Chinese Mixtral 8x7B
1.0.0

Dieses Projekt basiert auf dem von Mistral veröffentlichten Modell Mixtral-8x7b und wird erwartet, dass die Untersuchung des MOE-Modells durch die chinesische Community für natürliche Sprache weiter fördert. Unsere erweiterte Vokabularliste verbessert die Codierung und Dekodierung der Chinesen des Modells des Modells signifikant und führt durch einen großräumigen Open-Source-Corpus eine inkrementelle Vorausbildung des erweiterten Modelllistenmodells durch, sodass das Modell eine starke chinesische Erzeugung und das Verständnis für die chinesische Generation und das Verständnis hat.
Projekt Open Source Inhalt:
Bitte beachten Sie, dass chinesisch-mixtral-8x7b möglicherweise weiterhin irreführende Antworten erzeugt, die Faktenfehler oder schädliche Inhalte enthalten, die Verzerrungen/Diskriminierung enthalten. Bitte achten Sie darauf, den generierten Inhalt zu identifizieren und zu verwenden, und verteilen Sie die generierten schädlichen Inhalte nicht im Internet.
Dieses Projekt wird mit Qlora geschult. Das Lora -Gewicht und das kombinierte Gewichtsmodell sind jeweils Open Source. Sie können entsprechend Ihren Anforderungen herunterladen:
| Modellname | Modellgröße | Adresse herunterladen | Bemerkung |
|---|---|---|---|
| Chinese-Mixtral-8x7b | 88 GB | Umarmung ModelsCope | Das vollständige chinesische Wortlistenmodell kann direkt verwendet werden |
| Chinese-Mixtral-8x7b-Adapter | 2,7 GB | Umarmung | Lora-Gewichte müssen mit dem ursprünglichen Mixtral-8x7b zusammengeführt werden, bevor sie verwendet werden können. Weitere Informationen finden Sie im Zusammenführungsskript hier. |
Das chinesische Mixtral-8x7b unterstützt das vollständige Mixtral-8x7b-Modell-Ökosystem, einschließlich der Verwendung vLLM und Flash Attention 2 für die Beschleunigung, die Verwendung bitsandbytes zur Modellquantisierung usw. Hier finden Sie ein Code-Beispiel für die Argumentation mit chinesischem mixtral-8x7b.
Verwenden von Flash -Aufmerksamkeit 2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Quantifizierung mit 4bit:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Bitte beachten Sie, dass chinesische Mixtral-8x7b ein Basismodell ist und durch Anweisungen nicht fein abgestimmt wurde, sodass die Compliance-Funktionen der Anweisung begrenzt sind. Sie können sich auf den Feinabschnitt beziehen, um das Modell zu optimieren.
Wir haben die folgenden Bewertungsdatensätze verwendet, um chinesisch-mixtral-8x7b separat zu bewerten:
Laut einem von Mistral veröffentlichten technischen Bericht aktiviert der MixTral-8x7b den 13B-Parameter bei Inferenz. Die folgende Tabelle zeigt die 5-Shot-Ergebnisse von chinesischem Mixtral-8x7b und anderen 13B-Modellen des chinesischen Wortausdehnungs in jedem Evaluierungsdatensatz:
| Modellname | Inkrementelles Trainingsmaterial | C-Eval (Chinesisch) | CMMLU (Chinesisch) | MMLU (Englisch) | Hellaswag (Englisch) |
|---|---|---|---|---|---|
| Idee-ccnl/ziya2-13b-base | 650B Token | 59.29 | 60.93 | 59,86 | 58.90 |
| TigerResearch/Tigerbot-13b-Base-V3 | 500B Token | 50.52 | 51.65 | 53.46 | 59.16 |
| Linly-AI/Chinese-Llama-2-13B-HF | 11b Token | 42,57 | 41.95 | 51.32 | 59.05 |
| HFL/Chinese-Llama-2-13b | Ca. 30B Token (120 GB) | 41.90 | 42.08 | 51.92 | 59,28 |
| Chinese-Mixtral-8x7b (dieses Projekt) | 42B Token | 52.08 | 51.08 | 69,80 | 65.69 |
In Bezug auf das chinesische Wissen und das chinesische Verständnis ist unsere chinesische Mixtral-8x7b mit der Leistung der Tigerbot-13b-Base-V3 vergleichbar. Da die Anzahl der Trainingsdaten von chinesischem Mixtral-8x7b nur 8% der von Tigerbot-13b-Base-V3 beträgt, verfügt unser Modell immer noch Raum für weitere Verbesserungen. Gleichzeitig hat unser chinesisches Mixtral-8x7b dank der leistungsstarken Leistung des ursprünglichen Mixtral-8x7b-Modells die stärkste englische Ebene jedes Wortlistenmodells erreicht.
Aufgrund der subtilen Unterschiede in den Implementierungsdetails der Bewertungsskripte in verschiedenen Versionen, um die Konsistenz und Fairness der Evaluierungsergebnisse zu gewährleisten, verwenden unsere Evaluierungsskripte die von Eleutherai veröffentlichte LM-Evaluierungshärte, und der Commit Hash ist 28EC7FA.
Die folgende Tabelle zeigt die Erzeugungseffekte jedes Wort -Expansionsmodells. Da der vorgebildete Korpus einiger Modelle nicht durch eos_token getrennt ist, verwenden wir max_tokens = 100 um den generierten Text abzuschneiden. Unsere Stichprobenparameter sind temperature = 0.8, top_p = 0.9 .

Für die chinesische Codierung und Dekodierungseffizienz haben wir den Wortsegmentierer jedes Wortlistenmodells verwendet, um eine Scheibe des Skypile-Datensatzes (2023-06_Zh_head_0000.jsonl) zu codieren und die chinesische Text-Token-Menge zu vergleichen, die nach jedem Wortsegmentierer ausgegeben wurde:
| Modellname | Modellkategorie | Wortschatzgröße | Token -Menge im chinesischen Text | Codec -Effizienz |
|---|---|---|---|---|
| meta-llama/lama-2-13b-hf | Lama | 32000 | 780 m | Niedrig |
| Mistralai/Mixtral-8x7b-V0.1 | Mixtral | 32000 | 606 m | Niedrig |
| Linly-AI/Chinese-Llama-2-13B-HF | Lama | 40076 | 532 m | Mitte |
| Idee-ccnl/ziya2-13b-base | Lama | 39424 | 532 m | Mitte |
| HFL/Chinese-Llama-2-13b | Lama | 55296 | 365 m | hoch |
| TigerResearch/Tigerbot-13b-Base-V3 | Lama | 65112 | 342 m | hoch |
| Chinese-Mixtral-8x7b (dieses Projekt) | Mixtral | 57000 | 355 m | hoch |
Unter dem Testtext von ca. 1,4 GB ist unsere chinesische Mixtral-8x7b-chinesische Codec-Effizienz nur für Tigerbot-13b-Base-V3 an zweiter Stelle, was 41,5% höher ist als das ursprüngliche Modell. Dies ist förderlich, um die Inferenzgeschwindigkeit chinesischer Texte zu beschleunigen und die Sequenzlänge in Szenarien wie das Lernen des Kontextes und die Gedankenkette zu sparen, was der Verbesserung der Leistung komplexer Inferenzaufgaben förderlich ist.
Wir verwenden sentencepiece , um das chinesische BPE -Vokabular für 12G -Zhihu -Daten und 2G -Aufklärungsdaten zu trainieren. Bei der Ausbildung der Vokabularliste haben wir die Anzahl der chinesischen Einzelwörter-Token und die Gesamtzahl der chinesischen Token aufgezählt und die beiden kombiniert, um Hunderte von Vokabellenlisten mit unterschiedlichen Größen und Inhalten zu erhalten. Um die am besten geeignete Vokabularliste zu erhalten, haben wir die von Zheng Bo et al. ALP ist ein bequemer und schneller Indikator, um die Vokabularfähigkeit einer bestimmten Sprache zu messen, indem die Granularität von Subwörtern in einer bestimmten Sprache berechnet und die Subwords der mittleren und niedrigen Frequenz der Vokabularliste bestraft werden.
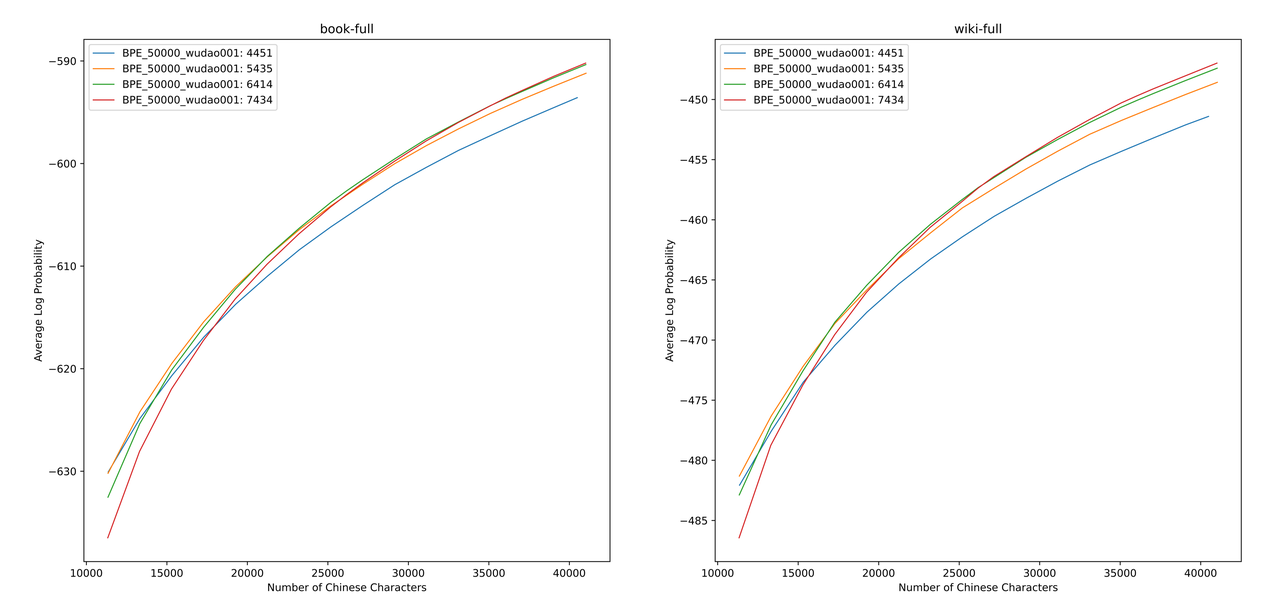
Wir haben die ALP -Werte für verschiedene Vokabularlisten zu Büchern und Encyclopedia Corpus bewertet. In der Abbildung repräsentieren die vier Kurven die Wortliste von vier chinesischen Einwort-Token (4451, 5435, 6414 und 7434). Um die zu kleine chinesische Kompressionsrate und die zu spärliche Einbettungsschicht zu vermeiden, wählen wir den Beugungspunkt der ALP -Kurve aus, die der Vokabelliste 25.000 chinesische Token hinzufügen. Auf dieser Basis haben wir den größten ALP unter den vier Kurven ausgewählt, dh die Vokabularliste von 6414 chinesischen Einzel-Wort-Token als endgültige Vokabularliste hinzugefügt, die von chinesischem Mixtral-8x7b ausgewählt wurde.
Nachdem wir das neue Vokabular erhalten haben, müssen wir die Einbettung und LM_HEAD -Schichten erweitern und initialisieren. Wir initialisieren die Expansion mit dem Wort einbettenden Durchschnitt des neuen Tokens in der alten Einbettungsschicht. In unseren vorherigen Experimenten ist dieser Ansatz etwas besser als die Standardimplementierung von Huggingface, d. H. Die Initialisierung wird unter Verwendung einer festen Normalverteilung durchgeführt.
Das Mixtral-8x7b-Modell hat ein Parametervolumen von 46,7b. Das vollständige Parametertraining erfordert die Verwendung mehrerer paralleler Strategien gleichzeitig. Die Zeitkosten sind zu hoch, wenn die Schulungsressourcen begrenzt sind. Daher verwenden wir die offiziell empfohlene Methode, indem wir das Modell mit Qlora trainieren. Basierend auf der LORA-Zerlegung mit niedriger Rang reduziert Qlora den für das Training erforderlichen Videospeicher weiter und behält die Leistung bei der Einführung von 4-Bit-Quantisierung, doppelter Quantisierung und Verwendung von NVIDIA Unified Memory für das Paging weiter mit vollem Parametertraining.
Wir verweisen auf die Einstellungen von Lora durch Yiming Cui et al., Wenden Sie eine geringe Zerlegung auf alle linearen Schichten des ursprünglichen Modells an und setzen die Parameter der amplifizierten Einbettung und LM_head-Schichten, um trainierbar zu sein. Für die Modellkörper verwenden wir das NF4 -Format zur Quantisierung, wodurch die quantisierten Daten die gleiche Datenverteilung wie vor der Quantisierung aufweisen und der Verlust des Gewichtsinformationsverlusts des Modells geringer ist.
Wir empfehlen die Verwendung von Python 3.10 + Torch 2.0.1
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolationWir haben chinesisch-mixtral-8x7b basierend auf dem vorhandenen Open-Source-Datensatz geschult, einschließlich:
| Datensatzname | Datensatzsprache | Die verwendete Datenmenge | Bemerkung |
|---|---|---|---|
| Skywork/Skypile-150b | chinesisch | 30b | Verwenden Sie nur Daten von 2022 + 2023 |
| Dkyoon/Slimpajama-6b | Englisch | 12b | Datensatz Duplizierung 2 Epoche |
Laden Sie den Datensatz über data/download.py in data herunter. Für den Slimpajama -Datensatz müssen Sie data/parquet2jsonl.py verwenden, um das ursprüngliche Datensatz in das jsonl -Format umzuwandeln.
Der heruntergeladene Datensatz ist ein Shard mehrerer JSONL -Dateien. Verwenden Sie cat , um mehrere Scherben in eine JSONL -Datei zusammenzuführen.
$ cat * .jsonl > all.jsonl split JSONL in Zug und gültige Sammlungen. Das Verhältnis von Zug und gültigen Linien in diesem Projekt beträgt 999: 1.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl Registrieren Sie den Datensatznamen und Pfad in data/datasets.toml :
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置Verwenden Sie data/preprocess_datasets.py um das Datensatz zu subword -segment zu subword -segment, um das Training zu beschleunigen.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab Nach der Durchführung der Subword -Segmentierung können Sie data/utils.py verwenden, um die gesamten Token jedes Datensatzes anzuzeigen:
$ python data/utils.py Das Trainingsstartskript ist scripts/train.sh . Das Trainingsdatensatz und das Datensatzverhältnis können geändert werden, indem TRAIN_DATASETS geändert werden:
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) Wenn Sie das Slurm Cluster -Managementsystem verwenden, können Sie es über sbatch einreichen:
$ sbatch scripts/train-pt.sh Wenn Sie nicht über die Befehlszeile mit dem Training mit dem Training beginnen möchten, können Sie torchrun direkt in scripts/train-pt.sh extrahieren, um mit dem Training zu beginnen.
Das für die Feinabstimmung erforderliche Datensatzformat ähnelt der Vorausbildung. Die Dataset -Datei muss im JSONL -Format vorliegen: ein JSON pro Zeile, der das Feld "text" enthalten und die Anweisung, den Eingang und die Ausgabe entsprechend der benötigten Vorlage spleißen muss.
Anschließend müssen Sie den Datensatznamen und den Pfad in data/datasets.toml registrieren.
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 Das Trainingsstartskript ist scripts/train-sft.sh . Das Trainingsdatensatz und das Datensatzverhältnis können geändert werden, indem TRAIN_DATASETS geändert werden:
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) Wenn Sie das Slurm Cluster -Managementsystem verwenden, können Sie es über sbatch einreichen:
$ sbatch scripts/train-sft.sh Wenn Sie nicht über die Befehlszeile mit dem Training mit dem Training beginnen möchten, können Sie torchrun direkt in scripts/train-sft.sh extrahieren, um mit dem Training zu beginnen.
Wenn Sie der Meinung sind, dass dieses Projekt für Ihre Recherche hilfreich ist oder den Code dieses Projekts verwenden, lesen Sie bitte dieses Projekt:
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

