whisper timestamped
v1.15.8
Reconhecimento automático multilíngue de fala com registro de data e hora no nível da palavra e confiança.
Whisper é um conjunto de modelos de reconhecimento de fala multilíngues e robustos treinados pelo OpenAI que alcançam resultados de ponta em vários idiomas. Os modelos de sussurros foram treinados para prever o registro de data e hora aproximados nos segmentos de fala (na maioria das vezes com precisão de 1 segundo), mas eles não podem originalmente prever o registro de data e hora das palavras. Este repositório propõe uma implementação para prever registros de data e hora de palavras e fornecer uma estimativa mais precisa dos segmentos de fala ao transcrever com modelos de sussurros . Além disso, uma pontuação de confiança é atribuída a cada palavra e a cada segmento.
A abordagem é baseada em distorção dinâmica de tempo (DTW) aplicada aos pesos de atendimento cruzado, como demonstrado por este notebook por Jong Wook Kim. Existem algumas adições a este caderno:
whisper-timestamped é capaz de processar arquivos longos com pouca memória adicional em comparação com o uso regular do modelo Whisper. whisper-timestamped é uma extensão do pacote Python openai-whisper e deve ser compatível com qualquer versão do openai-whisper . Ele fornece registros de data e hora mais eficientes/precisos, juntamente com esses recursos adicionais:
Isenção de responsabilidade: Observe que esta extensão é destinada a fins experimentais e pode afetar significativamente o desempenho. Não somos responsáveis por quaisquer problemas ou ineficiências que surgem de seu uso.
Uma abordagem alternativa relevante para a recuperação de registros de data e hora no nível da palavra envolve o uso de modelos WAV2VEC que prevêem caracteres, conforme implementado com sucesso no Whisperx. No entanto, essas abordagens têm várias desvantagens que não estão presentes em abordagens com base em pesos de atendimento cruzado, como whisper_timestamped . Essas desvantagens incluem:
Uma abordagem alternativa que não requer um modelo adicional é observar as probabilidades dos tokens de registro de data e hora estimados pelo modelo de sussurro após o previsão de cada (sub) token da palavra. Isso foi implementado, por exemplo, no sussurro.cpp e no Stable-Ts. No entanto, essa abordagem carece de robustez porque os modelos de sussurros não foram treinados para produzir registros de data e hora significativos após cada palavra. Os modelos de sussurros tendem a prever registros de data e hora somente depois que um certo número de palavras foram previstas (normalmente no final de uma frase), e a distribuição de probabilidade de registros de data e hora fora dessa condição pode ser imprecisa. Na prática, esses métodos podem produzir resultados totalmente fora de sincronização em alguns períodos de tempo (observamos isso especialmente quando há música jingle). Além disso, a precisão do timestamp dos modelos de sussurros tende a ser arredondada para 1 segundo (como em muitas legendas de vídeo), o que é impreciso demais para as palavras, e atingir melhor precisão é complicado.
Requisitos:
python3 (versão superior ou igual a 3,7, pelo menos 3,9 é recomendado)ffmpeg (consulte Instruções para instalação no repositório Whisper) Você pode instalar whisper-timestamped usando o PIP:
pip3 install whisper-timestampedou clonando este repositório e executando a instalação:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py installSe você deseja plotar o alinhamento entre os registros de data e hora de áudio e as palavras (como nesta seção), também precisa de matplotlib:
pip3 install matplotlibSe você deseja usar a opção VAD (detecção de atividades de voz antes de executar o modelo Whisper), também precisa de Torchaudio e OnnxRuntime:
pip3 install onnxruntime torchaudioSe você deseja usar modelos Whisper Finetuned do Hubging Face Hub, também precisa de transformadores:
pip3 install transformersUma imagem do Docker de cerca de 9 GB pode ser construída usando:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .Se você não possui uma GPU (ou não deseja usá -lo), não precisa instalar as dependências do CUDA. Você deve apenas instalar uma versão leve da tocha antes de instalar o Whisper-Timestamped, por exemplo, como segue:
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.htmlUma imagem específica do Docker de cerca de 3,5 GB também pode ser construída usando:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .Ao usar o PIP, a biblioteca pode ser atualizada para a versão mais recente usando:
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
Uma versão específica do openai-whisper pode ser usada em execução, por exemplo:
pip3 install openai-whisper==20230124 No Python, você pode usar a função whisper_timestamped.transcribe() , que é semelhante à função whisper.transcribe() :
import whisper_timestamped
help ( whisper_timestamped . transcribe ) A principal diferença com whisper.transcribe() é que a saída incluirá uma chave "words" para todos os segmentos, com a palavra inicial e posição final. Observe que a palavra incluirá pontuação. Veja o exemplo abaixo.
Além disso, as opções de decodificação padrão são diferentes para favorecer a decodificação eficiente (decodificação gananciosa em vez de pesquisa de feixe, e sem fallback de amostragem de temperatura). Para ter o mesmo padrão do whisper , use beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0) .
Também existem opções adicionais relacionadas ao alinhamento de palavras.
Em geral, se você importar whisper_timestamped em vez de whisper em seu script python e usar transcribe(model, ...) em vez de model.transcribe(...) , ele deve fazer o trabalho:
import whisper_timestamped as whisper
audio = whisper . load_audio ( "AUDIO.wav" )
model = whisper . load_model ( "tiny" , device = "cpu" )
result = whisper . transcribe ( model , audio , language = "fr" )
import json
print ( json . dumps ( result , indent = 2 , ensure_ascii = False )) Observe que você pode usar um modelo Whisper FinetUned da HuggingFace ou de uma pasta local usando o método load_model de whisper_timestamped . Por exemplo, se você quiser usar o Whisper-Large-V2-NOB, pode simplesmente fazer o seguinte:
import whisper_timestamped as whisper
model = whisper . load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" )
# ... Você também pode usar whisper_timestamped na linha de comando, da mesma forma que o whisper . Veja a ajuda com:
whisper_timestamped --help As principais diferenças com a CLI whisper são:
--output_dir . para sussurrar o padrão.--verbose True para o sussurro padrão.--accurate (que é um alias para --beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5 ).--compute_confidence para ativar/desativar o cálculo das pontuações de confiança para cada palavra.--punctuations_with_words para decidir se as marcas de pontuação devem ser incluídas ou não com palavras anteriores. Um comando de exemplo para processar vários arquivos usando o modelo tiny e produzir os resultados na pasta atual, como seria feito por padrão com o Whisper, é o seguinte:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Observe que você pode usar um modelo de sussurro ajustado no Huggingface ou uma pasta local. Por exemplo, se você deseja usar o modelo Whisper-Large-V2-NOB, basta fazer o seguinte:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
Além da principal função transcribe , o Whisper-Timestamped fornece algumas funções de utilidade:
remove_non_speechRemova os segmentos não de fala do áudio usando a detecção de atividades de voz (VAD).
from whisper_timestamped import remove_non_speech
audio_speech , segments , convert_timestamps = remove_non_speech ( audio , vad = "silero" )load_modelCarregue um modelo de sussurro de um determinado nome ou caminho, incluindo suporte para modelos ajustados do HuggingFace.
from whisper_timestamped import load_model
model = load_model ( "NbAiLab/whisper-large-v2-nob" , device = "cpu" ) Observe que você pode usar a opção plot_word_alignment da função python whisper_timestamped.transcribe() ou a opção --plot da CLI whisper_timestamped para ver o alinhamento da palavra para cada segmento.
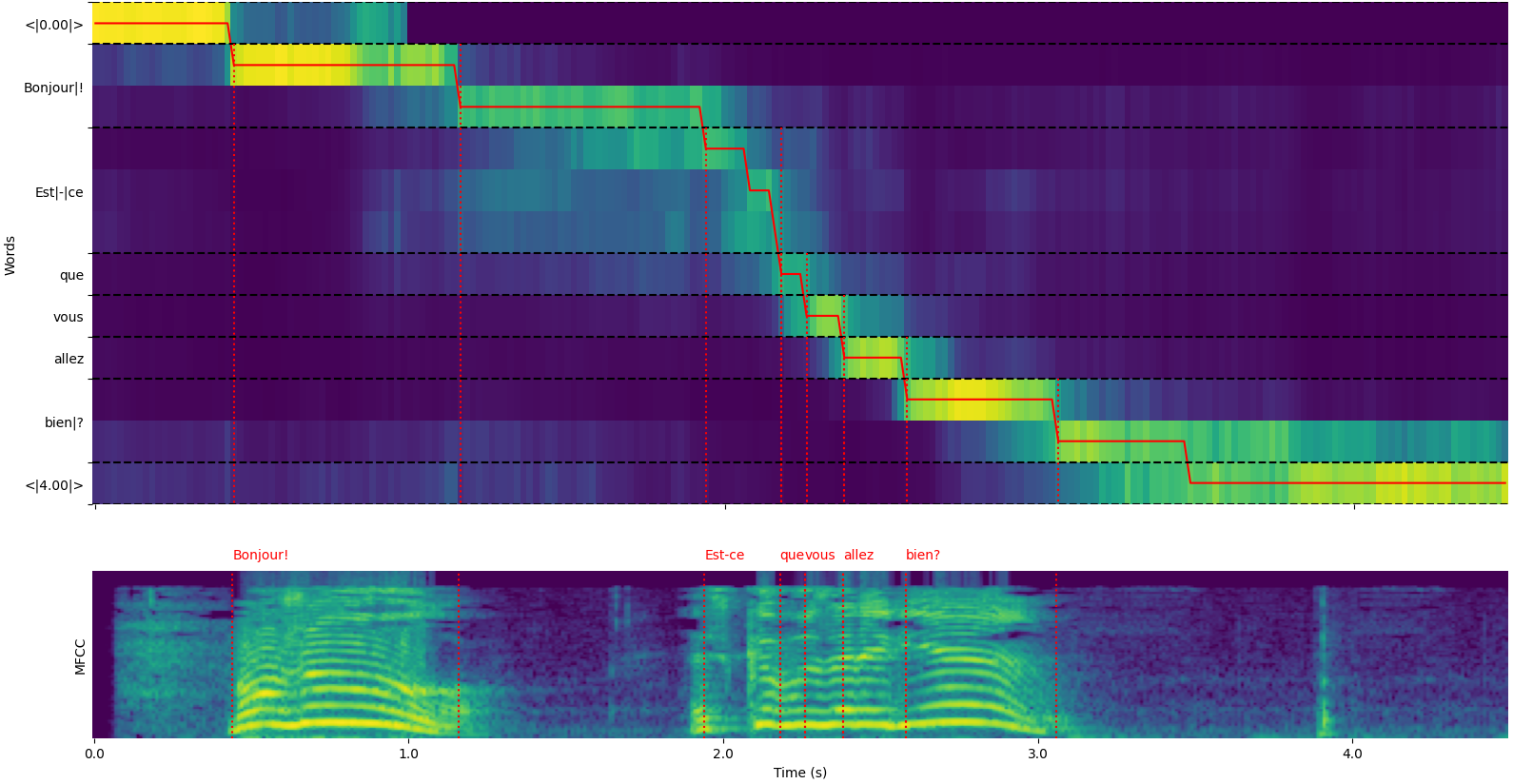
A saída da função whisper_timestamped.transcribe() é um dicionário Python, que pode ser visualizado no formato JSON usando a CLI.
O esquema JSON pode ser visto em testes/json_schema.json.
Aqui está um exemplo de saída:
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr{
"text" : " Bonjour! Est-ce que vous allez bien? " ,
"segments" : [
{
"id" : 0 ,
"seek" : 0 ,
"start" : 0.5 ,
"end" : 1.2 ,
"text" : " Bonjour! " ,
"tokens" : [ 25431 , 2298 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.6674491882324218 ,
"compression_ratio" : 0.8181818181818182 ,
"no_speech_prob" : 0.10241222381591797 ,
"confidence" : 0.51 ,
"words" : [
{
"text" : " Bonjour! " ,
"start" : 0.5 ,
"end" : 1.2 ,
"confidence" : 0.51
}
]
},
{
"id" : 1 ,
"seek" : 200 ,
"start" : 2.02 ,
"end" : 4.48 ,
"text" : " Est-ce que vous allez bien? " ,
"tokens" : [ 50364 , 4410 , 12 , 384 , 631 , 2630 , 18146 , 3610 , 2506 , 50464 ],
"temperature" : 0.0 ,
"avg_logprob" : -0.43492694334550336 ,
"compression_ratio" : 0.7714285714285715 ,
"no_speech_prob" : 0.06502953916788101 ,
"confidence" : 0.595 ,
"words" : [
{
"text" : " Est-ce " ,
"start" : 2.02 ,
"end" : 3.78 ,
"confidence" : 0.441
},
{
"text" : " que " ,
"start" : 3.78 ,
"end" : 3.84 ,
"confidence" : 0.948
},
{
"text" : " vous " ,
"start" : 3.84 ,
"end" : 4.0 ,
"confidence" : 0.935
},
{
"text" : " allez " ,
"start" : 4.0 ,
"end" : 4.14 ,
"confidence" : 0.347
},
{
"text" : " bien? " ,
"start" : 4.14 ,
"end" : 4.48 ,
"confidence" : 0.998
}
]
}
],
"language" : " fr "
} Se o idioma não for especificado (por exemplo, sem opção --language fr na CLI), você encontrará uma chave adicional com as probabilidades de idioma:
{
...
"language" : " fr " ,
"language_probs" : {
"en" : 0.027954353019595146 ,
"zh" : 0.02743500843644142 ,
...
"fr" : 0.9196318984031677 ,
...
"su" : 3.0119704064190955e-08 ,
"yue" : 2.2565967810805887e-05
}
}transcribe_timestamped(model, audio, **kwargs)Transcreva o áudio usando um modelo de sussurro e calcule registros de data e hora no nível da palavra.
model : Instância do modelo sussurro O modelo de sussurro a ser usado para transcrição.
audio : Union [str, np.ndarray, Torch.tensor] O caminho para o arquivo de áudio para transcrever ou a forma de onda de áudio como uma matriz Numpy ou um tensor pytorch.
language : STR, Opcional (Padrão: Nenhum) O idioma do áudio. Se não, a detecção de idiomas será realizada.
task : STR, padrão "transcreva" a tarefa para executar: "transcreva" para reconhecimento de fala ou "traduzir" para tradução para o inglês.
vad : Union [Bool, STR, Lista [Tupla [Float, Float]]], opcional (padrão: false) se deve usar a detecção de atividades de voz (VAD) para remover segmentos não de fala. Pode ser:
detect_disfluencies : bool, padrão false se deve detectar e marcar desfluências (hesitações, palavras de preenchimento etc.) na transcrição.
trust_whisper_timestamps : bool, padrão é verdadeiro se depende dos registros de data e hora do Whisper para as posições iniciais do segmento.
compute_word_confidence : bool, padrão true se deve calcular as pontuações de confiança para as palavras.
include_punctuation_in_confidence : bool, padrão false se deve incluir probabilidade de pontuação ao calcular a confiança da palavra.
refine_whisper_precision : flutuar, padrão 0.5 quanto para refinar as posições do segmento de sussurros, em segundos. Deve ser um múltiplo de 0,02.
min_word_duration : flutuante, padrão 0,02 Duração mínima de uma palavra, em segundos.
plot_word_alignment : bool ou str, padrão false se a plotar o alinhamento da palavra para cada segmento. Se uma string, salve o gráfico no arquivo fornecido.
word_alignement_most_top_layers : int, opcional (padrão: nenhum) número de camadas superiores a serem usadas para alinhamento de palavras. Se não for, use todas as camadas.
remove_empty_words : bool, padrão false se deve remover palavras sem duração que ocorra no final dos segmentos.
naive_approach : bool, padrão falsa força a abordagem ingênua de decodificar duas vezes (uma transcrição, uma vez para alinhamento).
use_backend_timestamps : bool, padrão false se deve usar o Word Timestamps fornecidos pelo back-end (openi-whisper ou Transformers), em vez dos calculados por heurísticas mais complexas de sussurro-timestampados.
temperature : união [flutuação, lista [flutuação]], temperatura padrão de 0,0 para amostragem. Pode ser um valor único ou uma lista para temperaturas de fallback.
compression_ratio_threshold : float, padrão 2.4 Se a taxa de compressão GZIP estiver acima desse valor, trate a decodificação como falhou.
logprob_threshold : Float, padrão -1.0 Se a probabilidade média de log estiver abaixo desse valor, trate a decodificação como falhada.
no_speech_threshold : FLOAT, LIMITAL DE PROBACIPAÇÃO 0.6 Padrão para <| Nospeech |> Tokens.
condition_on_previous_text : bool, padrão true se deve fornecer a saída anterior como um prompt para a próxima janela.
initial_prompt : STR, opcional (padrão: nenhum) Texto opcional a ser fornecido como um prompt para a primeira janela.
suppress_tokens : STR, padrão "-1" Lista separada por vírgula de IDs de token para suprimir durante a amostragem.
fp16 : BOOL, Opcional (Padrão: Nenhum) Se deve executar a inferência na precisão do FP16.
verbose : bool ou nenhum, padrão false se você deve exibir o texto sendo decodificado para o console. Se for verdade, exibe todos os detalhes. Se falso, exibe detalhes mínimos. Se nenhum, não exibe nada.
Um dicionário contendo:
text : STR - o texto completo da transcriçãosegments : Lista [dict] - Lista de dicionários de segmento, cada um contendo:id : INT - ID do segmentoseek : Int - Iniciar a posição no arquivo de áudio (em amostras)start : Float - Hora de início do segmento (em segundos)end : Float - Hora final do segmento (em segundos)text : STR - texto transcrito para o segmentotokens : List [int] - IDs de token para o segmentotemperature : flutuação - temperatura usada para este segmentoavg_logprob : FLOAT - Probabilidade média de log do segmentocompression_ratio : float - taxa de compressão do segmentono_speech_prob : FLOAT - Probabilidade de nenhum discurso no segmentoconfidence : flutuação - pontuação de confiança para o segmentowords : Lista [dict] - Lista de dicionários de palavras, cada um contendo:start : Float - Hora de início da palavra (em segundos)end : Float - Hora final da palavra (em segundos)text : STR - A palavra textoconfidence : Float - Score de confiança para a palavra (se calculado)language : STR - Linguagem detectada ou especificadalanguage_probs : Dict - Probabilidades de detecção de idiomas (se aplicável) RuntimeError : se o método VAD não estiver instalado ou configurado corretamente.ValueError : se o refine_whisper_precision não for um múltiplo positivo de 0,02.AssertionError : se a duração do áudio for mais curta que o esperado ou se houver inconsistências no número de segmentos. naive_approach pode ser útil para depuração ou ao lidar com características específicas de áudio, mas pode ser mais lento que a abordagem padrão.use_efficient_by_default é verdadeiro, alguns parâmetros como best_of , beam_size e temperature_increment_on_fallback são definidos como nenhum por padrão para processamento mais eficiente.remove_non_speech(audio, **kwargs)Remova os segmentos não de fala do áudio usando a detecção de atividades de voz (VAD).
audio : Torch.tensor Audio Data como um tensor pytorch.
use_sample : bool, padrão false se true, retorno de início e horário de término nas amostras em vez de segundos.
min_speech_duration : Float, duração mínima de 0,1 0,1 de um segmento de fala em segundos.
min_silence_duration : flutuante, padrão 1 duração mínima de um segmento de silêncio em segundos.
dilatation : flutuar, padrão 0.5 Quanto aumentar cada segmento de fala detectado por VAD, em segundos.
sample_rate : int, taxa de amostragem 16000 padrão do áudio.
method : STR ou LIST [Tupla [FLOAT, FLOAT]], Método "Silero" padrão para usar. Pode ser "Silero", "Auditok" ou uma lista de registros de data e hora.
avoid_empty_speech : BOOL, padrão false se verdadeiro, evite retornar um segmento de fala vazia.
plot : Union [Bool, STR], padrão false se verdadeiro, plote os resultados do VAD. Se uma string, salve o gráfico no arquivo fornecido.
Uma tupla contendo:
ImportError : se a biblioteca VAD necessária (por exemplo, Auditok) não estiver instalada.ValueError : se um método VAD inválido for especificado. load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)Carregue um modelo de sussurro de um determinado nome ou caminho.
name : Str Nome do modelo ou caminho para o modelo. Pode ser:
device : Union [STR, Torch.Device], dispositivo opcional (padrão: nenhum) para usar. Se não for, use CUDA, se disponível, caso contrário, a CPU.
backend : STR, back-end "OpenAi-Whisper" padrão para usar. "Transformers" ou "Openai-Whisper".
download_root : str, opcional (padrão: nenhuma) pasta root para baixar o modelo para. Se não for, use a raiz de download padrão.
in_memory : bool, padrão false se a pré -carga do modelo pesam na memória do host.
O modelo de sussurro carregado.
ValueError : se um back -end inválido for especificado.ImportError : se a biblioteca Transformers não estiver instalada ao usar o back -end "Transformers".RuntimeError : se o modelo não puder ser encontrado ou baixado da fonte especificada.OSError : Se houver problemas para ler o arquivo de modelo ou acessar o caminho especificado. get_alignment_heads(model, max_top_layer=3)Obtenha as cabeças de alinhamento para o modelo fornecido.
model : Instância do modelo sussurro O modelo de sussurro para recuperar cabeças de alinhamento.
max_top_layer : int, padrão 3 número máximo de camadas superiores a serem consideradas para as cabeças de alinhamento.
Um tensor esparso representando as cabeças de alinhamento.
As funções a seguir estão disponíveis para gravar transcrições para vários formatos de arquivo:
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)Escreva dados de transcrição em um arquivo CSV.
transcript : Lista [dict] Lista de dicionários de segmento de transcrição.
file : arquivo de objeto semelhante a um arquivo para gravar os dados do CSV.
sep : STR, padrão "," separador para usar no arquivo CSV.
text_first : bool, padrão true se true, escreva a coluna de texto antes dos horários de início/final.
format_timestamps : Callable, Opcional (Padrão: Nenhum) Função para formatar os valores de timestamp.
header : Union [bool, list [str]], padrão false se true, escreva cabeçalho padrão. Se uma lista, use como cabeçalho personalizado.
IOError : se houver problemas de gravação no arquivo especificado.ValueError : se os dados da transcrição não estiverem no formato esperado. format_timestamps permite a formatação personalizada de valores de timestamp, que podem ser úteis para casos de uso específicos ou requisitos de análise de dados. write_srt(transcript, file)Escreva dados de transcrição em um arquivo SRT (Sub -Rip Swititle).
transcript : Lista [dict] Lista de dicionários de segmento de transcrição.
file : arquivo de objeto semelhante a um arquivo para gravar os dados SRT.
IOError : se houver problemas de gravação no arquivo especificado.ValueError : se os dados da transcrição não estiverem no formato esperado. write_vtt(transcript, file)Escreva dados de transcrição em um arquivo VTT (WebVTT).
transcript : Lista [dict] Lista de dicionários de segmento de transcrição.
file : arquivo de objeto semelhante a um arquivo para gravar os dados da VTT.
IOError : se houver problemas de gravação no arquivo especificado.ValueError : se os dados da transcrição não estiverem no formato esperado. write_tsv(transcript, file)Escreva dados de transcrição em um arquivo TSV (Valores Separado com TAB).
transcript : Lista [dict] Lista de dicionários de segmento de transcrição.
file : arquivo de objeto semelhante a um arquivo para gravar os dados do TSV.
IOError : se houver problemas de gravação no arquivo especificado.ValueError : se os dados da transcrição não estiverem no formato esperado. Aqui estão algumas opções que não são ativadas por padrão, mas podem melhorar os resultados.
Como mencionado anteriormente, algumas opções de decodificação são desativadas por padrão para oferecer melhor eficiência. No entanto, isso pode afetar a qualidade da transcrição. Para executar com as opções que têm a melhor chance de fornecer uma boa transcrição, use as seguintes opções.
results = whisper_timestamped . transcribe ( model , audio , beam_size = 5 , best_of = 5 , temperature = ( 0.0 , 0.2 , 0.4 , 0.6 , 0.8 , 1.0 ), ...)whisper_timestamped --accurate ... Os modelos de sussurros podem "alucinar" o texto quando recebidos um segmento sem fala. Isso pode ser evitado executando o VAD e colando segmentos de fala antes de transcrever com o modelo Whisper. Isso é possível com whisper-timestamped .
results = whisper_timestamped . transcribe ( model , audio , vad = True , ...)whisper_timestamped --vad True ...Por padrão, o método VAD utilizado é Silero. Mas outros métodos estão disponíveis, como versões anteriores do Silero ou Auditok. Esses métodos foram introduzidos porque as versões mais recentes do Silero Vad podem ter muitos alarmes falsos em alguns áudios (discursos detectados no silêncio).
results = whisper_timestamped . transcribe ( model , audio , vad = "silero:v3.1" , ...)
results = whisper_timestamped . transcribe ( model , audio , vad = "auditok" , ...)whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ... Para assistir aos resultados do VAD, você pode usar a opção --plot da CLI whisper_timestamped , ou a opção plot_word_alignment da função python whisper_timestamped.transcribe() . Ele mostrará os resultados do VAD no sinal de áudio de entrada como seguinte (o eixo x é o tempo em segundos):
| Vad = "Silero: v4.0" | Vad = "Silero: v3.1" | vad = "auditok" |
|---|---|---|
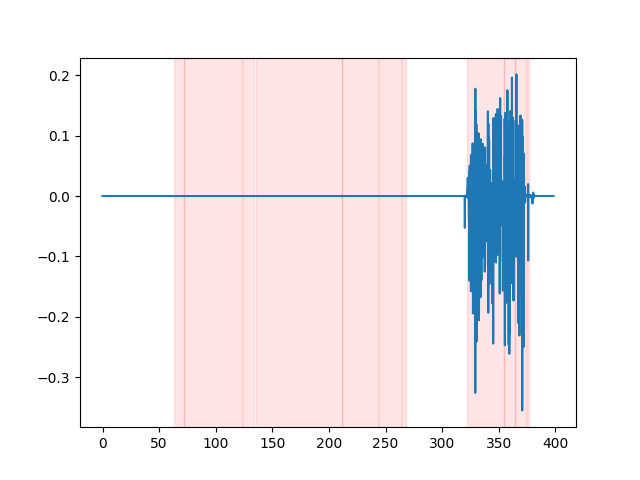 | 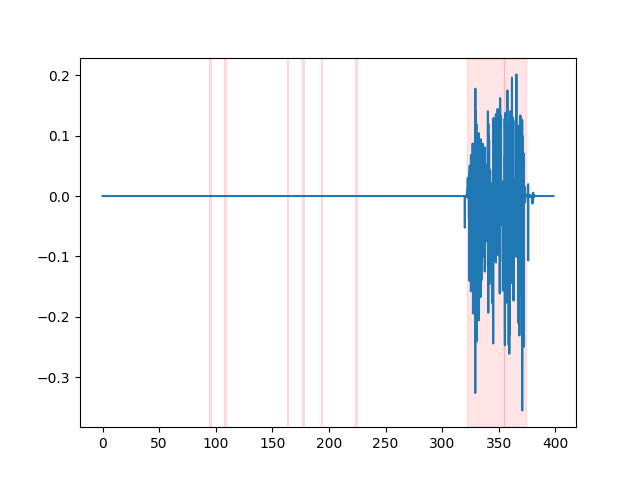 | 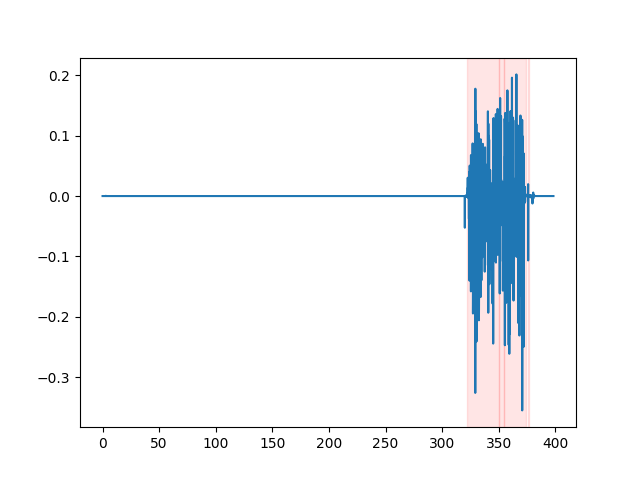 |
Os modelos de sussurros tendem a remover as disfluências de fala (palavras de preenchimento, hesitações, repetições etc.). Sem precauções, as desfluências que não são transcritas afetarão o carimbo de data e hora da seguinte palavra: o registro de data e hora do início da palavra será realmente o registro de data e hora do início das desfluências. whisper-timestamped pode ter algumas heurísticas para evitar isso.
results = whisper_timestamped . transcribe ( model , audio , detect_disfluencies = True , ...)whisper_timestamped --detect_disfluencies True ... IMPORTANTE: Observe que, ao usar essas opções, possíveis disfluências aparecerão na transcrição como uma palavra especial " [*] ".
Se você usar isso em sua pesquisa, cite o repositório:
@misc { lintoai2023whispertimestamped ,
title = { whisper-timestamped } ,
author = { Louradour, J{'e}r{^o}me } ,
journal = { GitHub repository } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/linto-ai/whisper-timestamped} }
}bem como o papel sussurro do Openai:
@article { radford2022robust ,
title = { Robust speech recognition via large-scale weak supervision } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
journal = { arXiv preprint arXiv:2212.04356 } ,
year = { 2022 }
}E este artigo para a dinâmica-tempo de variação:
@article { JSSv031i07 ,
title = { Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package } ,
author = { Giorgino, Toni } ,
journal = { Journal of Statistical Software } ,
year = { 2009 } ,
volume = { 31 } ,
number = { 7 } ,
doi = { 10.18637/jss.v031.i07 }
}

