Chinese Mixtral 8x7B
1.0.0

Этот проект основан на модели Mixtral-8x7b, выпущенной Mistral, и, как ожидается, будет способствовать изучению модели MOE китайским сообществом обработки естественного языка. Наш расширенный словарный запас значительно улучшает эффективность кодирования и декодирования модели китайского и выполняет постепенное предварительное обучение модели расширенного списка словарного запаса через крупномасштабный корпус с открытым исходным кодом, чтобы модель обладала сильным китайским поколением и пониманием.
Проект контент с открытым исходным кодом:
Обратите внимание, что китайский Mixtral-8x7b все еще может генерировать вводящие в заблуждение ответы, содержащие фактические ошибки или вредное содержание, содержащее смещение/дискриминацию. Пожалуйста, будьте осторожны, чтобы идентифицировать и использовать сгенерированный контент и не распространять сгенерированный вредный контент в Интернет.
Этот проект обучен с использованием Qlora. Вес Лоры и модель комбинированного веса являются открытым исходным кодом соответственно. Вы можете загрузить в соответствии с вашими потребностями:
| Название модели | Размер модели | Скачать адрес | Примечание |
|---|---|---|---|
| Китайский Миксал-8x7b | 88 ГБ | Объятие Моделикоп | Полная модель китайского списка слов может быть использована напрямую |
| Китайский Миксал-8x7B-адаптер | 2,7 ГБ | Объятие | Веса лоры должны быть объединены с исходным Mixtral-8x7b, прежде чем их можно будет использовать. Пожалуйста, обратитесь к сценарию слияния здесь. |
Китайский Mixtral-8x7b поддерживает полную экосистему модели Mixtral-8x7b, включая использование vLLM и Flash Attention 2 для ускорения, используя bitsandbytes для квантования модели и т. Д. Вот пример кода для рассуждения с использованием китайского Mixtral-8x7b.
Используя флэш -внимание 2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Количественная оценка с использованием 4 -бит:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Обратите внимание, что китайский Mixtral-8x7b является базовой моделью и не была точно настроена по инструкциям, поэтому возможности соответствия инструкциям ограничены. Вы можете обратиться к разделу с тонкой настройкой, чтобы точно настроить модель.
Мы использовали следующие наборы данных оценки для оценки китайского Миксал-8x7B отдельно:
Согласно техническому отчету, опубликованному Мистраль, Mixtral-8x7b активирует параметр 13b при выводе. В следующей таблице показаны результаты 5-выстрелов китайских моделей китайского Mixtral-8x7b и других моделей расширения слов в масштабе 13b в каждом наборе данных оценки:
| Название модели | Покрементный учебный материал | C-Eval (Китайский) | Cmmlu (Китайский) | MMLU (Английский) | Hellaswag (Английский) |
|---|---|---|---|---|---|
| IDEA-CCNL/ZIYA2-13B-BASE | 650b токен | 59,29 | 60.93 | 59,86 | 58,90 |
| Tigerresearch/Tigerbot-13b-Base-V3 | 500b токен | 50,52 | 51.65 | 53,46 | 59,16 |
| Linly-AI/Китай-лама-2-13B-HF | 11b токен | 42,57 | 41,95 | 51.32 | 59,05 |
| HFL/китайская лама-2-13B | Около 30b токен (120 ГБ) | 41.90 | 42.08 | 51,92 | 59,28 |
| Китайский Миксал-8x7b (этот проект) | 42b токен | 52,08 | 51.08 | 69,80 | 65,69 |
С точки зрения китайского знания и понимания, наш китайский микстрал-8x7b сопоставим с характеристиками Tigerbot-13b-base-V3. Поскольку объем учебных данных китайского Миксал-8x7B составляет всего 8% от Tigerbot-13b-Base-V3, у нашей модели все еще есть место для дальнейшего улучшения. В то же время, благодаря мощным результатам оригинальной модели Mixtral-8x7b, наш китайский микстрал-8x7b достиг самых сильных английских уровней каждой модели списка слов.
Из-за тонких различий в деталях реализации сценариев оценки в разных версиях, чтобы обеспечить согласованность и справедливость результатов оценки, наши сценарии оценки используют LM-оценку-дожди, выпущенную Eleutherai, а Commit Hash-28EC7FA.
В следующей таблице показаны эффекты генерации каждой модели расширения слова. Поскольку предварительно обученный корпус некоторых моделей не разделен eos_token , мы используем max_tokens = 100 для усечения сгенерированного текста. Наши параметры выборки - temperature = 0.8, top_p = 0.9 .

Для китайской кодирования и эффективности декодирования мы использовали сегмент слов каждой модели списка слов, чтобы кодировать срез набора данных Skypile (2023-06_ZH_HEAD_0000.jsonl) и сравнили сумму в китайском текстовом токене, выводящимся с помощью каждого сегмента слова:
| Название модели | Модель категория | Размер словарного запаса | Токеновое количество в китайском тексте | Эффективность кодека |
|---|---|---|---|---|
| Метама/лама-2-13b-HF | Лама | 32000 | 780 м | Низкий |
| Mistralai/Mixtral-8x7b-v0.1 | Миктральный | 32000 | 606 м | Низкий |
| Linly-AI/Китай-лама-2-13B-HF | Лама | 40076 | 532 м | середина |
| IDEA-CCNL/ZIYA2-13B-BASE | Лама | 39424 | 532 м | середина |
| HFL/китайская лама-2-13B | Лама | 55296 | 365 м | высокий |
| Tigerresearch/Tigerbot-13b-Base-V3 | Лама | 65112 | 342 м | высокий |
| Китайский Миксал-8x7b (этот проект) | Миктральный | 57000 | 355M | высокий |
Среди тестового текста около 1,4 ГБ нашего китайского китайского кодека китайского кодекса китайского китайского кодека составляет только Tigerbot-13b-Base-V3, что на 41,5% выше, чем исходная модель. Это способствует ускорению скорости вывода китайских текстов и сохранения длины последовательности в сценариях, таких как встроенное обучение и цепочка мыслей, которая способствует улучшению выполнения сложных задач вывода.
Мы используем sentencepiece для обучения китайского словарного запаса BPE на данных 12G Zhihu и данных просветления 2G. При обучении списка словарного запаса мы перечислили количество китайских токенов с одним словом и общее количество китайских жетонов и объединили их, чтобы получить сотни словарных списков с различными размерами и содержанием. Чтобы получить наиболее подходящий список словарного запаса, мы рассчитали китайскую словарную способность этих списков словарного запаса через ALP, предложенную Zheng Bo et al. ALP - это удобный и быстрый показатель для измерения словарной способности конкретного языка путем расчета гранулярности подчинок на определенном языке и наказания средних и низкочастотных подчинок списка словаря.
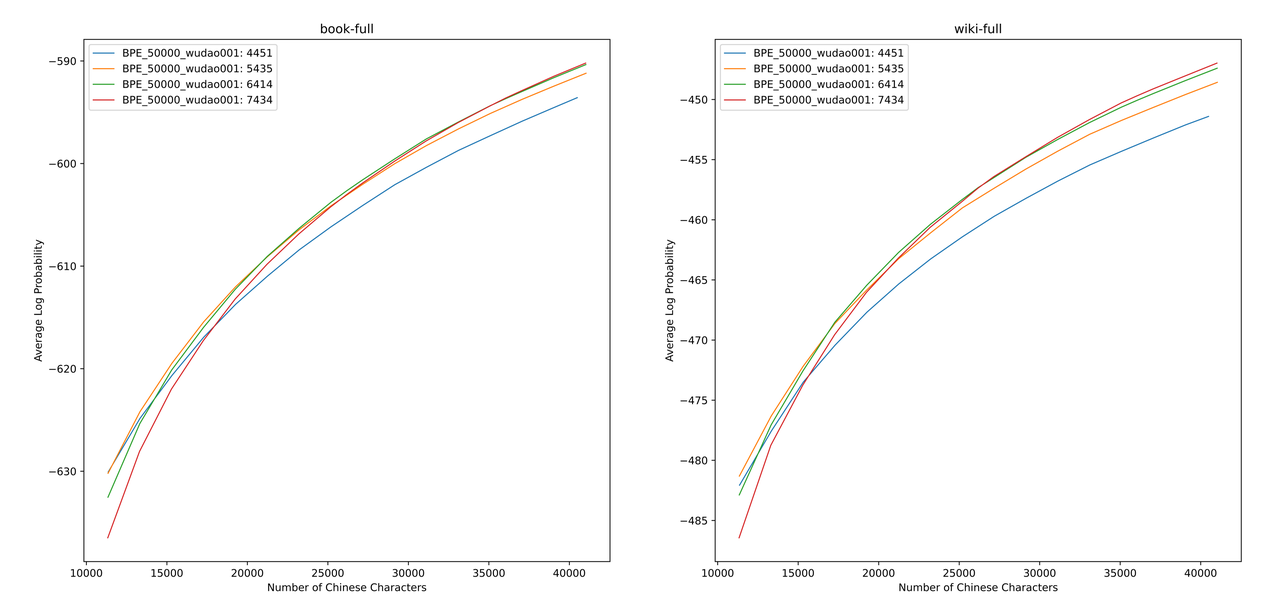
Мы оценили значения ALP для различных списков словарного запаса в книгах и энциклопедии. На иллюстрации четыре кривых представляют собой список из четырех китайских токенов с одним словом (4451, 5435, 6414 и 7434). Чтобы избежать слишком малой скорости сжатия в Китае, и слишком редкого встроенного слоя, мы выбираем точку перегиба кривой ALP, которая добавит 25 000 китайских токенов в список словарного запаса. Исходя из этого, мы выбрали самый большой ALP среди четырех кривых, то есть список словарного запаса из 6414 китайских токенов с одним словом был добавлен в качестве окончательного списка словарного запаса, выбранного китайским Микстралом-8x7B.
После получения нового словаря нам необходимо расширить и инициализировать слои встраивания и LM_HEAD. Мы инициализируем расширение, используя слово, встраивающее среднее значение нового токена в старый встраивающий слой. В наших предыдущих экспериментах этот подход немного лучше, чем реализация по умолчанию Huggingface, то есть инициализация выполняется с использованием фиксированного нормального распределения.
Модель Mixtral-8x7b имеет объем параметров 46,7b. Полное обучение параметров требует использования нескольких параллельных стратегий одновременно. Стоимость времени слишком высока, когда учебные ресурсы ограничены. Поэтому мы используем метод, официально рекомендованный HuggingFace для обучения модели с помощью Qlora. Основываясь на разложении LORA с низким уровнем ранга, Qlora дополнительно снижает видео память, необходимую для обучения, и поддерживает производительность, сравнимую с полнопараметрическим обучением, путем введения 4-битного квантования, двойного квантования и использования Nvidia Unified Memory для пейджина.
Мы ссылаемся на настройки LORA Yiming Cui et al., Применяем низкокачественные разложения ко всем линейным слоям исходной модели и устанавливаем параметры усиленных слоев встраивания и LM_HEAD для обучения. Для тела модели мы используем формат NF4 для квантования, который может заставить квантованные данные имеют такое же распределение данных, что и до квантования, а потеря веса модели меньше.
Мы рекомендуем использовать Python 3.10 + Torch 2.0.1
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolationМы обучили китайский Mixtral-8x7b на основе существующего набора данных с открытым исходным кодом, который включает в себя:
| Имя набора данных | Язык наборов данных | Объем используемых данных | Примечание |
|---|---|---|---|
| Skywork/Skypile-150b | китайский | 30b | Используйте только данные с 2022 + 2023 |
| Dkyoon/slimpajama-6b | Английский | 12B | Наборы данных Duplication 2 Epoch |
Загрузите набор данных в data с помощью data/download.py . Для набора данных Slimpajama вам необходимо использовать data/parquet2jsonl.py , чтобы преобразовать исходный набор данных в формат jsonl .
Загруженный набор данных - это осколок нескольких файлов JSONL. Используйте cat , чтобы объединить несколько осколков в один файл JSONL.
$ cat * .jsonl > all.jsonl split jsonl на поезд и действительные коллекции. Соотношение поезда и действительных линий в этом проекте составляет 999: 1.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl Зарегистрируйте имя и путь набора данных в data/datasets.toml :
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置Используйте data/preprocess_datasets.py , чтобы сегментировать набор данных для ускорения обучения.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab После выполнения сегментации подносов вы можете использовать data/utils.py для просмотра общего токена каждого набора данных:
$ python data/utils.py Сценарий обучения запуска - scripts/train.sh . Обучающий набор данных и соотношение набора данных может быть изменено путем изменения TRAIN_DATASETS :
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) Если вы используете систему управления кластером Slurm, вы можете отправить ее через sbatch :
$ sbatch scripts/train-pt.sh Если у вас нет Slurm или вы хотите начать обучение через командную строку, вы можете напрямую извлечь torchrun в scripts/train-pt.sh чтобы начать обучение.
Формат набора данных, необходимый для точной настройки, аналогичен предварительному обучению. Файл набора данных должен быть в формате JSONL: один json на строку, который должен содержать поле "text" и размывать инструкцию, ввод и вывод в соответствии с необходимым вам шаблоном.
Затем вам нужно зарегистрировать имя и PATH data/datasets.toml :
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 Сценарий обучения запуска- scripts/train-sft.sh . Обучающий набор данных и соотношение набора данных может быть изменено путем изменения TRAIN_DATASETS :
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) Если вы используете систему управления кластером Slurm, вы можете отправить ее через sbatch :
$ sbatch scripts/train-sft.sh Если у вас нет Slurm или вы хотите начать обучение через командную строку, вы можете напрямую извлечь torchrun в scripts/train-sft.sh для начала обучения.
Если вы чувствуете, что этот проект полезен для вашего исследования или используйте код этого проекта, пожалуйста, обратитесь к этому проекту:
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

