanguageModelDataset ( X_train , y_train )
valid_set = LanguageModelDataset ( X_valid , y_valid )
test_set = LanguageModelDataset ( X_test , y_test )
# Create data loaders (optional)
train_loader = DataLoader ( train_set , batch_size = 32 , shuffle = True )
valid_loader = DataLoader ( valid_set , batch_size = 32 )
test_loader = DataLoader ( test_set , batch_size = 32 )
# Access the data
x_batch , y_batch = next ( iter ( train_loader ))
print ( f"Input batch shape: { x_batch . shape } " ) # Input batch shape: torch.Size([32, 30])
print ( f"Target batch shape: { y_batch . shape } " ) # Target batch shape: torch.Size([32, 30]) The code defines a custom PyTorch language model that allows you to use different types of word embeddings, including randomly initialized embeddings, pre-trained GloVe embeddings, pre-trained FastText embeddings, by simply specifying the embedding_type argument when creating the model instance.
import torch . nn as nn
from torchtext . vocab import GloVe , FastText
class LanguageModel ( nn . Module ):
def __init__ ( self , vocab_size , embedding_dim ,
hidden_dim , num_layers , dropout_embd = 0.5 ,
dropout_rnn = 0.5 , embedding_type = 'random' ):
super (). __init__ ()
self . num_layers = num_layers
self . hidden_dim = hidden_dim
self . embedding_dim = embedding_dim
self . embedding_type = embedding_type
if embedding_type == 'random' :
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . uniform_ ( - 0.1 , 0.1 )
elif embedding_type == 'glove' :
self . glove = GloVe ( name = '6B' , dim = embedding_dim )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . glove . vectors )
self . embedding . weight . requires_grad = False
elif embedding_type == 'fasttext' :
self . glove = FastText ( language = 'en' )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . fasttext . vectors )
self . embedding . weight . requires_grad = False
else :
raise ValueError ( "Invalid embedding_type. Choose from 'random', 'glove', 'fasttext'." )
self . dropout = nn . Dropout ( p = dropout_embd )
self . lstm = nn . LSTM ( embedding_dim , hidden_dim , num_layers = num_layers ,
dropout = dropout_rnn , batch_first = True )
self . fc = nn . Linear ( hidden_dim , vocab_size )
def forward ( self , src ):
embedding = self . dropout ( self . embedding ( src ))
output , hidden = self . lstm ( embedding )
prediction = self . fc ( output )
return prediction model = LanguageModel ( vocab_size = len ( vocab ),
embedding_dim = 300 ,
hidden_dim = 512 ,
num_layers = 2 ,
dropout_embd = 0.65 ,
dropout_rnn = 0.5 ,
embedding_type = 'glove' ) def num_trainable_params ( model ):
nums = sum ( p . numel () for p in model . parameters () if p . requires_grad ) / 1e6
return nums
# Calculate the number of trainable parameters in the embedding, LSTM, and fully connected layers of the LanguageModel instance 'model'
num_trainable_params ( model . embedding ) # (7.0956)
num_trainable_params ( model . lstm ) # (3.76832)
num_trainable_params ( model . fc ) # (12.133476)

