Chinese Mixtral 8x7B
1.0.0

Proyek ini didasarkan pada model mixtral-8x7b yang dirilis oleh Mistral, dan diharapkan untuk lebih mempromosikan studi model MOE oleh komunitas pemrosesan bahasa alami Cina. Daftar kosa kata kami yang diperluas secara signifikan meningkatkan efisiensi pengkodean dan decoding model Cina, dan melakukan pra-pelatihan tambahan dari model daftar kosa kata yang diperluas melalui korpus open source skala besar, sehingga model tersebut memiliki generasi Cina yang kuat dan kemampuan pemahaman.
Proyek Konten Sumber Terbuka:
Harap dicatat bahwa China-Mixtral-8x7b mungkin masih menghasilkan balasan menyesatkan yang mengandung kesalahan faktual atau konten berbahaya yang mengandung bias/diskriminasi. Harap berhati -hati untuk mengidentifikasi dan menggunakan konten yang dihasilkan dan jangan menyebarkan konten berbahaya yang dihasilkan ke Internet.
Proyek ini dilatih menggunakan qlora. Berat Lora dan model berat gabungan masing -masing adalah open source. Anda dapat memilih untuk mengunduh sesuai dengan kebutuhan Anda:
| Nama model | Ukuran model | Alamat unduhan | Komentar |
|---|---|---|---|
| China-mixtral-8x7b | 88GB | Huggingface Modelscope | Model daftar kata Cina lengkap, dapat digunakan secara langsung |
| Adaptor China-Mixtral-8x7b | 2.7GB | Huggingface | Bobot Lora perlu digabungkan dengan Mixtral-8x7b asli sebelum dapat digunakan. Silakan merujuk ke skrip gabungan di sini. |
China-mixtral-8x7b mendukung ekosistem model Mixtral-8x7b lengkap, termasuk menggunakan vLLM dan Flash Attention 2 untuk akselerasi, menggunakan bitsandbytes untuk kuantisasi model, dll. Berikut adalah contoh kode untuk penalaran menggunakan China-Mixtral-8x7b.
Menggunakan perhatian flash 2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Kuantifikasi Menggunakan 4bit:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Harap dicatat bahwa China-Mixtral-8x7b adalah model dasar dan belum disempurnakan oleh instruksi, sehingga kemampuan kepatuhan instruksi terbatas. Anda dapat merujuk ke bagian fine-tuning untuk menyempurnakan model.
Kami menggunakan set data evaluasi berikut untuk mengevaluasi China-Mixtral-8x7b secara terpisah:
Menurut laporan teknis yang dirilis oleh Mistral, Mixtral-8x7b akan mengaktifkan parameter 13B saat inferensi. Tabel berikut menunjukkan hasil 5-shot dari Model Ekspansi Kata Cina-Mixtral-8x dan 13B lainnya pada setiap dataset evaluasi:
| Nama model | Materi pelatihan tambahan | C-eval (Cina) | Cmmlu (Cina) | Mmlu (Bahasa inggris) | Hellaswag (Bahasa inggris) |
|---|---|---|---|---|---|
| IDEA-CCNL/ZIYA2-13B-BASE | Token 650b | 59.29 | 60.93 | 59.86 | 58.90 |
| TigerResearch/Tigerbot-13b-Base-V3 | Token 500B | 50.52 | 51.65 | 53.46 | 59.16 |
| Linly-Ai/China-llama-2-13b-hf | 11b token | 42.57 | 41.95 | 51.32 | 59.05 |
| hfl/cina-llama-2-13b | Sekitar 30b token (120GB) | 41.90 | 42.08 | 51.92 | 59.28 |
| China-mixtral-8x7b (proyek ini) | 42b token | 52.08 | 51.08 | 69.80 | 65.69 |
Dalam hal pengetahuan dan pemahaman Tiongkok, Cina-Mixtral-8x7b kami sebanding dengan kinerja TigerBot-13B-BASE-V3. Karena jumlah data pelatihan China-Mixtral-8x7b hanya 8% dari Tigerbot-13b-Base-V3, model kami masih memiliki ruang untuk perbaikan lebih lanjut. Pada saat yang sama, berkat kinerja yang kuat dari model Mixtral-8x7b asli, Cina-Mixtral-8x7b kami telah mencapai tingkat bahasa Inggris terkuat dari setiap model daftar kata.
Karena perbedaan halus dalam rincian implementasi skrip evaluasi dalam versi yang berbeda, untuk memastikan konsistensi dan keadilan hasil evaluasi, skrip evaluasi kami menggunakan LM-evaluasi-harness yang dikeluarkan oleh eleutherai, dan hash komit adalah 28ec7fa.
Tabel berikut menunjukkan efek pembuatan dari setiap model ekspansi kata. Karena korpus pra-terlatih dari beberapa model tidak dipisahkan oleh eos_token , kami menggunakan max_tokens = 100 untuk memotong teks yang dihasilkan. Parameter pengambilan sampel kami adalah temperature = 0.8, top_p = 0.9 .

Untuk efisiensi pengkodean dan decoding Cina, kami menggunakan kata segmenter dari setiap model daftar kata untuk menyandikan sepotong dataset Skypile (2023-06_ZH_HEAD_0000.JSONL) dan membandingkan output jumlah token teks Cina oleh setiap segmenter kata:
| Nama model | Kategori model | Ukuran kosa kata | Kuantitas token dalam teks Cina | Efisiensi codec |
|---|---|---|---|---|
| Meta-llama/llama-2-13b-hf | Llama | 32000 | 780m | Rendah |
| MISTRALAI/MIXTRAL-8X7B-V0.1 | Mixtral | 32000 | 606m | Rendah |
| Linly-Ai/China-llama-2-13b-hf | Llama | 40076 | 532m | tengah |
| IDEA-CCNL/ZIYA2-13B-BASE | Llama | 39424 | 532m | tengah |
| hfl/cina-llama-2-13b | Llama | 55296 | 365m | tinggi |
| TigerResearch/Tigerbot-13b-Base-V3 | Llama | 65112 | 342m | tinggi |
| China-mixtral-8x7b (proyek ini) | Mixtral | 57000 | 355m | tinggi |
Di antara teks uji sekitar 1,4GB, efisiensi codec Cina-mixtral-8x7b kami adalah yang kedua setelah Tigerbot-13b-base-V3, yang 41,5% lebih tinggi dari model aslinya. Ini kondusif untuk mempercepat kecepatan inferensi teks-teks Cina, dan menghemat panjang urutan dalam skenario seperti pembelajaran dalam konteks dan rantai-pemikiran, yang kondusif untuk meningkatkan kinerja tugas inferensi yang kompleks.
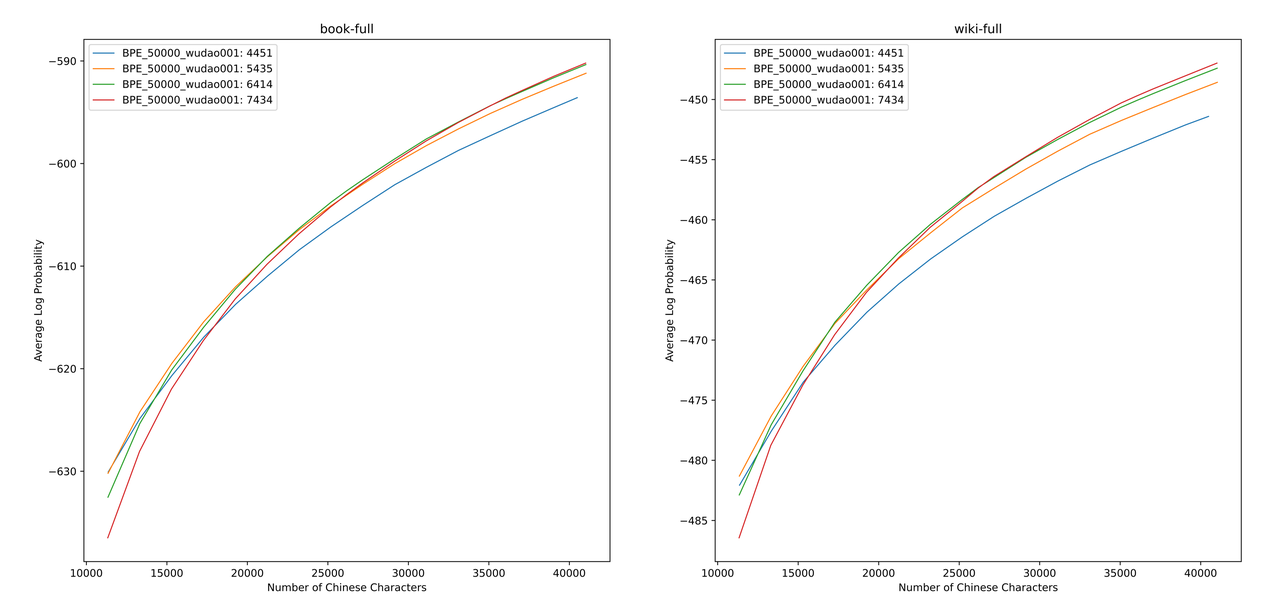
Kami menggunakan sentencepiece untuk melatih kosa kata BPE Cina pada data 12G Zhihu dan data Pencerahan 2G. Saat melatih daftar kosakata, kami menyebutkan jumlah token kata tunggal Cina dan jumlah total token Cina, dan menggabungkan keduanya untuk mendapatkan ratusan daftar kosakata dengan ukuran dan konten yang berbeda. Untuk mendapatkan daftar kosa kata yang paling cocok, kami menghitung kemampuan kosa kata Cina dari daftar kosa kata ini melalui ALP yang diusulkan oleh Zheng Bo et al. ALP adalah indikator yang nyaman dan cepat untuk mengukur kemampuan kosa kata dari bahasa tertentu dengan menghitung granularitas subword dalam bahasa tertentu dan menghukum subword frekuensi menengah dan rendah dari daftar kosa kata.
Kami mengevaluasi nilai ALP untuk daftar kosakata yang berbeda di buku dan ensiklopedia corpus. Dalam ilustrasi, empat kurva mewakili kata daftar empat token kata tunggal Cina (4451, 5435, 6414 dan 7434). Untuk menghindari laju kompresi Cina yang terlalu kecil, dan lapisan embedding yang terlalu jarang, kami memilih titik infleksi kurva ALP, yang akan menambah 25.000 token Cina ke daftar kosa kata. Atas dasar ini, kami memilih ALP terbesar di antara empat kurva, yaitu, daftar kosakata 6414 token kata tunggal Cina ditambahkan sebagai daftar kosa kata terakhir yang dipilih oleh China-Mixtral-8x7b.
Setelah mendapatkan kosakata baru, kita perlu memperluas dan menginisialisasi lapisan embedding dan LM_HEAD. Kami menginisialisasi ekspansi menggunakan kata rata -rata embedding dari token baru di lapisan embedding lama. Dalam percobaan kami sebelumnya, pendekatan ini sedikit lebih baik daripada implementasi default HuggingFace, yaitu inisialisasi dilakukan dengan menggunakan distribusi normal tetap.
Model Mixtral-8x7b memiliki volume parameter 46.7b. Pelatihan parameter penuh membutuhkan penggunaan beberapa strategi paralel secara bersamaan. Biaya waktu terlalu tinggi ketika sumber daya pelatihan terbatas. Oleh karena itu, kami menggunakan metode ini secara resmi direkomendasikan oleh Huggingface untuk melatih model menggunakan Qlora. Berdasarkan dekomposisi Lora Low-Rank, Qlora lebih lanjut mengurangi memori video yang diperlukan untuk pelatihan dan mempertahankan kinerja yang sebanding dengan pelatihan parameter penuh dengan memperkenalkan kuantisasi 4-bit, kuantisasi ganda dan menggunakan memori unified NVIDIA untuk paging.
Kami merujuk pada pengaturan lora dengan yiming cui et al., Menerapkan dekomposisi peringkat rendah untuk semua lapisan linier dari model asli, dan mengatur parameter dari embedding yang diamplifikasi dan lapisan LM_HEAD untuk dapat dilatih. Untuk badan model, kami menggunakan format NF4 untuk kuantisasi, yang dapat membuat data terkuantisasi memiliki distribusi data yang sama seperti sebelum kuantisasi, dan kehilangan informasi berat model lebih sedikit.
Kami merekomendasikan menggunakan Python 3.10 + Torch 2.0.1
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolationKami melatih Cina-mixtral-8x7b berdasarkan dataset open source yang ada, yang meliputi:
| Nama dataset | Bahasa dataset | Jumlah data yang digunakan | Komentar |
|---|---|---|---|
| Skywork/Skypile-150b | Cina | 30b | Gunakan hanya data dari 2022 + 2023 |
| DKYOON/SLIMPAJAMA-6B | Bahasa inggris | 12b | Duplikasi dataset 2 zaman |
Unduh dataset ke dalam data melalui data/download.py . Untuk dataset Slimpajama, Anda perlu menggunakan data/parquet2jsonl.py untuk mengonversi dataset asli ke format jsonl .
Dataset yang diunduh adalah pecahan beberapa file JSONL. Gunakan cat untuk menggabungkan beberapa pecahan menjadi satu file JSONL.
$ cat * .jsonl > all.jsonl split JSONL menjadi kereta dan koleksi yang valid. Rasio kereta dan jalur yang valid dalam proyek ini adalah 999: 1.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl Daftarkan nama dataset dan jalur ke dalam data/datasets.toml :
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置Gunakan data/preprocess_datasets.py ke subword Segment Dataset untuk mempercepat pelatihan.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab Setelah melakukan segmentasi subword, Anda dapat menggunakan data/utils.py untuk melihat token total dari setiap dataset:
$ python data/utils.py Script startup pelatihan adalah scripts/train.sh . Dataset pelatihan dan rasio dataset dapat dimodifikasi dengan memodifikasi TRAIN_DATASETS :
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) Jika Anda menggunakan sistem manajemen cluster slurm, Anda dapat mengirimkannya melalui sbatch :
$ sbatch scripts/train-pt.sh Jika Anda tidak memiliki Slurm atau ingin memulai pelatihan melalui baris perintah, Anda dapat secara langsung mengekstrak torchrun dalam scripts/train-pt.sh untuk memulai pelatihan.
Format dataset yang diperlukan untuk fine-tuning mirip dengan pra-pelatihan. File dataset harus dalam format JSONL: satu JSON per baris, yang perlu berisi bidang "text" , dan menyambungkan instruksi, input dan output sesuai dengan templat yang Anda butuhkan.
Maka Anda perlu mendaftarkan nama dataset dan jalur ke data/datasets.toml :
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 Script startup pelatihan adalah scripts/train-sft.sh . Dataset pelatihan dan rasio dataset dapat dimodifikasi dengan memodifikasi TRAIN_DATASETS :
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) Jika Anda menggunakan sistem manajemen cluster slurm, Anda dapat mengirimkannya melalui sbatch :
$ sbatch scripts/train-sft.sh Jika Anda tidak memiliki Slurm atau ingin memulai pelatihan melalui baris perintah, Anda dapat secara langsung mengekstrak torchrun dalam scripts/train-sft.sh untuk memulai pelatihan.
Jika Anda merasa proyek ini bermanfaat untuk penelitian Anda atau menggunakan kode proyek ini, silakan merujuk ke proyek ini:
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

