whisper timestamped
v1.15.8
Mehrsprachige automatische Spracherkennung mit Zeitstempeln und Vertrauen auf Wortebene.
Whisper ist eine Reihe von mehrsprachigen, robusten Spracherkennungsmodellen, die von OpenAI trainiert wurden und die in vielen Sprachen hochmoderne Ergebnisse erzielen. Flüstermodelle wurden geschult, um ungefähre Zeitstempel in Sprachsegmenten (meistens mit 1-Sekunden-Genauigkeit) vorherzusagen, aber sie können ursprünglich die Wortstempel ursprünglich nicht vorhersagen. Dieses Repository schlägt eine Implementierung vor, um die Word -Zeitstempel vorherzusagen und eine genauere Schätzung von Sprachsegmenten bei der Transkription mit Flüstermodellen zu liefern . Außerdem wird jedem Wort und jedem Segment eine Vertrauensbewertung zugeordnet.
Der Ansatz basiert auf dynamischen Zeitverzerrungen (DTW), die auf Kreuzbekämpfungsgewichte angewendet werden, wie dieses Notebook von Jong Wook Kim zeigt. Dieses Notizbuch gibt einige Ergänzungen:
whisper-timestamped kann lange Dateien mit wenig zusätzlichem Speicher im Vergleich zur regelmäßigen Verwendung des Flüstermodells verarbeiten. whisper-timestamped ist eine Erweiterung des openai-whisper -Python-Pakets und soll mit jeder Version von openai-whisper kompatibel sein. Es bietet effizientere/genauere Wortstempel sowie diese zusätzlichen Funktionen:
Haftungsausschluss: Bitte beachten Sie, dass diese Erweiterung für experimentelle Zwecke bestimmt ist und die Leistung erheblich beeinflussen kann. Wir sind nicht verantwortlich für Probleme oder Ineffizienzen, die sich aus ihrer Verwendung ergeben.
Ein alternativer relevanter Ansatz zur Wiederherstellung von Zeitstempeln auf Wortebene besteht darin, WAV2VEC-Modelle zu verwenden, die Charaktere vorhersagen, die in Whisperx erfolgreich implementiert sind. Diese Ansätze haben jedoch mehrere Nachteile, die in Ansätzen, die auf kreuzbezogenen Gewichten wie whisper_timestamped basieren, nicht vorhanden sind. Diese Nachteile umfassen:
Ein alternativer Ansatz, bei dem kein zusätzliches Modell erforderlich ist, besteht darin, die Wahrscheinlichkeiten von Zeitstempel -Token zu untersuchen, die vom Flüstermodell nach jedem (Sub-) Wort -Token vorhergesagt werden. Dies wurde beispielsweise in Whisper.cpp und Stable-Ts implementiert. In diesem Ansatz fehlt jedoch Robustheit, da Flüstern nicht so geschult wurden, nach jedem Wort aussagekräftige Zeitstempel auszugeben. Flüstungsmodelle neigen dazu, Zeitstempel erst vorherzusagen, nachdem eine bestimmte Anzahl von Wörtern vorhergesagt wurde (typischerweise am Ende eines Satzes), und die Wahrscheinlichkeitsverteilung von Zeitstempeln außerhalb dieser Bedingung kann ungenau sein. In der Praxis können diese Methoden zu einigen Zeiten zu Ergebnissen führen (wir haben dies insbesondere dann beobachtet, wenn es sich um Jingle-Musik handelt). Außerdem wird die Zeitstempelpräzision von Flüstermodellen tendenziell auf 1 Sekunde gerundet (wie in vielen Video -Untertiteln), was für Wörter zu ungenau ist, und es ist schwierig, eine bessere Genauigkeit zu erreichen.
Anforderungen:
python3 (Version höher oder gleich 3,7, mindestens 3,9 wird empfohlen)ffmpeg (Siehe Anweisungen zur Installation im Whisper -Repository) Sie können mit PIP whisper-timestamped installieren:
pip3 install whisper-timestampedoder indem Sie dieses Repository klonen und Installation ausführen:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py installWenn Sie die Ausrichtung zwischen Audio -Zeitstempeln und Wörtern (wie in diesem Abschnitt) planen möchten, benötigen Sie auch Matplotlib:
pip3 install matplotlibWenn Sie die VAD -Option verwenden möchten (Sprachaktivitätserkennung, bevor Sie Flüstermodell ausführen), benötigen Sie auch Torchaudio und OnnxRuntime:
pip3 install onnxruntime torchaudioWenn Sie Funduned Whisper -Modelle aus dem Umarmungs -Face -Hub verwenden möchten, benötigen Sie auch Transformers:
pip3 install transformersEin Docker -Bild von etwa 9 GB kann mit:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .Wenn Sie keine GPU haben (oder sie nicht verwenden möchten), müssen Sie die CUDA -Abhängigkeiten nicht installieren. Sie sollten dann einfach eine leichte Version von Torch installieren, bevor Sie Flüsterstimestall installieren, z. B. wie folgt:
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.htmlEin spezifisches Docker -Bild von etwa 3,5 GB kann auch mit:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .Bei der Verwendung von PIP kann die Bibliothek mit der neuesten Version mit folgenden Versionen aktualisiert werden:
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
Eine spezifische Version von openai-whisper kann zum Beispiel durch Laufen verwendet werden:
pip3 install openai-whisper==20230124 In Python können Sie die Funktion whisper_timestamped.transcribe() verwenden, die der Funktion whisper.transcribe() ähnlich ist:
import whisper_timestamped
help ( whisper_timestamped . transcribe ) Der Hauptunterschied zu whisper.transcribe() besteht darin, dass die Ausgabe ein "words" für alle Segmente enthält, wobei das Wort Start- und Endposition. Beachten Sie, dass das Wort Interpunktion enthält. Siehe das Beispiel unten.
Außerdem unterscheiden sich die Standard -Dekodierungsoptionen, um eine effiziente Dekodierung zu bevorzugen (gierige Dekodierung anstelle von Strahlsuche und kein Fallback der Temperaturabtastung). Um den gleichen Standard wie in whisper zu haben, verwenden Sie beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0) .
Es gibt auch zusätzliche Optionen im Zusammenhang mit der Wortausrichtung.
Wenn Sie in Ihrem Python -Skript whisper_timestamped statt whisper importieren und transcribe(model, ...) anstelle von model.transcribe(...) verwenden, sollte es den Job erledigen:
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) Beachten Sie, dass Sie ein finetuniertes Flüstermodell von Suggingface oder einem lokalen Ordner verwenden können, indem Sie die Methode load_model von whisper_timestamped verwenden. Wenn Sie beispielsweise Whisper-Large-V2-NOB verwenden möchten, können Sie einfach Folgendes tun:
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ... Sie können auch in der Befehlszeile whisper_timestamped verwenden, ähnlich wie whisper . Siehe Hilfe mit:
whisper_timestamped --help Die Hauptunterschiede bei whisper CLI sind:
--output_dir . Für Whisper Standard.--verbose True für Whisper Standard.--accurate Alias für --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 ) verwenden.--compute_confidence um die Berechnung der Konfidenzwerte für jedes Wort zu aktivieren/zu deaktivieren.--punctuations_with_words um zu entscheiden, ob die Interpunktionsmarken mit den vorhergehenden Wörtern einbezogen werden sollten oder nicht. Ein Beispielbefehl, mit dem mehrere Dateien mithilfe des tiny Modells verarbeitet und die Ergebnisse im aktuellen Ordner ausgegeben werden können, wie es standardmäßig mit Flüstern geschehen würde, lautet wie folgt:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Beachten Sie, dass Sie ein fein abgestimmtes Flüstermodell von Suggingface oder einem lokalen Ordner verwenden können. Wenn Sie beispielsweise das Modell mit flüsterlargen-V2-NOB verwenden möchten, können Sie einfach Folgendes tun:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
Zusätzlich zur transcribe bietet Whisper-Timestamped einige Dienstprogrammfunktionen:
remove_non_speechEntfernen Sie nicht Sprachsegmente aus Audio mithilfe der Voice Activity Detection (VAD).
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelLaden Sie ein Flüstermodell von einem vorgegebenen Namen oder Pfad, einschließlich der Unterstützung für fein abgestimmte Modelle von Suggingface.
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" ) Beachten Sie, dass Sie die Option plot_word_alignment der Option whisper_timestamped.transcribe() Python oder die Option --plot der CLI whisper_timestamped CLI verwenden können, um die Wortausrichtung für jedes Segment anzuzeigen.
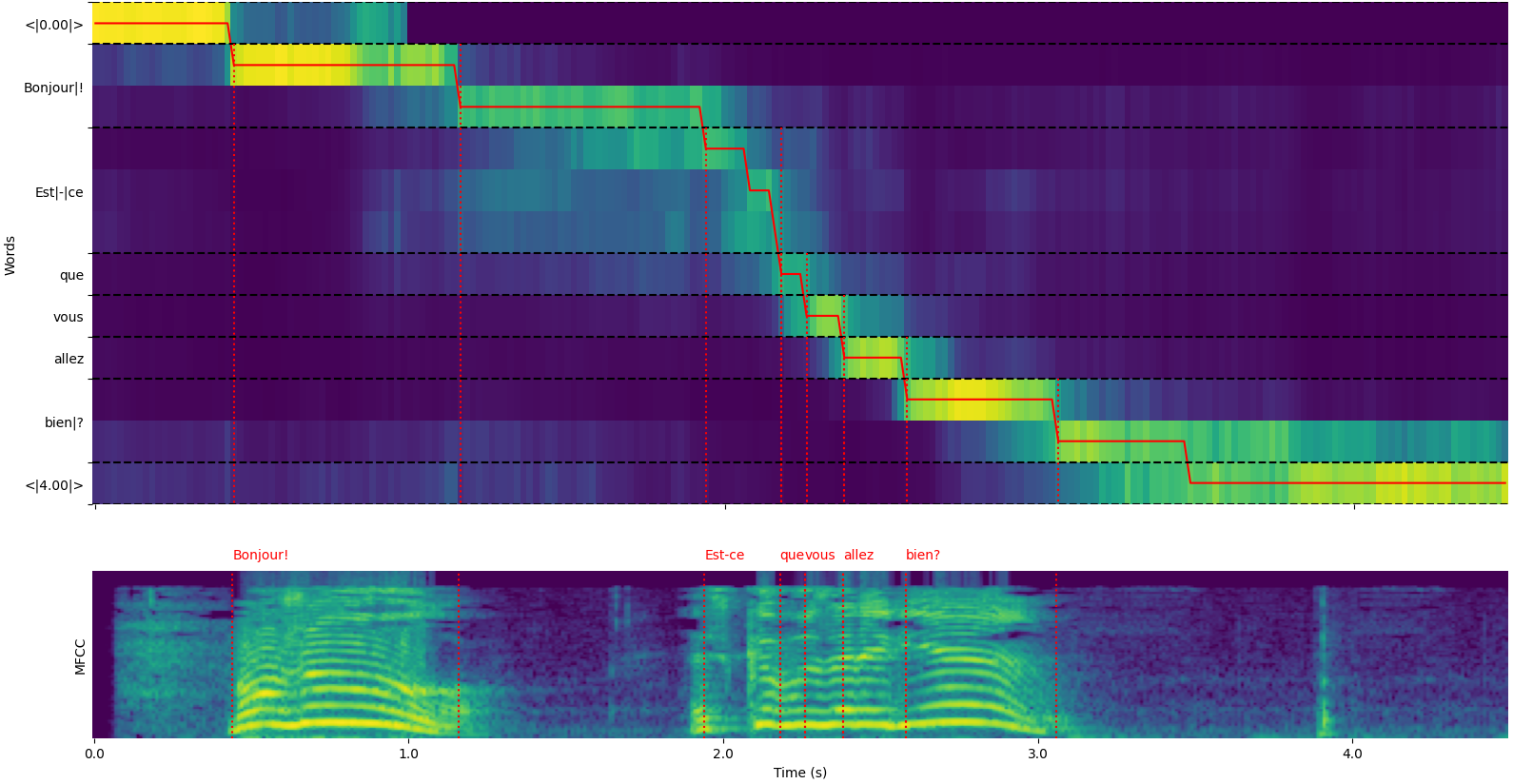
Die Ausgabe der Funktion whisper_timestamped.transcribe() ist ein Python -Wörterbuch, das im JSON -Format mit der CLI angezeigt werden kann.
Das JSON -Schema ist in den Tests/json_schema.json zu sehen.
Hier ist ein Beispielausgang:
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
} Wenn die Sprache nicht angegeben ist (z. B. ohne Option --language fr in der CLI), finden Sie einen zusätzlichen Schlüssel mit den Sprachwahrscheinlichkeiten:
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)Transkribieren Sie Audio mit einem Flüstermodell und berechnen Sie Zeitstempel auf Wortebene.
model : Flüstermodellinstanz Das für die Transkription zu verwendende Flüstermodell.
audio : Union [STR, NP.NDarray, Torch.tensor] Der Pfad zur Transkribe von Audio -Datei oder die Audiowellenform als Numme -Array oder Pytorch -Tensor.
language : STR, optional (Standard: Keine) Die Sprache des Audios. Wenn keine, wird die Spracherkennung durchgeführt.
task : STR, Standard "transkribieren" die Aufgabe, die auszuführen ist: Entweder "transkribieren" für die Spracherkennung oder "Übersetzung" zur Übersetzung in Englisch.
vad : Union [Bool, Str, List [Tuple [Float, Float]]], Optional (Standard: Falsch) Ob die Erkennung der Sprachaktivität (VAD) verwendet werden soll, um Nicht-Sprach-Segmente zu entfernen. Kann sein:
detect_disfluencies : BOOL, Standard Falsch, ob Disfluencies (Zögern, Füllwörter usw.) in der Transkription erfasst und markiert werden soll.
trust_whisper_timestamps : bool, Standard wahr, ob sie sich auf die Zeitstempel von Whisper für erste Segmentpositionen verlassen soll.
compute_word_confidence : bool, Standard wahr, ob Konfidenzwerte für Wörter berechnet werden sollen.
include_punctuation_in_confidence : bool, Standard Falsch, ob die Interpunktionswahrscheinlichkeit beim Berechnen des Wortes Vertrauen einbezogen werden soll.
refine_whisper_precision : Float, Standard 0.5 Wie viel Verfeinerungssegmentpositionen in Sekunden. Muss ein Vielfaches von 0,02 sein.
min_word_duration : float, Standard 0,02 Mindestdauer eines Wortes in Sekunden.
plot_word_alignment : bool oder str, Standard falsch, ob die Wortausrichtung für jedes Segment gezeichnet werden soll. Wenn eine Zeichenfolge, speichern Sie das Diagramm in der angegebenen Datei.
word_alignement_most_top_layers : INT, Optional (Standard: Keine) Anzahl der oberen Ebenen, die für die Wortausrichtung verwendet werden sollen. Wenn keine, verwenden Sie alle Schichten.
remove_empty_words : bool, Standard falsch, ob Wörter ohne Dauer am Ende der Segmente entfernen soll.
naive_approach : BOOL, Standard False Force Der naive Ansatz der Dekodierung zweimal (einmal für die Transkription, einmal für die Ausrichtung).
use_backend_timestamps : bool, Standard falsch, ob die vom Backend (OpenAI-Whisper oder Transformers) bereitgestellten Word-Zeitstempel verwendet werden, anstatt diejenigen, die durch komplexere Heuristiken von Flüsterstimten berechnet werden.
temperature : Union [Float, List [Float]], Standard -0,0 Temperatur für die Probenahme. Kann ein einzelner Wert oder eine Liste für Fallback -Temperaturen sein.
compression_ratio_threshold : float, Standard 2.4 Wenn das Gzip -Komprimierungsverhältnis über diesem Wert liegt, behandeln Sie die Decodierung als fehlgeschlagen.
logprob_threshold : float, Standard -1.0 Wenn die durchschnittliche Protokollwahrscheinlichkeit unter diesem Wert liegt, behandeln Sie die Decodierung als fehlgeschlagen.
no_speech_threshold : Float, Standard 0,6 Wahrscheinlichkeitsschwelle für <| nospeech |> Token.
condition_on_previous_text : bool, Standard true, ob die vorherige Ausgabe als Aufforderung für das nächste Fenster bereitgestellt werden soll.
initial_prompt : str, optional (Standard: Keine) Optionaler Text, der als Aufforderung für das erste Fenster bereitgestellt werden soll.
suppress_tokens : STR, Standard "-1" Comma-getrennte Liste von Token-IDs, die während der Probenahme unterdrückt werden können.
fp16 : BOOL, Optional (Standard: Keine), ob Inferenz in der FP16 -Präzision durchgeführt werden soll.
verbose : bool oder keine, Standard falsch, ob der Text an der Konsole dekodiert wird. Wenn wahr, wird alle Details angezeigt. Wenn falsch, zeigt minimale Details an. Wenn keine, zeigt nichts an.
Ein Wörterbuch mit:
text : str - der vollständige Transkriptionstextsegments : Liste [Diktat] - Liste der Segmentwörterbücher, die jeweils enthält:id : int - Segment -IDseek : Int - Startposition in der Audiodatei (in Beispielen)start : Float - Startzeit des Segments (in Sekunden)end : Float - Endzeit des Segments (in Sekunden)text : STR - Transkribierter Text für das Segmenttokens : List [int] - Token -IDs für das Segmenttemperature : Float - Temperatur verwendet für dieses Segmentavg_logprob : Float - Durchschnittliche Protokollwahrscheinlichkeit des Segmentscompression_ratio : float - Komprimierungsverhältnis des Segmentsno_speech_prob : float - Wahrscheinlichkeit einer Sprache im Segmentconfidence : Float - Vertrauensbewertung für das Segmentwords : Liste [dict] - Liste der Wortwörterbücher, die jeweils enthält:start : Float - Startzeit des Wortes (in Sekunden)end : Float - Endzeit des Wortes (in Sekunden)text : str - Der Wort Textconfidence : Float - Vertrauensbewertung für das Wort (falls berechnet)language : STR - erkannte oder angegebene Sprachelanguage_probs : Diktat - Spracherkennungswahrscheinlichkeiten (falls zutreffend) RuntimeError : Wenn die VAD -Methode nicht ordnungsgemäß installiert oder konfiguriert ist.ValueError : Wenn die refine_whisper_precision kein positives Vielfachen von 0,02 ist.AssertionError : Wenn die Audiodauer kürzer als erwartet ist oder wenn die Anzahl der Segmente inkonsistenz ist. naive_approach kann zum Debuggen oder beim Umgang mit bestimmten Audio -Merkmalen nützlich sein, kann jedoch langsamer sein als der Standardansatz.use_efficient_by_default TRUE ist, werden einige Parameter wie best_of , beam_size und temperature_increment_on_fallback standardmäßig für eine effizientere Verarbeitung auf keine gesetzt.remove_non_speech(audio, **kwargs)Entfernen Sie nicht Sprachsegmente aus Audio mithilfe der Voice Activity Detection (VAD).
audio : Torch.tensor Audiodaten als Pytorch -Tensor.
use_sample : Bool, Standard Falsch, wenn wahr, Start- und Endzeit in Samples anstelle von Sekunden zurückkehren.
min_speech_duration : float, Standard 0,1 Mindestdauer eines Sprachsegments in Sekunden.
min_silence_duration : Float, Standard 1 Mindestdauer eines Stille -Segments in Sekunden.
dilatation : Float, Standard 0.5 Wie viel zu vergrößern jedes von VAD erkannte Sprachsegment in Sekunden.
sample_rate : int, Standard 16000 Beispielrate des Audio.
method : STR oder List [Tuple [Float, Float]], Standard "Silero" VAD -Methode zu verwenden. Kann "Silero", "Auditok" oder eine Liste von Zeitstempeln sein.
avoid_empty_speech : bool, Standard falsch, wenn wahr, vermeiden Sie ein leeres Sprachsegment.
plot : Union [bool, str], Standard falsch, wenn wahr, zeichnen Sie die VAD -Ergebnisse auf. Wenn eine Zeichenfolge, speichern Sie das Diagramm in der angegebenen Datei.
Ein Tupel mit:
ImportError : Wenn die erforderliche VAD -Bibliothek (z. B. Auditok) nicht installiert ist.ValueError : Wenn eine ungültige VAD -Methode angegeben ist. load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)Laden Sie ein Flüstermodell von einem angegebenen Namen oder Pfad.
name : STR -Name des Modells oder Pfades zum Modell. Kann sein:
device : Union [STR, Torch.Device], Optionales (Standard: Keine) Gerät zu verwenden. Wenn keine, verwenden Sie CUDA, falls verfügbar, andernfalls CPU.
backend : STR, Standard "OpenAi-Whisper" -Backend zu verwenden. Entweder "Transformers" oder "Openai-Whisper".
download_root : str, optional (Standard: Keine) Root -Ordner zum Herunterladen des Modells auf. Wenn keine, verwenden Sie das Standard -Download -Root.
in_memory : BOOL, Standard Falsch, ob die Modellgewichte in den Host -Speicher vorgeladen werden sollen.
Das geladene Flüstermodell.
ValueError : Wenn ein ungültiges Backend angegeben ist.ImportError : Wenn die Transformers -Bibliothek bei Verwendung des Backends "Transformers" nicht installiert ist.RuntimeError : Wenn das Modell nicht aus der angegebenen Quelle gefunden oder heruntergeladen werden kann.OSError : Wenn Probleme beim Lesen der Modelldatei oder des Zugriffs auf den angegebenen Pfad vorliegen. get_alignment_heads(model, max_top_layer=3)Holen Sie sich die Ausrichtungsköpfe für das angegebene Modell.
model : Flüstermodellinstanz Das Flüstermodell, für das Ausrichtungsköpfe abgerufen werden können.
max_top_layer : int, Standard 3 maximale Anzahl der oberen Ebenen, die für Ausrichtungsköpfe berücksichtigt werden müssen.
Ein spärlicher Tensor, der die Ausrichtungsköpfe darstellt.
Die folgenden Funktionen stehen zum Schreiben von Transkripten für verschiedene Dateiformate zur Verfügung:
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)Schreiben Sie Transkriptdaten in eine CSV -Datei.
transcript : Liste [dict] Liste der Transkript -Segmentwörterbücher.
file : Dateiähnliche Objektdatei zum Schreiben der CSV-Daten.
sep : STR, Standard "," Separator, die in der CSV -Datei verwendet werden soll.
text_first : bool, Standard true, wenn true, schreiben Sie die Textspalte vor Start/Endzeit.
format_timestamps : Callable, Optional (Standard: Keine) Funktion zum Formatieren von Zeitstempelwerten.
header : Union [Bool, Liste [STR]], Standard falsch, wenn wahr, Standardheader schreiben. Wenn eine Liste als benutzerdefinierte Header verwendet werden.
IOError : Wenn Probleme beim Schreiben in die angegebene Datei vorliegen.ValueError : Wenn sich die Transkriptdaten nicht im erwarteten Format befinden. format_timestamps ermöglicht die benutzerdefinierte Formatierung von Zeitstempelwerten, die für bestimmte Anwendungsfälle oder Datenanalyseanforderungen hilfreich sein können. write_srt(transcript, file)Schreiben Sie Transkriptdaten in eine SRT -Datei (Subrip -Untertitel).
transcript : Liste [dict] Liste der Transkript -Segmentwörterbücher.
file : Dateiähnliche Objektdatei zum Schreiben der SRT-Daten.
IOError : Wenn Probleme beim Schreiben in die angegebene Datei vorliegen.ValueError : Wenn sich die Transkriptdaten nicht im erwarteten Format befinden. write_vtt(transcript, file)Schreiben Sie Transkriptdaten in eine VTT (WebVTT) -Datei.
transcript : Liste [dict] Liste der Transkript -Segmentwörterbücher.
file : Dateiähnliche Objektdatei zum Schreiben der VTT-Daten.
IOError : Wenn Probleme beim Schreiben in die angegebene Datei vorliegen.ValueError : Wenn sich die Transkriptdaten nicht im erwarteten Format befinden. write_tsv(transcript, file)Schreiben Sie Transkriptdaten in eine TSV-Datei (Tab-getrennte Werte).
transcript : Liste [dict] Liste der Transkript -Segmentwörterbücher.
file : Dateiähnliche Objektdatei zum Schreiben der TSV-Daten.
IOError : Wenn Probleme beim Schreiben in die angegebene Datei vorliegen.ValueError : Wenn sich die Transkriptdaten nicht im erwarteten Format befinden. Hier sind einige Optionen, die standardmäßig nicht aktiviert sind, aber die Ergebnisse verbessern können.
Wie bereits erwähnt, sind einige Dekodierungsoptionen standardmäßig deaktiviert, um eine bessere Effizienz zu bieten. Dies kann jedoch die Qualität der Transkription beeinflussen. Verwenden Sie die folgenden Optionen, um mit den Optionen zu laufen, die die beste Chance haben, eine gute Transkription bereitzustellen.
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ... Whisper -Modelle können Text "halluzinieren", wenn sie ein Segment ohne Sprache erhalten. Dies kann vermieden werden, indem VAD und Sprachsegmente zusammengeführt werden, bevor sie mit dem Flüstermodell transkribiert werden. Dies ist mit whisper-timestamped möglich.
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...Standardmäßig ist die verwendete VAD -Methode Silero. Andere Methoden sind jedoch verfügbar, z. B. frühere Versionen von Silero oder Auditok. Diese Methoden wurden eingeführt, weil die neuesten Versionen von Silero VAD viele Fehlalarme bei einigen Audios haben können (Sprache zur Stille).
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... Um die VAD -Ergebnisse anzuschauen, können Sie die Option --plot der whisper_timestamped CLI oder die Option plot_word_alignment der Option whisper_timestamped.transcribe() Python -Funktion verwenden. Es wird die VAD-Ergebnisse des Eingangs-Audiosignals wie folgt angezeigt (x-Achse ist Zeit in Sekunden):
| vad = "Silero: v4.0" | vad = "Silero: v3.1" | vad = "auditok" |
|---|---|---|
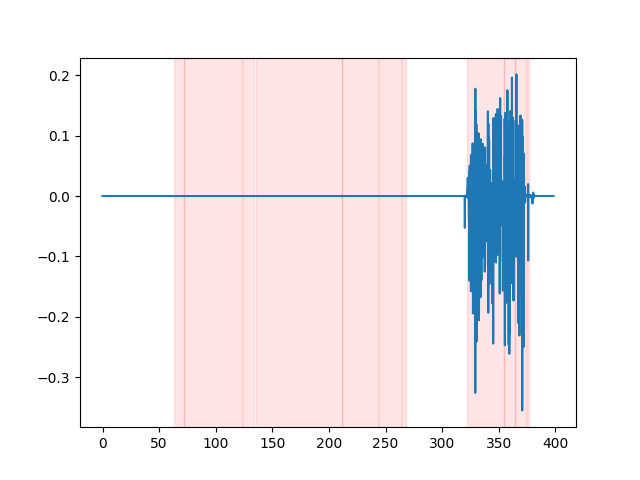 | 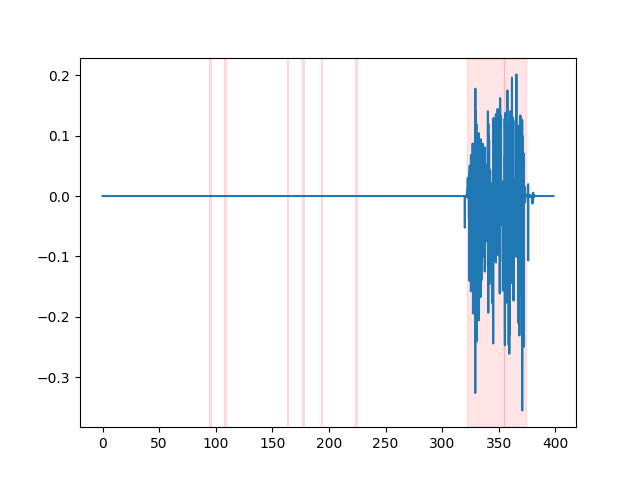 | 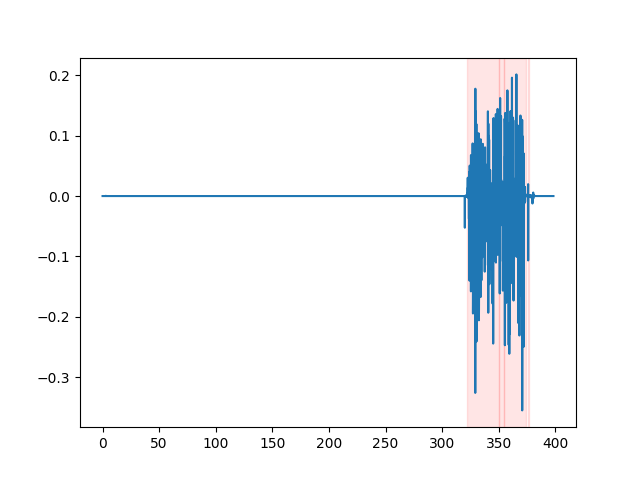 |
Whisper -Modelle neigen dazu, Sprachdisfluenzen zu entfernen (Füllwörter, Zögern, Wiederholungen usw.). Ohne Vorsichtsmaßnahmen beeinflussen die nicht transkribierten Disfluencies den Zeitstempel des folgenden Wortes: Der Zeitstempel des Beginns des Wortes wird tatsächlich der Zeitstempel des Beginns der Disfluenzen sein. whisper-timestamped können einige Heuristiken haben, um dies zu vermeiden.
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ... Wichtig: Beachten Sie, dass bei Verwendung dieser Optionen mögliche Disfluenzen in der Transkription als spezielles Wort " [*] " angezeigt werden.
Wenn Sie dies in Ihrer Forschung verwenden, zitieren Sie bitte das Repo:
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}sowie das Openai Whisper Paper:
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}und dieses Papier für Dynamic Time Waring:
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

