whisper timestamped
v1.15.8
Многоязычное автоматическое распознавание речи с временными метками уровня слов и уверенностью.
Whisper-это набор многоязычных, надежных моделей распознавания речи, обученных OpenAI, которые достигают современных результатов на многих языках. Модели шепота были обучены для прогнозирования приблизительных временных метров на сегментах речевых (большую часть времени с 1 секундной точностью), но они изначально не могут предсказать временные метки слов. Этот репозиторий предлагает реализацию для прогнозирования слов временных метров и обеспечения более точной оценки речевых сегментов при транскрибировании с помощью моделей Whisper . Кроме того, оценка доверия присваивается каждому слову и каждому сегменту.
Подход основан на динамическом деформации времени (DTW), применяемой к весам перекрестного активации, как продемонстрировано этой ноутбуком Чон Вук Ким. Есть некоторые дополнения к этой записной книжке:
whisper-timestamped может обрабатывать длинные файлы с небольшим количеством дополнительной памяти по сравнению с регулярным использованием модели Whisper. whisper-timestamped -это расширение пакета Python openai-whisper и предназначен для совместимости с любой версией openai-whisper . Он обеспечивает более эффективные/точные временные метки слов, а также эти дополнительные функции:
Отказ от ответственности: Обратите внимание, что это расширение предназначено для экспериментальных целей и может значительно повлиять на производительность. Мы не несем ответственности за какие -либо проблемы или неэффективность, которые возникают в результате его использования.
Альтернативный соответствующий подход к восстановлению временных метков уровня слов включает использование моделей WAV2VEC, которые предсказывают символы, как успешно реализовано в Whisperx. Тем не менее, эти подходы имеют несколько недостатков, которые не присутствуют в подходах, основанных на весах перекрестных атак, таких как whisper_timestamped . Эти недостатки включают в себя:
Альтернативный подход, который не требует дополнительной модели, состоит в том, чтобы посмотреть на вероятности токенов TimeStamp, оцененных по модели Whisper после предсказанного токена (суб) слов. Это было реализовано, например, в Whisper.cpp и Stable-TS. Тем не менее, этот подход не хватает надежности, потому что модели шепота не были обучены выводу значимых временных метров после каждого слова. Модели шепота, как правило, предсказывают временные метки только после того, как было предсказано определенное количество слов (обычно в конце предложения), и распределение вероятности временных метров за пределами этого условия может быть неточным. На практике эти методы могут дать результаты, которые полностью не синхронизированы в течение некоторых периодов времени (мы наблюдали это, особенно когда есть музыка джингл). Кроме того, точность временной метки моделей шепота имеет тенденцию быть округленной до 1 секунды (как во многих видео субтитрах), что слишком неточна для слов, и достижение лучшей точности сложно.
Требования:
python3 (версия выше или равна 3,7, рекомендуется не менее 3,9)ffmpeg (см. Инструкции по установке в репозитории Whisper) Вы можете установить whisper-timestamped либо с помощью PIP:
pip3 install whisper-timestampedили клонируя этот репозиторий и запустив установку:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py installЕсли вы хотите построить выравнивание между аудиопомещениями и словами (как в этом разделе), вам также нужен Matplotlib:
pip3 install matplotlibЕсли вы хотите использовать опцию VAD (обнаружение голосовой активности перед запуском модели Whisper), вам также нужны Torchaudio и Onnxruntime:
pip3 install onnxruntime torchaudioЕсли вы хотите использовать Manetuned Whisper Models из Hub -Hub, вам также нужны трансформаторы:
pip3 install transformersИзображение Docker около 9 ГБ может быть построено с помощью:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .Если у вас нет графического процессора (или не хотите его использовать), вам не нужно устанавливать зависимости CUDA. Затем вам следует просто установить легкую версию Torch, прежде чем установить Whisper-Timested, например, следующим образом:
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.htmlКонкретное изображение Docker около 3,5 ГБ также может быть построено с помощью:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .При использовании PIP библиотека может быть обновлена до последней версии, используя:
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
Например: конкретная версия openai-whisper может быть использована, например:
pip3 install openai-whisper==20230124 В Python вы можете использовать функцию whisper_timestamped.transcribe() , что аналогично функции whisper.transcribe() :
import whisper_timestamped
help ( whisper_timestamped . transcribe ) Основное различие с whisper.transcribe() состоит в том, что вывод будет включать в себя ключевые "words" для всех сегментов, со словом начала и конечной позиции. Обратите внимание, что слово будет включать пунктуацию. См. Пример ниже.
Кроме того, параметры декодирования по умолчанию отличаются от эффективного декодирования (жадное декодирование вместо поиска пучка, и нет отбора проб температуры). Чтобы иметь то же самое по умолчанию, что и во whisper , используйте beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0) .
Есть также дополнительные варианты, связанные с выравниванием слов.
В общем, если вы импортируете whisper_timestamped вместо того, чтобы whisper в своем сценарии Python и использовать transcribe(model, ...) вместо model.transcribe(...) , он должен выполнять работу:
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) Обратите внимание, что вы можете использовать современную модель шепота из HuggingFace или локальную папку, используя метод load_model whisper_timestamped . Например, если вы хотите использовать Whisper-Large-V2-Nob, вы можете просто сделать следующее:
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ... Вы также можете использовать whisper_timestamped в командной строке, аналогично whisper . Смотрите помощь с:
whisper_timestamped --help Основные различия с whisper CLI:
--output_dir . для шепота по умолчанию.--verbose True для Whisper Default.--accurate (который является псевдонимом для --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 ).--compute_confidence , чтобы включить/отключить вычисление показателей доверия для каждого слова.--punctuations_with_words , чтобы решить, следует ли включать знаки препинания или нет с предыдущими словами. Пример команды для обработки нескольких файлов с использованием tiny модели и вывода результатов в текущей папке, как это будет сделано по умолчанию с Whisper, выглядит следующим образом:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Обратите внимание, что вы можете использовать модель Whisper с тонкой настройкой из Huggingface или локальной папки. Например, если вы хотите использовать модель Whisper-Large-V2-NOB, вы можете просто сделать следующее:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
В дополнение к основной функции transcribe , Whisper-Timested обеспечивает некоторые полезные функции:
remove_non_speechУдалите сегменты неречести из аудио, используя обнаружение голосовой активности (VAD).
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelЗагрузите модель Whisper с данного имени или пути, включая поддержку тонких настроенных моделей из HuggingFace.
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" ) Обратите внимание, что вы можете использовать опцию plot_word_alignment of whisper_timestamped.transcribe() Функция Python или опцию --plot of whisper_timestamped , чтобы увидеть выравнивание слова для каждого сегмента.
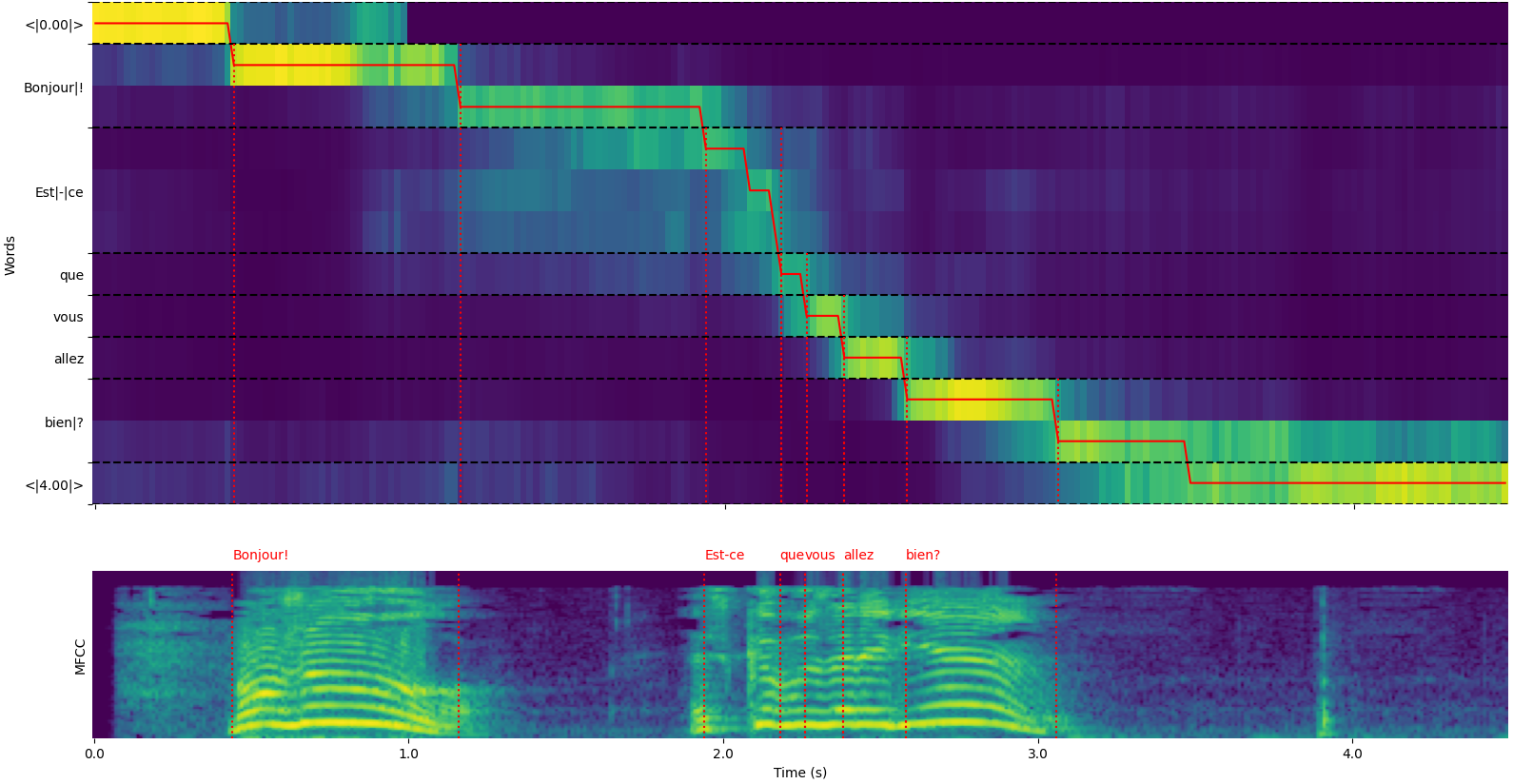
Вывод функции whisper_timestamped.transcribe() - это словарь Python, который можно просматривать в формате JSON с использованием CLI.
Схема JSON можно увидеть в тестах/json_schema.json.
Вот пример вывода:
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
} Если язык не указан (например, без опции --language fr в CLI), вы найдете дополнительный ключ с языковыми вероятностями:
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)Транскрибируйте звук, используя модель шепота и вычислите временные метки уровня слова.
model : шепотом модель экземпляра Whisper Model для использования для транскрипции.
audio : Union [str, np.ndarray, torch.tensor] Путь к аудиофайлу к транскрибибе или звуковой форме в виде массива Numpy или тензора Pytorch.
language : str, необязательный (по умолчанию: нет) язык аудио. Если нет, будет выполнено обнаружение языка.
task : str, по умолчанию «транскрибировать» задачу для выполнения: либо «транскрибировать» для распознавания речи или «перевод» для перевода на английский.
vad : Union [Bool, STR, List [Tuple [float, Float]]], необязательно (по умолчанию: false), следует ли использовать обнаружение голосовой активности (VAD) для удаления сегментов, не являющихся речью. Может быть:
detect_disfluencies : BOOL, FALLE DEFAULT DOTE DETECT и MARD DISFLUERE (колебания, слова наполнителя и т. Д.) В транскрипции.
trust_whisper_timestamps : bool, по умолчанию True, будьте полагаться на временные метки Whisper для начальных позиций сегмента.
compute_word_confidence : BOOL, по умолчанию TRUE, будь то вычислять оценки доверия для слов.
include_punctuation_in_confidence : bool, false по умолчанию, если включить вероятность препинания при вычислении доверия слова.
refine_whisper_precision : Float, по умолчанию 0,5 Сколько нужно уточнить позиции сегмента шепота, за секунды. Должен быть кратный 0,02.
min_word_duration : float, по умолчанию 0,02 Минимальная продолжительность слова, в секундах.
plot_word_alignment : bool или str, по умолчанию ложно, независимо от того, чтобы построить слово выравнивание для каждого сегмента. Если строка, сохраните график в данном файле.
word_alignement_most_top_layers : int, необязательно (по умолчанию: нет) количество верхних слоев для использования для выравнивания слов. Если нет, используйте все слои.
remove_empty_words : bool, ложь по умолчанию, удаляет ли слова без продолжительности в конце сегментов.
naive_approach : BOOL, ложная сила по умолчанию ПАНЕТ ДВАЙСКИЙ подход к декодированию (один раз для транскрипции, один раз для выравнивания).
use_backend_timestamps : bool, false по умолчанию, независимо от того, используют липотные метки слов, предоставленные бэкэнд (Openai-Whisper или Transformers), вместо тех, которые вычисляются более сложной эвристикой для Whisper-Timested.
temperature : объединение [float, список [float]], по умолчанию 0,0 температура для отбора проб. Может быть единственным значением или списком для резервных температур.
compression_ratio_threshold : float, по умолчанию 2.4 Если коэффициент сжатия GZIP выше этого значения, обрабатывать декодирование как неудачное.
logprob_threshold : float, по умолчанию -1,0 Если средняя вероятность журнала ниже этого значения, обрабатывать декодирование как неудачное.
no_speech_threshold : float, по умолчанию 0,6 Порог вероятности для <| nospeech |> tokens.
condition_on_previous_text : bool, по умолчанию true, чтобы предоставить предыдущий вывод в качестве подсказки для следующего окна.
initial_prompt : str, необязательный (по умолчанию: нет) необязательный текст, чтобы предоставить в качестве подсказки для первого окна.
suppress_tokens : str, по умолчанию "-1", разделенный запятыми списками идентификаторов токена для подавления во время отбора проб.
fp16 : Bool, необязательный (по умолчанию: нет), следует ли выполнять вывод в точке FP16.
verbose : Bool или нет, по умолчанию False, чтобы отобразить текст, декодированный в консоли. Если это правда, отображает все детали. Если false, отображает минимальные детали. Если нет, ничего не отображает.
Словарь, содержащий:
text : Str - полный текст транскрипцииsegments : Список [DICT] - Список словарей сегмента, каждый из которых содержит:id : INT - ID сегментаseek : int - начальная позиция в аудиофайле (в образцах)start : float - время начала сегмента (за секунды)end : Float - время окончания сегмента (за секунды)text : Str - транскрибированный текст для сегментаtokens : список [int] - идентификаторы токена для сегментаtemperature : поплавок - температура, используемая для этого сегментаavg_logprob : FLOAT - Средняя вероятность журнала сегментаcompression_ratio : Float - соотношение сжатия сегментаno_speech_prob : float - вероятность отсутствия речи в сегментеconfidence : плавание - счет доверия для сегментаwords : Список [DICT] - Список словесных слоев, каждый из которых содержит:start : Float - время начала слова (в секундах)end : Float - время окончания слова (в секунды)text : str - слово текстconfidence : плавание - оценка доверия для слова (если вычислено)language : Str - обнаружен или указанный языкlanguage_probs : DICT - Вероятности обнаружения языка (если применимо) RuntimeError : если метод VAD не установлен или настроен должным образом.ValueError : если refine_whisper_precision не является положительным кратным 0,02.AssertionError : Если длительность звука короче ожидаемого или если в количестве сегментов есть несоответствия. naive_approach может быть полезен для отладки или при работе с конкретными характеристиками аудио, но он может быть медленнее, чем подход по умолчанию.use_efficient_by_default true, некоторые параметры, такие как best_of , beam_size и temperature_increment_on_fallback не по умолчанию устанавливаются по умолчанию для более эффективной обработки.remove_non_speech(audio, **kwargs)Удалите сегменты неречести из аудио, используя обнаружение голосовой активности (VAD).
audio : Torch.tensor Audio Data в виде тензора Pytorch.
use_sample : bool, по умолчанию false Если верно, верните время начала и окончания в образцах вместо секунд.
min_speech_duration : float, по умолчанию 0,1 Минимальная продолжительность речевого сегмента за секунды.
min_silence_duration : float, по умолчанию 1 Минимальная продолжительность сегмента молчания за несколько секунд.
dilatation : плавает, по умолчанию 0,5 Сколько, чтобы увеличить каждый сегмент речи, обнаруженный VAD, за несколько секунд.
sample_rate : int, по умолчанию 16000 SAISE STARD AUDIO.
method : STR или List [Tuple [Float, Float]], метод по умолчанию «Silero» VAD для использования. Может быть «Силеро», «Аудиток» или список временных метров.
avoid_empty_speech : bool, по умолчанию false, если истина, избегайте возврата пустого сегмента речи.
plot : Союз [Bool, Str], по умолчанию false, если верно, график результатов VAD. Если строка, сохраните график в данном файле.
Кортеж, содержащий:
ImportError : Если требуемая библиотека VAD (например, Auditok) не установлена.ValueError : если указан неверный метод VAD. load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)Загрузите модель шепота с данного имени или пути.
name : Имя модели или путь к модели. Может быть:
device : Union [str, torch.device], необязательное (по умолчанию: нет) устройство для использования. Если нет, используйте CUDA, если доступно, иначе ЦП.
backend : Str, по умолчанию «Openai-Whisper» бэкэнд для использования. Либо "Трансформеры" или "Openai-Wisper".
download_root : str, необязательный (по умолчанию: нет) корневая папка для загрузки модели. Если нет, используйте корень загрузки по умолчанию.
in_memory : bool, false по умолчанию, предварительно загружать веса модели в память хоста.
Загруженная модель шепота.
ValueError : если указан неверный бэкэнд.ImportError : Если библиотека трансформаторов не установлена при использовании бэкэнда «трансформаторов».RuntimeError : если модель не может быть найдена или загружена из указанного источника.OSError : Если есть проблемы с чтением файла модели или доступа к указанному пути. get_alignment_heads(model, max_top_layer=3)Получите головы выравнивания для данной модели.
model : Чепоточный экземпляр модели. Модель шепота, для которой можно получить головы выравнивания.
max_top_layer : int, по умолчанию 3 Максимальное количество верхних слоев для рассмотрения для выравнивания головок.
Редкий тензор, представляющий головы выравнивания.
Следующие функции доступны для написания транскриптов в различных форматах файлов:
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)Запишите данные транскрипта в файл CSV.
transcript : список [DICT] Список словарей сегмента транскриптов.
file : Файл-подобный объектный файл для записи данных CSV.
sep : Str, по умолчанию »,« Разделитель для использования в файле CSV.
text_first : bool, по умолчанию true Если true, напишите текстовый столбец перед началом/окончанием.
format_timestamps : Callible, необязательный (по умолчанию: нет) Функция для формата значений временной метки.
header : Union [Bool, List [str]], по умолчанию false, если верно, напишите заголовок по умолчанию. Если список, используйте как пользовательский заголовок.
IOError : Если есть проблемы, написанные в указанном файле.ValueError : если данные транскрипта не находятся в ожидаемом формате. format_timestamps позволяет создавать пользовательское форматирование значений временных метров, что может быть полезно для конкретных вариантов использования или требований анализа данных. write_srt(transcript, file)Записать данные транскрипта в файл SRT (SubRip Subtitle).
transcript : список [DICT] Список словарей сегмента транскриптов.
file : Файл-подобный объектный файл для записи данных SRT.
IOError : Если есть проблемы, написанные в указанном файле.ValueError : если данные транскрипта не находятся в ожидаемом формате. write_vtt(transcript, file)Запишите данные транскрипта в файл VTT (WebVTT).
transcript : список [DICT] Список словарей сегмента транскриптов.
file : Файл-подобный объектный файл для записи данных VTT.
IOError : Если есть проблемы, написанные в указанном файле.ValueError : если данные транскрипта не находятся в ожидаемом формате. write_tsv(transcript, file)Запишите данные транскрипта в файл TSV (разделенные вкладками) файл.
transcript : список [DICT] Список словарей сегмента транскриптов.
file : файл, похожий на файл объекта для записи данных TSV.
IOError : Если есть проблемы, написанные в указанном файле.ValueError : если данные транскрипта не находятся в ожидаемом формате. Вот некоторые параметры, которые не включены по умолчанию, но могут улучшить результаты.
Как упоминалось ранее, некоторые параметры декодирования отключены по умолчанию, чтобы обеспечить лучшую эффективность. Однако это может повлиять на качество транскрипции. Чтобы работать с вариантами, которые имеют наилучшую вероятность обеспечения хорошей транскрипции, используйте следующие варианты.
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ... Модели шепота могут «галлюцинировать» текст при получении сегмента без речи. Этого можно избежать, запустив VAD и приклеивая сегменты речи вместе перед транскрибированием с помощью модели Whisper. Это возможно с помощью whisper-timestamped .
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...По умолчанию используемый метод VAD является Silero. Но доступны другие методы, такие как более ранние версии Silero или Auditok. Эти методы были введены, потому что последние версии Silero VAD могут иметь много ложных тревог на некоторых звуках (речь, обнаруженная на молчании).
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... Чтобы наблюдать за результатами VAD, вы можете использовать опцию --plot Opport of whisper_timestamped CLI или опцию plot_word_alignment функции python whisper_timestamped.transcribe() . Он покажет результаты VAD на входном аудиосигнале следующим образом (ось X-время в секундах):
| vad = "silero: v4.0" | vad = "silero: v3.1" | vad = "auditok" |
|---|---|---|
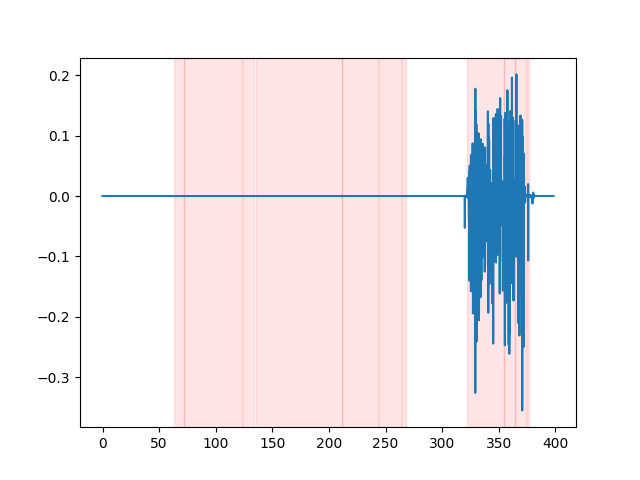 | 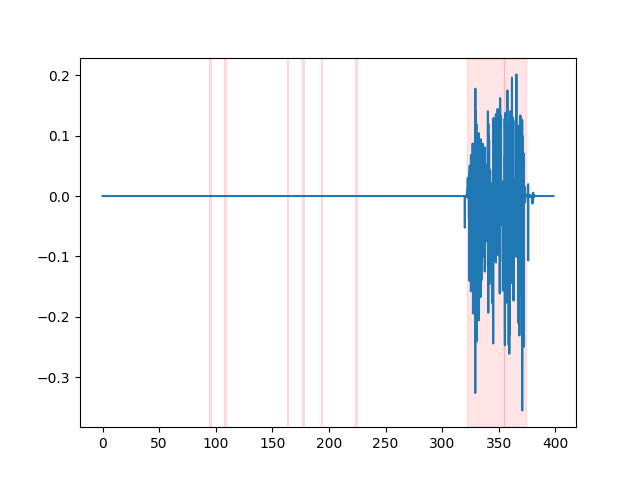 | 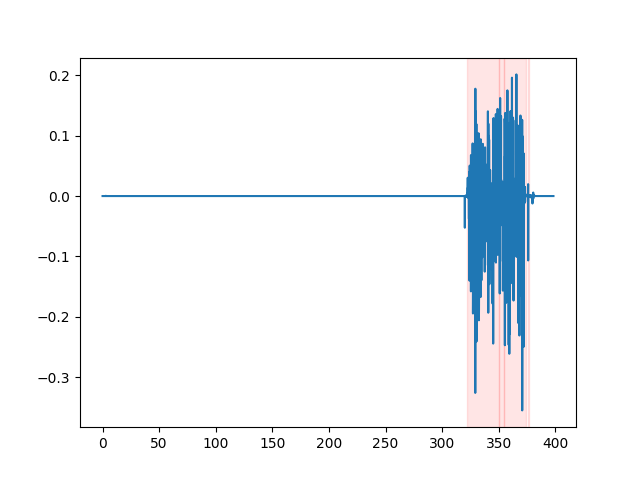 |
Модели шепота, как правило, устраняют речевые недостатки (слова наполнителя, колебания, повторения и т. Д.). Без мер предосторожности дисфунируемые недостатки не будут влиять на временную метку следующего слова: временная метка начала слова на самом деле будет временной меткой начала недостатков. whisper-timestamped может иметь некоторую эвристику, чтобы избежать этого.
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ... ВАЖНО: Обратите внимание, что при использовании этих вариантов возможные недостатки появятся в транскрипции как специальное слово « [*] ».
Если вы используете это в своем исследовании, пожалуйста, укажите репо:
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}а также шепота Openai:
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}И эта статья для динамического времени:
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

