whisper timestamped
v1.15.8
단어 수준 타임 스탬프 및 신뢰를 가진 다국어 자동 음성 인식.
Whisper는 Openai가 교육하는 다국어, 강력한 음성 인식 모델 세트로 여러 언어로 최첨단 결과를 달성합니다. 속삭임 모델은 음성 세그먼트에서 근사한 타임 스탬프를 예측하도록 훈련되었지만 (대부분 1 초 정확도로) 원래 단어 타임 스탬프를 예측할 수는 없습니다. 이 저장소는 단어 타임 스탬프를 예측하는 구현을 제안하고 속삭임 모델로 전사 할 때 더 정확한 음성 세그먼트를 제공합니다 . 게다가, 신뢰 점수는 각 단어와 각 세그먼트에 할당됩니다.
이 접근 방식은 Jong Wook Kim 의이 노트북에서 보여준 바와 같이, 교차 무의미한 가중치에 적용되는 DTW (Dynamic Time Warping)를 기반으로합니다. 이 노트에 추가 사항이 있습니다.
whisper-timestamped Whisper 모델의 정기적 인 사용과 비교하여 추가 메모리가 거의없는 긴 파일을 처리 할 수 있습니다. whisper-timestamped 는 openai-whisper Python 패키지의 확장이며 모든 버전의 openai-whisper 와 호환됩니다. 추가 기능과 함께보다 효율적이고 정확한 단어 타임 스탬프를 제공합니다.
면책 조항 :이 확장은 실험 목적을위한 것이며 성능에 크게 영향을 줄 수 있습니다. 우리는 그 사용으로 인해 발생하는 문제 나 비 효율성에 대해 책임을지지 않습니다.
단어 수준 타임 스탬프를 복구하는 대안 적 관련 접근법은 Wisperx에서 성공적으로 구현 된 문자를 예측하는 WAV2VEC 모델을 사용하는 것입니다. 그러나 이러한 접근법에는 whisper_timestamped 와 같은 상호 관측 중량에 기초한 접근법에는 존재하지 않는 몇 가지 단점이 있습니다. 이러한 단점에는 다음이 포함됩니다.
추가 모델이 필요하지 않은 대체 접근법은 각 (서브) 단어 토큰이 예측 된 후 Whisper 모델에 의해 추정 된 타임 스탬프 토큰의 확률을 보는 것입니다. 예를 들어 Whisper.CPP 및 안정적인 TT에서 구현되었습니다. 그러나이 접근법에는 Whisper 모델이 각 단어 후에 의미있는 타임 스탬프를 출력하도록 훈련되지 않았기 때문에이 접근법은 견고성이 없습니다. Whisper 모델은 특정 수의 단어가 예측 된 후에 만 타임 스탬프를 예측하는 경향이 있으며 (일반적으로 문장 끝에),이 조건 외부의 타임 스탬프의 확률 분포는 부정확 할 수 있습니다. 실제로, 이러한 방법은 일정 기간 동안 완전히 동기화되지 않은 결과를 생성 할 수 있습니다 (특히 징글 음악이있을 때이를 관찰했습니다). 또한 Whisper 모델의 타임 스탬프 정밀도는 1 초로 반올림되는 경향이 있으며 (많은 비디오 자막에서와 같이) 단어에 너무 부정확하며 더 나은 정확도에 도달하는 것은 까다 롭습니다.
요구 사항 :
python3 (3.7, 3.9 이상의 버전이 권장됩니다)ffmpeg (Whisper Repository의 설치 지침 참조) PIP를 사용하여 whisper-timestamped 설치할 수 있습니다.
pip3 install whisper-timestamped또는이 저장소를 복제하고 설치를 실행함으로써 :
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py install오디오 타임 스탬프와 단어 사이 (이 섹션에서와 같이) 사이의 정렬을 플로팅하려면 matplotlib도 필요합니다.
pip3 install matplotlibVAD 옵션 (Whisper 모델을 실행하기 전에 음성 활동 감지)을 사용하려면 Torchaudio 및 OnnxRuntime도 필요합니다.
pip3 install onnxruntime torchaudioHugging Face Hub의 Finetuned Whisper 모델을 사용하려면 Transformers도 필요합니다.
pip3 install transformers약 9GB의 도커 이미지는 다음을 사용하여 구축 할 수 있습니다.
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .GPU가 없거나 사용하고 싶지 않은 경우 CUDA 종속성을 설치할 필요가 없습니다. 그런 다음 Whisper-Timestamped를 설치하기 전에 다음과 같이 Light 버전의 Torch를 설치해야합니다.
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.html약 3.5GB의 특정 도커 이미지는 다음을 사용하여 구축 할 수 있습니다.
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .PIP를 사용하는 경우 라이브러리는 다음을 사용하여 최신 버전으로 업데이트 할 수 있습니다.
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
예를 들어 실행하면 특정 버전의 openai-whisper 사용할 수 있습니다.
pip3 install openai-whisper==20230124 Python에서는 whisper_timestamped.transcribe() 와 유사한 함수 whisper.transcribe() 를 사용할 수 있습니다.
import whisper_timestamped
help ( whisper_timestamped . transcribe ) whisper.transcribe() 의 주요 차이점은 출력에 시작 및 종료 위치가있는 모든 세그먼트에 대한 "words" 가 포함된다는 것입니다. 단어에는 구두점이 포함됩니다. 아래 예제를 참조하십시오.
또한 기본 디코딩 옵션은 효율적인 디코딩을 선호하는 데 다르고 (빔 검색 대신 욕심 많은 디코딩 및 온도 샘플링 낙하가 없음). whisper 에서와 동일한 기본값을 사용하려면 beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0) 사용하십시오.
단어 정렬과 관련된 추가 옵션도 있습니다.
일반적으로 Python 스크립트에서 whisper 대신 whisper_timestamped 가져 와서 model.transcribe ( transcribe(model, ...) model.transcribe(...) 사용하면 작업을 수행해야합니다.
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) whisper_timestamped 의 load_model 메소드를 사용하여 Huggingface 또는 로컬 폴더의 Finetuned Whisper 모델을 사용할 수 있습니다. 예를 들어, Whisper-Large-V2-Nob을 사용하려면 다음을 수행 할 수 있습니다.
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ... whisper 와 유사하게 명령 줄에서 whisper_timestamped 사용할 수도 있습니다. 도움말을 참조하십시오 :
whisper_timestamped --help whisper Cli의 주요 차이점은 다음과 같습니다.
--output_dir . Whisper Default의 경우.--verbose True for Whisper Default.--accurate ( --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 의 별칭입니다.--compute_confidence 각 단어에 대한 신뢰 점수 계산을 활성화/비활성화합니다.--punctuations_with_words 구두점 마크가 포함되어야하는지 여부를 결정하려면 앞의 단어가 포함되어 있지 않습니다. tiny 모델을 사용하여 여러 파일을 처리하고 Whisper와 함께 기본적으로 수행되는 것처럼 현재 폴더의 결과를 출력하는 예제 명령은 다음과 같습니다.
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Huggingface 또는 로컬 폴더에서 미세 조정 된 속삭임 모델을 사용할 수 있습니다. 예를 들어, Whisper-Large-V2-Nob 모델을 사용하려면 다음을 수행 할 수 있습니다.
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
주요 transcribe 기능 외에도 Whisper-Timestamped는 몇 가지 유틸리티 기능을 제공합니다.
remove_non_speech음성 활동 감지 (VAD)를 사용하여 오디오에서 비석 세그먼트를 제거하십시오.
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelHuggingface의 미세 조정 모델에 대한 지원을 포함하여 주어진 이름 또는 경로에서 Whisper 모델을로드하십시오.
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" ) whisper_timestamped.transcribe() python function 또는 whisper_timestamped cli의 --plot 옵션의 plot_word_alignment 옵션을 사용하여 각 세그먼트의 단어 정렬을 볼 수 있습니다.
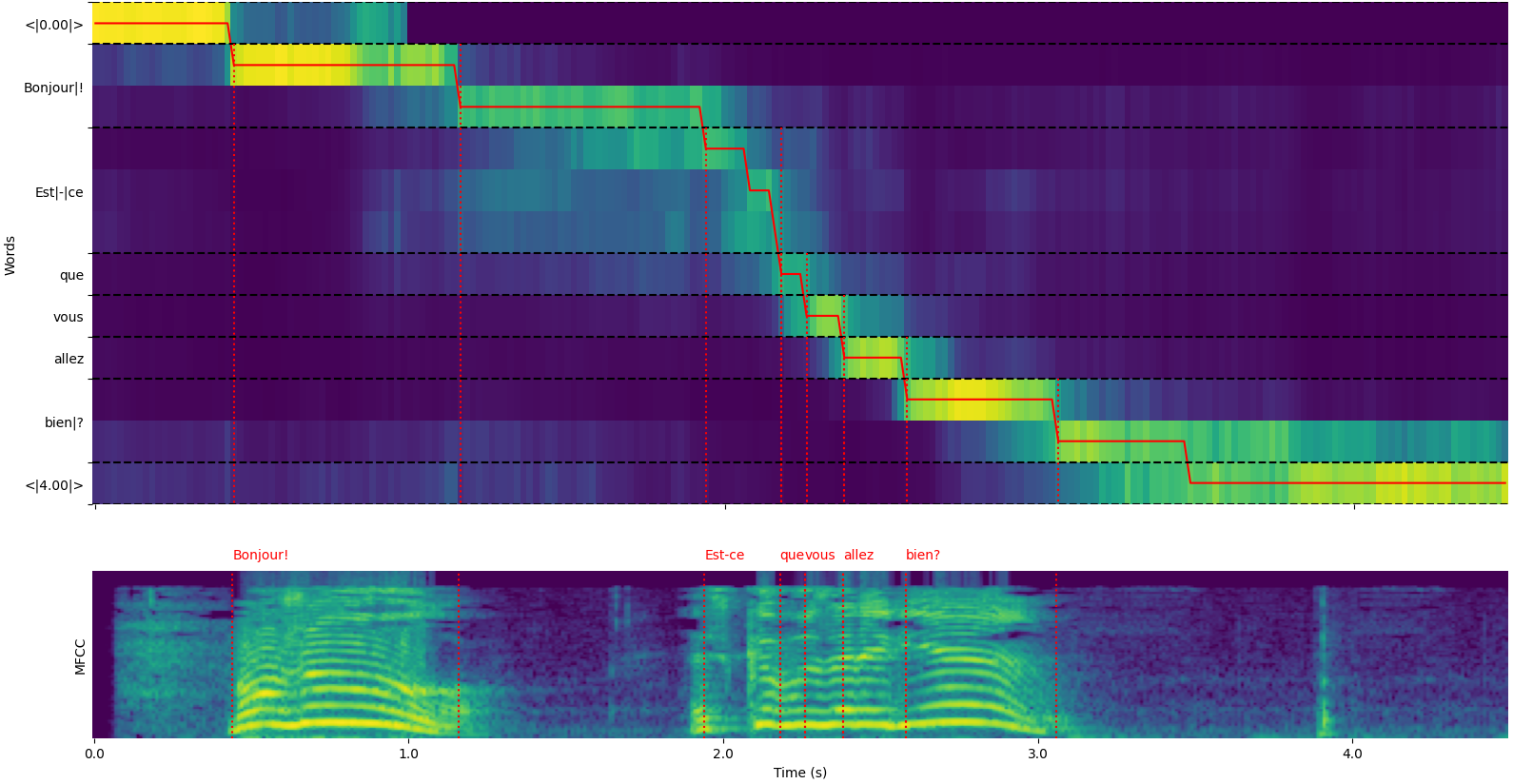
whisper_timestamped.transcribe() 함수의 출력은 Python Dictionary이며 CLI를 사용하여 JSON 형식으로 볼 수 있습니다.
JSON 스키마는 테스트/json_schema.json에서 볼 수 있습니다.
예제 출력은 다음과 같습니다.
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
} 언어가 지정되지 않은 경우 (예 : 옵션없이 -CLI의 --language fr ) 언어 확률과 함께 추가 키를 찾을 수 있습니다.
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)Whisper 모델을 사용하여 오디오를 전사하고 단어 수준 타임 스탬프를 계산하십시오.
model : 속삭임 모델 인스턴스 전사에 사용할 속삭임 모델.
audio : Union [STR, NP.NDARRAY, TORCH.TENSOR] 오디오 파일의 경로 또는 오디오 파형을 낭비한 배열 또는 Pytorch 텐서로서의 오디오 파형.
language : STR, 선택 사항 (기본값 : 없음) 오디오의 언어. 없으면 언어 탐지가 수행됩니다.
task : STR, 기본적으로 "전사"작업 : 음성 인식을 위해 "전사"또는 영어로 번역을 위해 "번역".
vad : Union [bool, str, list [tuple [float, float]], 옵션 (기본값 : false)을 사용하여 음성 활동 감지 (VAD)를 제거 할 것인지 비석 세그먼트를 제거할지 여부. 될 수 있습니다 :
detect_disfluencies : bool, 기본적으로 전사에서 불만을 감지하고 표시할지 표시할지 여부.
trust_whisper_timestamps : bool, 기본적으로 초기 세그먼트 위치에 대한 Whisper의 타임 스탬프에 의존할지 여부.
compute_word_confidence : bool, default true 단어에 대한 신뢰 점수를 계산할지 여부.
include_punctuation_in_confidence : bool, default false 단어 신뢰를 계산할 때 구두점 확률을 포함할지 여부.
refine_whisper_precision : float, 기본값 0.5 몇 초 만에 속삭임 세그먼트 위치를 개선 할 수 있습니다. 0.02의 배수 여야합니다.
min_word_duration : float, 기본 0.02 단어의 최소 기간, 초.
plot_word_alignment : bool 또는 str, 기본값 거짓 각 세그먼트에 대한 단어 정렬을 플로팅할지 여부. 문자열이라면 플롯을 주어진 파일에 저장하십시오.
word_alignement_most_top_layers : int, 옵션 (기본값 : 없음) 단어 정렬에 사용할 최상층 수. 없는 경우 모든 레이어를 사용하십시오.
remove_empty_words : bool, default false 세그먼트 끝에 지속 시간이 발생하지 않은 단어를 제거할지 여부.
naive_approach : bool, 기본 거짓 힘 디코딩의 순진한 접근법 (정렬을 위해 한 번 전사의 경우 한 번).
use_backend_timestamps : bool, 기본적으로 Whisper-Timestamped의보다 복잡한 휴리스틱으로 계산 된 것 대신 Backend (Openai-Whisper 또는 Transformers)가 제공하는 단어 타임 스탬프를 사용할지 여부.
temperature : Union [float, list [float]], 샘플링의 기본 0.0 온도. 단일 값 또는 폴백 온도의 목록 일 수 있습니다.
compression_ratio_threshold : float, default 2.4 GZIP 압축 비율 이이 값보다 높으면 디코딩을 실패한 것으로 취급하십시오.
logprob_threshold : float, default -1.0 평균 로그 확률 이이 값 미만인 경우 디코딩을 실패한 것으로 취급하십시오.
no_speech_threshold : float, default 0.6 확률 임계 <| nospeech |> 토큰.
condition_on_previous_text : bool, default true 다음 창에 대한 프롬프트로 이전 출력을 제공할지 여부.
initial_prompt : str, 선택 사항 (기본값 : 없음) 옵션 텍스트를 첫 번째 창에 대한 프롬프트로 제공합니다.
suppress_tokens : str, default "-1"샘플링 중에 억제 할 토큰 ID 목록.
fp16 : BOOL, 선택 사항 (기본값 : 없음) FP16 정밀도에서 추론을 수행할지 여부.
verbose : bool 또는 없음, 기본값 거짓 콘솔에 디코딩되는 텍스트를 표시할지 여부. 사실이라면 모든 세부 사항을 표시합니다. False 인 경우 최소한의 세부 사항을 표시합니다. 없다면 아무것도 표시하지 않습니다.
포함 된 사전 :
text : str- 전체 전사 텍스트segments : 목록 [dict] - 각각 포함 된 세그먼트 사전 목록 :id : int- 세그먼트 IDseek : int- 오디오 파일의 시작 위치 (샘플)start : 플로트 - 세그먼트의 시작 시간 (초)end : 플로트 - 세그먼트의 종료 시간 (초)text : str- 세그먼트의 전사 텍스트tokens : 목록 [int] - 세그먼트의 토큰 IDtemperature : 플로트 -이 세그먼트에 사용되는 온도avg_logprob : 플로트 - 세그먼트의 평균 로그 확률compression_ratio : 플로트 - 세그먼트의 압축 비율no_speech_prob : float- 세그먼트에서 음성이없는 확률confidence : 플로트 - 세그먼트의 신뢰 점수words : 목록 [dict] - 각각 포함 된 단어 사전 목록 :start : 플로트 - 단어의 시작 시간 (초)end : 플로트 - 단어의 종료 시간 (초)text : str- 단어 텍스트confidence : 플로트 - 단어에 대한 신뢰 점수 (계산 된 경우)language : str- 탐지 또는 지정된 언어language_probs : Dict- 언어 탐지 확률 (해당되는 경우) RuntimeError : VAD 메소드가 올바르게 설치되거나 구성되지 않은 경우.ValueError : refine_whisper_precision 이 0.02의 양의 배수가 아닌 경우.AssertionError : 오디오 지속 시간이 예상보다 짧거나 세그먼트 수에 불일치가있는 경우. naive_approach 매개 변수는 디버깅에 유용하거나 특정 오디오 특성을 처리 할 때 유용 할 수 있지만 기본 접근 방식보다 느릴 수 있습니다.use_efficient_by_default 가 true 일 때 best_of , beam_size 및 temperature_increment_on_fallback 과 같은 일부 매개 변수는보다 효율적인 처리를 위해 기본적으로 아무것도 설정하지 않습니다.remove_non_speech(audio, **kwargs)음성 활동 감지 (VAD)를 사용하여 오디오에서 비석 세그먼트를 제거하십시오.
audio : Torch.tensor 오디오 데이터는 Pytorch 텐서입니다.
use_sample : bool, default false true, true, segin and end and end and end and end and end and inde and a End Time은 초가 아닌 샘플에서 시작합니다.
min_speech_duration : float, 기본 0.1 연설 세그먼트의 최소 기간 동안 초.
min_silence_duration : float, 기본값 1 초 1 초의 최소 1 초 만에.
dilatation : 플로트, 기본 0.5 VAD가 감지 한 각 음성 세그먼트를 몇 초 만에 확대 할 금액.
sample_rate : int, 기본 16000 오디오의 샘플 속도.
method : str 또는 list [tuple [float, float]], 기본 "Silero"VAD 메서드를 사용할 수 있습니다. "Silero", "Auditok"또는 타임 스탬프 목록 일 수 있습니다.
avoid_empty_speech : bool, default false true 인 경우 빈 음성 세그먼트를 반환하지 마십시오.
plot : Union [bool, str], 기본적으로 false가 true 인 경우 VAD 결과를 플롯하십시오. 문자열이라면 플롯을 주어진 파일에 저장하십시오.
포함 된 튜플 :
ImportError : 필요한 VAD 라이브러리 (예 : Auditok)가 설치되지 않은 경우.ValueError : 잘못된 VAD 메소드가 지정된 경우. load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)주어진 이름이나 경로에서 속삭임 모델을로드하십시오.
name : 모델의 이름 또는 모델 경로. 될 수 있습니다 :
device : Union [Str, Torch.device], 선택 사항 (기본값 : 없음) 장치를 사용할 장치. 없는 경우 CUDA를 사용하십시오. 그렇지 않으면 CPU를 사용하십시오.
backend : STR, 기본 "OpenAi-Whisper"백엔드 사용. "변압기"또는 "Openai-Whisper".
download_root : str, 옵션 (기본값 : 없음) 루트 폴더로 모델을 다운로드하십시오. 없으면 기본 다운로드 루트를 사용하십시오.
in_memory : BOOL, 기본값 거짓 모델 가중치를 호스트 메모리에 전하할지 여부.
로드 된 속삭임 모델.
ValueError : 유효하지 않은 백엔드가 지정된 경우.ImportError : "Transformers"백엔드를 사용할 때 Transformers 라이브러리가 설치되지 않은 경우.RuntimeError : 지정된 소스에서 모델을 찾거나 다운로드 할 수없는 경우.OSError : 모델 파일을 읽거나 지정된 경로에 액세스하는 데 문제가있는 경우. get_alignment_heads(model, max_top_layer=3)주어진 모델의 정렬 헤드를 가져옵니다.
model : Whisper Model 인스턴스 정렬 헤드를 검색하는 속삭임 모델.
max_top_layer : int, 기본 3 정렬 헤드에 대해 고려해야 할 최대 3 개의 최상위 레이어 수입니다.
정렬 헤드를 나타내는 드문 텐서.
다음 기능은 다양한 파일 형식으로 전사를 작성할 수 있습니다.
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)전사 데이터를 CSV 파일에 작성하십시오.
transcript : 목록 [dict] 전사 세그먼트 사전 목록.
file : CSV 데이터를 작성하려면 파일과 같은 객체 파일.
sep : STR, DEFAULT ","CSV 파일에서 사용할 분리기.
text_first : bool, default true true 인 경우 true, 시작/종료 시간 전에 텍스트 열을 씁니다.
format_timestamps : 호출 가능, 선택 사항 (기본값 : 없음) 함수 timestamp 값을 형식화합니다.
header : Union [bool, list [str]], default false, true 인 경우 기본 헤더를 쓰십시오. 목록 인 경우 사용자 정의 헤더로 사용하십시오.
IOError : 지정된 파일에 쓰는 문제가있는 경우.ValueError : 전사 데이터가 예상 형식이 아닌 경우. format_timestamps 매개 변수는 타임 스탬프 값의 사용자 정의 서식을 허용하며, 이는 특정 사용 사례 또는 데이터 분석 요구 사항에 도움이 될 수 있습니다. write_srt(transcript, file)SRT (Subrip 자막) 파일에 전사 데이터를 작성하십시오.
transcript : 목록 [dict] 전사 세그먼트 사전 목록.
file : SRT 데이터를 작성하려면 파일과 같은 개체 파일.
IOError : 지정된 파일에 쓰는 문제가있는 경우.ValueError : 전사 데이터가 예상 형식이 아닌 경우. write_vtt(transcript, file)전사 데이터를 VTT (webvtt) 파일에 작성하십시오.
transcript : 목록 [dict] 전사 세그먼트 사전 목록.
file : VTT 데이터를 작성하려면 파일과 같은 개체 파일.
IOError : 지정된 파일에 쓰는 문제가있는 경우.ValueError : 전사 데이터가 예상 형식이 아닌 경우. write_tsv(transcript, file)전사 데이터를 TSV (Tab-Separated values) 파일로 씁니다.
transcript : 목록 [dict] 전사 세그먼트 사전 목록.
file : 파일과 같은 객체 파일로 TSV 데이터를 작성합니다.
IOError : 지정된 파일에 쓰는 문제가있는 경우.ValueError : 전사 데이터가 예상 형식이 아닌 경우. 다음은 기본적으로 활성화되지 않았지만 결과를 향상시킬 수있는 몇 가지 옵션입니다.
앞에서 언급했듯이 일부 디코딩 옵션은 기본적으로 더 나은 효율성을 제공하기 위해 비활성화됩니다. 그러나 이것은 전사의 품질에 영향을 줄 수 있습니다. 좋은 전사를 제공 할 수있는 가장 좋은 옵션을 사용하려면 다음 옵션을 사용하십시오.
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ... 속삭임 모델은 말이없는 세그먼트가 주어지면 텍스트를 "환각"할 수 있습니다. 이것은 Whisper 모델로 전사하기 전에 VAD를 실행하고 음성 세그먼트를 결합하여 피할 수 있습니다. 이것은 whisper-timestamped 에서 가능합니다.
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...기본적으로 사용 된 VAD 방법은 Silero입니다. 그러나 이전 버전의 Silero 또는 Auditok과 같은 다른 방법을 사용할 수 있습니다. 이러한 방법은 Silero Vad의 최신 버전이 일부 오디오에서 많은 잘못된 경보를 가질 수 있기 때문에 도입되었습니다 (침묵에서 감지 된 음성).
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... VAD 결과를 보려면 whisper_timestamped cli의 --plot 옵션 또는 whisper_timestamped.transcribe() python function의 plot_word_alignment 옵션을 사용할 수 있습니다. 다음 (x 축소 시간은 초)로 입력 오디오 신호의 VAD 결과를 보여줍니다.
| vad = "Silero : v4.0" | vad = "실로 : v3.1" | vad = "Auditok" |
|---|---|---|
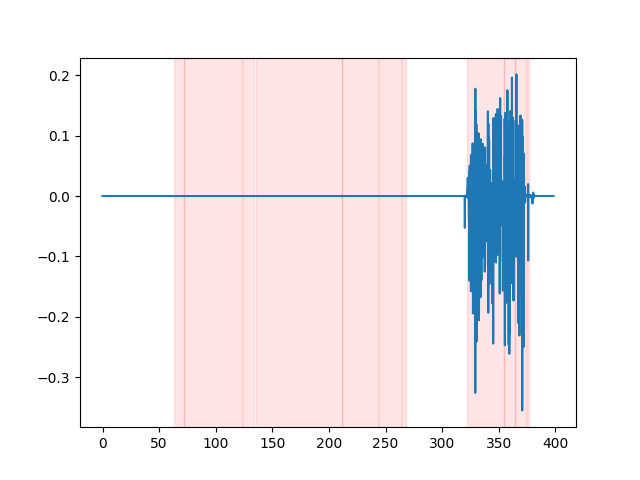 | 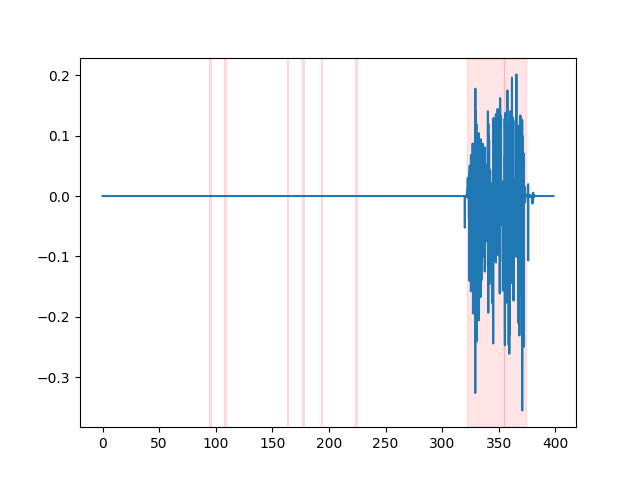 | 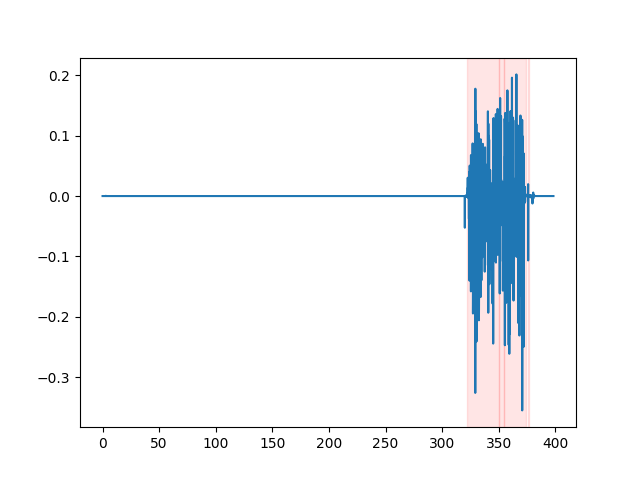 |
속삭임 모델은 음성 불일치 (필러 단어, 망설임, 반복 등)를 제거하는 경향이 있습니다. 예방 조치가 없으면 전사되지 않은 불만은 다음 단어의 타임 스탬프에 영향을 미칩니다. 단어의 시작의 타임 스탬프는 실제로 불만의 시작의 타임 스탬프가됩니다. whisper-timestamped 이를 피하기 위해 휴리스틱을 가질 수 있습니다.
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ... 중요 : 이러한 옵션을 사용할 때는 전사에 불만이 특별한 " [*] "단어로 나타납니다.
연구에서 이것을 사용하는 경우 리포트를 인용하십시오.
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}Openai Whisper Paper :
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}그리고 동적 시간 경고를위한이 논문 :
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

