Chinese Mixtral 8x7B
1.0.0

Este proyecto se basa en el modelo mixtral-8x7b publicado por Mistral, y se espera que promueva aún más el estudio del modelo MOE por la comunidad china de procesamiento del lenguaje natural. Nuestra lista de vocabulario ampliado mejora significativamente la eficiencia de codificación y decodificación del modelo de los chinos, y realiza un pre-entrenamiento incremental del modelo de lista de vocabulario expandido a través del corpus de código abierto a gran escala, de modo que el modelo tiene una fuerte generación china y capacidades de comprensión.
Proyecto Contenido de código abierto:
Tenga en cuenta que chino-mixtral-8x7b aún puede generar respuestas engañosas que contienen errores objetivos o contenido dañino que contiene sesgo/discriminación. Tenga cuidado de identificar y usar el contenido generado y no difundir el contenido dañino generado a Internet.
Este proyecto está capacitado con Qlora. El peso Lora y el modelo de peso combinado son de código abierto respectivamente. Puede elegir descargar de acuerdo con sus necesidades:
| Nombre del modelo | Tamaño del modelo | Dirección de descarga | Observación |
|---|---|---|---|
| Chino-mixtral-8x7b | 88 GB | Cara de abrazo Modelscope | Modelo completo de la lista de palabras chino, se puede usar directamente |
| Adaptador chino-mixtral-8x7b | 2.7GB | Cara de abrazo | Los pesos de Lora deben fusionarse con el mixtral-8x7b original antes de que puedan usarse. Consulte el script de fusión aquí. |
Chino-Mixtral-8x7b admite el ecosistema modelo MIXTRAL-8X7B completo, que incluye el uso de vLLM y Flash Attention 2 para la aceleración, utilizando bitsandbytes para la cuantización del modelo, etc. Aquí hay un ejemplo de código para el razonamiento utilizando chino-mixtral-8x7b.
Usando Flash Attention 2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Cuantificación utilizando 4 bits:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Tenga en cuenta que chino-mixtral-8x7b es un modelo base y no ha sido ajustado por las instrucciones, por lo que las capacidades de cumplimiento de la instrucción son limitadas. Puede consultar la sección ajustada para ajustar el modelo.
Utilizamos los siguientes conjuntos de datos de evaluación para evaluar chino-mixtral-8x7b por separado:
Según un informe técnico publicado por Mistral, el mixtral-8x7b activará el parámetro 13b cuando sea inferencia. La siguiente tabla muestra los resultados de 5 disparos de chino-mixtral-8x7b y otros modelos de expansión de palabras chinas a escala de 13b en cada conjunto de datos de evaluación:
| Nombre del modelo | Material de entrenamiento incremental | C-Eval (Chino) | Cmmlu (Chino) | MMLU (Inglés) | Helaswag (Inglés) |
|---|---|---|---|---|---|
| Idea-ccnl/ziya2-13b-base | Token 650b | 59.29 | 60.93 | 59.86 | 58.90 |
| TigerResearch/TigerBot-13B-Base-V3 | Token 500B | 50.52 | 51.65 | 53.46 | 59.16 |
| Linly-AI/Chinese-Llama-2-13B-HF | Token de 11b | 42.57 | 41.95 | 51.32 | 59.05 |
| HFL/chino-llama-2-13b | Alrededor de 30b Token (120 GB) | 41.90 | 42.08 | 51.92 | 59.28 |
| Chino-mixtral-8x7b (este proyecto) | Token 42b | 52.08 | 51.08 | 69.80 | 65.69 |
En términos de conocimiento y comprensión china, nuestro rendimiento de TigerBOT-13B-Base-V3 es comparable al rendimiento de TigerBOT-13B-Base-V3. Dado que la cantidad de datos de capacitación de chino-mixtral-8x7b es solo el 8% de la de Tigerbot-13b-Base-V3, nuestro modelo todavía tiene espacio para una mejora adicional. Al mismo tiempo, gracias al poderoso rendimiento del modelo original de mixtral-8x7b, nuestro chino-mixtral-8x7b ha alcanzado el nivel de inglés más fuerte de cada modelo de lista de palabras.
Debido a las diferencias sutiles en los detalles de implementación de los scripts de evaluación en diferentes versiones, para garantizar la consistencia y la justicia de los resultados de la evaluación, nuestros scripts de evaluación utilizan el LM-Evaluation-Harness liberado por Eleuthai, y el hash de confirmación es 28EC7FA.
La siguiente tabla muestra los efectos de generación de cada modelo de expansión de palabras. Dado que el corpus previamente entrenado de algunos modelos no está separado por eos_token , usamos max_tokens = 100 para truncar el texto generado. Nuestros parámetros de muestreo son temperature = 0.8, top_p = 0.9 .

Para la eficiencia de codificación y decodificación china, utilizamos el segmento de palabras de cada modelo de lista de palabras para codificar una porción del conjunto de datos Skypile (2023-06_zh_head_0000.jsonl) y comparamos la cantidad de cantidad de token de texto chino por cada segmento de segmento de palabras:
| Nombre del modelo | Categoría de modelo | Tamaño de vocabulario | Cantidad del token en el texto chino | Eficiencia de códec |
|---|---|---|---|---|
| Meta-llama/Llama-2-13B-HF | Llama | 32000 | 780m | Bajo |
| Mistralai/Mixtral-8x7b-V0.1 | Mixtral | 32000 | 606m | Bajo |
| Linly-AI/Chinese-Llama-2-13B-HF | Llama | 40076 | 532m | medio |
| Idea-ccnl/ziya2-13b-base | Llama | 39424 | 532m | medio |
| HFL/chino-llama-2-13b | Llama | 55296 | 365m | alto |
| TigerResearch/TigerBot-13B-Base-V3 | Llama | 65112 | 342m | alto |
| Chino-mixtral-8x7b (este proyecto) | Mixtral | 57000 | 355m | alto |
Entre el texto de prueba de aproximadamente 1.4GB, nuestra eficiencia de códec china china-8x7b es solo superada de TigerBOT-13B-Base-V3, que es 41.5% más alta que el modelo original. Esto es propicio para acelerar la velocidad de inferencia de los textos chinos y la longitud de la secuencia de ahorro en escenarios como el aprendizaje en contexto y la cadena de pensamiento, que conduce a mejorar el rendimiento de tareas de inferencia compleja.
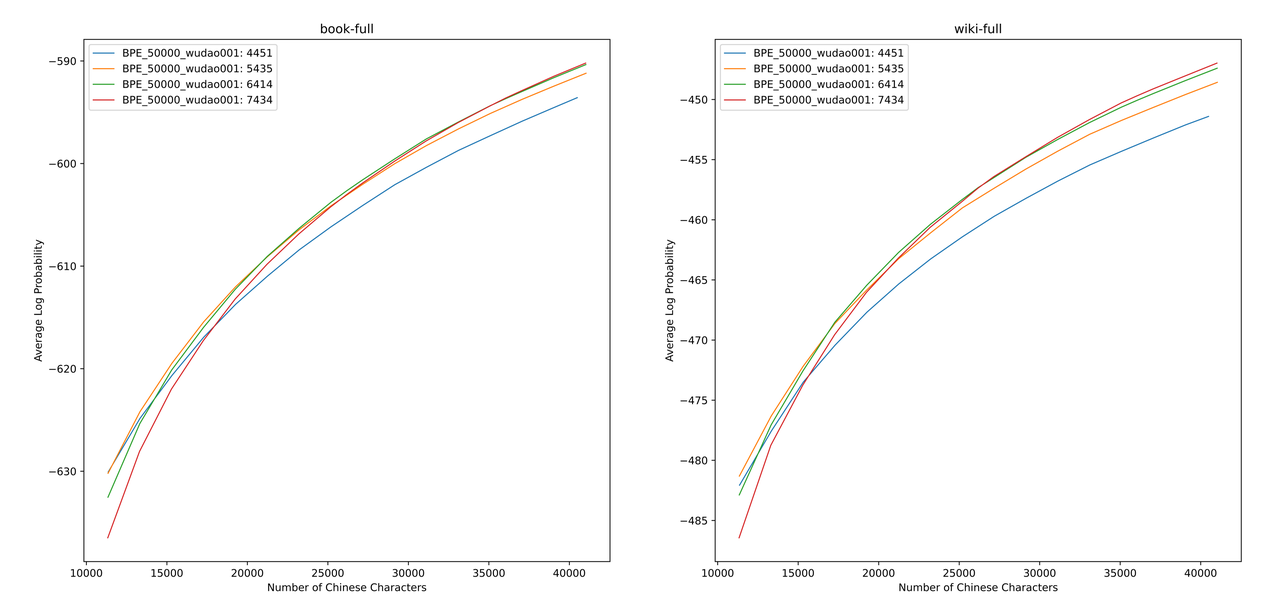
Utilizamos sentencepiece para entrenar el vocabulario de BPE chino en datos 12G Zhihu y datos de la Ilustración 2G. Al entrenar la lista de vocabulario, enumeramos el número de tokens de una sola palabra china y el número total de tokens chinos, y combinamos los dos para obtener cientos de listas de vocabulario con diferentes tamaños y contenidos. Para obtener la lista de vocabulario más adecuada, calculamos la capacidad de vocabulario chino de estas listas de vocabulario a través de ALP propuesto por Zheng Bo et al. ALP es un indicador conveniente y rápido para medir la capacidad de vocabulario de un lenguaje específico calculando la granularidad de las subvenciones en un lenguaje específico y castigando las subvenciones de frecuencia media y baja de la lista de vocabulario.
Evaluamos los valores de ALP para diferentes listas de vocabulario en libros y Corpus de Enciclopedia. En la ilustración, las cuatro curvas representan la lista de palabras de cuatro tokens de una sola palabra china (4451, 5435, 6414 y 7434). Para evitar la tasa de compresión china que es demasiado pequeña, y la capa de incrustación que es demasiado escasa, seleccionamos el punto de inflexión de la curva ALP, que agregará 25,000 tokens chinos a la lista de vocabulario. Sobre esta base, seleccionamos el ALP más grande entre las cuatro curvas, es decir, la lista de vocabulario de 6414 tokens chinos de una sola palabra se agregó como la lista de vocabulario final seleccionada por chino-mixtral-8x7b.
Después de obtener el nuevo vocabulario, necesitamos expandir e inicializar las capas de incrustación y lm_head. Inicializamos la expansión utilizando el promedio de incrustación de la palabra del nuevo token en la antigua capa de incrustación. En nuestros experimentos anteriores, este enfoque es ligeramente mejor que la implementación predeterminada de Huggingface, es decir, la inicialización se realiza utilizando una distribución normal fija.
El modelo MixTral-8x7b tiene un volumen de parámetros de 46.7b. El entrenamiento completo de parámetros requiere el uso de múltiples estrategias paralelas al mismo tiempo. El costo de tiempo es demasiado alto cuando los recursos de capacitación son limitados. Por lo tanto, utilizamos el método recomendado oficialmente por Huggingface para entrenar el modelo usando Qlora. Basado en la descomposición de bajo rango de Lora, Qlora reduce aún más la memoria de video requerida para la capacitación y mantiene el rendimiento comparable al entrenamiento de parámetro completo mediante la introducción de cuantización de 4 bits, cuantización dual y el uso de la memoria unificada de NVIDIA para la paginación.
Nos referimos a la configuración de Lora de Yiming Cui et al., Aplicamos la descomposición de bajo rango a todas las capas lineales del modelo original, y establecen los parámetros de las capas de incrustación amplificada y LM_head para que se pueden entrenar. Para el cuerpo del modelo, utilizamos el formato NF4 para la cuantización, que puede hacer que los datos cuantificados tengan la misma distribución de datos que antes de la cuantización, y la pérdida de información de peso del modelo es menor.
Recomendamos usar Python 3.10 + Torch 2.0.1
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolationEntrenamos chino-mixtral-8x7b basado en el conjunto de datos de código abierto existente, que incluye:
| Nombre del conjunto de datos | Lenguaje del conjunto de datos | La cantidad de datos utilizados | Observación |
|---|---|---|---|
| Skywork/skypile-150b | Chino | 30b | Use solo datos de 2022 + 2023 |
| Dkyoon/slimpajama-6b | Inglés | 12b | Duplicación del conjunto de datos 2 época |
Descargue el conjunto de datos en data a través data/download.py . Para el conjunto de datos de Slimpajama, debe usar data/parquet2jsonl.py para convertir el conjunto de datos original en formato jsonl .
El conjunto de datos descargado es un fragmento de múltiples archivos JSONL. Use cat para fusionar múltiples fragmentos en un archivo JSONL.
$ cat * .jsonl > all.jsonl split a JSONL en tren y colecciones válidas. La relación entre trenes y líneas válidas en este proyecto es 999: 1.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl Registre el nombre y la ruta del conjunto de datos en data/datasets.toml :
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置Use data/preprocess_datasets.py para subvencionar el segmento del conjunto de datos para acelerar el entrenamiento.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab Después de realizar la segmentación de subvenciones, puede usar data/utils.py para ver los tokens totales de cada conjunto de datos:
$ python data/utils.py El script de inicio de entrenamiento es scripts/train.sh . El conjunto de datos de entrenamiento y la relación de conjunto de datos se pueden modificar modificando TRAIN_DATASETS :
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) Si usa el sistema de administración de clúster SLURM, puede enviarlo a través de sbatch :
$ sbatch scripts/train-pt.sh Si no tiene slurm o desea comenzar a entrenar a través de la línea de comando, puede extraer directamente torchrun en scripts/train-pt.sh para comenzar a entrenar.
El formato del conjunto de datos requerido para el ajuste fino es similar al pre-entrenamiento. El archivo del conjunto de datos debe estar en formato JSONL: un JSON por línea, que debe contener el campo "text" y empalmar la instrucción, entrada y salida de acuerdo con la plantilla que necesita.
Luego debe registrar el nombre y la ruta del conjunto de datos en data/datasets.toml :
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 El script de inicio de entrenamiento es scripts/train-sft.sh . El conjunto de datos de entrenamiento y la relación de conjunto de datos se pueden modificar modificando TRAIN_DATASETS :
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) Si usa el sistema de administración de clúster SLURM, puede enviarlo a través de sbatch :
$ sbatch scripts/train-sft.sh Si no tiene slurm o desea comenzar a entrenar a través de la línea de comando, puede extraer directamente torchrun en scripts/train-sft.sh para comenzar a entrenar.
Si cree que este proyecto es útil para su investigación o usa el código de este proyecto, consulte este proyecto:
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

