Chinese Mixtral 8x7B
1.0.0

이 프로젝트는 Mistral이 발표 한 Mixtral-8x7b 모델을 기반으로하며 중국 자연 언어 처리 커뮤니티의 MOE 모델 연구를 더욱 촉진 할 것으로 예상됩니다. 우리의 확장 된 어휘 목록은 중국의 모델 인코딩 및 디코딩 효율성을 크게 향상시키고, 대규모 오픈 소스 코퍼스를 통해 확장 된 어휘 목록 모델의 증분 사전 훈련을 수행하므로 모델에 강력한 중국 생성 및 이해 기능이 있습니다.
프로젝트 오픈 소스 콘텐츠 :
중국-믹스 트랄 -8x7b는 여전히 바이어스/차별을 포함하는 사실적인 오류 또는 유해한 내용을 포함하는 오해의 소지가있는 답장을 생성 할 수 있습니다. 생성 된 컨텐츠를 식별하고 사용하고 생성 된 유해한 콘텐츠를 인터넷에 전파하지 마십시오.
이 프로젝트는 Qlora를 사용하여 교육을 받았습니다. 로라 중량과 결합 된 무게 모델은 각각 오픈 소스입니다. 필요에 따라 다운로드하도록 선택할 수 있습니다.
| 모델 이름 | 모델 크기 | 주소를 다운로드하십시오 | 주목 |
|---|---|---|---|
| 중국-믹스 트랄 -8x7b | 88GB | 포옹 페이스 ModelsCope | 완전한 중국어 단어 목록 모델은 직접 사용할 수 있습니다 |
| 중국-믹스 트랄 -8x7b 자산 | 2.7GB | 포옹 페이스 | LORA 무게는 사용하기 전에 원래 Mixtral-8x7b와 병합되어야합니다. 여기에서 Merge 스크립트를 참조하십시오. |
Chinese-Mixtral-8x7b는 모델 양자화에 bitsandbytes 사용하는 vLLM 및 Flash Attention 2 포함하여 완전한 mixtral-8x7b 모델 생태계를 지원합니다.
플래시주의 사용 2 :
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))4 비트를 사용한 정량화 :
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Chinese-Mixtral-8x7b는 기본 모델이며 지침에 의해 미세 조정되지 않았으므로 명령 규정 준수 기능은 제한되어 있습니다. 미세 조정 섹션을 참조하여 모델을 미세 조정할 수 있습니다.
우리는 다음 평가 데이터 세트를 사용하여 중국-믹스 트랄 -8x7b를 개별적으로 평가했습니다.
Mistral이 발표 한 기술 보고서에 따르면 Mixtral-8x7b는 추론 할 때 13b 매개 변수를 활성화합니다. 다음 표는 각 평가 데이터 세트에 대한 중국-믹스 트랄 -8x7b 및 기타 13B- 규모의 중국어 단어 확장 모델의 5 샷 결과를 보여줍니다.
| 모델 이름 | 증분 훈련 자료 | C-Eval (중국인) | cmmlu (중국인) | MMLU (영어) | Hellaswag (영어) |
|---|---|---|---|---|---|
| Idea-CCNL/ZIYA2-13B-베이스 | 650B 토큰 | 59.29 | 60.93 | 59.86 | 58.90 |
| tigerresearch/tigerbot-13b-base-v3 | 500B 토큰 | 50.52 | 51.65 | 53.46 | 59.16 |
| Linly-AI/Chinese-Llama-2-13B-HF | 11b 토큰 | 42.57 | 41.95 | 51.32 | 59.05 |
| HFL/중국-롤라마 -2-13B | 약 30B 토큰 (120GB) | 41.90 | 42.08 | 51.92 | 59.28 |
| 중국-믹스 트랄 -8x7b (이 프로젝트) | 42B 토큰 | 52.08 | 51.08 | 69.80 | 65.69 |
중국의 지식과 이해 측면에서, 우리의 중국-믹스 트랄 -8x7b는 tigerbot-13b-base-v3 성능과 비슷합니다. 중국-믹스 트랄 -8x7b의 훈련 데이터의 양은 TigerBot-13B-Base-V3의 8%에 불과하기 때문에, 우리의 모델은 여전히 추가 개선의 여지가 있습니다. 동시에, 원래 Mixtral-8x7b 모델의 강력한 성능 덕분에, 우리의 Chinese-Mixtral-8x7b는 각 단어 목록 모델에서 가장 강력한 영어 수준에 도달했습니다.
평가 결과의 일관성과 공정성을 보장하기 위해 다른 버전의 평가 스크립트의 구현 세부 사항의 미묘한 차이로 인해 평가 스크립트는 Eleutheai가 발표 한 LM- 평가 하네스를 사용하며 커밋 해시는 28EC7FA입니다.
다음 표는 각 단어 확장 모델의 생성 효과를 보여줍니다. 일부 모델의 미리 훈련 된 코퍼스는 eos_token 으로 분리되지 않으므로 max_tokens = 100 사용하여 생성 된 텍스트를 자릅니다. 우리의 샘플링 매개 변수는 temperature = 0.8, top_p = 0.9 입니다.

중국 인코딩 및 디코딩 효율의 경우 각 단어 목록 모델의 단어 세그먼트를 사용하여 Skypile 데이터 세트 (2023-06_ZH_HEAD_0000.JSONL)의 슬라이스를 인코딩하고 각 단어 세그먼트에 의해 중국어 텍스트 토큰 금액을 비교했습니다.
| 모델 이름 | 모델 카테고리 | 어휘 크기 | 중국어 텍스트의 토큰 수량 | 코덱 효율 |
|---|---|---|---|---|
| 메타 롤라/라마 -2-13B-HF | 야마 | 32000 | 780m | 낮은 |
| mistralai/mixtral-8x7b-v0.1 | 믹스 트랄 | 32000 | 606m | 낮은 |
| Linly-AI/Chinese-Llama-2-13B-HF | 야마 | 40076 | 532m | 가운데 |
| Idea-CCNL/ZIYA2-13B-베이스 | 야마 | 39424 | 532m | 가운데 |
| HFL/중국-롤라마 -2-13B | 야마 | 55296 | 365m | 높은 |
| tigerresearch/tigerbot-13b-base-v3 | 야마 | 65112 | 342m | 높은 |
| 중국-믹스 트랄 -8x7b (이 프로젝트) | 믹스 트랄 | 57000 | 355m | 높은 |
약 1.4GB의 테스트 텍스트 중에서, 우리의 중국-믹스 트랄 -8x7b 중국 코덱 효율은 원래 모델보다 41.5% 높은 TigerBot-13B-Base-V3에 이어 두 번째입니다. 이는 중국어 텍스트의 추론 속도를 가속화하고 텍스트 내 학습 및 생각의 사슬과 같은 시나리오에서 시퀀스 길이를 절약하는 데 도움이되며, 이는 복잡한 추론 작업의 성능을 향상시키는 데 도움이됩니다.
우리는 sentencepiece 사용하여 12g Zhihu 데이터와 2G 깨달음 데이터에 대해 중국 BPE 어휘를 훈련시킵니다. 어휘 목록을 훈련시킬 때, 우리는 중국 단일 단어 토큰의 수와 총 중국 토큰 수를 열거하고 두 가지 크기와 내용으로 수백 개의 어휘 목록을 얻기 위해 두 가지를 결합했습니다. 가장 적합한 어휘 목록을 얻기 위해 Zheng Bo 등이 제안한 ALP를 통해 이러한 어휘 목록의 중국 어휘 능력을 계산했습니다. ALP는 특정 언어로 서브 워드의 세분성을 계산하고 어휘 목록의 중간 및 저주파 하위 단어를 처벌함으로써 특정 언어의 어휘 능력을 측정하는 편리하고 빠른 지표입니다.
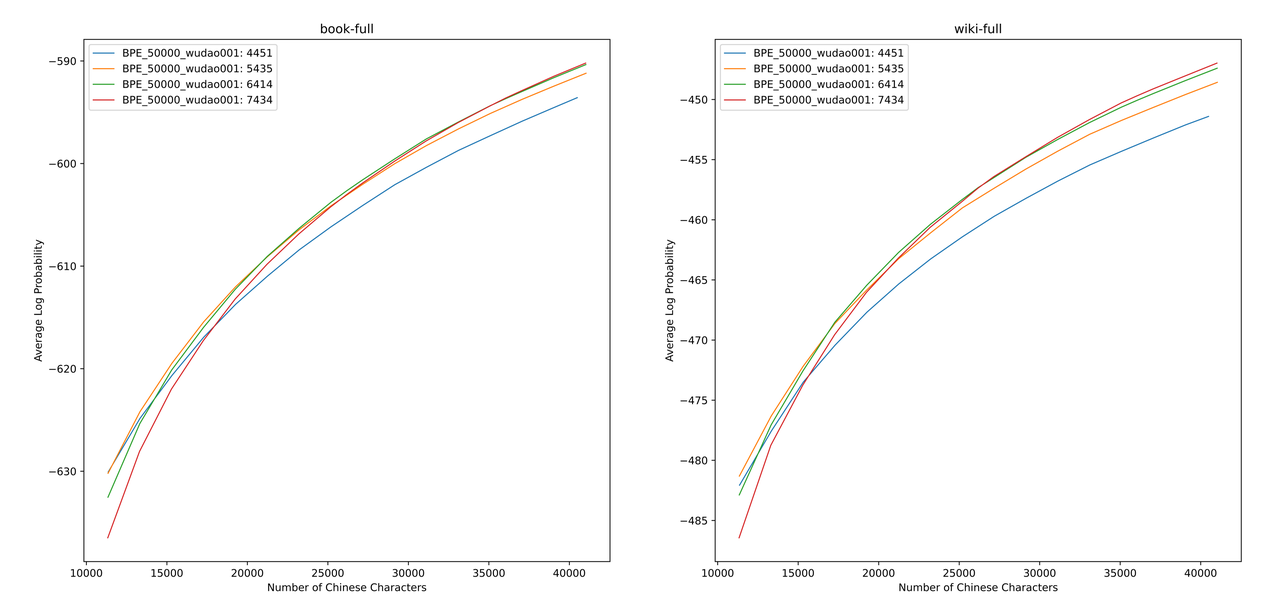
우리는 책과 백과 사전 코퍼스의 다양한 어휘 목록에 대한 ALP 값을 평가했습니다. 그림에서, 4 개의 곡선은 4 개의 중국 단일 단어 토큰 (4451, 5435, 6414 및 7434)의 단어 목록을 나타냅니다. 너무 작은 중국 압축 속도와 너무 희박한 임베딩 층을 피하기 위해 ALP 곡선의 변곡점을 선택하여 어휘 목록에 25,000 개의 중국 토큰을 추가합니다. 이를 바탕으로, 우리는 4 개의 곡선 중 가장 큰 ALP를 선택했습니다.
새로운 어휘를 얻은 후에는 임베딩 및 LM_ 헤드 레이어를 확장하고 초기화해야합니다. 오래된 임베딩 층에 새 토큰의 평균을 포함하여 확장을 초기화합니다. 이전 실험 에서이 접근법은 Huggingface의 기본 구현보다 약간 낫습니다. 즉, 초기화는 고정 정규 분포를 사용하여 수행됩니다.
mixtral-8x7b 모델의 매개 변수 볼륨 부피는 46.7b입니다. 전체 매개 변수 교육에는 동시에 여러 병렬 전략을 사용해야합니다. 훈련 자원이 제한 될 때 시간 비용이 너무 높습니다. 따라서 우리는 Qlora를 사용하여 모델을 훈련시키기 위해 Huggingface를 통해 공식적으로 권장되는 방법을 사용합니다. LORA 저 순위 분해를 기반으로 Qlora는 교육에 필요한 비디오 메모리를 더욱 줄이고 4 비트 양자화, 이중 양자화 및 페이징에 NVIDIA 통합 메모리를 사용하여 전체 매개 변수 교육과 비교할 수있는 성능을 유지합니다.
Yiming Cui et al.에 의한 LORA의 설정을 참조하고, 원래 모델의 모든 선형 레이어에 저 순위 분해를 적용하고, 증폭 된 임베딩 및 LM_head 레이어의 매개 변수를 훈련 할 수 있도록 설정합니다. 모델 본문의 경우 양자화에 NF4 형식을 사용하여 양자화 된 데이터가 양자화 전과 동일한 데이터 분포를 갖고 모델의 체중 정보 손실이 적을 수 있습니다.
Python 3.10 + Torch 2.0.1을 사용하는 것이 좋습니다
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolation우리는 기존 오픈 소스 데이터 세트를 기반으로 중국-믹스 트랄 -8x7b를 훈련 시켰습니다.
| 데이터 세트 이름 | 데이터 세트 언어 | 사용 된 데이터의 양 | 주목 |
|---|---|---|---|
| Skywork/Skypile-150B | 중국인 | 30b | 2022 + 2023의 데이터 만 사용하십시오 |
| Dkyoon/Slimpajama-6b | 영어 | 12b | 데이터 세트 복제 2 Epoch |
data/download.py 통해 데이터 세트를 data 로 다운로드하십시오. Slimpajama 데이터 세트의 경우 원본 데이터 세트를 jsonl 형식으로 변환하려면 data/parquet2jsonl.py 사용해야합니다.
다운로드 된 데이터 세트는 여러 JSONL 파일의 샤드입니다. cat 사용하여 여러 파편을 하나의 JSONL 파일로 병합하십시오.
$ cat * .jsonl > all.jsonl JSONL을 기차와 유효한 컬렉션으로 split . 이 프로젝트에서 열차와 유효한 라인의 비율은 999 : 1입니다.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl 데이터 세트 이름과 경로를 data/datasets.toml 에 등록하십시오.
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置data/preprocess_datasets.py 사용하여 데이터 세트를 세분화하여 교육 속도를 높이십시오.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab 서브 워드 분할을 수행 한 후 data/utils.py 사용하여 각 데이터 세트의 총 토큰을 볼 수 있습니다.
$ python data/utils.py 교육 시작 스크립트는 scripts/train.sh 입니다. TRAIN_DATASETS 수정하여 교육 데이터 세트 및 데이터 세트 비율을 수정할 수 있습니다.
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) Slurm 클러스터 관리 시스템을 사용하는 경우 sbatch 를 통해 제출할 수 있습니다.
$ sbatch scripts/train-pt.sh Slurm이 없거나 명령 줄을 통해 훈련을 시작하려면 scripts/train-pt.sh 에서 torchrun 직접 추출하여 교육을 시작할 수 있습니다.
미세 조정에 필요한 데이터 세트 형식은 사전 훈련과 유사합니다. 데이터 세트 파일은 JSONL 형식 : 라인 당 하나의 JSON이어야하며, "text" 필드를 포함하고 필요한 템플릿에 따라 명령, 입력 및 출력을 스플릿합니다.
그런 다음 데이터 세트 이름과 경로를 data/datasets.toml 에 등록해야합니다.
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 교육 시작 스크립트는 scripts/train-sft.sh 입니다. TRAIN_DATASETS 수정하여 교육 데이터 세트 및 데이터 세트 비율을 수정할 수 있습니다.
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) Slurm 클러스터 관리 시스템을 사용하는 경우 sbatch 를 통해 제출할 수 있습니다.
$ sbatch scripts/train-sft.sh Slurm이 없거나 명령 줄을 통해 교육을 시작하려면 scripts/train-sft.sh 에서 torchrun 직접 추출하여 교육을 시작할 수 있습니다.
이 프로젝트가 귀하의 연구에 도움이 되거나이 프로젝트의 코드를 사용한다고 생각되면이 프로젝트를 참조하십시오.
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

