Chinese Mixtral 8x7B
1.0.0

このプロジェクトは、MistralがリリースしたモデルMixtral-8x7Bに基づいており、中国の自然言語加工コミュニティによるMOEモデルの研究をさらに促進することが期待されています。拡張された語彙リストは、モデルの中国語のエンコード効率を大幅に改善し、大規模なオープンソースコーパスを介して拡張された語彙リストモデルの漸進的なトレーニングを実行し、モデルには中国の世代と理解の能力が強いようになります。
プロジェクトオープンソースコンテンツ:
中国のMixtral-8X7Bは、事実上の誤りまたはバイアス/差別を含む有害なコンテンツを含む誤解を招く返信を生成する可能性があることに注意してください。生成されたコンテンツを特定して使用するように注意してください。生成された有害なコンテンツをインターネットに広めないでください。
このプロジェクトは、Qloraを使用してトレーニングされています。ロラ重量と組み合わせの重量モデルは、それぞれオープンソースです。ニーズに応じてダウンロードすることを選択できます。
| モデル名 | モデルサイズ | アドレスをダウンロードしてください | 述べる |
|---|---|---|---|
| 中国語-MIXTRAL-8X7B | 88GB | ハギングフェイス ModelScope | 完全な中国語の単語リストモデルは、直接使用できます |
| 中国mixtral-8x7b-adapter | 2.7GB | ハギングフェイス | Loraの重量は、使用する前に元のMixtral-8x7Bとマージする必要があります。こちらのマージスクリプトを参照してください。 |
中国語-MixTral-8X7Bは、 vLLMとFlash Attention 2使用するなど、モデルの量子化にbitsandbytesを使用するなど、完全なMixTral-8X7Bモデルエコシステムをサポートします。これは、中国Mixtral-8X7Bを使用した推論のコード例を示します。
Flash Anterness 2の使用2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))4ビットを使用した定量化:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))中国のMixtral-8X7Bは基本モデルであり、指示に微調整されていないため、命令コンプライアンス機能は限られています。微調整セクションを参照して、モデルを微調整できます。
次の評価データセットを使用して、中国のMixtral-8x7bを個別に評価しました。
Mistralが発表した技術レポートによると、MixTral-8X7Bは推論時に13Bパラメーターをアクティブにします。次の表は、各評価データセットにおける中国のミックストラル-8x7Bおよびその他の13Bスケールの中国語拡張モデルの5ショット結果を示しています。
| モデル名 | 増分トレーニング資料 | C-EVAL (中国語) | cmmlu (中国語) | mmlu (英語) | Hellaswag (英語) |
|---|---|---|---|---|---|
| IDEA-CCNL/ZIYA2-13Bベース | 650Bトークン | 59.29 | 60.93 | 59.86 | 58.90 |
| TigerResearch/TigerBot-13B-Base-V3 | 500Bトークン | 50.52 | 51.65 | 53.46 | 59.16 |
| linly-ai/中国語 - ラマ-2-13b-hf | 11bトークン | 42.57 | 41.95 | 51.32 | 59.05 |
| HFL/中国 - ラマ-2-13b | 約30Bトークン(120GB) | 41.90 | 42.08 | 51.92 | 59.28 |
| 中国語mixtral-8x7b(このプロジェクト) | 42Bトークン | 52.08 | 51.08 | 69.80 | 65.69 |
中国の知識と理解の観点から、私たちの中国のMixtral-8x7Bは、TigerBot-13B-Base-V3のパフォーマンスに匹敵します。中国のMixtral-8x7Bのトレーニングデータの量はTigerbot-13b-base-V3のトレーニングデータの8%に過ぎないため、モデルにはさらに改善の余地があります。同時に、元のMixTral-8X7Bモデルの強力なパフォーマンスのおかげで、中国のMixtral-8X7Bは、各単語リストモデルの最も強力な英語レベルに達しました。
異なるバージョンの評価スクリプトの実装の詳細の微妙な違いにより、評価結果の一貫性と公平性を確保するために、評価スクリプトはEleutheraiによってリリースされたLM評価ハーネスを使用し、コミットハッシュは28EC7FAです。
次の表は、各単語拡張モデルの生成効果を示しています。一部のモデルの事前に訓練されたコーパスはeos_tokenによって分離されていないため、 max_tokens = 100を使用して生成されたテキストを切り捨てます。サンプリングパラメーターはtemperature = 0.8, top_p = 0.9です。

中国のエンコードとデコード効率の場合、各単語リストモデルの単語セグメントターを使用して、Skypileデータセット(2023-06_ZH_HEAD_0000.JSONL)のスライスをエンコードし、各単語セグメントターによる中国のテキストトークン量出力を比較しました。
| モデル名 | モデルカテゴリ | 語彙サイズ | 中国のテキストのトークン量 | コーデック効率 |
|---|---|---|---|---|
| メタラマ/llama-2-13b-hf | ラマ | 32000 | 780m | 低い |
| Mistralai/mixtral-8x7b-v0.1 | Mixtral | 32000 | 606m | 低い |
| linly-ai/中国語 - ラマ-2-13b-hf | ラマ | 40076 | 532m | 真ん中 |
| IDEA-CCNL/ZIYA2-13Bベース | ラマ | 39424 | 532m | 真ん中 |
| HFL/中国 - ラマ-2-13b | ラマ | 55296 | 365m | 高い |
| TigerResearch/TigerBot-13B-Base-V3 | ラマ | 65112 | 342m | 高い |
| 中国語mixtral-8x7b(このプロジェクト) | Mixtral | 57000 | 355m | 高い |
約1.4GBのテストテキストの中で、中国のミックストラル-8x7B中国のコーデック効率は、元のモデルよりも41.5%高いTigerbot-13b-base-V3に次ぐ2番目です。これは、中国のテキストの推論速度を加速し、コンテキスト学習や考え方などのシナリオでシーケンスの長さを保存することを助長します。これは、複雑な推論タスクのパフォーマンスを改善するのに役立ちます。
sentencepieceを使用して、12G Zhihuデータと2G啓発データで中国のBPE語彙をトレーニングします。語彙リストをトレーニングするとき、中国の単一単語トークンの数と中国のトークンの総数を列挙し、2つを組み合わせて、異なるサイズと内容の数百の語彙リストを取得しました。最も適切な語彙リストを取得するために、Zheng Bo et al。 ALPは、特定の言語でサブワードの粒度を計算し、語彙リストの中間および低周波数サブワードを罰することにより、特定の言語の語彙能力を測定するための便利で迅速な指標です。
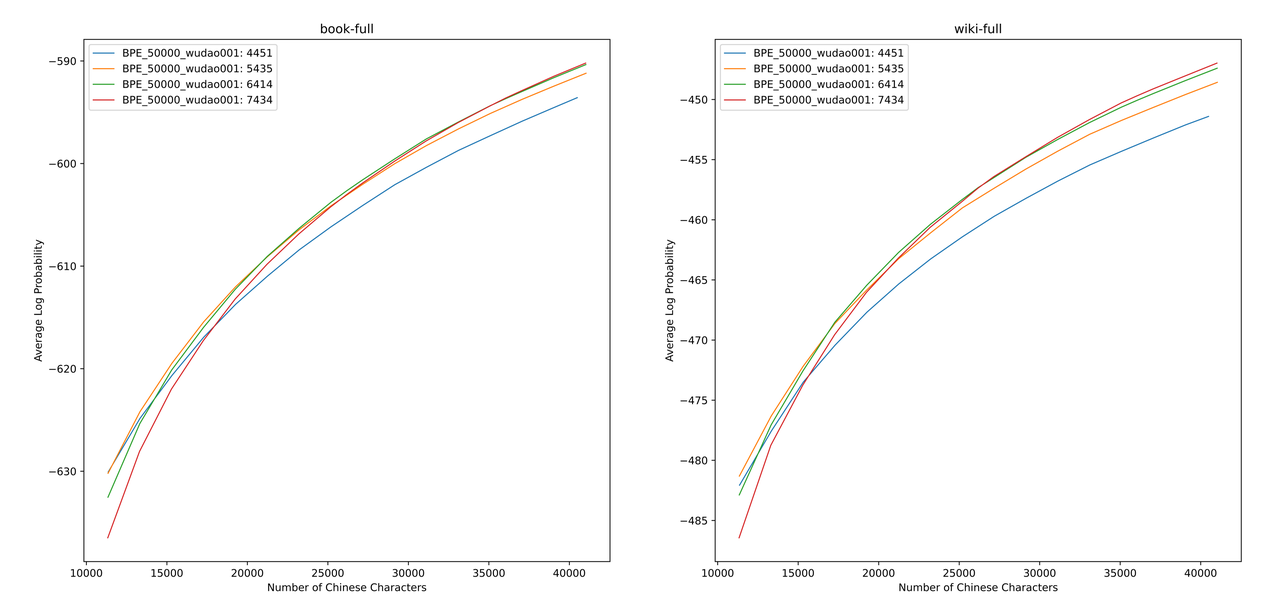
本や百科事典コーパスのさまざまな語彙リストのALP値を評価しました。図では、4つの曲線は、4つの中国の単一単語トークン(4451、5435、6414、7434)の単語リストを表しています。小さすぎる中国の圧縮速度を回避するために、およびまばらすぎる埋め込み層は、ALP曲線の変曲点を選択します。これにより、語彙リストに25,000個の中国のトークンが追加されます。これに基づいて、4つの曲線の中で最大のALPを選択しました。つまり、中国のMixtral-8X7bが選択した最終的な語彙リストとして、6414の中国の単一ワードトークンの語彙リストが追加されました。
新しい語彙を取得した後、埋め込み層とLM_headレイヤーを拡張および初期化する必要があります。古い埋め込み層の新しいトークンの埋め込み平均という単語を使用して、拡張を初期化します。以前の実験では、このアプローチはHuggingfaceのデフォルトの実装よりもわずかに優れています。つまり、初期化は固定正規分布を使用して実行されます。
MixTral-8X7Bモデルのパラメーターボリュームは46.7bです。完全なパラメータートレーニングでは、複数の並列戦略を同時に使用する必要があります。トレーニングリソースが限られている場合、時間コストが高すぎます。したがって、Huggingfaceが正式に推奨する方法を使用して、Qloraを使用してモデルをトレーニングします。 Lora Low-Rank分解に基づいて、Qloraはトレーニングに必要なビデオメモリをさらに減らし、4ビット量子化、デュアル量子化、およびページング用のNvidia Unifiedメモリを使用することにより、フルパラメータートレーニングに匹敵するパフォーマンスを維持します。
Yiming Cui et al。によるLoraの設定を参照し、元のモデルのすべての線形層に低ランク分解を適用し、増幅された埋め込みとLM_head層のパラメーターをトレーニング可能に設定します。モデル本体の場合、量子化にはNF4形式を使用します。これにより、量子化されたデータが量子化前と同じデータ分布を持つようになり、モデルの重量情報の損失が少なくなります。
Python 3.10 + Torch 2.0.1を使用することをお勧めします
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolation既存のオープンソースデータセットに基づいて、中国のMixtral-8x7bをトレーニングしました。
| データセット名 | データセット言語 | 使用されるデータの量 | 述べる |
|---|---|---|---|
| Skywork/skypile-150b | 中国語 | 30b | 2022 + 2023のデータのみを使用します |
| dkyoon/slimpajama-6b | 英語 | 12b | データセットの複製2エポック |
data/download.pyを介してデータセットをdataにダウンロードします。 Slimpajamaデータセットの場合、 data/parquet2jsonl.pyを使用して、元のデータセットをjsonl形式に変換する必要があります。
ダウンロードされたデータセットは、複数のJSONLファイルのシャードです。 catを使用して、複数のシャードを1つのJSONLファイルにマージします。
$ cat * .jsonl > all.jsonl jsonlを電車と有効なコレクションにsplit 。このプロジェクトの列車と有効なラインの比率は999:1です。
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonlデータセット名とパスをdata/datasets.tomlに登録します。TOML:
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置data/preprocess_datasets.pyを使用して、データセットをサブワードセグメントしてトレーニングを高速化します。
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocabサブワードセグメンテーションを実行した後、 data/utils.pyを使用して、各データセットのトークンの合計トークンを表示できます。
$ python data/utils.pyトレーニングスタートアップスクリプトはscripts/train.shです。トレーニングデータセットとデータセットの比率は、 TRAIN_DATASETS変更することで変更できます。
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) SluRMクラスター管理システムを使用する場合は、 sbatchを介して送信できます。
$ sbatch scripts/train-pt.sh SluRMを持っていない場合、またはコマンドラインを介してトレーニングを開始したい場合は、 scripts/train-pt.shでtorchrunを直接抽出してトレーニングを開始できます。
微調整に必要なデータセット形式は、トレーニング前に似ています。データセットファイルはJSONL形式である必要があります。1行ごとに1つのJSONで、 "text"フィールドを含み、必要なテンプレートに従って命令、入力、出力をスプライスする必要があります。
次に、データセット名とパスをdata/datasets.tomlに登録する必要があります。TOML:
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名トレーニングスタートアップスクリプトはscripts/train-sft.shです。トレーニングデータセットとデータセットの比率は、 TRAIN_DATASETS変更することで変更できます。
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) SluRMクラスター管理システムを使用する場合は、 sbatchを介して送信できます。
$ sbatch scripts/train-sft.sh SluRMを持っていない場合、またはコマンドラインを介してトレーニングを開始したい場合は、 scripts/train-sft.shでtorchrunを直接抽出してトレーニングを開始できます。
このプロジェクトが調査に役立つと感じたり、このプロジェクトのコードを使用したりする場合は、このプロジェクトを参照してください。
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

