whisper timestamped
v1.15.8
Reconnaissance de la parole automatique multilingue avec horodatage et confiance au niveau des mots.
Whisper est un ensemble de modèles de reconnaissance de la parole multilingues et robustes formés par OpenAI qui atteignent des résultats de pointe dans de nombreuses langues. Les modèles Whisper ont été formés pour prédire les horodatages approximatifs sur les segments de la parole (la plupart du temps avec une précision d'une seconde), mais ils ne peuvent pas prédire à l'origine des horodatages des mots. Ce référentiel propose une implémentation pour prédire les horodatages des mots et fournir une estimation plus précise des segments de la parole lors de la transcription avec des modèles Whisper . En outre, un score de confiance est attribué à chaque mot et à chaque segment.
L'approche est basée sur la déformation temporelle dynamique (DTW) appliquée aux poids de l'attention croisée, comme l'ont démontré ce cahier de Jong Wook Kim. Il y a quelques ajouts à ce cahier:
whisper-timestamped est capable de traiter les fichiers longs avec peu de mémoire supplémentaire par rapport à l'utilisation régulière du modèle Whisper. whisper-timestamped est une extension du package openai-whisper Python et est censé être compatible avec n'importe quelle version d' openai-whisper . Il fournit des horodatages de mots plus efficaces / précis, ainsi que ces fonctionnalités supplémentaires:
Avertissement: veuillez noter que cette extension est destinée à des fins expérimentales et peut avoir un impact significatif sur les performances. Nous ne sommes pas responsables des problèmes ou des inefficacités qui découlent de son utilisation.
Une approche pertinente alternative pour récupérer les horodatages au niveau des mots consiste à utiliser des modèles WAV2VEC qui prédisent les caractères, comme mis en œuvre avec succès dans WhisperX. Cependant, ces approches présentent plusieurs inconvénients qui ne sont pas présents dans les approches basées sur des poids de transtention croisée tels que whisper_timestamped . Ces inconvénients incluent:
Une autre approche qui ne nécessite pas de modèle supplémentaire consiste à examiner les probabilités de jetons horodatotes estimées par le modèle Whisper après que chaque (sous) jeton de mot est prévu. Ceci a été implémenté, par exemple, dans Whisper.cpp et stable-ts. Cependant, cette approche manque de robustesse car les modèles Whisper n'ont pas été formés pour produire des horodatages significatifs après chaque mot. Les modèles Whisper ont tendance à prédire les horodatages qu'après un certain nombre de mots ont été prédits (généralement à la fin d'une phrase), et la distribution de probabilité des horodatages en dehors de cette condition peut être inexacte. Dans la pratique, ces méthodes peuvent produire des résultats totalement synchronisés sur certaines périodes (nous l'avons observé surtout quand il y a de la musique jingle). De plus, la précision horodato des modèles Whisper a tendance à être arrondie à 1 seconde (comme dans de nombreux sous-titres vidéo), ce qui est trop inexact pour les mots, et atteindre une meilleure précision est délicat.
Exigences:
python3 (version supérieure ou égale à 3,7, au moins 3,9 est recommandée)ffmpeg (Voir les instructions pour l'installation sur le référentiel Whisper) Vous pouvez installer whisper-timestamped
pip3 install whisper-timestampedou en clonage ce référentiel et en cours d'installation:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py installSi vous souhaitez tracer l'alignement entre les horodatages audio et les mots (comme dans cette section), vous avez également besoin de matplotlib:
pip3 install matplotlibSi vous souhaitez utiliser l'option VAD (détection d'activité vocale avant d'exécuter un modèle Whisper), vous avez également besoin de torchaudio et d'onnxruntime:
pip3 install onnxruntime torchaudioSi vous souhaitez utiliser des modèles Whisper Finetuned à partir du centre de face étreint, vous avez également besoin de transformateurs:
pip3 install transformersUne image Docker d'environ 9 Go peut être construite en utilisant:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .Si vous n'avez pas de GPU (ou que vous ne voulez pas l'utiliser), vous n'avez pas besoin d'installer les dépendances CUDA. Vous devez ensuite simplement installer une version légère de Torch avant d'installer des chuchotements, par exemple, comme suit:
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.htmlUne image docker spécifique d'environ 3,5 Go peut également être construite en utilisant:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .Lorsque vous utilisez PIP, la bibliothèque peut être mise à jour vers la dernière version en utilisant:
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
Une version spécifique d' openai-whisper peut être utilisée en fonctionnant, par exemple:
pip3 install openai-whisper==20230124 Dans Python, vous pouvez utiliser la fonction whisper_timestamped.transcribe() , qui est similaire à la fonction whisper.transcribe() :
import whisper_timestamped
help ( whisper_timestamped . transcribe ) La principale différence avec whisper.transcribe() est que la sortie inclura une clé "words" pour tous les segments, avec le mot de départ et de position finale. Notez que le mot inclura la ponctuation. Voir l'exemple ci-dessous.
En outre, les options de décodage par défaut sont différentes pour favoriser le décodage efficace (décodage gourmand au lieu de la recherche de faisceau, et pas de repli d'échantillonnage de température). Pour avoir la même valeur par défaut que dans whisper , utilisez beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0) .
Il existe également des options supplémentaires liées à l'alignement des mots.
En général, si vous importez whisper_timestamped au lieu de whisper dans votre script Python et utilisez transcribe(model, ...) au lieu de model.transcribe(...) , il devrait faire le travail:
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) Notez que vous pouvez utiliser un modèle Whisper Finetuned à partir de HuggingFace ou un dossier local en utilisant la méthode load_model de whisper_timestamped . Par exemple, si vous souhaitez utiliser Whisper-Large-V2-NOB, vous pouvez simplement effectuer ce qui suit:
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ... Vous pouvez également utiliser whisper_timestamped sur la ligne de commande, similaire à whisper . Voir l'aide avec:
whisper_timestamped --help Les principales différences avec whisper CLI sont:
--output_dir . pour chuchoter par défaut.--verbose True for whisper par défaut.--accurate (qui est un alias pour --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 ).--compute_confidence pour activer / désactiver le calcul des scores de confiance pour chaque mot.--punctuations_with_words pour décider si les marques de ponctuation doivent être incluses ou non avec des mots précédents. Un exemple de commande pour traiter plusieurs fichiers à l'aide du modèle tiny et publier les résultats dans le dossier actuel, comme cela serait fait par défaut avec Whisper, est le suivant:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Notez que vous pouvez utiliser un modèle de chuchotement affiné de HuggingFace ou d'un dossier local. Par exemple, si vous souhaitez utiliser le modèle Whisper-Large-V2-NOB, vous pouvez simplement effectuer ce qui suit:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
En plus de la fonction transcribe principale, Whisper-Timestamped fournit certaines fonctions d'utilité:
remove_non_speechRetirez les segments de non-parole de l'audio à l'aide de la détection d'activité vocale (VAD).
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelChargez un modèle Whisper à partir d'un nom ou d'un chemin donné, y compris la prise en charge des modèles affinés de HuggingFace.
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" ) Notez que vous pouvez utiliser l'option plot_word_alignment de la fonction python whisper_timestamped.transcribe() ou l'option --plot de la CLI whisper_timestamped pour voir l'alignement du mot pour chaque segment.
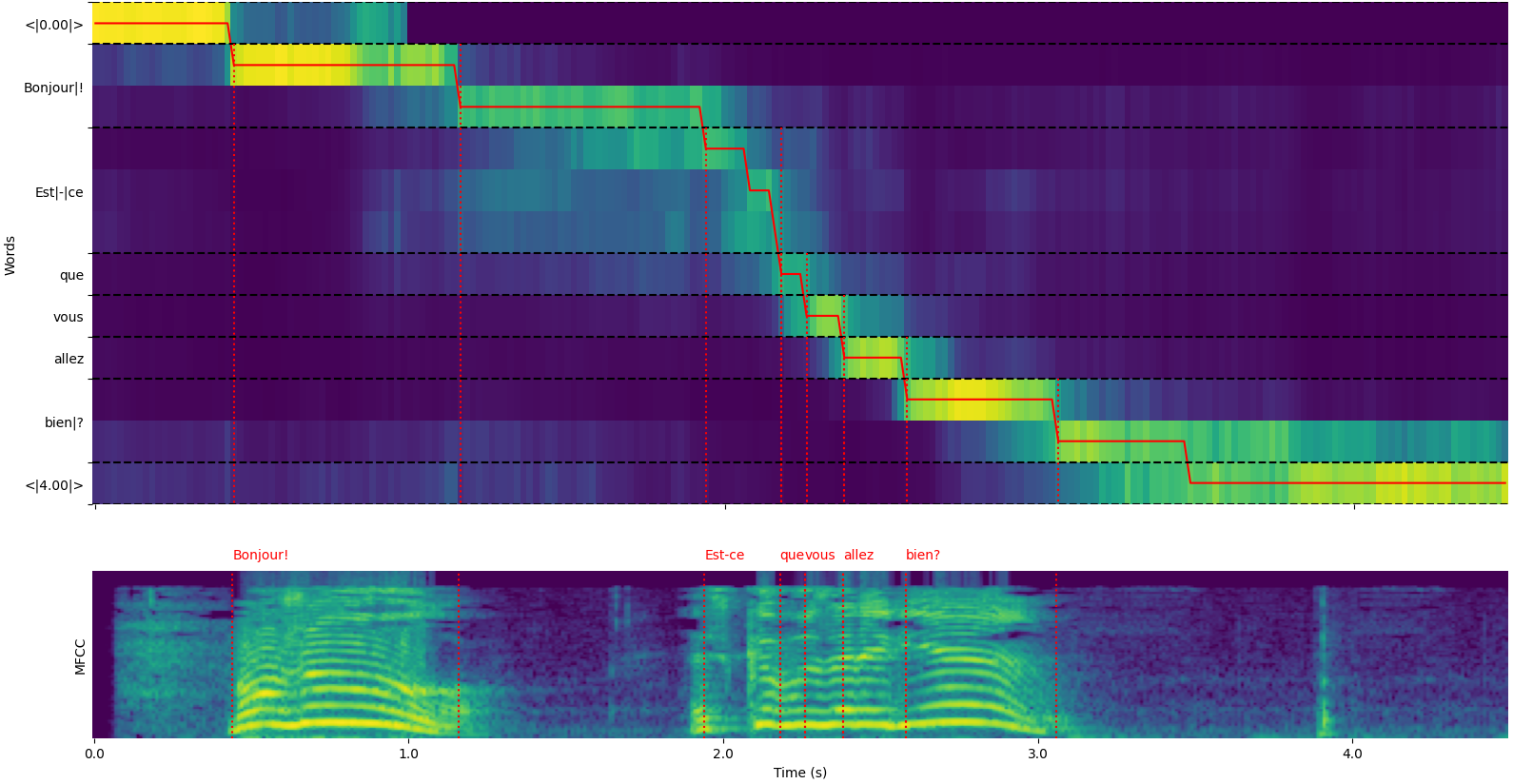
La sortie de la fonction whisper_timestamped.transcribe() est un dictionnaire Python, qui peut être visualisé au format JSON à l'aide de la CLI.
Le schéma JSON peut être vu dans Tests / JSON_SChema.json.
Voici un exemple de sortie:
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
} Si la langue n'est pas spécifiée (par exemple sans option --language fr dans la CLI), vous trouverez une clé supplémentaire avec les probabilités de langue:
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)Transcrire l'audio à l'aide d'un modèle Whisper et calculer les horodatages de niveau mot.
model : Whisper Model Instance Le modèle Whisper à utiliser pour la transcription.
audio : Union [Str, NP.NDARRAY, TORCH.tensor] Le chemin du fichier audio à transcrire, ou la forme d'onde audio en tant que réseau numpy ou tensor pytorch.
language : Str, Facultatif (par défaut: aucun) La langue de l'audio. Si aucun, la détection de la langue sera effectuée.
task : STR, par défaut "Transcrire" la tâche à effectuer: soit "transcrire" pour la reconnaissance vocale ou "traduire" pour la traduction en anglais.
vad : Union [bool, str, list [tuple [float, float]]], facultatif (par défaut: false), s'il faut utiliser la détection d'activité vocale (VAD) pour supprimer les segments de non-discours. Peut être:
detect_disfluencies : bool, par défaut faux, s'il faut détecter et marquer les disfluences (hésitations, mots de remplissage, etc.) dans la transcription.
trust_whisper_timestamps : Bool, par défaut True, s'il faut s'appuyer sur les horlogers de Whisper pour les positions de segment initiales.
compute_word_confidence : bool, par défaut True s'il faut calculer les scores de confiance pour les mots.
include_punctuation_in_confidence : bool, par défaut faux, s'il faut inclure la probabilité de ponctuation lors du calcul de la confiance des mots.
refine_whisper_precision : float, par défaut 0,5 combien affiner les positions du segment des chuchotements, en quelques secondes. Doit être un multiple de 0,02.
min_word_duration : Float, par défaut 0,02 Durée minimale d'un mot, en secondes.
plot_word_alignment : bool ou str, par défaut faux, s'il faut tracer l'alignement du mot pour chaque segment. Si une chaîne, enregistrez le tracé dans le fichier donné.
word_alignement_most_top_layers : int, facultatif (par défaut: aucun) nombre de couches supérieures à utiliser pour l'alignement des mots. Si aucun, utilisez toutes les couches.
remove_empty_words : bool, par défaut faux, s'il faut supprimer des mots sans durée à la fin des segments.
naive_approach : bool, par défaut False Force L'approche naïve du décodage deux fois (une fois pour la transcription, une fois pour l'alignement).
use_backend_timestamps : bool, par défaut faux, qu'il s'agisse d'utiliser des horodatages de mots fournis par le backend (openai-whisper ou transformateurs), au lieu de ceux calculés par une heuristique plus complexe de chuchotements-timestampé.
temperature : Union [Float, List [Float]], par défaut 0,0 Température pour l'échantillonnage. Peut être une valeur unique ou une liste pour les températures de secours.
compression_ratio_threshold : float, par défaut 2.4 Si le rapport de compression GZIP est supérieur à cette valeur, traitez le décodage comme échoué.
logprob_threshold : float, par défaut -1,0 Si la probabilité du journal moyen est inférieure à cette valeur, traitez le décodage comme échoué.
no_speech_threshold : Float, par défaut 0,6 Seuil de probabilité pour <| Nospeech |> Tokens.
condition_on_previous_text : bool, par défaut vrai si vous devez fournir la sortie précédente comme invite pour la fenêtre suivante.
initial_prompt : STR, Facultatif (par défaut: aucun) Texte facultatif à fournir comme invite pour la première fenêtre.
suppress_tokens : STR, par défaut "-1" Liste des ID de jeton séparée par les virgules à supprimer lors de l'échantillonnage.
fp16 : bool, facultatif (par défaut: aucun) s'il faut effectuer l'inférence dans la précision FP16.
verbose : bool ou aucun, par défaut faux, s'il faut afficher le texte décodé sur la console. Si vrai, affiche tous les détails. Si faux, affiche des détails minimaux. Si aucun, il n'affiche rien.
Un dictionnaire contenant:
text : Str - Le texte de transcription completsegments : Liste [dict] - Liste des dictionnaires de segment, chacun contenant:id segmentseek : INT - Position de démarrage dans le fichier audio (dans des échantillons)start : Float - Heure de début du segment (en secondes)end : Float - Temps de fin du segment (en secondes)text : STR - Texte transcrit pour le segmenttokens : Liste [int] - ID de jeton pour le segmenttemperature : flotteur - température utilisée pour ce segmentavg_logprob : Float - PROBABILITÉ DU LOG moyen du segmentcompression_ratio : Float - Ratio de compression du segmentno_speech_prob : float - probabilité d'aucun discours dans le segmentconfidence : flotteur - score de confiance pour le segmentwords : Liste [Dict] - Liste des dictionnaires de mots, chacun contenant:start : Float - Heure de début du mot (en quelques secondes)end : Float - Temps de fin du mot (en secondes)text : Str - Le mot texteconfidence : Float - Score de confiance pour le mot (s'il est calculé)language : STR - Langue détectée ou spécifiéelanguage_probs : Dict - Probabilités de détection du langage (le cas échéant) RuntimeError : si la méthode VAD n'est pas correctement installée ou configurée.ValueError : si le refine_whisper_precision n'est pas un multiple positif de 0,02.AssertionError : Si la durée de l'audio est plus courte que prévu ou s'il y a des incohérences dans le nombre de segments. naive_approach peut être utile pour le débogage ou lorsqu'il s'agit de caractéristiques audio spécifiques, mais elle peut être plus lente que l'approche par défaut.use_efficient_by_default est vrai, certains paramètres comme best_of , beam_size et temperature_increment_on_fallback sont définis sur aucun par défaut pour un traitement plus efficace.remove_non_speech(audio, **kwargs)Retirez les segments de non-parole de l'audio à l'aide de la détection d'activité vocale (VAD).
audio : Torch.tensor Data audio en tant que tenseur de pytorch.
use_sample : bool, par défaut false if true, return start et fin les temps dans des échantillons au lieu de secondes.
min_speech_duration : float, par défaut 0,1 Durée minimale d'un segment de la parole en secondes.
min_silence_duration : Float, par défaut 1 durée minimale d'un segment de silence en secondes.
dilatation : flotteur, par défaut 0,5 combien agrandir chaque segment de parole détecté par VAD, en secondes.
sample_rate : INT, Taux d'échantillonnage par défaut 16000 de l'audio.
method : str ou list [tuple [float, float]], méthode VAD par défaut "SILERO" à utiliser. Peut être "SILERO", "Auditok" ou une liste d'horodatage.
avoid_empty_speech : bool, par défaut faux si vrai, évitez de renvoyer un segment de parole vide.
plot : Union [Bool, Str], par défaut Faux Si vrai, tracez les résultats VAD. Si une chaîne, enregistrez le tracé dans le fichier donné.
Un tuple contenant:
ImportError : Si la bibliothèque VAD requise (par exemple, Auditok) n'est pas installée.ValueError : si une méthode VAD non valide est spécifiée. load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)Chargez un modèle de chuchotement à partir d'un nom ou d'un chemin donné.
name : Str Nom du modèle ou chemin vers le modèle. Peut être:
device : Union [Str, Torch.Device], Dispositif facultatif (par défaut: aucun) à utiliser. Si aucun, utilisez CUDA si disponible, sinon CPU.
backend : STR, backend par défaut "Openai-Whisper" à utiliser. Soit "Transformers" ou "Openai-Whisper".
download_root : STR, Fostère facultatif (par défaut: aucun) pour télécharger le modèle. Si aucun, utilisez la racine de téléchargement par défaut.
in_memory : BOOL, FAUX par défaut pour précharger les poids du modèle dans la mémoire de l'hôte.
Le modèle chuchoté chargé.
ValueError : si un backend non valide est spécifié.ImportError : si la bibliothèque Transformers n'est pas installée lors de l'utilisation du backend "Transformers".RuntimeError : si le modèle ne peut être trouvé ou téléchargé à partir de la source spécifiée.OSError : S'il y a des problèmes lisant le fichier du modèle ou accédant au chemin spécifié. get_alignment_heads(model, max_top_layer=3)Obtenez les têtes d'alignement pour le modèle donné.
model : Whisper Model Instance Le modèle Whisper pour lequel récupérer les têtes d'alignement.
max_top_layer : int, par défaut 3 Nombre maximum de couches supérieures à considérer pour les têtes d'alignement.
Un tenseur clairsemé représentant les têtes d'alignement.
Les fonctions suivantes sont disponibles pour écrire des transcriptions dans divers formats de fichiers:
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)Écrivez des données de transcription dans un fichier CSV.
transcript : liste [dict] Liste des dictionnaires de segment de transcription.
file : fichier d'objet de type fichier pour écrire les données CSV.
sep : Str, par défaut "," séparateur à utiliser dans le fichier CSV.
text_first : bool, par défaut True If True, écrivez la colonne de texte avant le démarrage / les heures de fin.
format_timestamps : Fonction appelée, facultative (par défaut: aucun) pour formater les valeurs d'horodatage.
header : Union [bool, list [Str]], par défaut Faux Si vrai, écrivez l'en-tête par défaut. Si une liste, utilisez comme en-tête personnalisé.
IOError : s'il y a des problèmes qui écrivent dans le fichier spécifié.ValueError : si les données de transcription ne sont pas dans le format attendu. format_timestamps permet la mise en forme personnalisée des valeurs d'horodatage, qui peuvent être utiles pour des cas d'utilisation spécifiques ou des exigences d'analyse des données. write_srt(transcript, file)Écrivez des données de transcription dans un fichier SRT (Subrip Subtitle).
transcript : liste [dict] Liste des dictionnaires de segment de transcription.
file : fichier d'objet de type fichier pour écrire les données SRT.
IOError : s'il y a des problèmes qui écrivent dans le fichier spécifié.ValueError : si les données de transcription ne sont pas dans le format attendu. write_vtt(transcript, file)Écrivez des données de transcription dans un fichier VTT (WebVTT).
transcript : liste [dict] Liste des dictionnaires de segment de transcription.
file : fichier d'objet de type fichier pour écrire les données VTT.
IOError : s'il y a des problèmes qui écrivent dans le fichier spécifié.ValueError : si les données de transcription ne sont pas dans le format attendu. write_tsv(transcript, file)Écrivez des données de transcription dans un fichier TSV (valeurs séparées par TAB).
transcript : liste [dict] Liste des dictionnaires de segment de transcription.
file : fichier d'objet de type fichier pour écrire les données TSV.
IOError : s'il y a des problèmes qui écrivent dans le fichier spécifié.ValueError : si les données de transcription ne sont pas dans le format attendu. Voici quelques options qui ne sont pas activées par défaut mais qui peuvent améliorer les résultats.
Comme mentionné précédemment, certaines options de décodage sont désactivées par défaut pour offrir une meilleure efficacité. Cependant, cela peut avoir un impact sur la qualité de la transcription. Pour fonctionner avec les options qui ont les meilleures chances de fournir une bonne transcription, utilisez les options suivantes.
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ... Les modèles de chuchotement peuvent «halluciner» du texte lorsqu'ils ont donné un segment sans discours. Cela peut être évité en exécutant des segments de parole VAD et en collant ensemble avant de transcrire avec le modèle Whisper. Ceci est possible avec whisper-timestamped .
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...Par défaut, la méthode VAD utilisée est SILERE. Mais d'autres méthodes sont disponibles, telles que des versions antérieures de SILERO ou Auditok. Ces méthodes ont été introduites car les dernières versions de SILERO VAD peuvent avoir beaucoup de fausses alarmes sur certains audios (discours détecté sur le silence).
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... Afin de regarder les résultats VAD, vous pouvez utiliser l'option --plot de la CLI whisper_timestamped , ou l'option plot_word_alignment de la fonction python whisper_timestamped.transcribe() . Il affichera les résultats VAD sur le signal audio d'entrée comme suivant (l'axe x est temps en secondes):
| VAD = "SILERO: V4.0" | VAD = "SILERO: V3.1" | vad = "Auditok" |
|---|---|---|
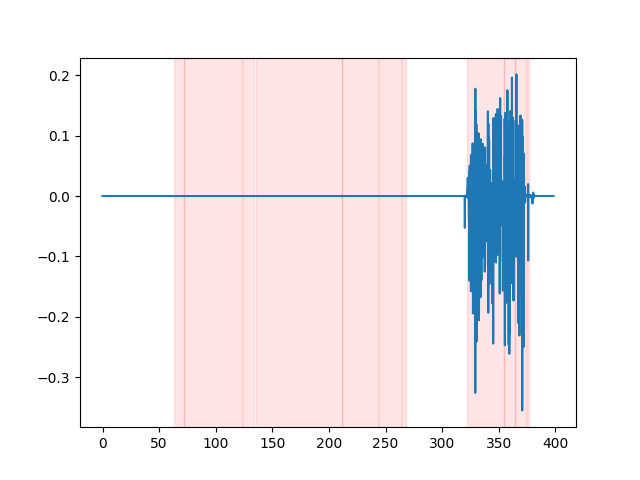 | 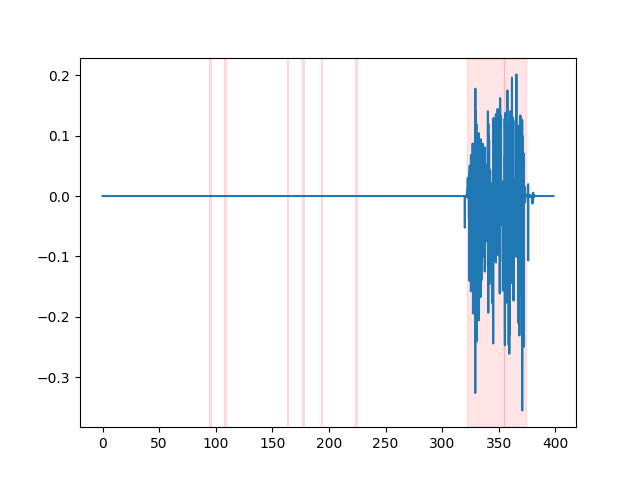 | 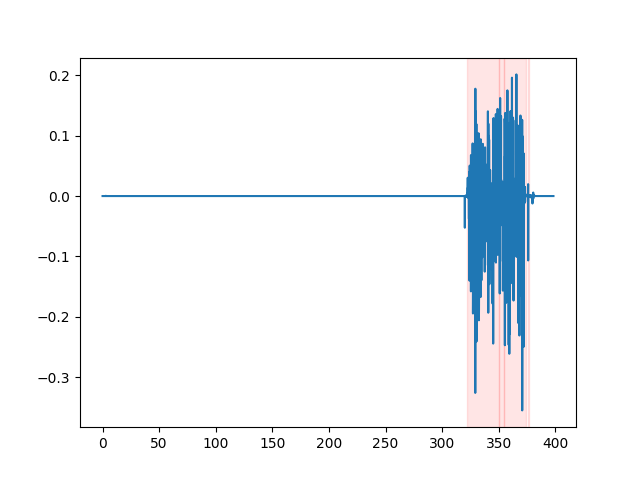 |
Les modèles Whisper ont tendance à supprimer les disfluences de la parole (mots de remplissage, hésitations, répétitions, etc.). Sans précautions, les disfluences qui ne sont pas transcrites affecteront l'horodatage du mot suivant: L'horodatage du début du mot sera en fait l'horodatage du début des disfluences. whisper-timestamped peut avoir une certaine heuristique pour éviter cela.
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ... IMPORTANT: Notez que lors de l'utilisation de ces options, les disfluences possibles apparaîtront dans la transcription comme un mot " [*] " spécial.
Si vous l'utilisez dans vos recherches, veuillez citer le dépôt:
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}Ainsi que le papier chuchoté Openai:
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}Et ce document pour la barrage dynamique:
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

