whisper timestamped
v1.15.8
Reconocimiento de voz automático multilingüe con marcas de tiempo a nivel de palabra y confianza.
Whisper es un conjunto de modelos de reconocimiento de voz multilingües y robustos entrenados por OpenAI que logran resultados de última generación en muchos idiomas. Los modelos Whisper fueron entrenados para predecir las marcas de tiempo aproximadas en los segmentos del habla (la mayoría de las veces con precisión de 1 segundo), pero originalmente no pueden predecir las marcas de tiempo de las palabras. Este repositorio propone una implementación para predecir las marcas de tiempo de palabras y proporcionar una estimación más precisa de los segmentos del habla al transcribir con modelos Whisper . Además, se asigna un puntaje de confianza a cada palabra y a cada segmento.
El enfoque se basa en la deformación de tiempo dinámico (DTW) aplicado a los pesos de atención cruzada, como lo demuestra este cuaderno por Jong Wook Kim. Hay algunas adiciones a este cuaderno:
whisper-timestamped puede procesar archivos largos con poca memoria adicional en comparación con el uso regular del modelo Whisper. whisper-timestamped es una extensión del paquete Python openai-whisper y está destinado a ser compatible con cualquier versión de openai-whisper . Proporciona marcas de tiempo de palabras más eficientes/precisas, junto con esas características adicionales:
Descargo de responsabilidad: Tenga en cuenta que esta extensión está destinada a fines experimentales y puede afectar significativamente el rendimiento. No somos responsables de ningún problema o ineficiencia que surja de su uso.
Un enfoque alternativo relevante para recuperar marcas de tiempo a nivel de palabras implica el uso de modelos WAV2VEC que predicen los personajes, como se implementa con éxito en Whisperx. Sin embargo, estos enfoques tienen varios inconvenientes que no están presentes en los enfoques basados en pesos de atención cruzada como whisper_timestamped . Estos inconvenientes incluyen:
Un enfoque alternativo que no requiere un modelo adicional es analizar las probabilidades de los tokens de marca de tiempo estimados por el modelo Whisper después de que se predice cada token de palabras (sub). Esto se implementó, por ejemplo, en Whisper.cpp y Stable-TS. Sin embargo, este enfoque carece de robustez porque los modelos Whisper no han sido entrenados para obtener marcas de tiempo significativas después de cada palabra. Los modelos Whisper tienden a predecir las marcas de tiempo solo después de que se hayan predicho un cierto número de palabras (generalmente al final de una oración), y la distribución de probabilidad de las marcas de tiempo fuera de esta condición puede ser inexacta. En la práctica, estos métodos pueden producir resultados que están totalmente fuera de sincronización en algunos períodos de tiempo (observamos esto, especialmente cuando hay música de jingle). Además, la precisión de la marca de tiempo de los modelos Whisper tiende a redondearse a 1 segundo (como en muchos subtítulos de video), lo que es demasiado inexacto para las palabras, y alcanzar una mejor precisión es complicado.
Requisitos:
python3 (versión más alta o igual a 3.7, al menos 3.9 se recomienda)ffmpeg (consulte las instrucciones para la instalación en el repositorio de susurros) Puede instalar whisper-timestamped utilizando PIP:
pip3 install whisper-timestampedo clonando este repositorio y ejecutando la instalación:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py installSi desea trazar la alineación entre las marcas de tiempo de audio y las palabras (como en esta sección), también necesita matplotlib:
pip3 install matplotlibSi desea usar la opción VAD (detección de actividades de voz antes de ejecutar el modelo Whisper), también necesita Torchaudio y Onnxruntime:
pip3 install onnxruntime torchaudioSi desea usar modelos Whisper Finetuned del Hub Face, también necesita transformadores:
pip3 install transformersSe puede construir una imagen Docker de aproximadamente 9GB usando:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .Si no tiene una GPU (o no quiere usarla), entonces no necesita instalar las dependencias CUDA. Luego debe instalar una versión ligera de la antorcha antes de instalar Whisper-Timestamped, por ejemplo, como sigue:
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.htmlTambién se puede construir una imagen específica de Docker de aproximadamente 3.5GB usando:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .Al usar PIP, la biblioteca se puede actualizar a la última versión utilizando:
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
Se puede usar una versión específica de openai-whisper ejecutando, por ejemplo:
pip3 install openai-whisper==20230124 En Python, puede usar la función whisper_timestamped.transcribe() , que es similar a la función whisper.transcribe() ::
import whisper_timestamped
help ( whisper_timestamped . transcribe ) La principal diferencia con whisper.transcribe() es que la salida incluirá una "words" clave para todos los segmentos, con la posición de inicio y finalización de la palabra. Tenga en cuenta que la palabra incluirá puntuación. Vea el ejemplo a continuación.
Además, las opciones de decodificación predeterminadas son diferentes para favorecer la decodificación eficiente (decodificación codiciosa en lugar de la búsqueda del haz, y sin alternativa de muestreo de temperatura). Para tener el mismo valor predeterminado que en whisper , use beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0) .
También hay opciones adicionales relacionadas con la alineación de palabras.
En general, si importa whisper_timestamped en lugar de whisper en su script de Python y use transcribe(model, ...) en lugar de model.transcribe(...) , debe hacer el trabajo:
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) Tenga en cuenta que puede usar un modelo Whisper Finetuned desde Huggingface o una carpeta local utilizando el método load_model de whisper_timestamped . Por ejemplo, si desea usar Whisper-Large-V2-nob, simplemente puede hacer lo siguiente:
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ... También puede usar whisper_timestamped en la línea de comando, de manera similar a whisper . Ver ayuda con:
whisper_timestamped --help Las principales diferencias con whisper CLI son:
--output_dir . para Whisper predeterminado.--verbose True para whisper predeterminado.--accurate (que es un alias para --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 ).--compute_confidence para habilitar/deshabilitar el cálculo de los puntajes de confianza para cada palabra.--punctuations_with_words para decidir si los signos de puntuación deben incluirse o no con palabras anteriores. Un comando de ejemplo para procesar varios archivos utilizando el modelo tiny y producir los resultados en la carpeta actual, como se haría de forma predeterminada con Whisper, es el siguiente:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Tenga en cuenta que puede usar un modelo Whisper ajustado desde Huggingface o una carpeta local. Por ejemplo, si desea usar el modelo Whisper-Large-V2-Nob, simplemente puede hacer lo siguiente:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
Además de la función transcribe principal, Whisper-Timestamped proporciona algunas funciones de utilidad:
remove_non_speechElimine los segmentos de no voz del audio utilizando la detección de actividad de voz (VAD).
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelCargue un modelo de susurro de un nombre o ruta de pila, incluido el soporte para modelos ajustados desde Huggingface.
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" ) Tenga en cuenta que puede usar la opción plot_word_alignment de la función whisper_timestamped.transcribe() python o la opción --plot de la CLI whisper_timestamped para ver la alineación de palabras para cada segmento.
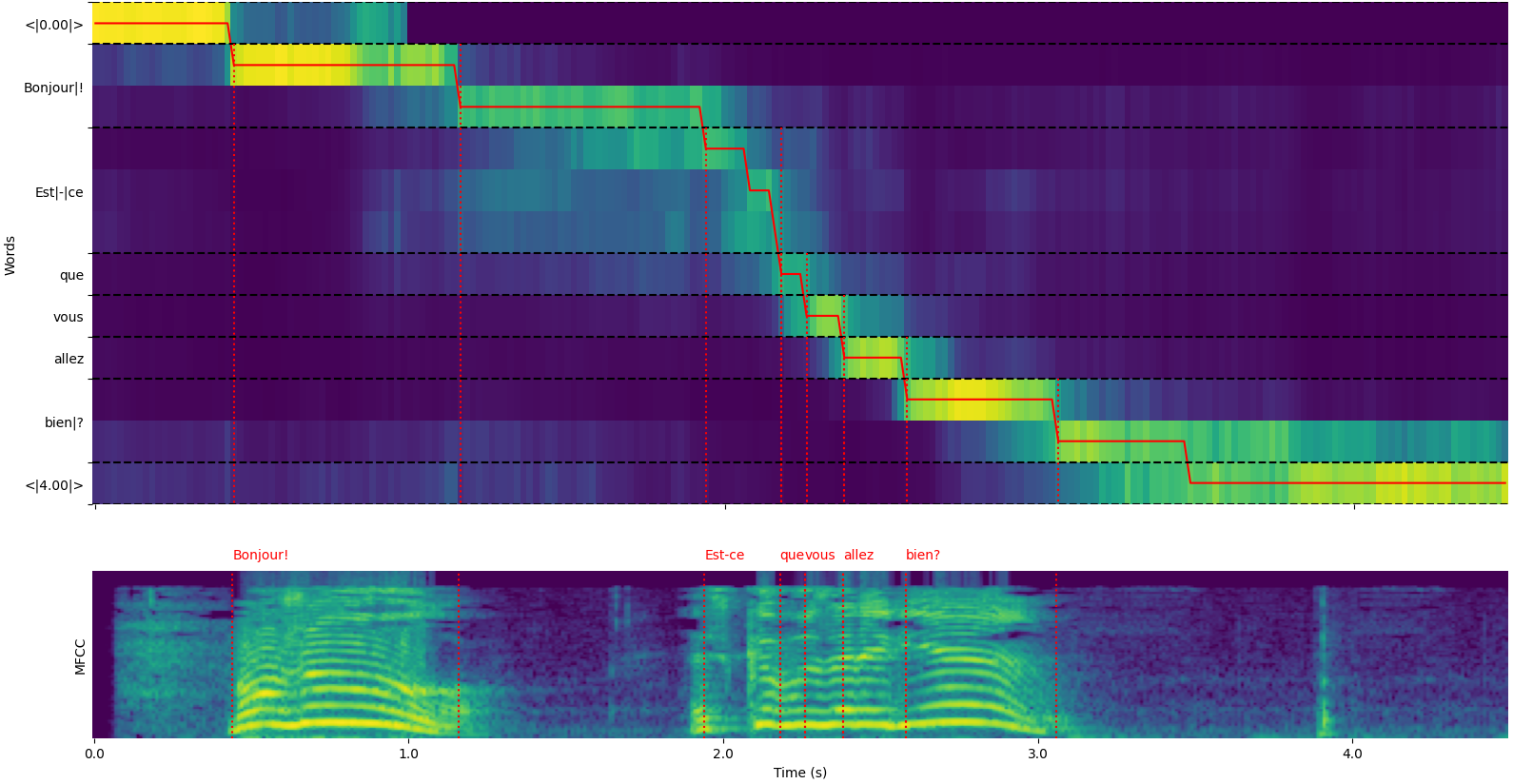
La salida de whisper_timestamped.transcribe() función es un diccionario de Python, que se puede ver en formato JSON utilizando la CLI.
El esquema JSON se puede ver en las pruebas/json_schema.json.
Aquí hay una salida de ejemplo:
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
} Si no se especifica el idioma (por ejemplo, sin opción --language fr en la CLI) encontrará una clave adicional con las probabilidades del idioma:
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)Transcribe audio usando un modelo Whisper y calcule las marcas de tiempo a nivel de palabra.
model : Instancia del modelo Whisper El modelo Whisper para usar para la transcripción.
audio : Union [STR, NP.NDArray, Torch.Tensor] La ruta al archivo de audio para transcribir, o la forma de onda de audio como una matriz numpy o tensor de pytorch.
language : STR, Opcional (predeterminado: Ninguno) El idioma del audio. Si no, se realizará la detección del idioma.
task : STR, predeterminada "transcribir" la tarea para realizar: "transcribir" para el reconocimiento de voz o "traducir" para la traducción al inglés.
vad : Union [Bool, Str, List [Tuple [Float, Float]]], Opcional (predeterminado: FALSO) Si se debe usar la detección de actividad de voz (VAD) para eliminar los segmentos sin voz. Puede ser:
detect_disfluencies : bool, falso predeterminado si debe detectar y marcar disfluencias (dudas, palabras de relleno, etc.) en la transcripción.
trust_whisper_timestamps : bool, predeterminado es cierto si confiar en las marcas de tiempo de Whisper para las posiciones de segmento iniciales.
compute_word_confidence : bool, verdadero verdadero si calcula los puntajes de confianza para las palabras.
include_punctuation_in_confidence : bool, predeterminado falso si se debe incluir la probabilidad de puntuación al calcular la confianza de las palabras.
refine_whisper_precision : flotante, predeterminado 0.5 cuánto refinar las posiciones de segmento de susurro, en segundos. Debe ser un múltiplo de 0.02.
min_word_duration : Float, predeterminado 0.02 Duración mínima de una palabra, en segundos.
plot_word_alignment : bool o str, predeterminado falso si traza la alineación de la palabra para cada segmento. Si es una cadena, guarde el diagrama en el archivo dado.
word_alignement_most_top_layers : int, opcional (predeterminado: ninguno) número de capas superiores para usar para la alineación de palabras. Si ninguna, usa todas las capas.
remove_empty_words : bool, falso predeterminado si debe eliminar las palabras sin duración al final de los segmentos.
naive_approach : bool, Falsa falsa predeterminada El enfoque ingenuo de decodificar dos veces (una vez para la transcripción, una vez para la alineación).
use_backend_timestamps : bool, falso predeterminado si se utiliza marcas de tiempo de palabras proporcionadas por el backend (openAI-Whisper o Transformers), en lugar de las calculadas por heurísticas más complejas de Whisper-Timestamped.
temperature : unión [flotante, lista [flotante]], temperatura predeterminada de 0.0 para el muestreo. Puede ser un valor único o una lista para temperaturas de retroalimentación.
compression_ratio_threshold : flotante, predeterminado 2.4 Si la relación de compresión GZIP está por encima de este valor, trate la decodificación como fallida.
logprob_threshold : float, predeterminado -1.0 Si la probabilidad de registro promedio está por debajo de este valor, trate la decodificación como fallida.
no_speech_threshold : FLOAT, umbral de probabilidad predeterminado 0.6 para <| nospeech |> tokens.
condition_on_previous_text : bool, predeterminado verdadero si proporcionar la salida anterior como un mensaje para la siguiente ventana.
initial_prompt : str, opcional (predeterminado: ninguno) texto opcional para proporcionar como un mensaje para la primera ventana.
suppress_tokens : STR, Lista de comasas "-1" predeterminada de ID de token para suprimir durante el muestreo.
fp16 : BOOL, Opcional (predeterminado: Ninguno) Si realizar una inferencia en la precisión FP16.
verbose : bool o ninguno, falso predeterminado si muestra el texto que se decodifica a la consola. Si es cierto, muestra todos los detalles. Si False, muestra detalles mínimos. Si ninguno, no muestra nada.
Un diccionario que contiene:
text : STR - El texto de la transcripción completasegments : Lista [DICT] - Lista de diccionarios de segmentos, cada uno que contiene:id : int - ID de segmentoseek : int - Inicie la posición en el archivo de audio (en muestras)start : Float - Hora de inicio del segmento (en segundos)end : Float - Tiempo de finalización del segmento (en segundos)text : STR - Texto transcrito para el segmentotokens : List [int] - ID de token para el segmentotemperature : Flotación: temperatura utilizada para este segmentoavg_logprob : FLOAT - Probabilidad de registro promedio del segmentocompression_ratio : flotación - relación de compresión del segmentono_speech_prob : FLOAT - Probabilidad de ningún discurso en el segmentoconfidence : Flotación - Puntuación de confianza para el segmentowords : Lista [dict] - Lista de diccionarios de palabras, cada uno que contiene:start : Float - Hora de inicio de la palabra (en segundos)end : Float - Tiempo de finalización de la palabra (en segundos)text : Str - la palabra textoconfidence : Float - Puntuación de confianza para la palabra (si se calcula)language : Str - Idioma detectado o especificadolanguage_probs : DICT - Probabilidades de detección de idiomas (si corresponde) RuntimeError : si el método VAD no está instalado o configurado correctamente.ValueError : si el refine_whisper_precision no es un múltiplo positivo de 0.02.AssertionError : Si la duración de audio es más corta de lo esperado o si hay inconsistencias en el número de segmentos. naive_approach puede ser útil para la depuración o cuando se trata de características de audio específicas, pero puede ser más lento que el enfoque predeterminado.use_efficient_by_default es verdadero, algunos parámetros como best_of , beam_size y temperature_increment_on_fallback se establecen en ninguno de forma predeterminada para un procesamiento más eficiente.remove_non_speech(audio, **kwargs)Elimine los segmentos de no voz del audio utilizando la detección de actividad de voz (VAD).
audio : Torch.Tensor Audio Data como un tensor Pytorch.
use_sample : bool, predeterminado falso si es verdadero, returación de inicio y finalización en muestras en lugar de segundos.
min_speech_duration : Float, predeterminado 0.1 Duración mínima de un segmento de voz en segundos.
min_silence_duration : flotante, predeterminado 1 duración mínima de un segmento de silencio en segundos.
dilatation : Flotación, predeterminada 0.5 cuánto ampliar cada segmento de habla detectado por VAD, en segundos.
sample_rate : int, tasa de muestra predeterminada 16000 del audio.
method : STR o List [Tuple [Float, Float]], Método VAD "Silero" predeterminado para usar. Puede ser "Silero", "Auditok" o una lista de marcas de tiempo.
avoid_empty_speech : bool, predeterminado Falso Si es verdadero, evite devolver un segmento de habla vacío.
plot : Union [Bool, Str], predeterminado falso si es verdadero, traza los resultados de VAD. Si es una cadena, guarde el diagrama en el archivo dado.
Una tupla que contiene:
ImportError : si no está instalada la biblioteca VAD requerida (por ejemplo, Auditok).ValueError : si se especifica un método VAD inválido. load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)Cargue un modelo de susurro a partir de un nombre o ruta.
name : Nombre STR del modelo o ruta al modelo. Puede ser:
device : Union [STR, Torch.device], Opcional (predeterminado: ninguno) dispositivo para usar. Si ninguno, use CUDA si está disponible, de lo contrario CPU.
backend : STR, el backend predeterminado "OpenAI-Whisper" para usar. "Transformadores" o "OpenAi-Whisper".
download_root : str, opcional (predeterminado: none) carpeta raíz para descargar el modelo a. Si ninguno, use la raíz de descarga predeterminada.
in_memory : bool, predeterminado falso si precarga los pesos del modelo en la memoria del host.
El modelo de susurro cargado.
ValueError : si se especifica un backend inválido.ImportError : si la biblioteca Transformers no está instalada cuando se usa el backend "Transformers".RuntimeError : si el modelo no se puede encontrar o descargar desde la fuente especificada.OSError : si hay problemas para leer el archivo modelo o acceder a la ruta especificada. get_alignment_heads(model, max_top_layer=3)Obtenga los cabezales de alineación para el modelo dado.
model : Instancia del modelo Whisper El modelo Whisper para el cual recuperar cabezas de alineación.
max_top_layer : int, predeterminado 3 número máximo de capas superiores a considerar para los cabezales de alineación.
Un tensor escaso que representa los cabezales de alineación.
Las siguientes funciones están disponibles para escribir transcripciones a varios formatos de archivo:
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)Escriba datos de transcripción en un archivo CSV.
transcript : lista [dict] Lista de diccionarios de segmento de transcripción.
file : archivo de objeto similar al archivo para escribir los datos de CSV.
sep : STR, Predeterminado "," Separador para usar en el archivo CSV.
text_first : bool, predeterminado verdadero si es verdadero, escriba la columna de texto antes de inicio/finalización.
format_timestamps : Función Callable, Opcional (predeterminado: Ninguno) para formatear los valores de la marca de tiempo.
header : Union [bool, list [str]], predeterminado falso si es verdadero, escriba el encabezado predeterminado. Si es una lista, use como encabezado personalizado.
IOError : Si hay problemas que escriben en el archivo especificado.ValueError : si los datos de transcripción no están en el formato esperado. format_timestamps permite el formato personalizado de los valores de la marca de tiempo, que puede ser útil para casos de uso específicos o requisitos de análisis de datos. write_srt(transcript, file)Escriba datos de transcripción en un archivo SRT (subtítulo Subrip).
transcript : lista [dict] Lista de diccionarios de segmento de transcripción.
file : archivo de objeto similar al archivo para escribir los datos SRT.
IOError : Si hay problemas que escriben en el archivo especificado.ValueError : si los datos de transcripción no están en el formato esperado. write_vtt(transcript, file)Escriba datos de transcripción en un archivo VTT (WebVTT).
transcript : lista [dict] Lista de diccionarios de segmento de transcripción.
file : archivo de objeto similar al archivo para escribir los datos VTT.
IOError : Si hay problemas que escriben en el archivo especificado.ValueError : si los datos de transcripción no están en el formato esperado. write_tsv(transcript, file)Escriba datos de transcripción en un archivo TSV (valores separados por tabulación).
transcript : lista [dict] Lista de diccionarios de segmento de transcripción.
file : archivo de objeto similar al archivo para escribir los datos de TSV.
IOError : Si hay problemas que escriben en el archivo especificado.ValueError : si los datos de transcripción no están en el formato esperado. Aquí hay algunas opciones que no están habilitadas de forma predeterminada, pero que pueden mejorar los resultados.
Como se mencionó anteriormente, algunas opciones de decodificación están deshabilitadas de forma predeterminada para ofrecer una mejor eficiencia. Sin embargo, esto puede afectar la calidad de la transcripción. Para ejecutar con las opciones que tienen la mejor oportunidad de proporcionar una buena transcripción, use las siguientes opciones.
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ... Los modelos Whisper pueden "alucinar" el texto cuando se le da un segmento sin discurso. Esto se puede evitar ejecutando VAD y pegando segmentos de habla antes de transcribir con el modelo Whisper. Esto es posible con whisper-timestamped .
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...Por defecto, el método VAD utilizado es Silero. Pero hay otros métodos disponibles, como versiones anteriores de Silero o Auditok. Esos métodos se introdujeron porque las últimas versiones de Silero Vad pueden tener muchas falsas alarmas en algunos audios (discurso detectado en silencio).
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... Para observar los resultados de VAD, puede usar la opción --plot de la CLI whisper_timestamped , o la opción plot_word_alignment de la función whisper_timestamped.transcribe() python. Mostrará los resultados de VAD en la señal de audio de entrada a continuación (el eje X es el tiempo en segundos):
| vad = "silero: v4.0" | vad = "silero: v3.1" | vad = "Auditok" |
|---|---|---|
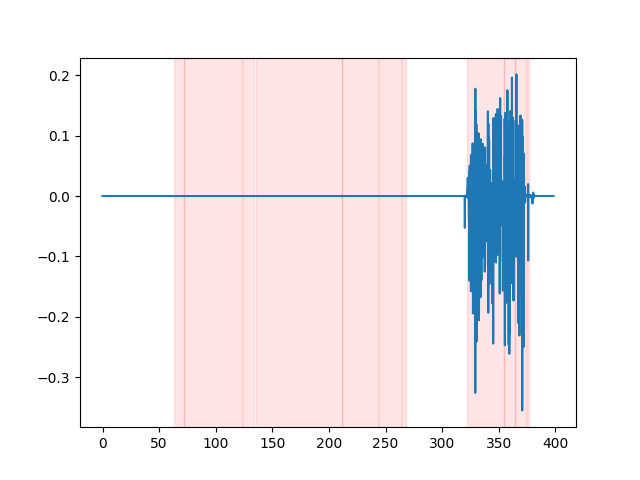 | 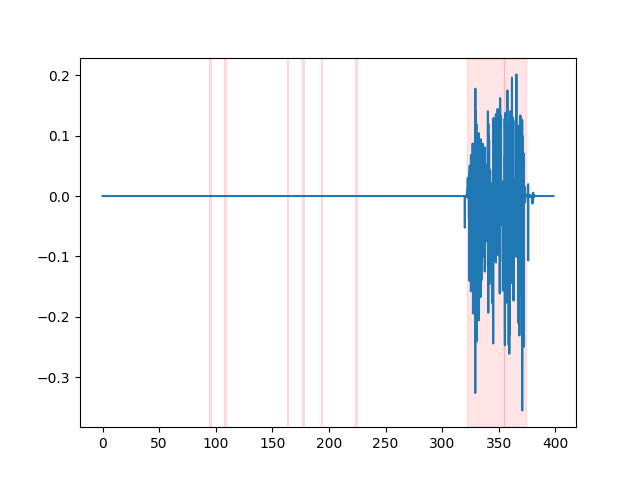 | 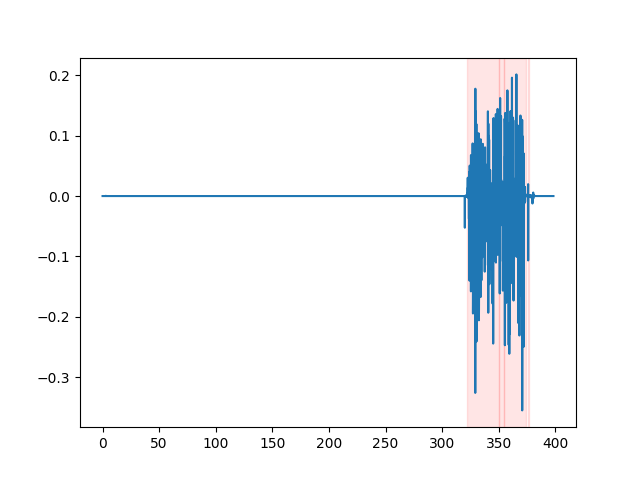 |
Los modelos Whisper tienden a eliminar las disfluencias del habla (palabras de relleno, dudas, repeticiones, etc.). Sin precauciones, las disfluencias que no se transcriben afectarán la marca de tiempo de la siguiente palabra: la marca de tiempo del comienzo de la palabra será la marca de tiempo del comienzo de las disfluencias. whisper-timestamped puede tener algunas heurísticas para evitar esto.
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ... IMPORTANTE: Tenga en cuenta que al usar estas opciones, las posibles disfluencias aparecerán en la transcripción como una palabra especial " [*] ".
Si usa esto en su investigación, cite el repositorio:
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}así como el papel de Operai Whisper:
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}Y este documento para la guerra dinámica: el tiempo:
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

