whisper timestamped
v1.15.8
التعرف على الكلام التلقائي متعدد اللغات مع الطوابع الزمنية على مستوى الكلمات والثقة.
Whisper هي مجموعة من نماذج التعرف على الكلام المتعددة اللغات والقوة التي تدربها Openai والتي تحقق نتائج أحدث نتائج في العديد من اللغات. تم تدريب نماذج الهمس على التنبؤ بالطوابع الزمنية التقريبية على قطاعات الكلام (معظم الوقت بدقة 1 ثانية) ، لكنها لا يمكن أن تتنبأ في الأصل بالوقود الزمنية. يقترح هذا المستودع تنفيذًا للتنبؤ بالطابع الزمني للكلمة وتوفير تقدير أكثر دقة لقطاعات الكلام عند النسخ مع نماذج الهمس . علاوة على ذلك ، يتم تعيين درجة الثقة لكل كلمة وكل جزء.
يعتمد النهج على تزييف الوقت الديناميكي (DTW) المطبق على أوزان الالتحاق ، كما يتضح من هذا الكمبيوتر الدفتري من قبل Jong Wook Kim. هناك بعض الإضافات إلى هذا الكمبيوتر الدفتري:
whisper-timestamped قادر على معالجة الملفات الطويلة مع القليل من الذاكرة الإضافية مقارنة بالاستخدام المنتظم لنموذج الهمس. whisper-timestamped هو امتداد لحزمة Python openai-whisper ومن المفترض أن تكون متوافقة مع أي إصدار من openai-whisper . يوفر المزيد من الطوابع الزمنية للكلمة أكثر كفاءة/دقة ، إلى جانب تلك الميزات الإضافية:
إخلاء المسئولية: يرجى ملاحظة أن هذا التمديد مخصص لأغراض تجريبية وقد يؤثر بشكل كبير على الأداء. نحن لسنا مسؤولين عن أي قضايا أو أوجه عدم الكفاءة التي تنشأ عن استخدامها.
يتضمن النهج البديل ذو الصلة لاستعادة الطوابع الزمنية على مستوى الكلمات استخدام نماذج WAV2VEC التي تتنبأ بالأحرف ، كما تم تنفيذها بنجاح في Whisperx. ومع ذلك ، فإن هذه الأساليب لها عدة عيوب غير موجودة في الأساليب القائمة على أوزان الالتحاق مثل whisper_timestamped . تشمل هذه العيوب:
إن النهج البديل الذي لا يتطلب نموذجًا إضافيًا هو النظر إلى احتمالات الرموز الطوابع الزمنية المقدرة بواسطة نموذج الهمس بعد كل رمز كلمة (فرعي). تم تنفيذ هذا ، على سبيل المثال ، في Whisper.cpp و stable-ts. ومع ذلك ، فإن هذا النهج يفتقر إلى المتانة لأنه لم يتم تدريب نماذج الهمس على إخراج الطوابع الزمنية ذات معنى بعد كل كلمة. تميل نماذج الهمس إلى التنبؤ بالطابع الزمني فقط بعد التنبؤ بمجموعة معينة من الكلمات (عادة في نهاية الجملة) ، وقد يكون توزيع احتمال الطوابع الزمنية خارج هذه الحالة غير دقيق. في الممارسة العملية ، يمكن أن تنتج هذه الأساليب نتائج غير متزامنة تمامًا في بعض الفترات الزمنية (لاحظنا ذلك خاصة عندما تكون هناك موسيقى Jingle). أيضًا ، تميل دقة الطوابع الزمنية لنماذج الهمس إلى أن يتم تقريبها إلى ثانية واحدة (كما هو الحال في العديد من ترجمات الفيديو) ، وهو أمر غير دقيق للغاية بالنسبة للكلمات ، والوصول إلى دقة أفضل أمر صعب.
متطلبات:
python3 (الإصدار أعلى أو يساوي 3.7 ، على الأقل 3.9 يوصى به)ffmpeg (انظر تعليمات التثبيت على مستودع الهمس) يمكنك تثبيت whisper-timestamped إما باستخدام PIP:
pip3 install whisper-timestampedأو عن طريق استنساخ هذا المستودع وتركيب التشغيل:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py installإذا كنت ترغب في رسم التوافق بين الطوابع الزمنية والكلمات (كما في هذا القسم) ، فأنت بحاجة أيضًا إلى matplotlib:
pip3 install matplotlibإذا كنت ترغب في استخدام خيار VAD (اكتشاف النشاط الصوتي قبل تشغيل نموذج الهمس) ، فأنت بحاجة أيضًا إلى Torchaudio و OnnxRuntime:
pip3 install onnxruntime torchaudioإذا كنت ترغب في استخدام نماذج الهمس المحببة من مركز الوجه المعانقة ، فأنت بحاجة أيضًا إلى محولات:
pip3 install transformersيمكن بناء صورة Docker لحوالي 9 جيجابايت باستخدام:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .إذا لم يكن لديك وحدة معالجة الرسومات (أو لا ترغب في استخدامها) ، فلن تحتاج إلى تثبيت تبعيات CUDA. يجب عليك بعد ذلك تثبيت إصدار خفيف من Torch قبل تثبيت Whisper-timestamped ، على سبيل المثال على النحو التالي:
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.htmlيمكن أيضًا بناء صورة عامل ميناء بحوالي 3.5 جيجابايت باستخدام:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .عند استخدام PIP ، يمكن تحديث المكتبة إلى أحدث إصدار باستخدام:
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
يمكن استخدام نسخة محددة من openai-whisper عن طريق التشغيل ، على سبيل المثال:
pip3 install openai-whisper==20230124 في Python ، يمكنك استخدام الدالة whisper_timestamped.transcribe() ، والتي تشبه الدالة whisper.transcribe() :
import whisper_timestamped
help ( whisper_timestamped . transcribe ) الفرق الرئيسي مع whisper.transcribe() هو أن الإخراج سيتضمن "words" مفتاح لجميع الأجزاء ، مع وضع البداية والنهاية. لاحظ أن الكلمة ستشمل علامات الترقيم. انظر المثال أدناه.
علاوة على ذلك ، تختلف خيارات فك التشفير الافتراضية لصالح فك التشفير الفعال (فك تشفير الجشع بدلاً من البحث عن الشعاع ، ولا توجد عوامل في أخذ عينات من درجة الحرارة). للحصول على نفس الافتراضي كما في whisper ، استخدم beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0) .
هناك أيضًا خيارات إضافية تتعلق بمحاذاة Word.
بشكل عام ، إذا قمت باستيراد whisper_timestamped بدلاً من whisper في البرنامج النصي Python واستخدم transcribe(model, ...) بدلاً من model.transcribe(...) .
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) لاحظ أنه يمكنك استخدام طراز همسات محيط من Huggingface أو مجلد محلي باستخدام طريقة load_model لـ whisper_timestamped . على سبيل المثال ، إذا كنت ترغب في استخدام Whisper-Large-V2-NOB ، يمكنك ببساطة القيام بما يلي:
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ... يمكنك أيضًا استخدام whisper_timestamped على سطر الأوامر ، على غرار whisper . انظر المساعدة في:
whisper_timestamped --help الاختلافات الرئيسية مع whisper CLI هي:
--output_dir . لتهامس الافتراضي.--verbose True للهمس الافتراضي.--accurate (وهو الاسم المستعار لـ --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 ).--compute_confidence لتمكين/تعطيل حساب درجات الثقة لكل كلمة.--punctuations_with_words لتحديد ما إذا كان ينبغي تضمين علامات الترقيم أم لا مع الكلمات السابقة. أمر مثال لمعالجة العديد من الملفات باستخدام النموذج tiny وإخراج النتائج في المجلد الحالي ، كما سيتم ذلك افتراضيًا مع Whisper ، كما يلي:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
لاحظ أنه يمكنك استخدام طراز همسة دقيق من Huggingface أو مجلد محلي. على سبيل المثال ، إذا كنت ترغب في استخدام نموذج Whisper-Large-V2-NOB ، يمكنك ببساطة القيام بما يلي:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
بالإضافة إلى وظيفة transcribe الرئيسية ، يوفر Whisper-timestamped بعض وظائف الأداة المساعدة:
remove_non_speechإزالة شرائح غير الكلام من الصوت باستخدام الكشف عن النشاط الصوتي (VAD).
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelقم بتحميل طراز همس من اسم أو مسار معين ، بما في ذلك دعم النماذج التي تم ضبطها من Luggingface.
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" ) لاحظ أنه يمكنك استخدام خيار plot_word_alignment الخاص بـ whisper_timestamped.transcribe() وظيفة Python أو خيار --plot لـ whisper_timestamped CLI لرؤية محاذاة كلمة كل قطعة.
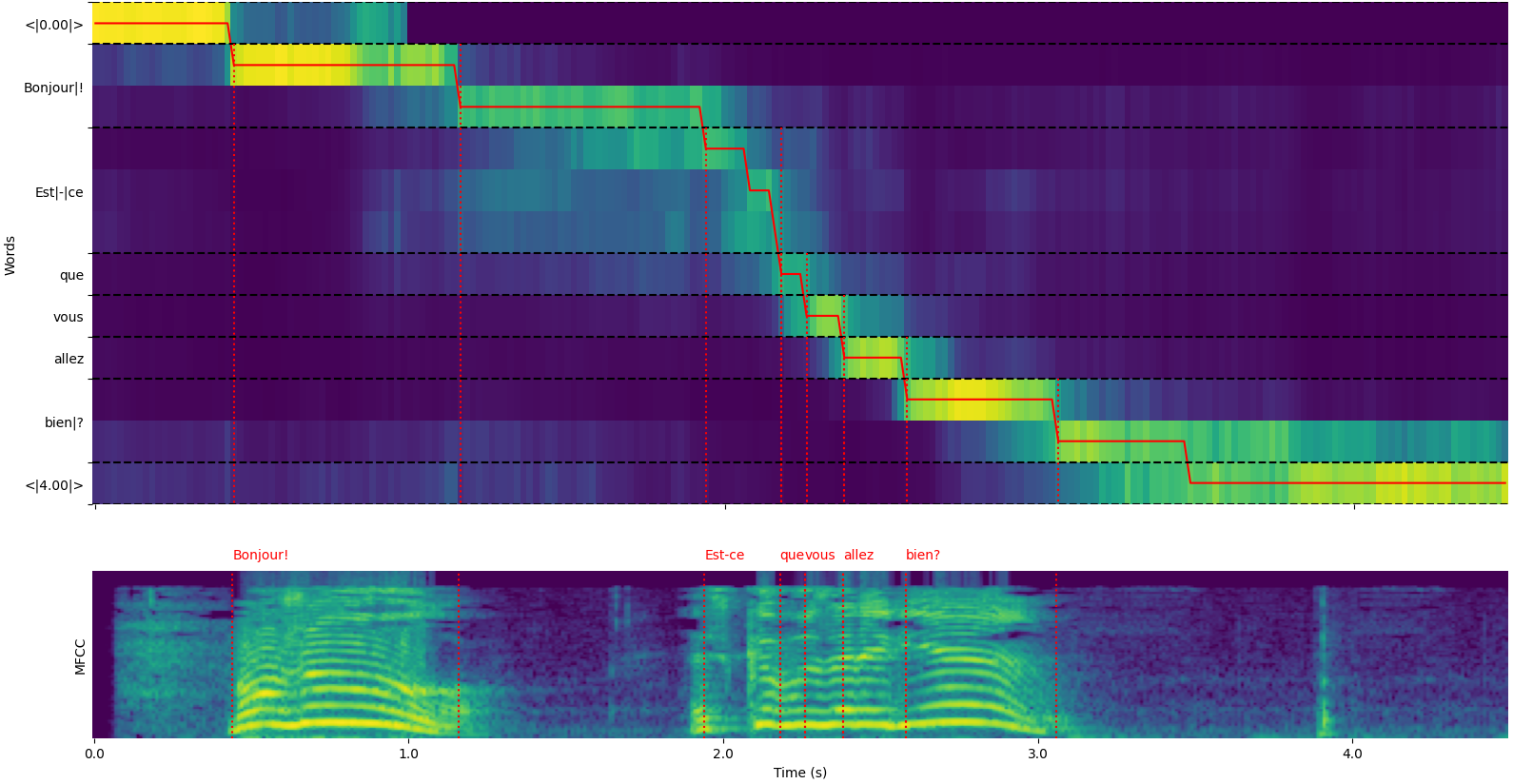
إن إخراج وظيفة whisper_timestamped.transcribe() عبارة عن قاموس بيثون ، والذي يمكن عرضه بتنسيق JSON باستخدام CLI.
يمكن رؤية مخطط JSON في الاختبارات/JSON_SCHEMA.JSON.
هنا مثال على الإخراج:
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
} إذا لم يتم تحديد اللغة (على سبيل المثال بدون خيار --language fr في CLI) ، فستجد مفتاحًا إضافيًا مع احتمالات اللغة:
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)قم بنسخ الصوت باستخدام نموذج همس وحساب الطوابع الزمنية على مستوى الكلمات.
model : مثيل النموذج الهامس هو نموذج الهمس لاستخدامه في النسخ.
audio : Union [str ، np.ndarray ، torch.tensor] المسار إلى ملف الصوت المراد نسخه ، أو شكل الموجة الصوتية كصفيف numpy أو pytorch unsor.
language : STR ، اختياري (افتراضي: لا شيء) لغة الصوت. إذا لم يكن هناك شيء ، فسيتم إجراء الكشف عن اللغة.
task : STR ، الافتراضي "قم بنسخ" المهمة التي يجب تنفيذها: إما "نسخ" للتعرف على الكلام أو "ترجمة" للترجمة إلى اللغة الإنجليزية.
vad : Union [Bool ، Str ، List [Tuple [Float ، Float]] ، اختياري (افتراضي: خطأ) ما إذا كنت تستخدم اكتشاف النشاط الصوتي (VAD) لإزالة الأجزاء غير الكلام. يمكن أن يكون:
detect_disfluencies : bool ، الافتراضي خطأ ما إذا كان سيتم اكتشاف وعلامة التمييز (التردد ، كلمات الحشو ، إلخ) في النسخ.
trust_whisper_timestamps : Bool ، صحيح ما إذا كان سيتم الاعتماد على الطوابع الزمنية للهسبر لمواقع القطاع الأولية.
compute_word_confidence : bool ، صحيح ما إذا كان سيتم حساب درجات الثقة للكلمات.
include_punctuation_in_confidence : bool ، خطأ افتراضي ما إذا كان يجب تضمين احتمال علامات الترقيم عند حساب ثقة الكلمة.
refine_whisper_precision : تعويم ، الافتراضي 0.5 مقدار ما يجب صقله في مواقف قطاع الهمس ، في ثوان. يجب أن يكون مضاعف 0.02.
min_word_duration : تعويم ، الافتراضي 0.02 الحد الأدنى للمدة للكلمة ، في ثوان.
plot_word_alignment : Bool أو Str ، خطأ ما إذا كنت تريد رسم كلمة محاذاة لكل قطعة. إذا كانت سلسلة ، احفظ المؤامرة إلى الملف المحدد.
word_alignement_most_top_layers : int ، اختياري (افتراضي: لا شيء) عدد الطبقات العليا التي يجب استخدامها لمحاذاة الكلمات. إذا لم يسبق له مثيل ، استخدم جميع الطبقات.
remove_empty_words : Bool ، خطأ افتراضي ما إذا كان يجب إزالة الكلمات دون مدة تحدث في نهاية الأجزاء.
naive_approach : Bool ، الافتراضي القوة الخاطئة ، النهج الساذج المتمثل في فك التشفير مرتين (مرة واحدة للنسخ ، مرة واحدة لمحاذاة).
use_backend_timestamps : Bool ، خطأ افتراضي ما إذا كنت تريد استخدام الطوابع الزمنية للكلمة التي توفرها الواجهة الخلفية (Openai-Whisper أو Transformers) ، بدلاً من تلك التي يتم حسابها عن طريق الاستدلال الأكثر تعقيدًا للهمس.
temperature : الاتحاد [تعويم ، قائمة [تعويم]] ، درجة حرارة 0.0 الافتراضية لأخذ العينات. يمكن أن تكون قيمة واحدة أو قائمة لدرجات حرارة العودة.
compression_ratio_threshold : float ، افتراضي 2.4 إذا كانت نسبة ضغط GZIP أعلى من هذه القيمة ، تعامل مع فك التشفير كما فشل.
logprob_threshold : تعويم ، افتراضي -1.0 إذا كان متوسط احتمال السجل أقل من هذه القيمة ، تعامل مع فك التشفير على أنه فشل.
no_speech_threshold : تعويم ، افتراضي 0.6 عتبة الاحتمال لـ <| nospeech |> الرموز.
condition_on_previous_text : bool ، صحيح ما إذا كان سيتم توفير الإخراج السابق كمطالبة للنافذة التالية.
initial_prompt : STR ، نص اختياري (افتراضي: لا شيء) لتوفيره كموجه للمطالبة بالنافذة الأولى.
suppress_tokens : STR ، افتراضي "-1" قائمة مفصولة بفاصلة من معرفات الرمز المميز لقمعها أثناء أخذ العينات.
fp16 : BOOL ، اختياري (افتراضي: لا شيء) ما إذا كان سيتم إجراء الاستدلال في دقة FP16.
verbose : منطقي أو لا شيء ، خطأ افتراضي ما إذا كنت تريد عرض النص الذي يتم فك تشفيره على وحدة التحكم. إذا كان صحيحا ، يعرض جميع التفاصيل. إذا كان خطأ ، يعرض الحد الأدنى من التفاصيل. إذا لم يكن هناك ، لا يعرض أي شيء.
قاموس يحتوي على:
text : STR - نص النسخ الكاملsegments : قائمة [DICT] - قائمة قواميس القطاع ، كل تحتوي على:id : int - معرف القطاعseek : int - موقف البدء في ملف الصوت (في العينات)start : تعويم - وقت بدء الجزء (بالثواني)end : تعويم - وقت نهاية القطاع (بالثواني)text : STR - النص المكتوب للجزءtokens : قائمة [int] - معرفات الرمز المميز للجزءtemperature : تعويم - درجة الحرارة المستخدمة لهذا الجزءavg_logprob : تعويم - متوسط احتمال السجل للجزءcompression_ratio : تعويم - نسبة ضغط الجزءno_speech_prob : تعويم - احتمال عدم وجود خطاب في الجزءconfidence : تعويم - درجة الثقة للجزءwords : قائمة [DICT] - قائمة قواميس الكلمات ، كل تحتوي على:start : تعويم - وقت بدء الكلمة (بالثواني)end : تعويم - وقت نهاية الكلمة (بالثواني)text : str - كلمة النصconfidence : تعويم - درجة الثقة للكلمة (إذا تم حسابها)language : str - لغة مكتشفة أو محددةlanguage_probs : احتمالات الكشف عن اللغة (إن أمكن) RuntimeError : إذا لم يتم تثبيت أو تكوين طريقة VAD بشكل صحيح.ValueError : إذا لم يكن refine_whisper_precision مضاعفًا إيجابيًا قدره 0.02.AssertionError : إذا كانت مدة الصوت أقصر مما كان متوقعًا أو إذا كانت هناك تناقضات في عدد الأجزاء. naive_approach مفيدة للتصحيح أو عند التعامل مع خصائص صوتية محددة ، ولكن قد تكون أبطأ من النهج الافتراضي.use_efficient_by_default صحيحة ، يتم تعيين بعض المعلمات مثل best_of و beam_size و temperature_increment_on_fallback بشكل افتراضي لمعالجة أكثر كفاءة.remove_non_speech(audio, **kwargs)إزالة شرائح غير الكلام من الصوت باستخدام الكشف عن النشاط الصوتي (VAD).
audio : Torch.tensor بيانات الصوت كموتر Pytorch.
use_sample : bool ، false false إذا كان صحيحًا ، فابدأ البدء والنهاية في عينات بدلاً من الثواني.
min_speech_duration : تعويم ، الافتراضي 0.1 الحد الأدنى لمقطع الكلام في ثوان.
min_silence_duration : تعويم ، الافتراضي 1 الحد الأدنى من مقطع الصمت في ثوان.
dilatation : تعويم ، الافتراضي 0.5 مقدار تكبير كل قطاع خطاب تم اكتشافه بواسطة VAD ، في ثوانٍ.
sample_rate : int ، الافتراضي 16000 معدل عينة من الصوت.
method : STR أو قائمة [Tuple [Float ، Float]] ، طريقة "Silero" VAD الافتراضية للاستخدام. يمكن أن يكون "Silero" أو "Auditok" أو قائمة من الطوابع الزمنية.
avoid_empty_speech : bool ، الافتراضي خطأ إذا كان صحيحًا ، تجنب إرجاع مقطع خطاب فارغ.
plot : Union [Bool ، Str] ، default false if true ، ارسم نتائج VAD. إذا كانت سلسلة ، احفظ المؤامرة إلى الملف المحدد.
Tuple تحتوي على:
ImportError : إذا لم يتم تثبيت مكتبة VAD المطلوبة (على سبيل المثال ، Auditok).ValueError : إذا تم تحديد طريقة VAD غير صالحة. load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)قم بتحميل نموذج الهمس من اسم أو مسار معين.
name : STR اسم النموذج أو المسار إلى النموذج. يمكن أن يكون:
device : Union [Str ، Torch.device] ، جهاز اختياري (افتراضي: لا شيء) للاستخدام. إذا لم يكن هناك ، استخدم CUDA إذا كان ذلك متاحًا ، وإلا وحدة المعالجة المركزية.
backend : Str ، الافتراضي "Openai-Whisper" الخلفية لاستخدامها. إما "المحولات" أو "Openai-Whisper".
download_root : STR ، مجلد ROOT الاختياري (الافتراضي: لا شيء) لتنزيل النموذج إلى. إذا لم يكن هناك ، استخدم جذر التنزيل الافتراضي.
in_memory : Bool ، الافتراضي خطأ ما إذا كنت تريد التحميل قبل الأوزان في الذاكرة المضيفة.
نموذج الهمس المحمّل.
ValueError : إذا تم تحديد الواجهة الخلفية غير صالحة.ImportError : إذا لم يتم تثبيت مكتبة Transformers عند استخدام الواجهة الخلفية "المحولات".RuntimeError : إذا كان لا يمكن العثور على النموذج أو تنزيله من المصدر المحدد.OSError : إذا كانت هناك مشكلات في قراءة ملف النموذج أو الوصول إلى المسار المحدد. get_alignment_heads(model, max_top_layer=3)احصل على رؤوس المحاذاة للنموذج المحدد.
model : مثيل النموذج الهامس على نموذج الهمس الذي لاسترداد رؤوس المحاذاة.
max_top_layer : int ، الافتراضي 3 العدد القصوى من الطبقات العليا التي يجب مراعاتها لرؤوس المحاذاة.
موتر متناثر يمثل رؤساء المحاذاة.
الوظائف التالية متاحة لكتابة النصوص لتنسيقات الملفات المختلفة:
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)اكتب بيانات النص إلى ملف CSV.
transcript : قائمة [DICT] قائمة قواميس قطاع النص.
file : ملف كائن يشبه الملف لكتابة بيانات CSV إلى.
sep : STR ، افتراضي "،" فاصل لاستخدامه في ملف CSV.
text_first : Bool ، True If True ، اكتب عمود النص قبل بدء/نهاية الأوقات.
format_timestamps : وظيفة قابلة للاتصال ، اختياري (افتراضي: لا شيء) لتنسيق قيم الطابع الزمني.
header : Union [Bool ، List [STR]] ، default false if true ، اكتب رأسًا افتراضيًا. إذا كانت قائمة ، استخدم رأسًا مخصصًا.
IOError : إذا كانت هناك مشكلات في الكتابة إلى الملف المحدد.ValueError : إذا لم تكن بيانات النص بالتنسيق المتوقع. format_timestamps تنسيقًا مخصصًا لقيم الطابع الزمني ، والتي يمكن أن تكون مفيدة لحالات الاستخدام المحددة أو متطلبات تحليل البيانات. write_srt(transcript, file)اكتب بيانات النص إلى ملف SRT (العنوان الفرعي الفرعي).
transcript : قائمة [DICT] قائمة قواميس قطاع النص.
file : ملف كائن يشبه الملف لكتابة بيانات SRT إلى.
IOError : إذا كانت هناك مشكلات في الكتابة إلى الملف المحدد.ValueError : إذا لم تكن بيانات النص بالتنسيق المتوقع. write_vtt(transcript, file)اكتب بيانات النص إلى ملف VTT (WebVTT).
transcript : قائمة [DICT] قائمة قواميس قطاع النص.
file : ملف كائن يشبه الملف لكتابة بيانات VTT إلى.
IOError : إذا كانت هناك مشكلات في الكتابة إلى الملف المحدد.ValueError : إذا لم تكن بيانات النص بالتنسيق المتوقع. write_tsv(transcript, file)اكتب بيانات النص إلى ملف TSV (قيم مفصولة TAB).
transcript : قائمة [DICT] قائمة قواميس قطاع النص.
file : ملف كائن يشبه الملف لكتابة بيانات TSV إلى.
IOError : إذا كانت هناك مشكلات في الكتابة إلى الملف المحدد.ValueError : إذا لم تكن بيانات النص بالتنسيق المتوقع. فيما يلي بعض الخيارات التي لا يتم تمكينها افتراضيًا ولكنها قد تحسن النتائج.
كما ذكرنا سابقًا ، يتم تعطيل بعض خيارات فك التشفير افتراضيًا لتقديم كفاءة أفضل. ومع ذلك ، هذا يمكن أن يؤثر على جودة النسخ. لتشغيل الخيارات التي لديها أفضل فرصة لتوفير نسخ جيد ، استخدم الخيارات التالية.
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ... يمكن للطرز الهمس نص "الهلوسة" عند إعطاء شريحة بدون خطاب. يمكن تجنب ذلك عن طريق تشغيل شرائح الكلام VAD واللصق معًا قبل النسخ مع نموذج الهمس. هذا ممكن مع whisper-timestamped .
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...بشكل افتراضي ، طريقة VAD المستخدمة هي Silero. ولكن تتوفر طرق أخرى ، مثل الإصدارات السابقة من Silero أو Auditok. تم تقديم هذه الطرق لأن أحدث إصدارات Silero VAD يمكن أن تحتوي على الكثير من الإنذارات الخاطئة على بعض الصوت (الكلام المكتشف على الصمت).
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... لمشاهدة نتائج VAD ، يمكنك استخدام خيار --plot الخاص بـ whisper_timestamped CLI ، أو خيار plot_word_alignment الخاص بوظيفة whisper_timestamped.transcribe() Python. سيظهر نتائج VAD على إشارة الصوت الإدخال على النحو التالي (المحور السيني هو الوقت في ثوان):
| Vad = "Silero: v4.0" | Vad = "Silero: v3.1" | VAD = "Auditok" |
|---|---|---|
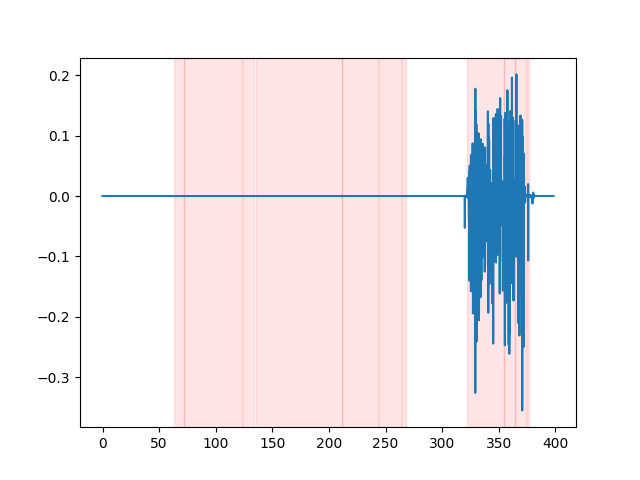 | 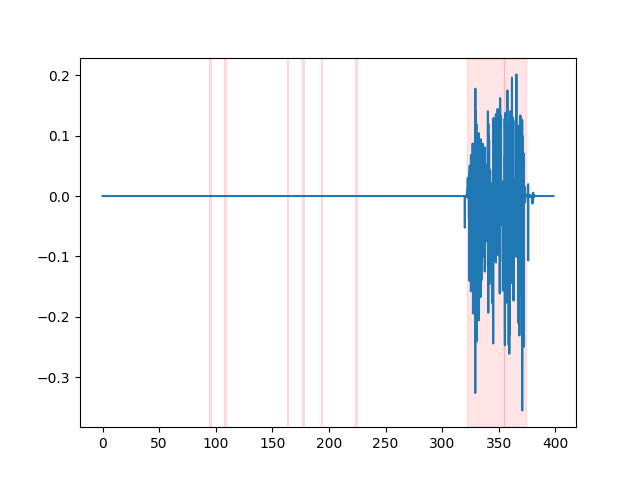 | 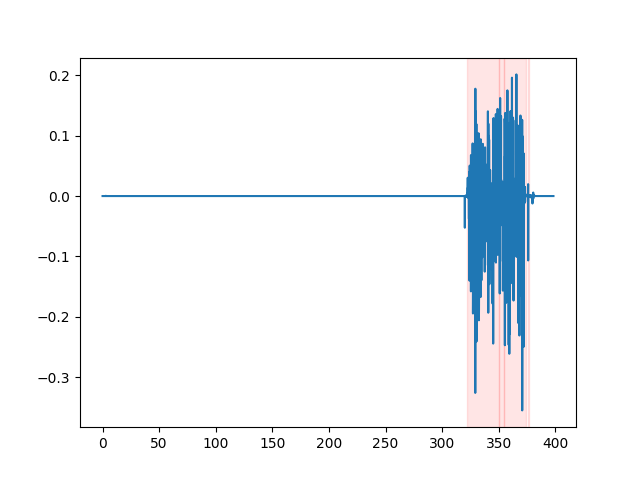 |
تميل نماذج الهمس إلى إزالة حالات عدم التنفيذ (كلمات الحشو ، والتردد ، والتكرار ، وما إلى ذلك). بدون الاحتياطات ، ستؤثر عمليات التزايد غير المكتوبة على الطابع الزمني للكلمة التالية: أن الطابع الزمني لبداية الكلمة سيكون في الواقع الطابع الزمني لبداية عمليات التخلص. يمكن أن يكون لدى whisper-timestamped بعض الاستدلال لتجنب ذلك.
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ... هام: لاحظ أنه عند استخدام هذه الخيارات ، ستظهر حالات التشابه المحتملة في النسخ ككلمة خاصة " [*] ".
إذا كنت تستخدم هذا في بحثك ، فيرجى الاستشهاد بالريزو:
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}وكذلك ورقة Openai Whisper:
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}وهذه الورقة من أجل حافظة الوقت الديناميكي:
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

