whisper timestamped
v1.15.8
Pengenalan ucapan otomatis multibahasa dengan cap waktu dan kepercayaan diri.
Whisper adalah serangkaian model pengenalan suara multi-bahasa yang kuat yang dilatih oleh Openai yang mencapai hasil canggih dalam banyak bahasa. Model Whisper dilatih untuk memprediksi perkiraan waktu pada segmen bicara (sebagian besar waktu dengan akurasi 1 detik), tetapi mereka pada awalnya tidak dapat memprediksi cap waktu kata. Repositori ini mengusulkan implementasi untuk memprediksi cap waktu dan memberikan estimasi segmen bicara yang lebih akurat saat menyalin dengan model bisikan . Selain itu, skor kepercayaan ditugaskan untuk setiap kata dan setiap segmen.
Pendekatan ini didasarkan pada Dynamic Time Warping (DTW) yang diterapkan pada bobot silang, seperti yang ditunjukkan oleh buku catatan ini oleh Jong Wook Kim. Ada beberapa tambahan untuk buku catatan ini:
whisper-timestamped dapat memproses file panjang dengan sedikit memori tambahan dibandingkan dengan penggunaan model Whisper secara teratur. whisper-timestamped adalah perpanjangan dari paket python openai-whisper dan dimaksudkan untuk kompatibel dengan versi openai-whisper apa pun. Ini memberikan stempel waktu kata yang lebih efisien/akurat, bersama dengan fitur -fitur tambahan tersebut:
Penafian: Harap dicatat bahwa ekstensi ini dimaksudkan untuk tujuan eksperimental dan dapat secara signifikan memengaruhi kinerja. Kami tidak bertanggung jawab atas masalah atau ketidakefisienan yang muncul dari penggunaannya.
Pendekatan alternatif yang relevan untuk memulihkan stempel waktu tingkat kata melibatkan penggunaan model WAV2VEC yang memprediksi karakter, sebagaimana berhasil diimplementasikan di Whisperx. Namun, pendekatan ini memiliki beberapa kelemahan yang tidak ada dalam pendekatan berdasarkan bobot silang seperti whisper_timestamped . Kelemahan ini termasuk:
Pendekatan alternatif yang tidak memerlukan model tambahan adalah dengan melihat probabilitas token cap waktu yang diperkirakan oleh model Whisper setelah masing -masing (sub) token kata diprediksi. Ini diimplementasikan, misalnya, di Whisper.cpp dan stabil-TS. Namun, pendekatan ini tidak memiliki ketahanan karena model Whisper belum dilatih untuk menghasilkan cap waktu yang bermakna setelah setiap kata. Model Whisper cenderung memprediksi cap waktu hanya setelah sejumlah kata telah diprediksi (biasanya pada akhir kalimat), dan distribusi probabilitas cap waktu di luar kondisi ini mungkin tidak akurat. Dalam praktiknya, metode ini dapat menghasilkan hasil yang benar-benar tidak sinkron pada beberapa periode waktu (kami mengamati ini terutama ketika ada musik jingle). Juga, presisi waktu model bisikan cenderung dibulatkan menjadi 1 detik (seperti dalam banyak subtitle video), yang terlalu tidak akurat untuk kata -kata, dan mencapai akurasi yang lebih baik adalah rumit.
Persyaratan:
python3 (versi lebih tinggi atau sama dengan 3,7, setidaknya 3,9 direkomendasikan)ffmpeg (lihat instruksi untuk instalasi pada repositori Whisper) Anda dapat menginstal whisper-timestamped baik dengan menggunakan PIP:
pip3 install whisper-timestampedatau dengan mengkloning repositori ini dan menjalankan instalasi:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py installJika Anda ingin merencanakan penyelarasan antara cap audio dan kata -kata (seperti pada bagian ini), Anda juga memerlukan matplotlib:
pip3 install matplotlibJika Anda ingin menggunakan opsi VAD (deteksi aktivitas suara sebelum menjalankan model Whisper), Anda juga memerlukan torchaudio dan onnxruntime:
pip3 install onnxruntime torchaudioJika Anda ingin menggunakan model Whisper Finetuned dari Hugging Face Hub, Anda juga membutuhkan Transformers:
pip3 install transformersGambar Docker sekitar 9GB dapat dibangun menggunakan:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .Jika Anda tidak memiliki GPU (atau tidak ingin menggunakannya), maka Anda tidak perlu menginstal dependensi CUDA. Anda kemudian harus hanya menginstal versi lampu obor sebelum menginstal wisper-times, misalnya sebagai berikut:
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.htmlGambar Docker spesifik sekitar 3.5GB juga dapat dibangun menggunakan:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .Saat menggunakan PIP, perpustakaan dapat diperbarui ke versi terbaru menggunakan:
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
Versi spesifik openai-whisper dapat digunakan dengan menjalankan, misalnya:
pip3 install openai-whisper==20230124 Dalam Python, Anda dapat menggunakan fungsi whisper_timestamped.transcribe() , yang mirip dengan fungsi whisper.transcribe() :
import whisper_timestamped
help ( whisper_timestamped . transcribe ) Perbedaan utama dengan whisper.transcribe() adalah bahwa output akan menyertakan "words" kunci untuk semua segmen, dengan kata start dan posisi akhir. Perhatikan bahwa kata tersebut akan mencakup tanda baca. Lihat contoh di bawah ini.
Selain itu, opsi decoding default berbeda untuk mendukung decoding yang efisien (decoding serakah alih -alih pencarian balok, dan tidak ada suhu pengambilan sampel suhu). Untuk memiliki default yang sama seperti di whisper , gunakan beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0) .
Ada juga opsi tambahan yang terkait dengan penyelarasan kata.
Secara umum, jika Anda mengimpor whisper_timestamped alih -alih whisper dalam skrip python Anda dan menggunakan transcribe(model, ...) alih -alih model.transcribe(...) , itu harus melakukan pekerjaan:
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) Perhatikan bahwa Anda dapat menggunakan model Whisper finetuned dari Huggingface atau folder lokal dengan menggunakan metode load_model dari whisper_timestamped . Misalnya, jika Anda ingin menggunakan Whisper-Large-V2-nob, Anda dapat melakukan hal berikut:
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ... Anda juga dapat menggunakan whisper_timestamped pada baris perintah, mirip dengan whisper . Lihat Bantuan dengan:
whisper_timestamped --help Perbedaan utama dengan CLI whisper adalah:
--output_dir . untuk wisper default.--verbose True untuk wisper default.--accurate (yang merupakan alias untuk --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 ).--compute_confidence untuk mengaktifkan/menonaktifkan perhitungan skor kepercayaan untuk setiap kata.--punctuations_with_words untuk memutuskan apakah tanda baca harus dimasukkan atau tidak dengan kata-kata sebelumnya. Perintah contoh untuk memproses beberapa file menggunakan model tiny dan output hasil di folder saat ini, seperti yang akan dilakukan secara default dengan Whisper, adalah sebagai berikut:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Perhatikan bahwa Anda dapat menggunakan model Whisper yang disempurnakan dari Huggingface atau folder lokal. Misalnya, jika Anda ingin menggunakan model Whisper-Large-V2-nob, Anda dapat melakukan hal berikut:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
Selain fungsi transcribe utama, Whisper-ditestamped menyediakan beberapa fungsi utilitas:
remove_non_speechHapus segmen non-speech dari audio menggunakan Deteksi Aktivitas Suara (VAD).
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelMuat model bisikan dari nama atau jalur yang diberikan, termasuk dukungan untuk model yang disesuaikan dari Huggingface.
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" ) Perhatikan bahwa Anda dapat menggunakan opsi plot_word_alignment dari fungsi python whisper_timestamped.transcribe() atau opsi --plot cli whisper_timestamped untuk melihat kata penyelarasan untuk setiap segmen.
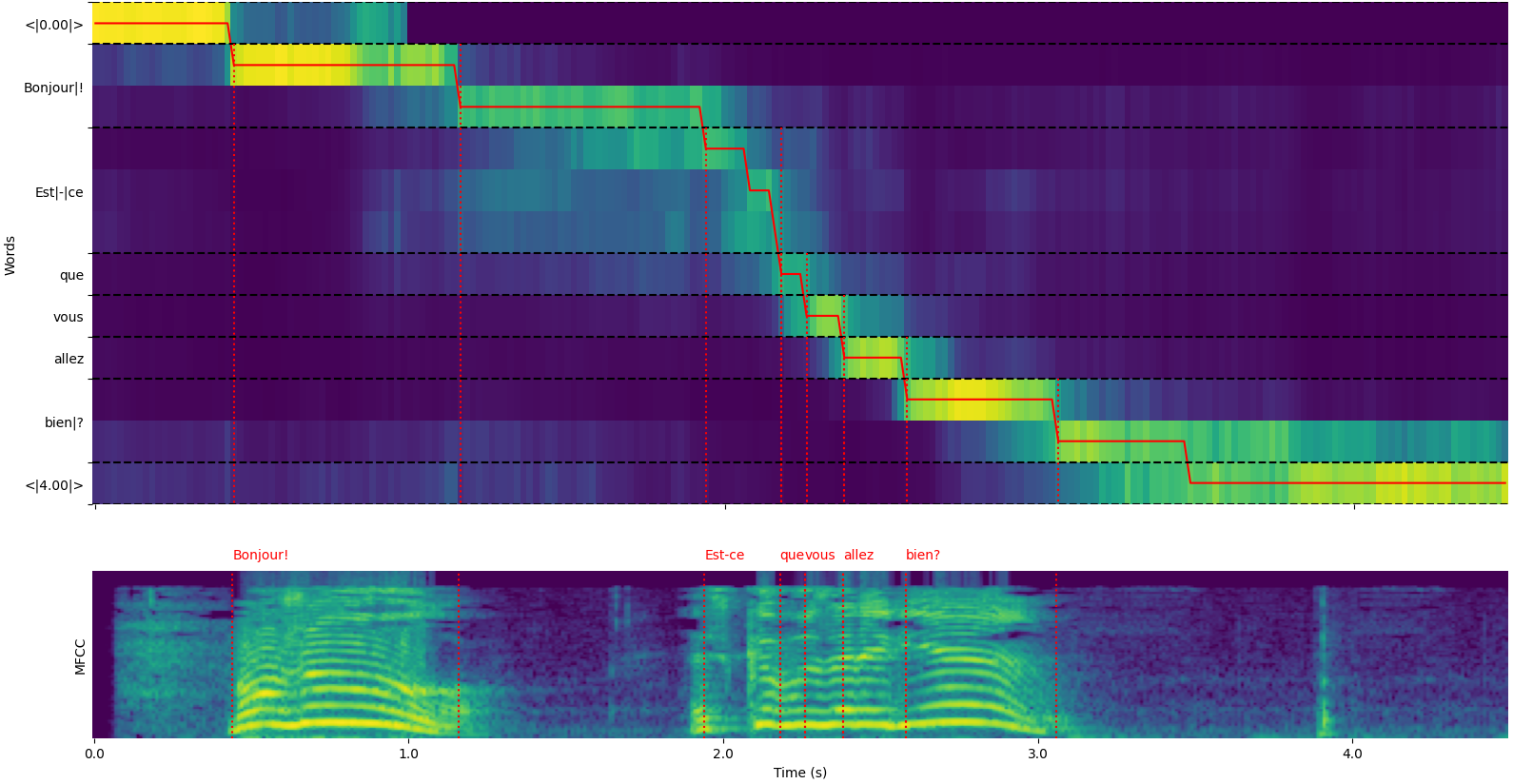
Output fungsi whisper_timestamped.transcribe() adalah kamus Python, yang dapat dilihat dalam format JSON menggunakan CLI.
Skema JSON dapat dilihat di Tests/json_schema.json.
Berikut adalah contoh output:
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
} Jika bahasa tidak ditentukan (misalnya tanpa opsi --language fr di CLI) Anda akan menemukan kunci tambahan dengan probabilitas bahasa:
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)Transkripsi audio menggunakan model bisikan dan menghitung cap waktu level kata.
model : Model Whisper Contoh Model Whisper untuk digunakan untuk transkripsi.
audio : Union [str, np.ndarray, torch.tensor] Jalur ke file audio untuk ditranskripsi, atau bentuk gelombang audio sebagai array numpy atau tentorch tensor.
language : STR, opsional (default: tidak ada) bahasa audio. Jika tidak ada, deteksi bahasa akan dilakukan.
task : STR, default "Transcribe" Tugas untuk Dilakukan: Baik "Transcribe" untuk pengenalan ucapan atau "menerjemahkan" untuk terjemahan ke bahasa Inggris.
vad : Union [bool, str, daftar [tuple [float, float]]], opsional (default: false) apakah akan menggunakan deteksi aktivitas suara (VAD) untuk menghapus segmen non-speech. Bisa:
detect_disfluencies : bool, default false apakah akan mendeteksi dan menandai disfluensi (keraguan, kata pengisi, dll.) Dalam transkripsi.
trust_whisper_timestamps : bool, default benar apakah akan mengandalkan cap waktu Whisper untuk posisi segmen awal.
compute_word_confidence : bool, default true apakah akan menghitung skor kepercayaan untuk kata -kata.
include_punctuation_in_confidence : bool, default false apakah akan memasukkan probabilitas tanda baca saat menghitung kepercayaan kata.
refine_whisper_precision : float, default 0,5 berapa banyak untuk memperbaiki posisi segmen bisikan, dalam detik. Harus kelipatan 0,02.
min_word_duration : float, default 0,02 Durasi minimum kata, dalam detik.
plot_word_alignment : bool atau str, default false apakah akan memplot kata penyelarasan untuk setiap segmen. Jika string, simpan plot ke file yang diberikan.
word_alignement_most_top_layers : int, opsional (default: tidak ada) Jumlah lapisan atas untuk digunakan untuk penyelarasan kata. Jika tidak ada, gunakan semua lapisan.
remove_empty_words : bool, default false apakah akan menghapus kata tanpa durasi terjadi di akhir segmen.
naive_approach : bool, default force force pendekatan naif decoding dua kali (sekali untuk transkripsi, sekali untuk penyelarasan).
use_backend_timestamps : bool, default false apakah akan menggunakan stempel waktu kata yang disediakan oleh backend (openai-whisper atau transformers), alih-alih yang dihitung oleh heuristik yang lebih kompleks dari wisper-timestamped.
temperature : Union [float, list [float]], default 0,0 suhu untuk pengambilan sampel. Dapat berupa nilai tunggal atau daftar suhu fallback.
compression_ratio_threshold : float, default 2.4 Jika rasio kompresi GZIP di atas nilai ini, perlakukan decoding sebagai gagal.
logprob_threshold : float, default -1.0 Jika probabilitas log rata -rata di bawah nilai ini, perlakukan decoding sebagai gagal.
no_speech_threshold : float, default 0.6 Probabilitas ambang batas untuk <| nospeech |> Token.
condition_on_previous_text : bool, default true apakah akan memberikan output sebelumnya sebagai prompt untuk jendela berikutnya.
initial_prompt : str, opsional (default: tidak ada) teks opsional untuk disediakan sebagai prompt untuk jendela pertama.
suppress_tokens : str, default "-1" Daftar token ID yang dipisahkan koma untuk ditekan selama pengambilan sampel.
fp16 : BOOL, Opsional (Default: Tidak Ada) Apakah akan melakukan inferensi pada presisi FP16.
verbose : bool atau tidak sama sekali, default false apakah akan menampilkan teks yang diterjemahkan ke konsol. Jika benar, menampilkan semua detail. Jika salah, menampilkan detail minimal. Jika tidak ada, tidak menampilkan apa pun.
Kamus yang berisi:
text : STR - Teks transkripsi lengkapsegments : Daftar [Dikt] - Daftar kamus segmen, masing -masing berisi:id : int - ID segmenseek : int - Mulai posisi dalam file audio (dalam sampel)start : Float - Mulai Waktu Segmen (dalam Detik)end : Float - End Time of the Segmen (dalam detik)text : STR - Teks yang ditranskripsi untuk segmen initokens : Daftar [int] - Token ID untuk segmentemperature : mengapung - suhu yang digunakan untuk segmen iniavg_logprob : float - probabilitas log rata -rata segmencompression_ratio : float - rasio kompresi segmenno_speech_prob : float - probabilitas tidak ada pidato di segmenconfidence : Mengapung - Skor Keyakinan untuk Segmenwords : Daftar [Dikt] - Daftar kamus kata, masing -masing berisi:start : float - Mulai waktu kata (dalam detik)end : Float - End Time of the Word (dalam detik)text : Str - The Word Textconfidence : Mengapung - Skor Keyakinan untuk Kata (jika dihitung)language : STR - Bahasa yang terdeteksi atau ditentukanlanguage_probs : Dikt - Probabilitas Deteksi Bahasa (jika berlaku) RuntimeError : Jika metode VAD tidak diinstal atau dikonfigurasi dengan benar.ValueError : Jika refine_whisper_precision bukan kelipatan positif 0,02.AssertionError : Jika durasi audio lebih pendek dari yang diharapkan atau jika ada ketidakkonsistenan dalam jumlah segmen. naive_approach dapat berguna untuk debugging atau ketika berhadapan dengan karakteristik audio tertentu, tetapi mungkin lebih lambat dari pendekatan default.use_efficient_by_default benar, beberapa parameter seperti best_of , beam_size , dan temperature_increment_on_fallback diatur ke tidak ada secara default untuk pemrosesan yang lebih efisien.remove_non_speech(audio, **kwargs)Hapus segmen non-speech dari audio menggunakan Deteksi Aktivitas Suara (VAD).
audio : Data audio TORCH.Tensor sebagai Tensor Pytorch.
use_sample : bool, default false jika benar, kembalikan waktu mulai dan akhir dalam sampel, bukan detik.
min_speech_duration : float, default 0,1 durasi minimum segmen bicara dalam hitungan detik.
min_silence_duration : float, default 1 durasi minimum segmen keheningan dalam detik.
dilatation : float, default 0,5 berapa banyak untuk memperbesar setiap segmen pidato yang terdeteksi oleh VAD, dalam hitungan detik.
sample_rate : int, laju sampel 16000 default audio.
method : STR atau Daftar [tuple [float, float]], metode default "Silero" untuk digunakan. Bisa "silero", "auditok", atau daftar cap waktu.
avoid_empty_speech : bool, default false jika benar, hindari mengembalikan segmen ucapan kosong.
plot : Union [bool, str], default false jika benar, plot hasil VAD. Jika string, simpan plot ke file yang diberikan.
Tuple yang berisi:
ImportError : Jika perpustakaan VAD yang diperlukan (misalnya, auditok) tidak diinstal.ValueError : Jika metode VAD yang tidak valid ditentukan. load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)Muat model bisikan dari nama atau jalur yang diberikan.
name : STR Nama model atau jalur ke model. Bisa:
device : Union [STR, TORCH.Device], Opsional (Default: None) Device untuk digunakan. Jika tidak ada, gunakan CUDA jika tersedia, jika tidak CPU.
backend : STR, default "OpenAI-WHISPER" Backend untuk digunakan. "Transformers" atau "openai-whisper".
download_root : str, folder root opsional (default: none) untuk mengunduh model ke. Jika tidak ada, gunakan root unduhan default.
in_memory : bool, default false apakah akan memuat bobot model ke dalam memori host.
Model Whisper yang dimuat.
ValueError : Jika backend yang tidak valid ditentukan.ImportError : Jika pustaka Transformers tidak diinstal saat menggunakan backend "Transformers".RuntimeError : Jika model tidak dapat ditemukan atau diunduh dari sumber yang ditentukan.OSError : Jika ada masalah yang membaca file model atau mengakses jalur yang ditentukan. get_alignment_heads(model, max_top_layer=3)Dapatkan kepala penyelarasan untuk model yang diberikan.
model : Model Whisper Contoh Model Whisper untuk mengambil kepala penyelarasan.
max_top_layer : int, default 3 jumlah maksimum lapisan atas untuk dipertimbangkan untuk kepala penyelarasan.
Tensor jarang yang mewakili kepala penyelarasan.
Fungsi berikut tersedia untuk menulis transkrip ke berbagai format file:
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)Tulis data transkrip ke file CSV.
transcript : Daftar [Dikt] Daftar Kamus Segmen Transkrip.
file : File objek seperti file untuk menulis data CSV ke.
sep : str, default "," pemisah untuk digunakan dalam file CSV.
text_first : bool, default true jika benar, tulis kolom teks sebelum start/end time.
format_timestamps : Callable, opsional (default: tidak ada) berfungsi untuk memformat nilai cap waktu.
header : Union [bool, daftar [str]], default false jika benar, tulis header default. Jika daftar, gunakan sebagai header khusus.
IOError : Jika ada masalah yang menulis ke file yang ditentukan.ValueError : Jika data transkrip tidak dalam format yang diharapkan. format_timestamps memungkinkan untuk pemformatan kustom nilai cap waktu, yang dapat bermanfaat untuk kasus penggunaan tertentu atau persyaratan analisis data. write_srt(transcript, file)Tulis data transkrip ke file SRT (subrip subtitle).
transcript : Daftar [Dikt] Daftar Kamus Segmen Transkrip.
file : File objek seperti file untuk menulis data SRT ke.
IOError : Jika ada masalah yang menulis ke file yang ditentukan.ValueError : Jika data transkrip tidak dalam format yang diharapkan. write_vtt(transcript, file)Tulis data transkrip ke file VTT (WebVTT).
transcript : Daftar [Dikt] Daftar Kamus Segmen Transkrip.
file : File objek seperti file untuk menulis data VTT ke.
IOError : Jika ada masalah yang menulis ke file yang ditentukan.ValueError : Jika data transkrip tidak dalam format yang diharapkan. write_tsv(transcript, file)Tulis data transkrip ke file TSV (Nilai yang dipisahkan Tab).
transcript : Daftar [Dikt] Daftar Kamus Segmen Transkrip.
file : File objek seperti file untuk menulis data TSV ke.
IOError : Jika ada masalah yang menulis ke file yang ditentukan.ValueError : Jika data transkrip tidak dalam format yang diharapkan. Berikut adalah beberapa opsi yang tidak diaktifkan secara default tetapi dapat meningkatkan hasil.
Seperti yang disebutkan sebelumnya, beberapa opsi decoding dinonaktifkan secara default untuk menawarkan efisiensi yang lebih baik. Namun, ini dapat memengaruhi kualitas transkripsi. Untuk menjalankan dengan opsi yang memiliki peluang terbaik untuk memberikan transkripsi yang baik, gunakan opsi berikut.
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ... Model Whisper dapat "berhalusinasi" teks saat diberikan segmen tanpa bicara. Ini dapat dihindari dengan menjalankan VAD dan menempelkan segmen ucapan bersama sebelum menyalin dengan model Whisper. Ini dimungkinkan dengan whisper-timestamped .
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...Secara default, metode VAD yang digunakan adalah Silero. Tetapi metode lain tersedia, seperti versi sebelumnya dari Silero, atau Auditok. Metode -metode tersebut diperkenalkan karena versi terbaru Silero Vad dapat memiliki banyak alarm palsu di beberapa audio (wicara yang terdeteksi pada keheningan).
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... Untuk menonton hasil VAD, Anda dapat menggunakan opsi --plot CLI whisper_timestamped , atau opsi plot_word_alignment dari fungsi python whisper_timestamped.transcribe() . Ini akan menunjukkan hasil VAD pada sinyal audio input sebagai berikut (sumbu x adalah waktu dalam detik):
| vad = "silero: v4.0" | vad = "silero: v3.1" | vad = "auditok" |
|---|---|---|
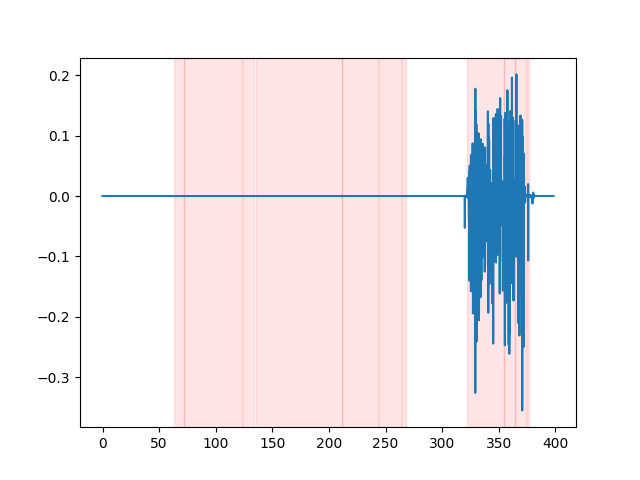 | 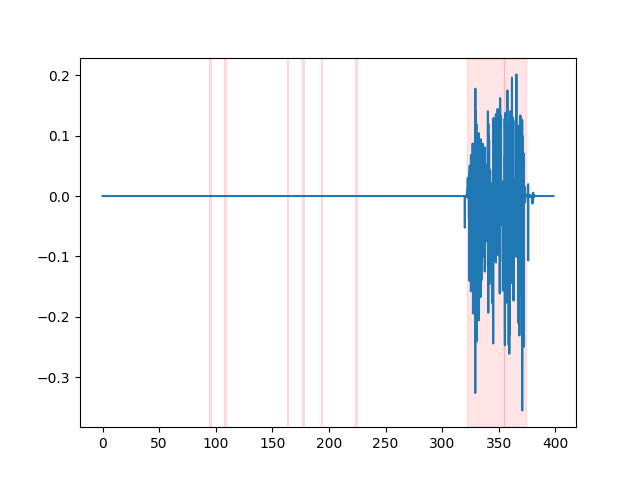 | 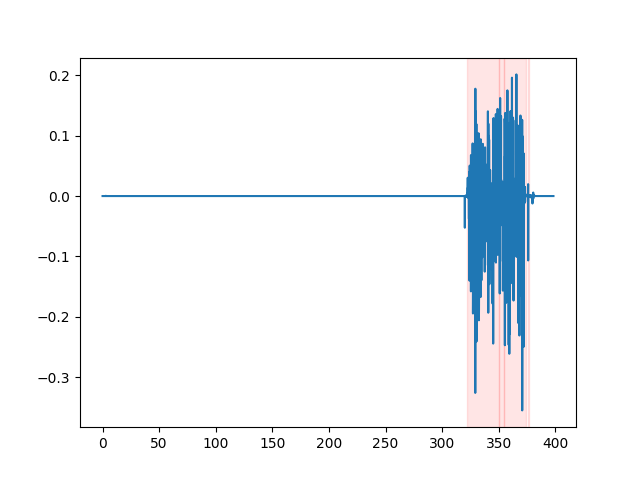 |
Model Whisper cenderung menghilangkan disfluensi bicara (kata pengisi, keraguan, pengulangan, dll.). Tanpa tindakan pencegahan, disfluensi yang tidak ditranskripsikan akan mempengaruhi cap waktu dari kata berikut: cap waktu awal kata sebenarnya akan menjadi cap waktu awal disfluensi. whisper-timestamped dapat memiliki beberapa heuristik untuk menghindari ini.
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ... Penting: Perhatikan bahwa saat menggunakan opsi ini, kemungkinan disfluensi akan muncul dalam transkripsi sebagai kata khusus " [*] ".
Jika Anda menggunakan ini dalam riset Anda, silakan kutip repo:
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}serta kertas bisikan openai:
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}Dan makalah ini untuk mendapatkan waktu yang dinamis:
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

