whisper timestamped
v1.15.8
単語レベルのタイムスタンプと自信を備えた多言語自動音声認識。
Whisperは、多くの言語で最先端の結果を達成するOpenaiによって訓練された多言語で堅牢な音声認識モデルのセットです。ささやきモデルは、音声セグメントの近似タイムスタンプ(ほとんどの場合1秒の精度で)を予測するように訓練されましたが、元々は単語のタイムスタンプを予測することはできません。このリポジトリは、単語のタイムスタンプを予測するための実装を提案し、ささやきモデルで転写する際に音声セグメントのより正確な推定を提供します。また、各単語と各セグメントに信頼性スコアが割り当てられます。
このアプローチは、Jong Wook Kimによるこのノートブックで実証されているように、通過重量に適用される動的タイムワーピング(DTW)に基づいています。このノートブックにはいくつかの追加があります:
whisper-timestampedささやきモデルの定期的な使用と比較して、メモリがほとんどない長いファイルを処理できます。 whisper-timestamped openai-whisper Pythonパッケージの延長であり、 openai-whisperの任意のバージョンと互換性があることを意図しています。これらの追加機能とともに、より効率的/正確なワードタイムスタンプを提供します。
免責事項:この拡張機能は実験目的で意図されており、パフォーマンスに大きな影響を与える可能性があることに注意してください。当社は、その使用から生じる問題や非効率性について責任を負いません。
単語レベルのタイムスタンプを回復するための代替の関連アプローチには、Whisperxで正常に実装されているように、文字を予測するWAV2VECモデルを使用することが含まれます。ただし、これらのアプローチには、 whisper_timestampedなどの通過重みに基づいたアプローチには存在しないいくつかの欠点があります。これらの欠点は次のとおりです。
追加のモデルを必要としない別のアプローチは、それぞれ(サブ)ワードトークンが予測された後、ウィスパーモデルによって推定されるタイムスタンプトークンの確率を調べることです。これは、たとえば、whisper.cppやstable-tsで実装されました。ただし、Whisperモデルが各単語の後に意味のあるタイムスタンプを出力するように訓練されていないため、このアプローチには堅牢性がありません。ささやきモデルは、特定の数の単語が予測された後にのみタイムスタンプを予測する傾向があり(通常は文の終わりに)、この状態外のタイムスタンプの確率分布は不正確になる可能性があります。実際には、これらの方法では、ある期間に完全にシンクしていない結果を生成できます(特にジングル音楽がある場合は、これを観察しました)。また、ささやきモデルのタイムスタンプの精度は、単語に対してあまりにも不正確であり、より良い精度に達することは難しい(多くのビデオ字幕のように)1秒に丸くなる傾向があります。
要件:
python3 (3.7以下のバージョン、少なくとも3.9をお勧めします)ffmpeg (ささやきリポジトリへのインストールの手順を参照) PIPを使用して、 whisper-timestampedをインストールできます。
pip3 install whisper-timestampedまたは、このリポジトリをクローニングし、インストールを実行することにより:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py installオーディオタイムスタンプと単語の間でアラインメントをプロットする場合(このセクションのように)、Matplotlibも必要です。
pip3 install matplotlibVADオプション(Whisperモデルを実行する前に音声アクティビティ検出)を使用する場合は、Torchaudioとonnxruntimeも必要です。
pip3 install onnxruntime torchaudio抱きしめるフェイスハブの微調ューされたささやきモデルを使用する場合は、トランスが必要です。
pip3 install transformers約9GBのDocker画像は、以下を使用して構築できます。
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .GPUをお持ちでない場合(または使用したくない場合)、CUDA依存関係をインストールする必要はありません。次のように、ささやき声をインストールする前に、トーチのライトバージョンをインストールするだけです。たとえば、次のようになります。
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.html約3.5GBの特定のDocker画像は、以下を使用して構築することもできます。
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .PIPを使用する場合、次のことを使用してライブラリを最新バージョンに更新できます。
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
openai-whisperの特定のバージョンは、たとえばランニングで使用できます。
pip3 install openai-whisper==20230124 Pythonでは、関数whisper_timestamped.transcribe()を使用できます。これは関数whisper.transcribe()に似ています。
import whisper_timestamped
help ( whisper_timestamped . transcribe ) whisper.transcribe()との主な違いは、出力にすべてのセグメントにキー"words"が含まれ、単語の開始と終了位置が含まれることです。単語には句読点が含まれることに注意してください。以下の例を参照してください。
また、デフォルトのデコードオプションは、効率的なデコードを支持するために異なります(ビーム検索の代わりに貪欲なデコード、温度サンプリングフォールバックはありません)。 whisperと同じデフォルトを持つには、 beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0)を使用します。
単語のアライメントに関連する追加のオプションもあります。
一般的に、pythonスクリプトでwhisper_timestamped whisperする場合、 model.transcribe(...) transcribe(model, ...) ...)を使用する場合、仕事をする必要があります。
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) whisper_timestampedのload_modelメソッドを使用して、HuggingfaceまたはローカルフォルダーのFinetuned Whisperモデルを使用できることに注意してください。たとえば、whisper-large-v2-nobを使用する場合は、単に次のことを行うことができます。
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ...また、 whisper_timestampedコマンドラインで使用することもできますwhisperヘルプを参照してください:
whisper_timestamped --help whisper CLIの主な違いは次のとおりです。
--output_dir .ささやきのデフォルトの場合。--verbose Trueです。--accurate ( --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 )を使用できます。--compute_confidence各単語の信頼スコアの計算を有効/無効にする。--punctuations_with_words前の単語で句読点を含めるべきかどうかを決定する。 tinyモデルを使用して複数のファイルを処理し、ウィスパーでデフォルトで実行されるように、現在のフォルダーに結果を出力するための例のコマンドは次のとおりです。
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Huggingfaceまたはローカルフォルダーの微調整されたささやきモデルを使用できることに注意してください。たとえば、whisper-large-v2-nobモデルを使用する場合は、次のことを実行できます。
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
メインのtranscribe関数に加えて、Whisper-Timestamedはいくつかのユーティリティ関数を提供します。
remove_non_speech音声アクティビティ検出(VAD)を使用して、音声セグメントをオーディオから削除します。
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelHuggingfaceからの微調整されたモデルのサポートを含む、特定の名前またはパスからささやきモデルをロードします。
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )whisper_timestamped.transcribe() python関数のplot_word_alignmentオプションまたはwhisper_timestamped CLIの--plotオプションを使用して、各セグメントの単語アライメントを確認できることに注意してください。
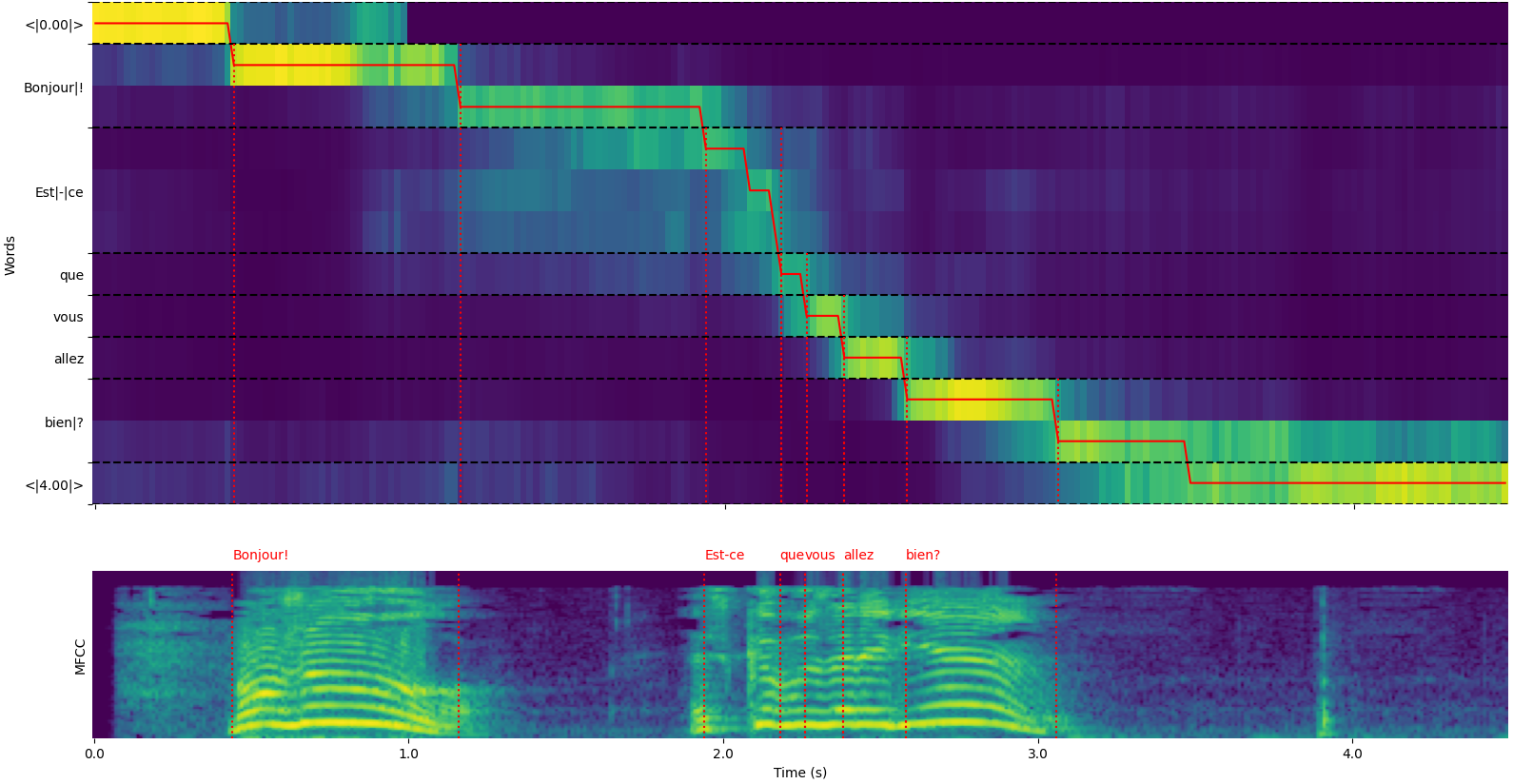
whisper_timestamped.transcribe()関数の出力はPython辞書であり、CLIを使用してJSON形式で表示できます。
JSONスキーマは、テスト/json_schema.jsonで見ることができます。
これが出力の例です。
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
}言語が指定されていない場合(たとえば、CLIのランガージ--language fr )、言語確率を備えた追加のキーがあります。
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)ささやきモデルを使用してオーディオを転写し、単語レベルのタイムスタンプを計算します。
model :ささやきモデルインスタンス転写に使用するささやきモデル。
audio :Union [str、np.ndarray、torch.tensor]は、転写するオーディオファイルへのパス、またはnumpyアレイまたはpytorchテンソルとしてのオーディオ波形。
language :str、オプション(デフォルト:なし)オーディオの言語。なしの場合、言語検出が実行されます。
task :STR、デフォルトのデフォルトは、実行するタスクを「転写」します。音声認識のために「転写」するか、英語への翻訳の「翻訳」。
vad :Union [Bool、str、list [tuple [float、float]]]、オプション(デフォルト:false)音声アクティビティ検出(VAD)を使用して非スピーチセグメントを削除するかどうか。できる:
detect_disfluencies :bool、default false転写のdisfluencies(ためらう、フィラーワードなど)を検出してマークするかどうか。
trust_whisper_timestamps :bool、デフォルトは、最初のセグメントの位置についてささやきのタイムスタンプに依存するかどうかをデフォルト真です。
compute_word_confidence :bool、デフォルト真の単語の信頼スコアを計算するかどうか。
include_punctuation_in_confidence :bool、default false単語の信頼性を計算するときに句読点を含めるかどうか。
refine_whisper_precision :float、default 0.5秒単位で、ささやきセグメントの位置を洗練する量。 0.02の倍数でなければなりません。
min_word_duration :フロート、デフォルト0.02単語の最小期間、秒単位。
plot_word_alignment :boolまたはstr、デフォルトのfalse各セグメントの単語アライメントをプロットするかどうか。文字列の場合は、特定のファイルにプロットを保存します。
word_alignement_most_top_layers :int、optional(default:none)word alignmentに使用する上位レイヤーの数。なしの場合は、すべてのレイヤーを使用します。
remove_empty_words :bool、デフォルトのfalseセグメントの最後に発生する期間のない単語を削除するかどうか。
naive_approach :bool、デフォルトの偽の力は、2回デコードするナイーブなアプローチ(転写のために1回、一度アライメントのために1回)。
use_backend_timestamps :bool、default falseささやきのヒューリスティックによって計算されたものではなく、バックエンド(openai-whisperまたはtransformers)が提供する単語タイムスタンプを使用するかどうか。
temperature :Union [FLOAT、LIST [FLOAT]]、デフォルトのサンプリングのための0.0温度。フォールバック温度の単一値またはリストにすることができます。
compression_ratio_threshold :float、default 2.4 GZIP圧縮比がこの値を上回っている場合、デコードを失敗したように扱います。
logprob_threshold :float、default -1.0平均ログ確率がこの値を下回っている場合、デコードを失敗したように扱います。
no_speech_threshold :float、<| nospeech |> tokensのデフォルト0.6確率しきい値。
condition_on_previous_text :bool、デフォルトは、次のウィンドウのプロンプトとして以前の出力を提供するかどうかをデフォルト真です。
initial_prompt :str、optional(default:none)オプションのテキストは、最初のウィンドウのプロンプトとして提供します。
suppress_tokens :str、デフォルトの "-1"コンマ分離されたトークンIDのリストは、サンプリング中に抑制します。
fp16 :bool、optional(default:none)fp16精度でincomenceを実行するかどうか。
verbose :boolまたはnone、デフォルトのfalseコンソールにデコードされているテキストを表示するかどうか。本当なら、すべての詳細を表示します。 falseの場合、最小限の詳細を表示します。いない場合は、何も表示しません。
含む辞書:
text :str-完全な転写テキストsegments :リスト[dict] - セグメント辞書のリスト、それぞれが含まれています。id :int-セグメントIDseek :int-オーディオファイル(サンプル)の開始位置start :フロート - セグメントの開始時間(秒単位)end :フロート - セグメントの終了時間(秒単位)text :STR-セグメントの転写テキストtokens :セグメントのトークンIDをリスト[int]temperature :フロート - このセグメントに使用される温度avg_logprob :float-セグメントの平均ログ確率compression_ratio :フロート - セグメントの圧縮比no_speech_prob :float-セグメントに音声がない確率confidence :フロート - セグメントの信頼性スコアwords :list [dict] - それぞれが含まれる単語辞書のリスト:start :フロート - 単語の開始時間(秒単位)end :フロート - 単語の終了時間(秒単位)text :str-単語テキストconfidence :フロート - 単語の信頼性スコア(計算された場合)language :STR-検出または指定された言語language_probs :dict-言語検出確率(該当する場合) RuntimeError :VADメソッドが適切にインストールまたは構成されていない場合。ValueError : refine_whisper_precisionが0.02の正の倍数ではない場合。AssertionError :オーディオ期間が予想よりも短い場合、またはセグメントの数に矛盾がある場合。 naive_approachパラメーターは、デバッグや特定のオーディオ特性を処理する場合に役立ちますが、デフォルトのアプローチよりも遅い場合があります。use_efficient_by_defaultがtrueの場合、より効率的な処理のために、 best_of 、 beam_size 、 temperature_increment_on_fallbackなどのパラメーターがデフォルトで設定されていません。remove_non_speech(audio, **kwargs)音声アクティビティ検出(VAD)を使用して、音声セグメントをオーディオから削除します。
audio :PytorchテンソルとしてのTorch.Tensorオーディオデータ。
use_sample :bool、default false trueの場合は、秒ではなくサンプルの開始時間と終了時間を返します。
min_speech_duration :float、デフォルト0.1秒単位の音声セグメントの最小期間。
min_silence_duration :float、デフォルト1サイレットセグメントの最小期間1秒で。
dilatation :フロート、デフォルト0.5秒でVADによって検出された各音声セグメントを拡大する量。
sample_rate :int、デフォルトのオーディオのサンプルレート。
method :strまたはlist [tuple [float、float]]、デフォルトの「シレロ」VADメソッドを使用します。 「Silero」、「Auditok」、またはタイムスタンプのリストにすることができます。
avoid_empty_speech :bool、default false trueの場合、空の音声セグメントを返すことを避けてください。
plot :Union [bool、str]、デフォルトのfalse trueの場合、VAD結果をプロットします。文字列の場合は、特定のファイルにプロットを保存します。
含むタプル:
ImportError :必要なVADライブラリ(Auditokなど)がインストールされていない場合。ValueError :無効なVADメソッドが指定されている場合。 load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)特定の名前またはパスからささやきモデルをロードします。
name :モデルのSTR名またはモデルへのパス。できる:
device :Union [str、torch.device]、使用するオプション(デフォルト:なし)デバイス。なしの場合は、利用可能な場合はCUDAを使用します。
backend :str、使用するデフォルトの「openai-whisper」バックエンド。 「トランス」または「Openai-Whisper」のいずれか。
download_root :str、optional(default:none)rootフォルダーをダウンロードします。ない場合は、デフォルトのダウンロードルートを使用します。
in_memory :bool、デフォルトのfalseモデルの重みをホストメモリにプリロードするかどうか。
ロードされたささやきモデル。
ValueError :無効なバックエンドが指定されている場合。ImportError :「Transformers」バックエンドを使用するときにトランスライブラリがインストールされていない場合。RuntimeError :指定されたソースからモデルを見つけたりダウンロードできない場合。OSError :モデルファイルを読み取ったり、指定されたパスにアクセスしたりする問題がある場合。 get_alignment_heads(model, max_top_layer=3)指定されたモデルのアライメントヘッドを取得します。
model :ささやきモデルインスタンスアライメントヘッドを取得するウィスパーモデル。
max_top_layer :int、デフォルト3アライメントヘッドを考慮する最大3層の最大数。
アライメントヘッドを表すまばらなテンソル。
次の機能は、さまざまなファイル形式にトランスクリプトを作成するために利用できます。
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)トランスクリプトデータをCSVファイルに書き込みます。
transcript :トランスクリプトセグメント辞書のリスト[DICT]リスト。
file :CSVデータを書き込むファイルのようなオブジェクトファイル。
sep :str、default "、" CSVファイルで使用するセパレーター。
text_first :bool、default true if true、開始/終了時間の前にテキスト列を書き込みます。
format_timestamps :callable、optional(default:none)function format timestamp値。
header :Union [bool、list [str]]、デフォルトのfalseがtrue、デフォルトヘッダーを書き込みます。リストの場合は、カスタムヘッダーとして使用します。
IOError :指定されたファイルに書き込む問題がある場合。ValueError :転写データが予想される形式でない場合。 format_timestampsパラメーターは、タイムスタンプ値のカスタムフォーマットを可能にします。これは、特定のユースケースまたはデータ分析要件に役立ちます。 write_srt(transcript, file)トランスクリプトデータをSRT(Subrip Subtitle)ファイルに書き込みます。
transcript :トランスクリプトセグメント辞書のリスト[DICT]リスト。
file :SRTデータを書き込むファイルのようなオブジェクトファイル。
IOError :指定されたファイルに書き込む問題がある場合。ValueError :転写データが予想される形式でない場合。 write_vtt(transcript, file)トランスクリプトデータをVTT(WebVTT)ファイルに書き込みます。
transcript :トランスクリプトセグメント辞書のリスト[DICT]リスト。
file :VTTデータを書き込むファイルのようなオブジェクトファイル。
IOError :指定されたファイルに書き込む問題がある場合。ValueError :転写データが予想される形式でない場合。 write_tsv(transcript, file)トランスクリプトデータをTSV(タブ分離値)ファイルに書き込みます。
transcript :トランスクリプトセグメント辞書のリスト[DICT]リスト。
file :TSVデータを書き込むファイルのようなオブジェクトファイル。
IOError :指定されたファイルに書き込む問題がある場合。ValueError :転写データが予想される形式でない場合。 デフォルトでは有効になっていないが結果が改善される可能性のあるオプションを以下に示します。
前述のように、いくつかのデコードオプションはデフォルトで無効にされ、より良い効率を提供します。ただし、これは転写の品質に影響を与える可能性があります。適切な転写を提供する可能性が最も高いオプションで実行するには、次のオプションを使用してください。
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ...ささやきモデルは、スピーチなしでセグメントを与えられた場合、テキストを「幻覚」することができます。これは、ささやきモデルで転写する前に、VADを実行し、音声セグメントを一緒に接着することで回避できます。これはwhisper-timestampedで可能です。
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...デフォルトでは、使用されるVADメソッドはSileroです。ただし、Sileroの以前のバージョンやAuditokなど、他の方法が利用可能です。これらの方法は、Silero VADの最新バージョンがいくつかのオーディオ(沈黙で検出されたスピーチ)に多くの誤報を持つ可能性があるため、導入されました。
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... VADの結果を視聴するには、 whisper_timestamped CLIの--plotオプション、またはwhisper_timestamped.transcribe() python関数のplot_word_alignmentオプションを使用できます。入力オーディオ信号のVAD結果が次のように表示されます(x軸は数秒で時間です):
| Vad = "Silero:V4.0" | Vad = "Silero:v3.1" | vad = "auditok" |
|---|---|---|
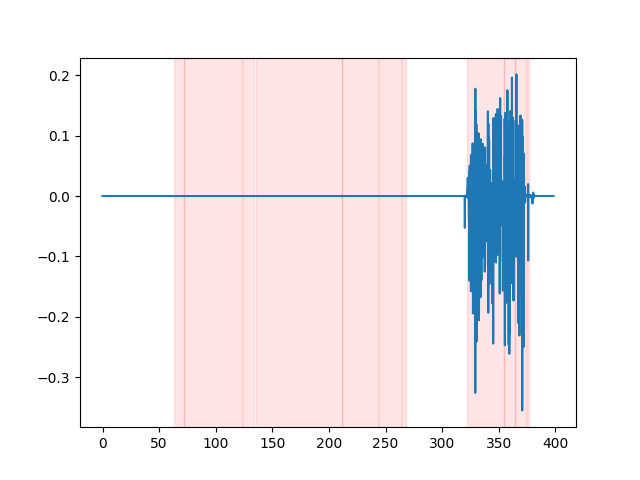 | 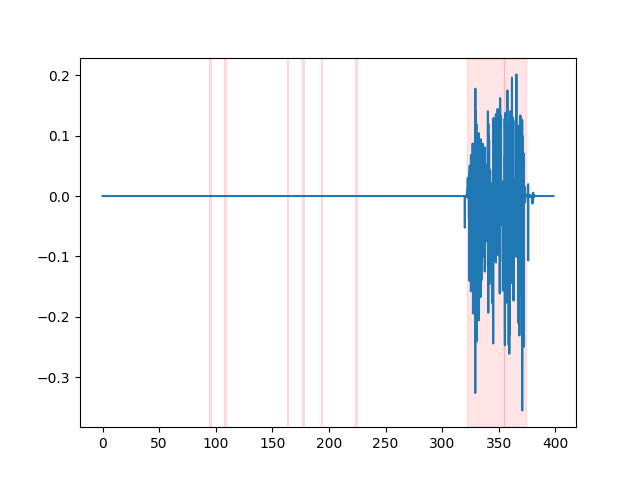 | 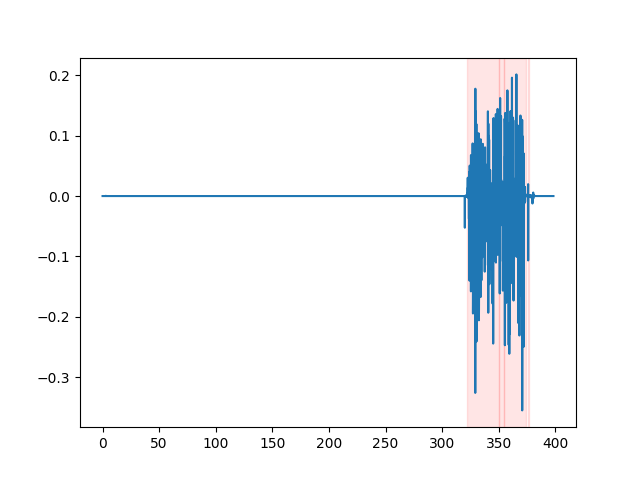 |
ささやきモデルは、音声の障害(フィラーワード、ためらい、繰り返しなど)を削除する傾向があります。予防措置がなければ、転写されていない障害は、次の言葉のタイムスタンプに影響します。単語の始まりのタイムスタンプは、実際には障害の始まりのタイムスタンプになります。 whisper-timestampedこれを避けるためにいくつかのヒューリスティックを持つことができます。
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ...重要:これらのオプションを使用する場合、転写に可能な障害が特別な「 [*] 」ワードとして表示されることに注意してください。
これを調査で使用する場合は、リポジトリを引用してください。
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}Openai Whisper Paperと同様に:
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}そして、ダイナミックタイムワーピングのためのこのペーパー:
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

