Chinese Mixtral 8x7B
1.0.0

Este projeto é baseado no modelo Mixtral-8x7b divulgado por Mistral e deve promover ainda mais o modelo de MOE do MOE pela comunidade de processamento de linguagem natural chinesa. Nossa lista de vocabulário expandida melhora significativamente a codificação e a eficiência de decodificação do modelo e realiza o pré-treinamento incremental do modelo de lista de vocabulário expandido por meio de corpus de código aberto em larga escala, para que o modelo tenha fortes capacidades de geração e compreensão chinesas.
Conteúdo de código aberto do projeto:
Observe que o chinês-mixtral-8x7b ainda pode gerar respostas enganosas contendo erros factuais ou conteúdo prejudicial contendo viés/discriminação. Tenha cuidado para identificar e usar o conteúdo gerado e não espalhe o conteúdo prejudicial gerado para a Internet.
Este projeto é treinado usando Qlora. O peso da Lora e o modelo de peso combinado são de código aberto, respectivamente. Você pode optar por baixar de acordo com suas necessidades:
| Nome do modelo | Tamanho do modelo | Endereço para download | Observação |
|---|---|---|---|
| Chinês-Mixtral-8x7b | 88 GB | Huggingface Modelscope | Modelo completo da lista de palavras chinesas, pode ser usada diretamente |
| Adaptador chinês-mixtral-8x7b | 2,7 GB | Huggingface | Os pesos da LORA precisam ser mesclados com o mixtral-8x7b original antes que possam ser usados. Consulte o script de mesclagem aqui. |
O ecossistema de modelo chinês-mixtral-8x7b suporta o ecossistema de modelo Mixtral-8x7b, incluindo o uso de vLLM e Flash Attention 2 para aceleração, usando bitsandbytes para quantização do modelo, etc. Aqui está um exemplo de código para raciocínio usando o chinês-mixtral-8x7b.
Usando a atenção do flash 2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Quantificação usando 4bit:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Observe que o chinês-mixtral-8x7b é um modelo básico e não foi ajustado por instruções, portanto os recursos de conformidade das instruções são limitados. Você pode consultar a seção de ajuste fina para ajustar o modelo.
Utilizamos os seguintes conjuntos de dados de avaliação para avaliar o chinês-mixtral-8x7b separadamente:
De acordo com um relatório técnico divulgado pela Mistral, o Mixtral-8x7b ativará o parâmetro 13B quando a inferência. A tabela a seguir mostra os resultados de 5 tiros dos modelos de expansão de palavras chineses-mixtral-8x7b chineses e outros 13B em escala chinesa em cada conjunto de dados de avaliação:
| Nome do modelo | Material de treinamento incremental | C-EVAL (Chinês) | Cmmlu (Chinês) | Mmlu (Inglês) | Hellaswag (Inglês) |
|---|---|---|---|---|---|
| IDEA-CCNL/ZIYA2-13B-BASE | 650B token | 59.29 | 60.93 | 59.86 | 58.90 |
| Tigerresearch/TigerBot-13B-BASE-V3 | Token de 500b | 50.52 | 51.65 | 53.46 | 59.16 |
| Linly-AI/Chinese-llama-2-13b-HF | 11b token | 42.57 | 41.95 | 51.32 | 59.05 |
| HFL/Chinês-Lama-2-13b | Cerca de 30b token (120 GB) | 41.90 | 42.08 | 51.92 | 59.28 |
| Chinês-Mixtral-8x7b (este projeto) | 42b token | 52.08 | 51.08 | 69.80 | 65.69 |
Em termos de conhecimento e entendimento chinês, nosso chinês-mixtral-8x7b é comparável ao desempenho do TigerBot-13B-BASE-V3. Como a quantidade de dados de treinamento do chinês-mixtral-8x7b é de apenas 8% do do Tigerbot-13B-BASE-V3, nosso modelo ainda tem espaço para melhorias adicionais. Ao mesmo tempo, graças ao desempenho poderoso do modelo Mixtral-8x7B original, nosso chinês-mixtral-8x7b atingiu o nível mais forte em inglês de cada modelo de lista de palavras.
Devido às diferenças sutis nos detalhes da implementação dos scripts de avaliação em diferentes versões, a fim de garantir a consistência e a justiça dos resultados da avaliação, nossos scripts de avaliação usam o LM-Avaliação-Harness liberado por Eleutherai, e o hash de comprometimento é 28C7FA.
A tabela a seguir mostra os efeitos de geração de cada modelo de expansão de palavras. Como o corpus pré-treinado de alguns modelos não é separado por eos_token , usamos max_tokens = 100 para truncar o texto gerado. Nossos parâmetros de amostragem estão em temperature = 0.8, top_p = 0.9 .

Para a codificação chinesa e a eficiência de decodificação, usamos o segmento de palavras de cada modelo de lista de palavras para codificar uma fatia do conjunto de dados Skypile (2023-06_ZH_HEAD_0000.JSONL) e comparou a quantidade de token de texto em chinês emitida por cada segmentador de palavras:
| Nome do modelo | Categoria de modelo | Tamanho do vocabulário | Quantidade simbólica no texto chinês | Eficiência do codec |
|---|---|---|---|---|
| meta-llama/llama-2-13b-hf | Lhama | 32000 | 780m | Baixo |
| Mistralai/Mixtral-8x7b-V0.1 | Mixtral | 32000 | 606m | Baixo |
| Linly-AI/Chinese-llama-2-13b-HF | Lhama | 40076 | 532m | meio |
| IDEA-CCNL/ZIYA2-13B-BASE | Lhama | 39424 | 532m | meio |
| HFL/Chinês-Lama-2-13b | Lhama | 55296 | 365m | alto |
| Tigerresearch/TigerBot-13B-BASE-V3 | Lhama | 65112 | 342m | alto |
| Chinês-Mixtral-8x7b (este projeto) | Mixtral | 57000 | 355m | alto |
Entre o texto do teste de cerca de 1,4 GB, nossa eficiência de codec chinesa chinês-mixtral-8x7b é perdendo apenas para TigerBot-13B-BASE-V3, que é 41,5% maior que o modelo original. Isso é propício para acelerar a velocidade de inferência dos textos chineses e salvar o comprimento da sequência em cenários, como aprendizado no contexto e cadeia de pensamentos, o que é propício para melhorar o desempenho de tarefas de inferência complexas.
Utilizamos sentencepiece para treinar o vocabulário BPE chinês nos dados 12G Zhihu e os dados da iluminação 2G. Ao treinar a lista de vocabulário, enumeramos o número de tokens de uma palavra única chinesa e o número total de tokens chineses, e combinamos os dois para obter centenas de listas de vocabulário com diferentes tamanhos e conteúdos. Para obter a lista de vocabulário mais adequada, calculamos a capacidade de vocabulário chinesa dessas listas de vocabulário através do ALP proposto por Zheng Bo et al. O ALP é um indicador conveniente e rápido para medir a capacidade de vocabulário de um idioma específico, calculando a granularidade das subpainhas em um idioma específico e punindo as subbordas de média e baixa frequência da lista de vocabulário.
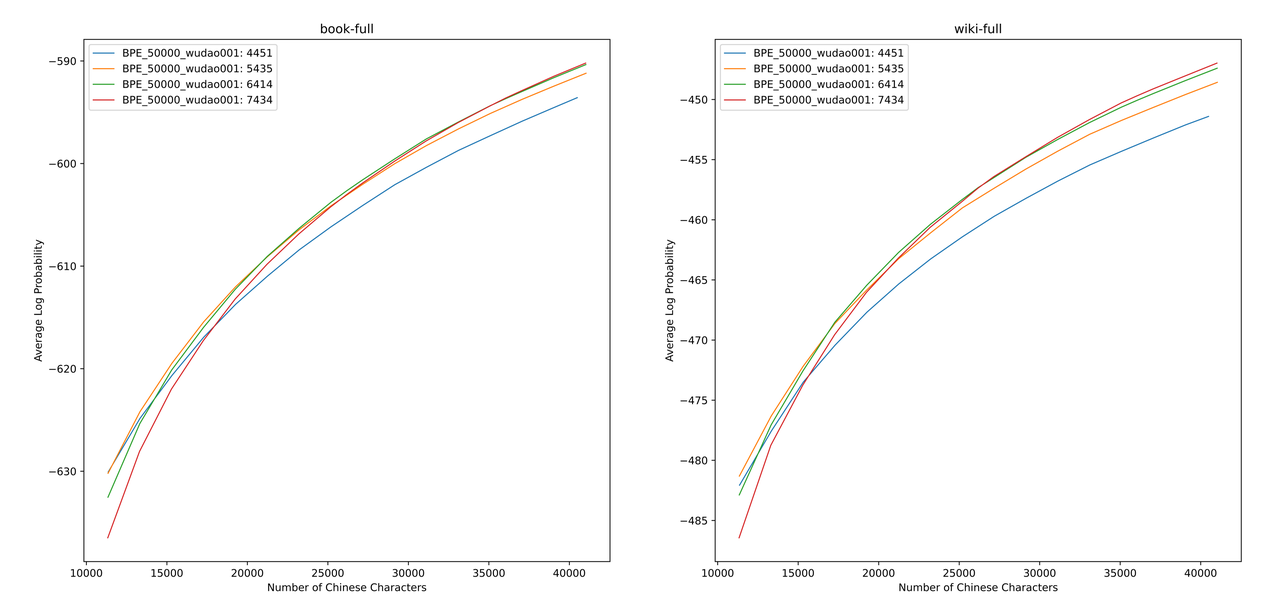
Avaliamos os valores da ALP para diferentes listas de vocabulário em livros e enciclopédia corpus. Na ilustração, as quatro curvas representam a lista de quatro tokens de palavra única chinesa (4451, 5435, 6414 e 7434). Para evitar a taxa de compressão chinesa muito pequena e a camada de incorporação muito escassa, selecionamos o ponto de inflexão da curva ALP, que adicionará 25.000 tokens chineses à lista de vocabulários. Nesta base, selecionamos o maior ALP entre as quatro curvas, ou seja, a lista de vocabulário de 6414 tokens de palavra única chinesa foi adicionada como a lista final de vocabulário selecionada por chinês-mixtral-8x7b.
Depois de obter o novo vocabulário, precisamos expandir e inicializar as camadas de incorporação e lm_head. Inicializamos a expansão usando a palavra de incorporação da média do novo token na antiga camada de incorporação. Em nossos experimentos anteriores, essa abordagem é um pouco melhor do que a implementação padrão do Huggingface, ou seja, a inicialização é realizada usando uma distribuição normal fixa.
O modelo Mixtral-8x7b possui um volume de parâmetro de 46,7b. O treinamento completo dos parâmetros requer o uso de várias estratégias paralelas ao mesmo tempo. O custo do tempo é muito alto quando os recursos de treinamento são limitados. Portanto, usamos o método recomendado oficialmente por Huggingface para treinar o modelo usando QLORA. Com base na decomposição de baixo rank LORA, a QLORA reduz ainda mais a memória de vídeo necessária para o treinamento e mantém o desempenho comparável ao treinamento completo do parâmetro, introduzindo quantização de 4 bits, quantização dupla e usando memória unificada da NVIDIA para paginação.
Nós nos referimos às configurações de Lora por Yiming Cui et al., Aplique a decomposição de baixo rank a todas as camadas lineares do modelo original e definimos os parâmetros das camadas de incorporação amplificada e LM_HEAD para serem treináveis. Para o corpo do modelo, usamos o formato NF4 para quantização, o que pode tornar os dados quantizados terem a mesma distribuição de dados que antes da quantização, e a perda de informações de peso do modelo é menor.
Recomendamos o uso do Python 3.10 + Torch 2.0.1
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolationTreinamos chinês-mixtral-8x7b com base no conjunto de dados de código aberto existente, que inclui:
| Nome do conjunto de dados | Idioma do conjunto de dados | A quantidade de dados utilizados | Observação |
|---|---|---|---|
| Skywork/Skypile-150b | chinês | 30b | Use apenas dados de 2022 + 2023 |
| DKYOON/VLIMPAJAMA-6B | Inglês | 12b | Duplicação do conjunto de dados 2 época |
Faça o download do conjunto de dados em data via data/download.py . Para o conjunto de dados do SlimpAjama, você precisa usar data/parquet2jsonl.py para converter o conjunto de dados original em formato jsonl .
O conjunto de dados baixado é um fragmento de vários arquivos JSONL. Use cat para mesclar vários fragmentos em um arquivo jsonl.
$ cat * .jsonl > all.jsonl split Jsonl em trem e coleções válidas. A proporção de trem e linhas válidas neste projeto é 999: 1.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl Registre o nome do conjunto de dados e o caminho em data/datasets.toml :
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置Use data/preprocess_datasets.py para segmento de subglema o conjunto de dados para acelerar o treinamento.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab Depois de executar a segmentação do subglema, você pode usar data/utils.py para visualizar os tokens totais de cada conjunto de dados:
$ python data/utils.py O script de inicialização do treinamento é scripts/train.sh . O conjunto de dados de treinamento e o índice de dados pode ser modificado modificando TRAIN_DATASETS :
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) Se você usar o Slurm Cluster Management System, poderá enviá -lo através sbatch :
$ sbatch scripts/train-pt.sh Se você não tiver Slurm ou deseja começar a treinar através da linha de comando, poderá extrair diretamente torchrun em scripts/train-pt.sh para começar a treinar.
O formato do conjunto de dados necessário para o ajuste fino é semelhante ao pré-treinamento. O arquivo do conjunto de dados precisa estar no formato JSONL: um JSON por linha, que precisa conter o campo "text" e ceder a instrução, entrada e saída de acordo com o modelo que você precisa.
Em seguida, você precisa registrar o nome do conjunto de dados e o caminho em data/datasets.toml :
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 O script de inicialização do treinamento é scripts/train-sft.sh . O conjunto de dados de treinamento e o índice de dados pode ser modificado modificando TRAIN_DATASETS :
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) Se você usar o Slurm Cluster Management System, poderá enviá -lo através sbatch :
$ sbatch scripts/train-sft.sh Se você não tiver Slurm ou deseja começar a treinar através da linha de comando, poderá extrair diretamente torchrun em scripts/train-sft.sh para começar o treinamento.
Se você acha que este projeto é útil para sua pesquisa ou use o código deste projeto, consulte este projeto:
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

