Torch Linguist
1.0.0

Este proyecto es una guía paso a paso sobre la construcción de un modelo de idioma que usa Pytorch. Su objetivo es proporcionar una comprensión integral del proceso involucrado en el desarrollo de un modelo de idioma y sus aplicaciones.
El modelado de lenguaje, o LM, es el uso de varias técnicas estadísticas y probabilísticas para determinar la probabilidad de una secuencia dada de palabras que ocurren en una oración. Los modelos de lenguaje analizan cuerpos de datos de texto para proporcionar una base para sus predicciones de palabras.
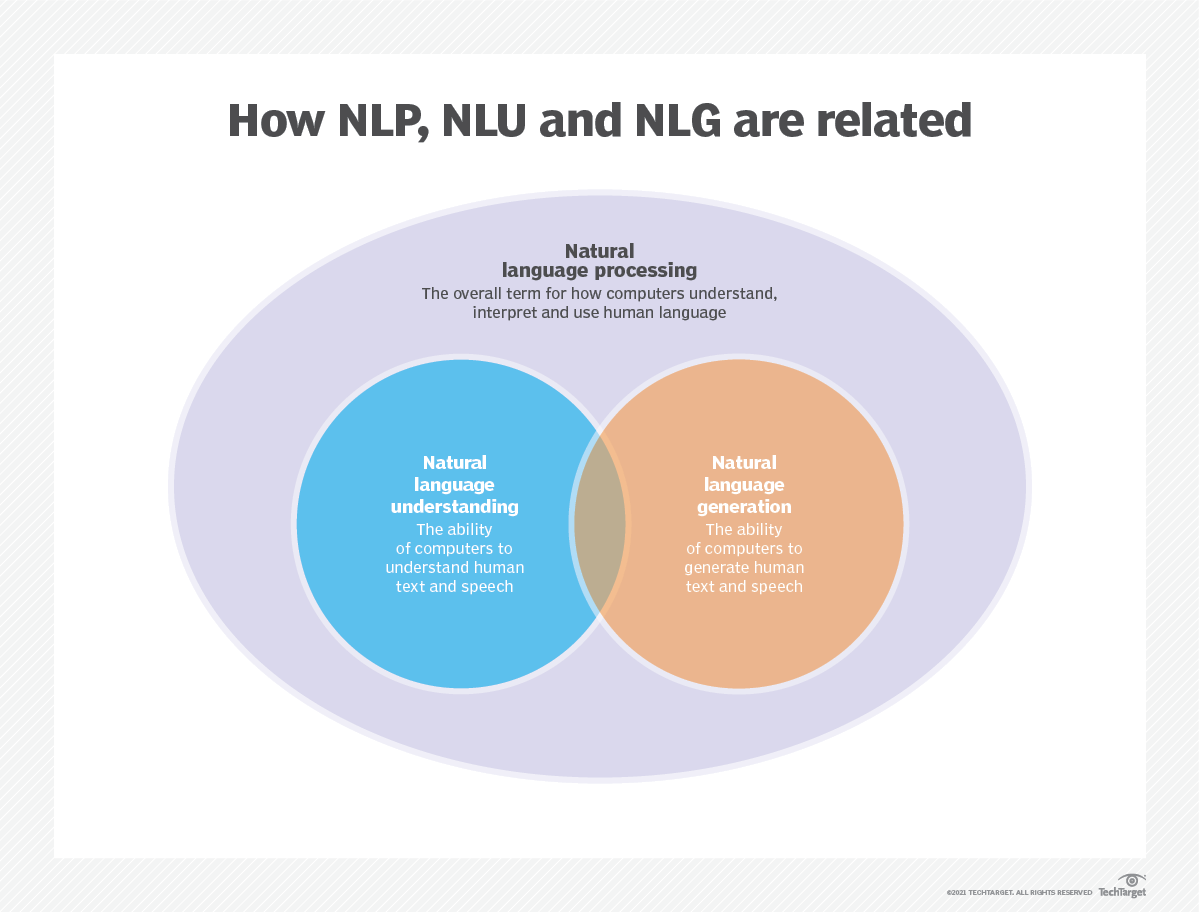
El modelado de idiomas se utiliza en inteligencia artificial (IA), procesamiento del lenguaje natural (PNL), comprensión del lenguaje natural (NLU) y sistemas de generación de lenguaje natural (NLG), particularmente los que realizan generación de texto, traducción automática y respuesta de preguntas.
Los modelos de idiomas grandes (LLM) también utilizan modelado de idiomas. Estos son modelos de idiomas avanzados, como GPT-3 de OpenAI y Palm 2 de Google, que manejan miles de millones de parámetros de datos de capacitación y generan salida de texto.
La efectividad de un modelo de lenguaje se evalúa típicamente utilizando métricas como la entropía cruzada y la perplejidad , que miden la capacidad del modelo para predecir la siguiente palabra con precisión (las cubriré en el paso 2 ). Varios conjuntos de datos, como Wikitext-2, Wikitext-103, un mil millones de palabras, Text8 y C4, entre otros, se usan comúnmente para evaluar los modelos de lenguaje. Nota : En este proyecto, uso wikitext-2.
La investigación de LM ha recibido una amplia atención en la literatura, que se puede dividir en cuatro etapas de desarrollo importantes:
Los SLM se desarrollan en base a métodos de aprendizaje estadístico que aumentaron en la década de 1990. La idea básica es construir el modelo de predicción de palabras basado en la suposición de Markov , por ejemplo, predecir la siguiente palabra basada en el contexto más reciente. Los SLM con una longitud de contexto fija n también se llaman modelos de lenguaje N-Gram , por ejemplo, modelos de lenguaje BigRam y Trigram. Los SLM se han aplicado ampliamente para mejorar el rendimiento de la tarea en la recuperación de información (IR) y el procesamiento del lenguaje natural (PNL). Sin embargo, a menudo sufren la maldición de la dimensionalidad:
Es difícil estimar con precisión los modelos de lenguaje de alto orden, ya que es necesario estimar un número exponencial de probabilidades de transición. Por lo tanto, se han introducido estrategias de suavizado especialmente diseñadas, como la estimación de retroceso y la buena estimación, para aliviar el problema de escasez de datos.
Los NLM caracterizan la probabilidad de secuencias de palabras por redes neuronales, por ejemplo, perceptrón de múltiples capas (MLP) y redes neuronales recurrentes (RNN). Como una contribución notable, es el concepto de representación distribuida . Representaciones distribuidas, también conocidas como incrustaciones , la idea es que el "significado" o el "contenido semántico" de un punto de datos se distribuye a través de múltiples dimensiones. Por ejemplo, en PNL, las palabras con significados similares se asignan a los puntos en el espacio vectorial que están cerca entre sí. Esta cercanía no es arbitraria, pero se aprende del contexto en el que aparecen las palabras. Este aprendizaje dependiente del contexto a menudo se logra a través de modelos de redes neuronales, como Word2vec o Glove , que procesan grandes corpus de texto para aprender estas representaciones.
Una de las ventajas clave de las representaciones distribuidas es su capacidad para capturar relaciones semánticas de grano fino. Por ejemplo, en un espacio de incrustación de palabras bien entrenado, los sinónimos estarían representados por vectores que están muy juntos, e incluso es posible realizar operaciones aritméticas con estos vectores que corresponden a operaciones semánticas significativas (por ejemplo, "rey" - "hombre" + "mujer" podría dar lugar a un vector cercano a la "reina").
Aplicaciones de representaciones distribuidas:
Las representaciones distribuidas tienen una amplia gama de aplicaciones, particularmente en tareas que involucran la comprensión del lenguaje natural. Se usan para:
Similitud de palabras : medir la similitud semántica entre las palabras.
Clasificación de texto : categorizar documentos en clases predefinidas.
Traducción automática : traducir texto de un idioma a otro.
Recuperación de información : encontrar documentos relevantes en respuesta a una consulta.
Análisis de sentimientos : Determinación del sentimiento expresado en una pieza de texto.
Además, las representaciones distribuidas no se limitan a los datos de texto. También se pueden aplicar a otros tipos de datos, como imágenes, donde los modelos de aprendizaje profundo aprenden a representar imágenes como vectores de alta dimensión que capturan las características visuales y la semántica.
Los modelos de lenguaje causal, también conocidos como modelos autorregresivos , generan texto prediciendo la siguiente palabra en una secuencia dadas las palabras anteriores. Estos modelos están entrenados para maximizar la probabilidad de la próxima palabra utilizando técnicas como la arquitectura del transformador. Durante el entrenamiento, la entrada al modelo es la secuencia completa hasta un token dado, y el objetivo del modelo es predecir el siguiente token. Este tipo de modelo es útil para tareas como la generación de texto , la finalización y el resumen .
Los modelos de lenguaje enmascarados (MLMS) están diseñados para aprender representaciones contextuales de palabras prediciendo palabras enmascaradas o faltantes en una oración. Durante el entrenamiento, una parte de la secuencia de entrada está enmascarada al azar, y el modelo está entrenado para predecir las palabras originales dadas el contexto. Las MLM usan arquitecturas bidireccionales como transformadores para capturar las dependencias entre las palabras enmascaradas y el resto de la oración. Estos modelos se destacan en tareas como la clasificación de texto , el reconocimiento de entidad nombrado y la respuesta de las preguntas .
Los modelos de secuencia a secuencia (SEQ2SEQ) están entrenados para mapear una secuencia de entrada a una secuencia de salida. Consisten en un codificador que procesa la secuencia de entrada y un decodificador que genera la secuencia de salida. Los modelos SEQ2SEQ se usan ampliamente en tareas como la traducción automática , el resumen de texto y los sistemas de diálogo . Pueden ser entrenados utilizando técnicas como redes neuronales recurrentes (RNN) o transformadores. El objetivo de entrenamiento es maximizar la probabilidad de generar la secuencia de salida correcta dada la entrada.
Es importante tener en cuenta que estos enfoques de capacitación no son mutuamente excluyentes , y los investigadores a menudo los combinan o emplean variaciones para lograr objetivos específicos. Por ejemplo, modelos como T5 combinan los objetivos de capacitación del modelo de lenguaje autorregresivo y enmascarado para aprender una amplia gama de tareas.
Cada enfoque de entrenamiento tiene sus propias fortalezas y debilidades, y la elección del modelo depende de los requisitos de tarea específicos y los datos de capacitación disponibles.
Para obtener más información, consulte el capítulo A Guide to Language Model Training en el sitio web "Medium.com".
El modelado de idiomas implica construir modelos que puedan generar o predecir secuencias de palabras o caracteres. Aquí hay algunos tipos diferentes de modelos comúnmente utilizados para el modelado de idiomas:
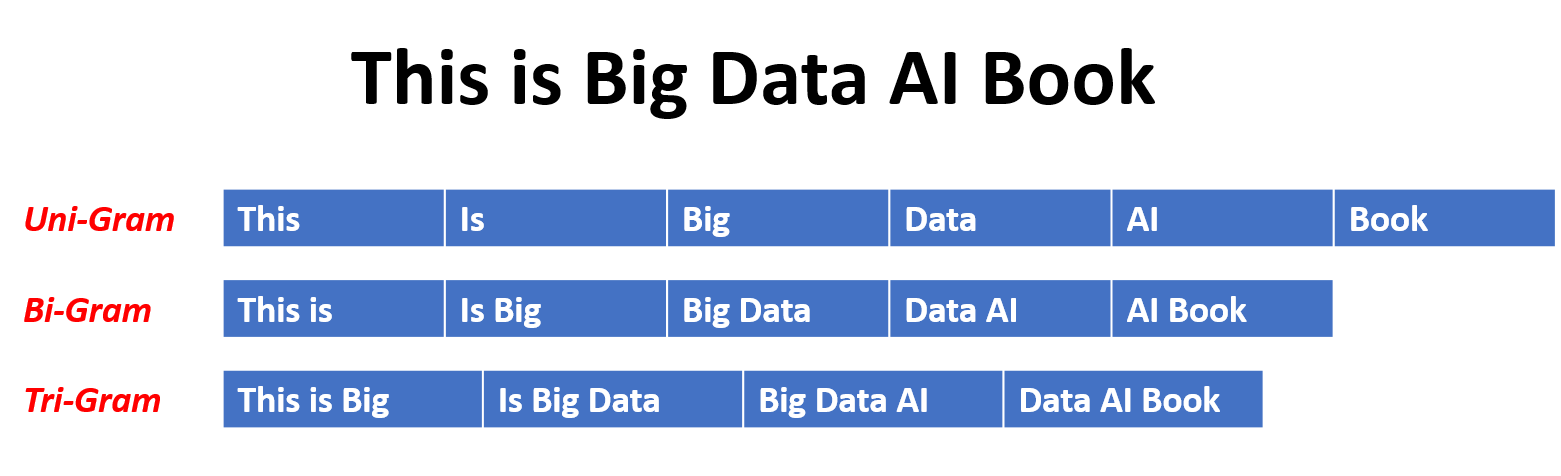
En un modelo N-Gram, la probabilidad de una palabra se estima en función de su ocurrencia en los datos de entrenamiento en relación con sus palabras N-1 anteriores. Por ejemplo, en un modelo de trigrama (n = 3), la probabilidad de una palabra está determinada por las dos palabras que lo preceden inmediatamente. Este enfoque supone que la probabilidad de una palabra depende solo de un número fijo de palabras anteriores y no considera dependencias de largo alcance.
Aquí hay algunos ejemplos de N-grams:
Estas son las ventajas y desventajas de los modelos de lenguaje N-Gram:
Ventajas :
Desventajas :
Aquí hay un ejemplo de usar N-Grams en TorchText:
import torchtext
from torchtext . data import get_tokenizer
from torchtext . data . utils import ngrams_iterator
tokenizer = get_tokenizer ( "basic_english" )
# Create a tokenizer object using the "basic_english" tokenizer provided by torchtext
# This tokenizer splits the input text into a list of tokens
tokens = tokenizer ( "I love to code in Python" )
# The result is a list of tokens, where each token represents a word or a punctuation mark
print ( list ( ngrams_iterator ( tokens , 3 )))
[ 'i' , 'love' , 'to' , 'code' , 'in' , 'python' , 'i love' , 'love to' , 'to code' , 'code in' , 'in python' , 'i love to' , 'love to code' , 'to code in' , 'code in python' ]Nota :
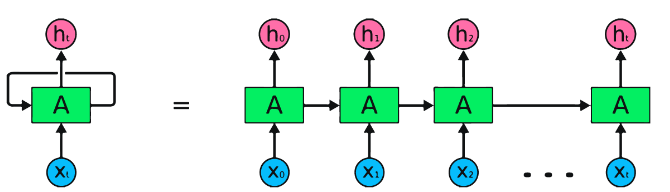
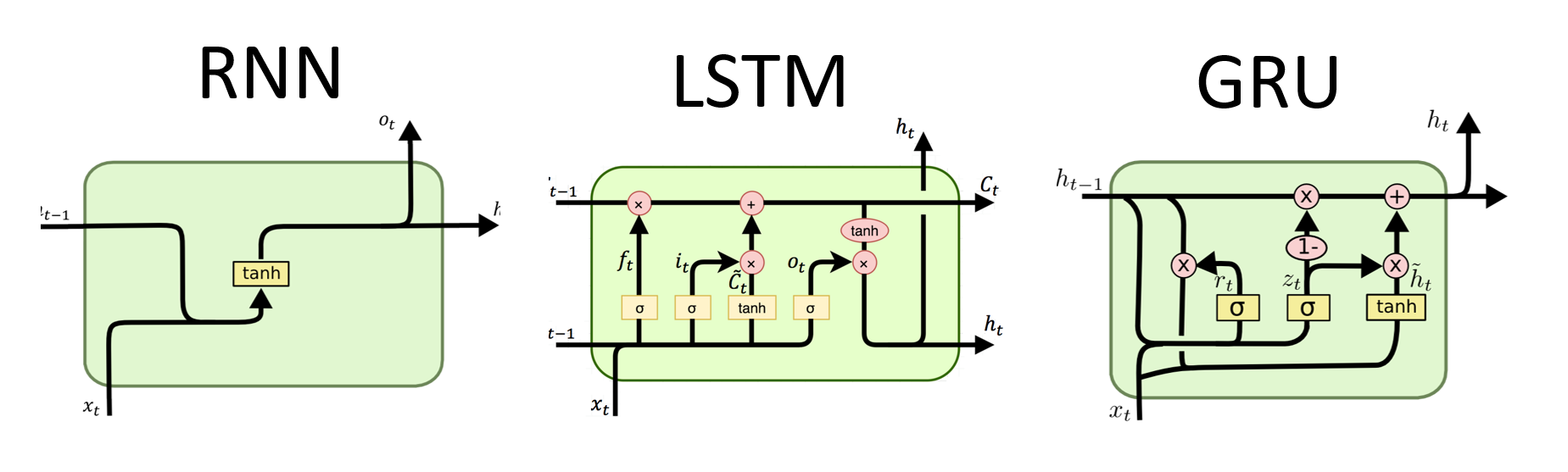
Los RNN son el tipo fundamental de red neuronal para el procesamiento de datos secuenciales. Tienen conexiones recurrentes que permiten que la información pase de un paso a otro, lo que les permite capturar dependencias a lo largo del tiempo. Sin embargo, los RNN tradicionales sufren el problema de gradiente de desaparición/explosión y la lucha con las dependencias a largo plazo.
Ventajas de RNN :
Desventajas de RNN :
Pytorch Code Fnippet para definir un RNN básico en Pytorch:
import torch
import torch . nn as nn
rnn = nn . RNN ( input_size = 10 , hidden_size = 20 , num_layers = 2 )
# input_size – The number of expected features in the input x
# hidden_size – The number of features in the hidden state h
# num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together
# Create a randomly initialized input tensor
input = torch . randn ( 5 , 3 , 10 ) # (sequence length=5, batch size=3, input size=10)
# Create a randomly initialized hidden state tensor
h0 = torch . randn ( 2 , 3 , 20 ) # (num_layers=2, batch size=3, hidden size=20)
# Apply the RNN module to the input tensor and initial hidden state tensor
output , hn = rnn ( input , h0 )
print ( output . shape ) # torch.Size([5, 3, 20])
# (sequence length=5, batch size=3, hidden size=20)
print ( hn . shape ) # torch.Size([2, 3, 20])
# (num_layers=2, batch size=3, hidden size=20)Ventajas de LSTM :
Desventajas de LSTM :
Fragmento de código de pytorch para definir un LSTM básico en Pytorch:
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
lstm = nn . LSTM ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
c0 = torch . zeros ( num_layers , batch_size , hidden_size )
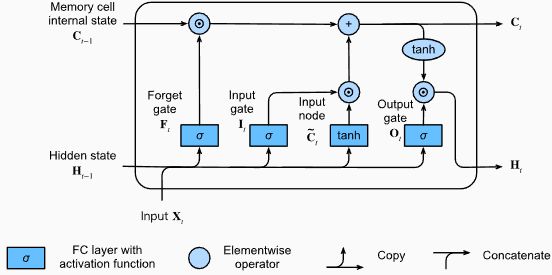
output , ( hn , cn ) = lstm ( input_data , ( h0 , c0 )) La forma de salida de la capa LSTM también será [seq_length, batch_size, hidden_size] . Esto significa que para cada entrada en la secuencia, habrá un estado oculto de salida correspondiente. En el ejemplo proporcionado, la forma de salida es torch.Size([10, 1, 64]) , lo que indica que el LSTM se aplicó a una secuencia de longitud 10, con un tamaño de lote de 1 y un tamaño de estado oculto de 64.
Ahora, discutamos el tensor hn (estado oculto). Su forma es torch.Size([2, 1, 64]) . La primera dimensión, 2, representa el número de capas en el LSTM. En este caso, el argumento num_layers se estableció en 2, por lo que hay 2 capas en el modelo LSTM. La segunda dimensión, 1, corresponde al tamaño del lote, que es 1 en el ejemplo dado. Finalmente, la última dimensión, 64, representa el tamaño del estado oculto.
Por lo tanto, el tensor hn contiene el estado oculto final para cada capa del LSTM después de procesar toda la secuencia de entrada, siguiendo la capacidad de LSTM para retener dependencias a largo plazo y mitigar el problema de gradiente de fuga.
Para obtener más información, consulte el capítulo de memoria a largo plazo (LSTM) en la documentación "Buce en el aprendizaje profundo".
Ventajas de Grus :
Desventajas de Grus :
En general, los modelos LSTM y Gru superan algunas de las limitaciones de los RNN tradicionales, particularmente en la captura de dependencias a largo plazo. Los LSTMS se destacan en la preservación de la información contextual, mientras que los grus ofrecen una alternativa más computacionalmente eficiente. La elección entre LSTM y Gru depende de los requisitos específicos de la tarea y los recursos computacionales disponibles.
import torch
import torch . nn as nn
input_size = 100
hidden_size = 64
num_layers = 2
batch_size = 1
seq_length = 10
gru = nn . GRU ( input_size , hidden_size , num_layers )
input_data = torch . randn ( seq_length , batch_size , input_size )
h0 = torch . zeros ( num_layers , batch_size , hidden_size )
output , hn = gru ( input_data , h0 ) La forma de salida de la capa Gru también será [seq_length, batch_size, hidden_size] . Esto significa que para cada entrada en la secuencia, habrá un estado oculto de salida correspondiente. En el ejemplo proporcionado, la forma de salida es torch.Size([10, 1, 64]) .
Ahora, discutamos el tensor hn (estado oculto). Su forma es torch.Size([2, 1, 64]) . La primera dimensión, 2, representa el número de capas en el Gru. En este caso, el argumento num_layers se estableció en 2, por lo que hay 2 capas en el modelo GRU. La segunda dimensión, 1, corresponde al tamaño del lote, que es 1 en el ejemplo dado. Finalmente, la última dimensión, 64, representa el tamaño del estado oculto.
Por lo tanto, el tensor hn contiene el estado oculto final para cada capa de la GRU después de procesar toda la secuencia de entrada, siguiendo la capacidad del GRU para capturar y retener información sobre secuencias largas mientras mitiga el problema de gradiente de fuga.
Para obtener más información, consulte el capítulo de unidades recurrentes (GRU) en la documentación "Buce en el aprendizaje profundo".
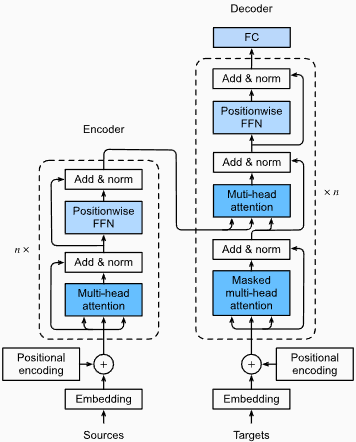
Ventajas :
Captura de dependencias de largo alcance: los transformadores sobresalen en la captura de dependencias de largo alcance en secuencias mediante el uso de mecanismos de autoatención. Esto les permite considerar todas las posiciones en la secuencia de entrada al hacer predicciones, permitir una mejor comprensión del contexto y mejorar la calidad del texto generado.
Procesamiento paralelo: a diferencia de los modelos recurrentes, los transformadores pueden procesar la secuencia de entrada en paralelo, haciéndolos altamente eficientes y reduciendo los tiempos de entrenamiento e inferencia. Esta paralelización es posible debido a la ausencia de dependencias secuenciales en la arquitectura.
Escalabilidad: los transformadores son altamente escalables y pueden manejar grandes secuencias de entrada de manera efectiva. Pueden procesar secuencias de longitudes arbitrarias sin la necesidad de truncamiento o relleno, lo que es particularmente ventajoso para tareas que involucran documentos o oraciones largas.
Comprensión contextual: los transformadores pueden capturar información contextual rica atendiendo a partes relevantes de la secuencia de entrada. Esto les permite comprender estructuras lingüísticas complejas, relaciones semánticas y dependencias entre las palabras, lo que resulta en una generación de lenguaje más coherente y contextualmente apropiada.
Desventajas de los modelos de transformadores :
Altos requisitos computacionales: los transformadores generalmente requieren recursos computacionales significativos en comparación con modelos más simples como N-Grams o RNN tradicionales. El entrenamiento de modelos de transformadores grandes con conjuntos de datos extensos puede ser computacionalmente costoso y lento.
Falta de modelado secuencial: mientras que los transformadores se destacan en la captura de dependencias globales, pueden no ser tan efectivos para modelar datos estrictamente secuenciales. En los casos en que el orden de la secuencia de entrada es crucial, como en las tareas que involucran datos de series temporales, RNN tradicionales o redes neuronales convolucionales (CNN) pueden ser más adecuadas.
Complejidad del mecanismo de atención: el mecanismo de autoeficiencia en los transformadores introduce una complejidad adicional para la arquitectura del modelo. Comprender e implementar los mecanismos de atención correctamente puede ser un desafío, y ajustar los hiperparámetros relacionados con la atención puede ser no trivial.
Requisitos de datos: los transformadores a menudo requieren grandes cantidades de datos de capacitación para lograr un rendimiento óptimo. El tratamiento previo en los corpus a gran escala, como en el caso de los modelos de transformadores previos a la aparición como GPT y Bert, es común para aprovechar el poder de los transformadores de manera efectiva.
Para obtener más información, consulte el Capítulo de Arquitectura del Transformador en la documentación "Buce en el aprendizaje profundo".
A pesar de estas limitaciones, los modelos de transformadores han revolucionado el campo del procesamiento del lenguaje natural y el modelado de idiomas. Su capacidad para capturar dependencias de largo alcance y comprensión contextual ha avanzado significativamente el estado del arte en diversas tareas relacionadas con el lenguaje, lo que las convierte en una opción destacada para muchas aplicaciones.
La perplejidad, en el contexto del modelado de lenguaje, es una medida que cuantifica qué tan bien un modelo de idioma predice un conjunto de pruebas dado, con una menor perplejidad que indica un mejor rendimiento predictivo. En términos más simples, la perplejidad se calcula tomando la probabilidad inversa del conjunto de pruebas y luego normalizándola por el número de palabras.
Cuanto menor sea el valor de perplejidad, mejor será el modelo de idioma para predecir el conjunto de pruebas. Minimizar la perplejidad es lo mismo que maximizar la probabilidad
La fórmula para la perplejidad como la probabilidad inversa del conjunto de pruebas, normalizada por el número de palabras, es la siguiente:
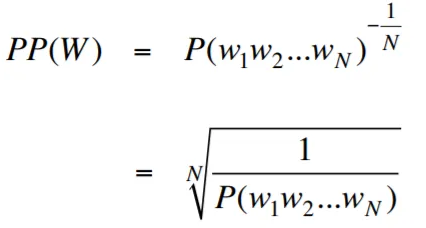

La perplejidad puede interpretarse como una medida del factor de ramificación en un modelo de lenguaje. El factor de ramificación representa el número promedio de las siguientes palabras o tokens posibles dado un contexto o secuencia particular de palabras.
El factor de ramificación de un lenguaje es el número de próximas palabras posibles que pueden seguir cualquier palabra. Podemos pensar en la perplejidad como el factor de ramificación promedio ponderado de un idioma.
El modelado de idiomas con capa de incrustación y código LSTM es una herramienta poderosa para construir y capacitar modelos de lenguaje. Esta implementación del código combina dos componentes fundamentales en el procesamiento del lenguaje natural: una capa de incrustación y una red larga de memoria a corto plazo (LSTM) .
La capa de incrustación es responsable de convertir los datos de texto en representaciones distribuidas, también conocidas como incrustaciones de palabras . Estas incrustaciones capturan propiedades semánticas y sintácticas de las palabras, lo que permite que el modelo comprenda el significado y el contexto del texto de entrada. La capa de incrustación mapea cada palabra en la secuencia de entrada a un vector de alta dimensión, que sirve como entrada para capas posteriores en el modelo.
La capa LSTM en la implementación del código procesa la palabra incrustaciones generadas por la capa de incrustación, capturando la información de secuencia y aprendiendo los patrones y estructuras subyacentes en el texto.
Al combinar la capa de incrustación y la red LSTM, el código permite la construcción de un modelo de idioma que puede generar texto coherente y contextualmente apropiado. Los modelos de lenguaje construidos utilizando este enfoque pueden ser capacitados en grandes conjuntos de datos textuales y son capaces de generar oraciones realistas y significativas, haciéndolas herramientas valiosas para diversas tareas de procesamiento del lenguaje natural, como la generación de texto, la traducción automática y el análisis de sentimientos.
Esta implementación del código proporciona una base simple, clara y concisa para construir modelos de lenguaje basados en la capa de incrustación y la arquitectura LSTM. Sirve como punto de partida para investigadores, desarrolladores y entusiastas que están interesados en explorar y experimentar con técnicas de modelado de idiomas de última generación.
A través de este código, puede obtener una comprensión más profunda de cómo las capas de incrustación y LSTM funcionan juntas para capturar los complejos patrones y dependencias dentro de los datos de texto. Con este conocimiento, puede extender aún más el código y explorar técnicas avanzadas, como incorporar mecanismos de atención o arquitecturas de transformadores, para mejorar el rendimiento y las capacidades de sus modelos de idiomas.
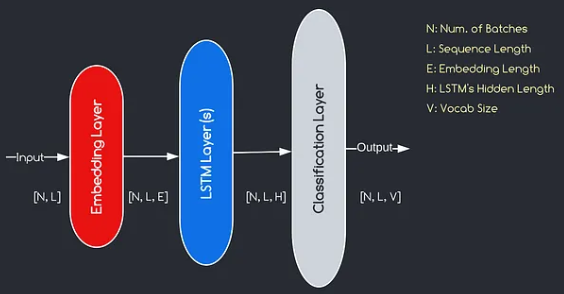
El modelo que construiremos corresponde al diagrama proporcionado anteriormente, ilustrando los tres componentes clave: una capa de incrustación, capas LSTM y una capa de clasificación. Si bien los objetivos de las capas LSTM y de clasificación ya nos son familiares, profundicemos en la importancia de la capa de incrustación.
La capa de incrustación juega un papel crucial en el modelo al transformar cada palabra, representada como un índice, en un vector de dimensiones E. Esta representación vectorial permite que las capas posteriores aprendan y extraen información significativa de la entrada. Vale la pena señalar que usar índices o vectores únicos para representar palabras puede ser inadecuado, ya que no asumen relaciones entre diferentes palabras.
El proceso de mapeo realizado por la capa de incrustación es un procedimiento aprendido que tiene lugar durante la capacitación. A través de esta fase de entrenamiento, el modelo gana la capacidad de asociar palabras con vectores específicos de una manera que captura relaciones semánticas y sintácticas, mejorando así la comprensión del modelo de la estructura del lenguaje subyacente.
El conjunto de datos WKITEXT-103, desarrollado por Salesforce, contiene más de 100 millones de tokens extraídos del conjunto de artículos verificados de bien y presentado en Wikipedia. Tiene 267,340 tokens únicos que aparecen al menos 3 veces en el conjunto de datos. Dado que tiene artículos de Wikipedia de longitud completa, el conjunto de datos se adapta bien a las tareas que pueden beneficiar a las dependencias a largo plazo, como el modelado de idiomas.
El conjunto de datos Wikitext-2 es una versión pequeña del conjunto de datos Wikitext-103, ya que contiene solo 2 millones de tokens. Este pequeño conjunto de datos es adecuado para probar su modelo de idioma.

Este repositorio contiene código para realizar análisis de datos exploratorios en el conjunto de datos UTK, que consiste en imágenes clasificadas por edad, género y etnia.
Para descargar un conjunto de datos con TorchText, puede usar el módulo torchtext.datasets . Aquí hay un ejemplo de cómo descargar el conjunto de datos Wikitext-2 usando TorchText:
import torchtext
from torchtext . datasets import WikiText2
data_path = "data"
train_iter , valid_iter , test_iter = WikiText2 ( root = data_path ) Inicialmente, intenté usar el código proporcionado para cargar el conjunto de datos Wikitext-2, pero encontré un problema con la URL (https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip) no funciona para mí. Para superar esto, decidí aprovechar la biblioteca torchtext y crear una implementación personalizada del cargador del conjunto de datos.
Dado que la URL original no funcionaba, descargué los conjuntos de datos del tren, la validación y probé de un repositorio de GitHub y los coloqué en el directorio 'data/datasets/WikiText2' .
Aquí hay un desglose del código:
import os
from typing import Union , Tuple
from torchdata . datapipes . iter import FileOpener , IterableWrapper
from torchtext . data . datasets_utils import _wrap_split_argument , _create_dataset_directory
DATA_DIR = "data"
NUM_LINES = {
"train" : 36718 ,
"valid" : 3760 ,
"test" : 4358 ,
}
DATASET_NAME = "WikiText2"
_EXTRACTED_FILES = {
"train" : "wiki.train.tokens" ,
"test" : "wiki.test.tokens" ,
"valid" : "wiki.valid.tokens" ,
}
def _filepath_fn ( root , split ):
return os . path . join ( root , _EXTRACTED_FILES [ split ])
@ _create_dataset_directory ( dataset_name = DATASET_NAME )
@ _wrap_split_argument (( "train" , "valid" , "test" ))
def WikiText2 ( root : str , split : Union [ Tuple [ str ], str ]):
url_dp = IterableWrapper ([ _filepath_fn ( DATA_DIR , split )])
data_dp = FileOpener ( url_dp , encoding = "utf-8" ). readlines ( strip_newline = False , return_path = False ). shuffle (). set_shuffle ( False ). sharding_filter ()
return data_dp Para usar el cargador de conjunto de datos wikitext-2, simplemente importe la función wikitext2 y llámelo con la división de datos deseada:
train_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "train" )
valid_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "valid" )
test_data = WikiText2 ( root = "data/datasets/WikiText2" , split = "test" )Esta implementación está inspirada en los cargadores oficiales del conjunto de datos TorchText y aprovecha las bibliotecas TorchData y TorchText para proporcionar una experiencia de carga de datos perfecta y eficiente.
Construir un vocabulario es un paso crucial en muchas tareas de procesamiento del lenguaje natural, ya que le permite representar palabras como identificadores únicos que pueden usarse en modelos de aprendizaje automático. Este documento de Markdown demuestra cómo construir un vocabulario a partir de un conjunto de datos de capacitación y guardarlo para uso futuro.
Aquí hay una función que encapsula el proceso de construcción y guardado de un vocabulario:
import torch
from torchtext . data . utils import get_tokenizer
from torchtext . vocab import build_vocab_from_iterator
def build_and_save_vocabulary ( train_iter , vocab_path = 'vocab.pt' , min_freq = 4 ):
"""
Build a vocabulary from the training data iterator and save it to a file.
Args:
train_iter (iterator): An iterator over the training data.
vocab_path (str, optional): The path to save the vocabulary file. Defaults to 'vocab.pt'.
min_freq (int, optional): The minimum frequency of a word to be included in the vocabulary. Defaults to 4.
Returns:
torchtext.vocab.Vocab: The built vocabulary.
"""
# Get the tokenizer
tokenizer = get_tokenizer ( "basic_english" )
# Build the vocabulary
vocab = build_vocab_from_iterator ( map ( tokenizer , train_iter ), specials = [ '<unk>' ], min_freq = min_freq )
# Set the default index to the unknown token
vocab . set_default_index ( vocab [ '<unk>' ])
# Save the vocabulary
torch . save ( vocab , vocab_path )
return vocabAsí es como puedes usar esta función:
# Assuming you have a training data iterator named `train_iter`
vocab = build_and_save_vocabulary ( train_iter , vocab_path = 'my_vocab.pt' )
# You can now use the vocabulary
print ( len ( vocab )) # 23652
print ( vocab ([ 'ebi' , 'AI' . lower (), 'qwerty' ])) # [0, 1973, 0] build_and_save_vocabulary toma tres argumentos: train_iter (un iterador sobre los datos de entrenamiento), vocab_path (la ruta para guardar el archivo de vocabulario, con un valor predeterminado de 'Vocab.Pt') y min_freq (la frecuencia mínima de una palabra que se incluirá en el vocabulario, con un valor predeterminado de 4).basic_english , que realiza la tokenización básica en el texto en inglés.build_vocab_from_iterator , pasando el iterador de datos de entrenamiento (después de la tokenización) y especificando el token especial '<unk>' y el umbral de frecuencia mínima.'<unk>' , lo que significa que cualquier palabra que no se encuentre en el vocabulario se asignará al token desconocido. Para usar esta función, debe tener un iterador de datos de entrenamiento llamado train_iter . Luego, puede llamar a la función build_and_save_vocabulary , pasando el train_iter y especificando la ruta del archivo de vocabulario deseada y el umbral de frecuencia mínima.
La función construirá el vocabulario, lo guardará en el archivo especificado y devolverá el objeto Vocab , que luego puede usar en sus tareas aguas abajo.
Este código proporciona una forma de analizar la longitud media de la oración en el conjunto de datos Wikitext-2. Aquí hay un desglose del código:
import matplotlib . pyplot as plt
def compute_mean_sentence_length ( data_iter ):
"""
Computes the mean sentence length for the given data iterator.
Args:
data_iter (iterable): An iterable of text data, where each element is a string representing a line of text.
Returns:
float: The mean sentence length.
"""
total_sentence_count = 0
total_sentence_length = 0
for line in data_iter :
sentences = line . split ( '.' ) # Split the line into individual sentences
for sentence in sentences :
tokens = sentence . strip (). split () # Tokenize the sentence
sentence_length = len ( tokens )
if sentence_length > 0 :
total_sentence_count += 1
total_sentence_length += sentence_length
mean_sentence_length = total_sentence_length / total_sentence_count
return mean_sentence_length
# Compute mean sentence length for each dataset
train_mean = compute_mean_sentence_length ( train_iter )
valid_mean = compute_mean_sentence_length ( valid_iter )
test_mean = compute_mean_sentence_length ( test_iter )
# Plot the results
datasets = [ 'Train' , 'Valid' , 'Test' ]
means = [ train_mean , valid_mean , test_mean ]
plt . figure ( figsize = ( 6 , 4 ))
plt . bar ( datasets , means )
plt . xlabel ( 'Dataset' )
plt . ylabel ( 'Mean Sentence Length' )
plt . title ( 'Mean Sentence Length in Wikitext-2' )
plt . grid ( True )
plt . show ()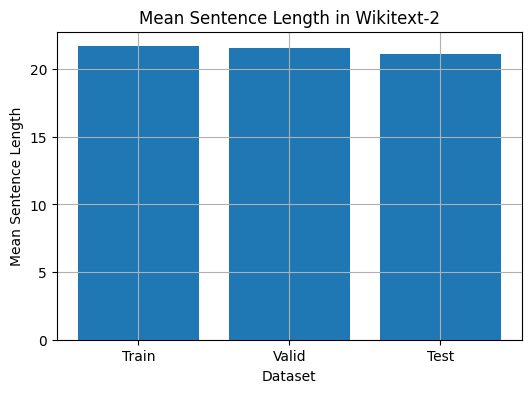
from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Find the 10 least common words
least_common_words = freqs . most_common ()[: - 11 : - 1 ]
print ( "Least Common Words:" )
for word , count in least_common_words :
print ( f" { word } : { count } " )
# Find the 10 most common words
most_common_words = freqs . most_common ( 10 )
print ( " n Most Common Words:" )
for word , count in most_common_words :
print ( f" { word } : { count } " ) from collections import Counter
# Compute word frequencies in the training dataset
freqs = Counter ()
for tokens in map ( tokenizer , train_iter ):
freqs . update ( tokens )
# Count the number of words that repeat 3, 4, and 5 times
count_3 = count_4 = count_5 = 0
for word , freq in freqs . items ():
if freq == 3 :
count_3 += 1
elif freq == 4 :
count_4 += 1
elif freq == 5 :
count_5 += 1
print ( f"Number of words that appear 3 times: { count_3 } " ) # 5130
print ( f"Number of words that appear 4 times: { count_4 } " ) # 3243
print ( f"Number of words that appear 5 times: { count_5 } " ) # 2261 from collections import Counter
import matplotlib . pyplot as plt
# Compute the word lengths in the training dataset
word_lengths = []
for tokens in map ( tokenizer , train_iter ):
word_lengths . extend ( len ( word ) for word in tokens )
# Create a frequency distribution of word lengths
word_length_counts = Counter ( word_lengths )
# Plot the word length distribution
plt . figure ( figsize = ( 10 , 6 ))
plt . bar ( word_length_counts . keys (), word_length_counts . values ())
plt . xlabel ( "Word Length" )
plt . ylabel ( "Frequency" )
plt . title ( "Word Length Distribution in Wikitext-2 Dataset" )
plt . show ()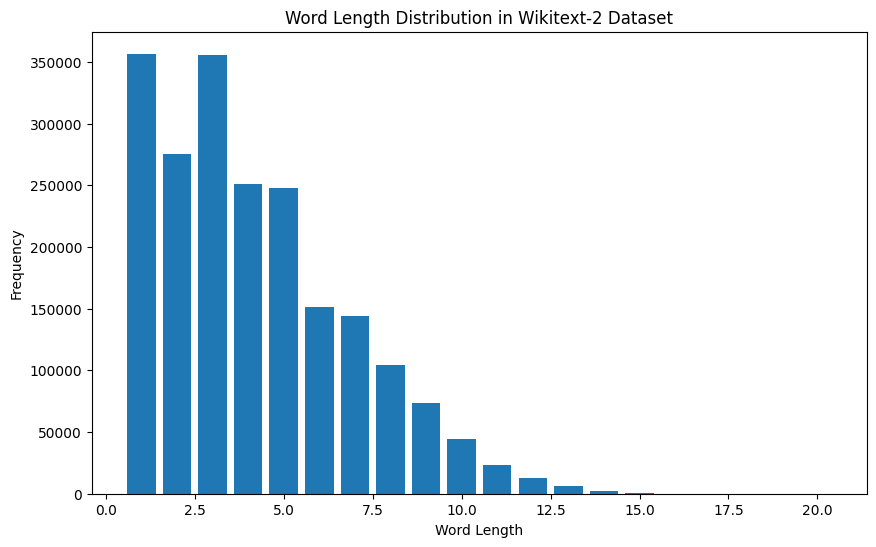
import spacy
import en_core_web_sm
# Load the small English language model from SpaCy
nlp = spacy . load ( "en_core_web_sm" )
# Alternatively, you can use the en_core_web_sm module to load the model
nlp = en_core_web_sm . load ()
# Process the given sentence using the loaded language model
doc = nlp ( "This is a sentence." )
# Print the text and part-of-speech tag for each token in the sentence
print ([( w . text , w . pos_ ) for w in doc ])
# [('This', 'PRON'), ('is', 'AUX'), ('a', 'DET'), ('sentence', 'NOUN'), ('.', 'PUNCT')]Para el conjunto de datos Wikitext-2:
import spacy
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform POS tagging on the training dataset
pos_tags = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
pos_tags . extend ([( token . text , token . pos_ ) for token in doc ])
# Count the frequency of each POS tag
pos_tag_counts = Counter ( tag for _ , tag in pos_tags )
# Print the most common POS tags
print ( "Most Common Part-of-Speech Tags:" )
for tag , count in pos_tag_counts . most_common ( 10 ):
print ( f" { tag } : { count } " )
# Visualize the POS tag distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( pos_tag_counts . keys (), pos_tag_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Part-of-Speech Tag" )
plt . ylabel ( "Frequency" )
plt . title ( "Part-of-Speech Tag Distribution in Wikitext-2 Dataset" )
plt . show ()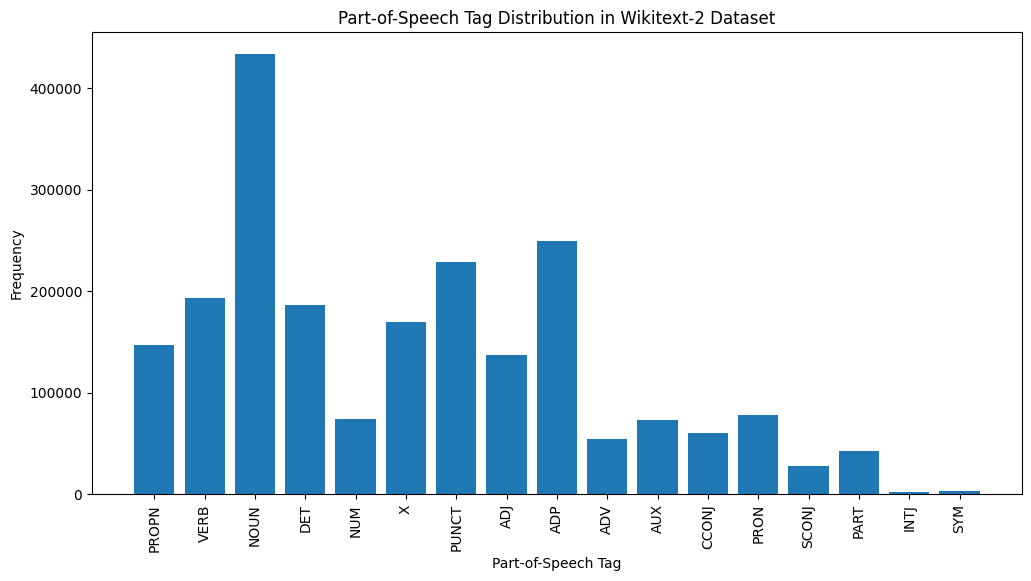
Aquí hay una breve explicación de las etiquetas POS más comunes en la salida proporcionada:
Sustantivo : los sustantivos representan personas, lugares, cosas o ideas.
ADP : las adposiciones, como las preposiciones y las posposiciones, se utilizan para expresar relaciones entre palabras o frases.
PUNT : puntos de puntuación, que son esenciales para separar y estructurar oraciones y texto.
Verbo : los verbos describen acciones, estados u ocurrencias en el texto.
Det : Determinadores, como los artículos (por ejemplo, "The," "A," An "), proporcionan información adicional sobre sustantivos.
X : Esta etiqueta a menudo se usa para palabras extranjeras, abreviaturas u otros tokens específicos del lenguaje que no se ajustan a las categorías POS estándar.
Propna : sustantivos propios, que representan nombres específicos de personas, lugares, organizaciones u otras entidades.
Adj : los adjetivos modifican o describen sustantivos y pronombres.
Pron : Los pronombres sustituyen a los sustantivos, haciendo que el texto sea más conciso y menos repetitivo.
NUM : Números, que representan cantidades, fechas u otra información numérica.
Esta distribución de etiquetas POS puede proporcionar información sobre las características lingüísticas del texto, como el predominio de los sustantivos, la prevalencia de adposiciones o el uso de sustantivos adecuados, que pueden ser útiles en tareas como clasificación de texto, extracción de información o análisis estilométrico.
import spacy
import matplotlib . pyplot as plt
# Load the English language model
nlp = spacy . load ( "en_core_web_sm" )
# Perform NER on the training dataset
named_entities = []
for tokens in map ( tokenizer , train_iter ):
doc = nlp ( " " . join ( tokens ))
named_entities . extend ([( ent . text , ent . label_ ) for ent in doc . ents ])
# Count the frequency of each named entity type
ner_counts = Counter ( label for _ , label in named_entities )
# Print the most common named entity types
print ( "Most Common Named Entity Types:" )
for label , count in ner_counts . most_common ( 10 ):
print ( f" { label } : { count } " )
# Visualize the named entity distribution
plt . figure ( figsize = ( 12 , 6 ))
plt . bar ( ner_counts . keys (), ner_counts . values ())
plt . xticks ( rotation = 90 )
plt . xlabel ( "Named Entity Type" )
plt . ylabel ( "Frequency" )
plt . title ( "Named Entity Distribution in Wikitext-2 Dataset" )
plt . show ()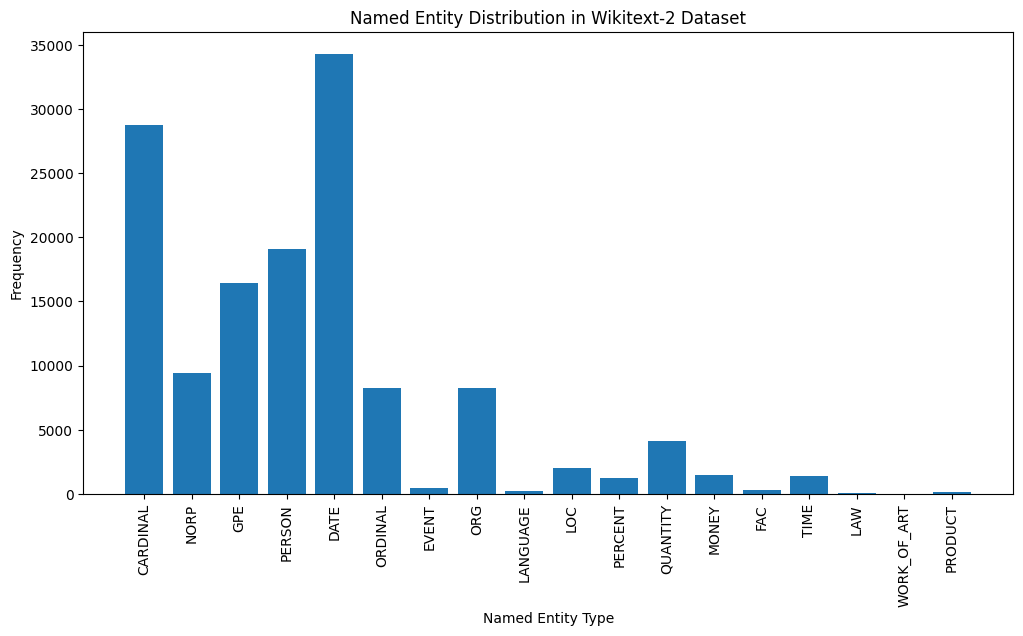
Here's a brief explanation of the most common named entity types in the output:
DATE : Represents specific dates, time periods, or temporal expressions, such as "June 15, 2024" or "last year".
CARDINAL : Includes numerical values, such as quantities, ages, or measurements.
PERSON : Identifies the names of individual people.
GPE (Geopolitical Entity): This entity type represents named geographical locations, such as countries, cities, or states.
NORP (Nationalities, Religious, or Political Groups): This entity type includes named groups or affiliations based on nationality, religion, or political ideology.
ORDINAL : Represents ordinal numbers, such as "first," "second," or "3rd".
ORG (Organization): The names of companies, institutions, or other organized groups.
QUANTITY : Includes non-numeric quantities, such as "a few" or "several".
LOC (Location): Represents named geographical locations, such as continents, regions, or landforms.
MONEY : Identifies monetary values, such as dollar amounts or currency names.
This distribution of named entity types can provide valuable insights into the content and focus of the text. For example, the prominence of DATE and CARDINAL entities may suggest a text that deals with numerical or temporal information, while the prevalence of PERSON, ORG, and GPE entities could indicate a text that discusses people, organizations, and geographical locations.
Understanding the named entity distribution can be useful in a variety of applications, such as information extraction, question answering, and text summarization, where identifying and categorizing key named entities is crucial for understanding the context and content of the text.
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the training dataset
with open ( "data/wiki.train.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Create a string from the entire training dataset
text = " " . join ( train_text )
# Generate the word cloud
wordcloud = WordCloud ( width = 800 , height = 400 , background_color = 'white' ). generate ( text )
# Plot the word cloud
plt . figure ( figsize = ( 12 , 8 ))
plt . imshow ( wordcloud , interpolation = 'bilinear' )
plt . axis ( 'off' )
plt . title ( 'Word Cloud for Wikitext-2 Training Dataset' )
plt . show ()
from sentence_transformers import SentenceTransformer
from sklearn . cluster import KMeans
from collections import defaultdict
from wordcloud import WordCloud
import matplotlib . pyplot as plt
# Load the BERT-based sentence transformer model
model = SentenceTransformer ( 'bert-base-nli-mean-tokens' )
# Load the training dataset
with open ( "data/wiki.valid.tokens" , "r" ) as f :
train_text = f . read (). split ()
# Compute the BERT embeddings for each unique word in the dataset
unique_words = set ( train_text )
word_embeddings = model . encode ( list ( unique_words ))
# Cluster the words using K-Means
num_clusters = 5
kmeans = KMeans ( n_clusters = num_clusters , random_state = 42 )
clusters = kmeans . fit_predict ( word_embeddings )
# Group the words by cluster
word_clusters = defaultdict ( list )
for i , word in enumerate ( unique_words ):
word_clusters [ clusters [ i ]]. append ( word )
# Create a word cloud for each cluster
fig , axes = plt . subplots ( 1 , 5 , figsize = ( 14 , 12 ))
axes = axes . flatten ()
for cluster_id , cluster_words in word_clusters . items ():
word_cloud = WordCloud ( width = 400 , height = 200 , background_color = 'white' ). generate ( ' ' . join ( cluster_words ))
axes [ cluster_id ]. imshow ( word_cloud , interpolation = 'bilinear' )
axes [ cluster_id ]. set_title ( f"Cluster { cluster_id } " )
axes [ cluster_id ]. axis ( 'off' )
plt . subplots_adjust ( wspace = 0.4 , hspace = 0.6 )
plt . tight_layout ()
plt . show ()
The two data formats, N x B x L and M x L , are commonly used in language modeling tasks, particularly in the context of neural network-based models.
N x B x L format:
N represents the number of batches. In this case, the dataset is divided into N smaller batches, which is a common practice to improve the efficiency and stability of the training process.B is the batch size, which represents the number of samples (eg, sentences, paragraphs, or documents) within each batch.L is the length of a sample within each batch, which typically corresponds to the number of tokens (words) in a sample. M x L format:
N x B x L format.M is equal to N x B , which represents the total number of samples (eg, sentences, paragraphs, or documents) in the dataset.L is the length of each sample, which corresponds to the number of tokens (words) in the sample. The choice between these two formats depends on the specific requirements of your language modeling task and the capabilities of the neural network architecture you're working with. If you're training a neural network-based language model, the N x B x L format is typically preferred, as it allows for efficient batch-based training and can lead to faster convergence and better performance. However, if your task doesn't involve neural networks or if the dataset is relatively small, the M x L format may be more suitable.
def prepare_language_model_data ( raw_text_iterator , sequence_length ):
"""
Prepare PyTorch tensors for a language model.
Args:
raw_text_iterator (iterable): An iterator of raw text data.
sequence_length (int): The length of the input and target sequences.
Returns:
tuple: A tuple containing two PyTorch tensors:
- inputs (torch.Tensor): A tensor of input sequences.
- targets (torch.Tensor): A tensor of target sequences.
"""
# Convert the raw text iterator into a single PyTorch tensor
data = torch . cat ([ torch . LongTensor ( vocab ( tokenizer ( line ))) for line in raw_text_iterator ])
# Calculate the number of complete sequences that can be formed
num_sequences = len ( data ) // sequence_length
# Calculate the remainder of the data length divided by the sequence length
remainder = len ( data ) % sequence_length
# If the remainder is 0, add a single <unk> token to the end of the data tensor
if remainder == 0 :
unk_tokens = torch . LongTensor ([ vocab [ '<unk>' ]])
data = torch . cat ([ data , unk_tokens ])
# Extract the input and target sequences from the data tensor
inputs = data [: num_sequences * sequence_length ]. reshape ( - 1 , sequence_length )
targets = data [ 1 : num_sequences * sequence_length + 1 ]. reshape ( - 1 , sequence_length )
print ( len ( inputs ), len ( targets ))
return inputs , targets sequence_length = 30
X_train , y_train = prepare_language_model_data ( train_iter , sequence_length )
X_valid , y_valid = prepare_language_model_data ( valid_iter , sequence_length )
X_test , y_test = prepare_language_model_data ( test_iter , sequence_length )
X_train . shape , y_train . shape , X_valid . shape , y_valid . shape , X_test . shape , y_test . shape
( torch . Size ([ 68333 , 30 ]),
torch . Size ([ 68333 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 7147 , 30 ]),
torch . Size ([ 8061 , 30 ]),
torch . Size ([ 8061 , 30 ])) This code defines a PyTorch Dataset class for working with language model data. The LanguageModelDataset class takes in input and target tensors and provides the necessary methods for accessing the data.
class LanguageModelDataset ( Dataset ):
def __init__ ( self , inputs , targets ):
self . inputs = inputs
self . targets = targets
def __len__ ( self ):
return self . inputs . shape [ 0 ]
def __getitem__ ( self , idx ):
return self . inputs [ idx ], self . targets [ idx ] The LanguageModelDataset class can be used as follows:
# Create the datasets
train_set = LanguageModelDataset ( X_train , y_train )
valid_set = LanguageModelDataset ( X_valid , y_valid )
test_set = LanguageModelDataset ( X_test , y_test )
# Create data loaders (optional)
train_loader = DataLoader ( train_set , batch_size = 32 , shuffle = True )
valid_loader = DataLoader ( valid_set , batch_size = 32 )
test_loader = DataLoader ( test_set , batch_size = 32 )
# Access the data
x_batch , y_batch = next ( iter ( train_loader ))
print ( f"Input batch shape: { x_batch . shape } " ) # Input batch shape: torch.Size([32, 30])
print ( f"Target batch shape: { y_batch . shape } " ) # Target batch shape: torch.Size([32, 30]) The code defines a custom PyTorch language model that allows you to use different types of word embeddings, including randomly initialized embeddings, pre-trained GloVe embeddings, pre-trained FastText embeddings, by simply specifying the embedding_type argument when creating the model instance.
import torch . nn as nn
from torchtext . vocab import GloVe , FastText
class LanguageModel ( nn . Module ):
def __init__ ( self , vocab_size , embedding_dim ,
hidden_dim , num_layers , dropout_embd = 0.5 ,
dropout_rnn = 0.5 , embedding_type = 'random' ):
super (). __init__ ()
self . num_layers = num_layers
self . hidden_dim = hidden_dim
self . embedding_dim = embedding_dim
self . embedding_type = embedding_type
if embedding_type == 'random' :
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . uniform_ ( - 0.1 , 0.1 )
elif embedding_type == 'glove' :
self . glove = GloVe ( name = '6B' , dim = embedding_dim )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . glove . vectors )
self . embedding . weight . requires_grad = False
elif embedding_type == 'fasttext' :
self . glove = FastText ( language = 'en' )
self . embedding = nn . Embedding ( vocab_size , embedding_dim )
self . embedding . weight . data . copy_ ( self . fasttext . vectors )
self . embedding . weight . requires_grad = False
else :
raise ValueError ( "Invalid embedding_type. Choose from 'random', 'glove', 'fasttext'." )
self . dropout = nn . Dropout ( p = dropout_embd )
self . lstm = nn . LSTM ( embedding_dim , hidden_dim , num_layers = num_layers ,
dropout = dropout_rnn , batch_first = True )
self . fc = nn . Linear ( hidden_dim , vocab_size )
def forward ( self , src ):
embedding = self . dropout ( self . embedding ( src ))
output , hidden = self . lstm ( embedding )
prediction = self . fc ( output )
return prediction model = LanguageModel ( vocab_size = len ( vocab ),
embedding_dim = 300 ,
hidden_dim = 512 ,
num_layers = 2 ,
dropout_embd = 0.65 ,
dropout_rnn = 0.5 ,
embedding_type = 'glove' ) def num_trainable_params ( model ):
nums = sum ( p . numel () for p in model . parameters () if p . requires_grad ) / 1e6
return nums
# Calculate the number of trainable parameters in the embedding, LSTM, and fully connected layers of the LanguageModel instance 'model'
num_trainable_params ( model . embedding ) # (7.0956)
num_trainable_params ( model . lstm ) # (3.76832)
num_trainable_params ( model . fc ) # (12.133476)

