Chinese Mixtral 8x7B
1.0.0

يعتمد هذا المشروع على نموذج MIXTRAL-8X7B الذي تم إصداره بواسطة MISTRAL ، ومن المتوقع أن يعزز دراسة نموذج MOE من قبل مجتمع معالجة اللغة الطبيعية الصينية. تعمل قائمة المفردات الموسعة على تحسين كفاءة ترميز النموذج والرسم الصيني بشكل كبير ، وتؤدي تدريبات تدريبية تدريبية على نموذج قائمة المفردات الموسعة من خلال مجموعة مصادر مفتوحة على نطاق واسع ، بحيث يكون للنموذج جيلًا صينيًا قويًا وقدرات فهم.
محتوى المشروع مفتوح المصدر:
يرجى ملاحظة أن الصينيين-mixtral-8x7b قد لا يزال يولد ردود مضللة تحتوي على أخطاء واقعية أو محتوى ضار يحتوي على التحيز/التمييز. يرجى توخي الحذر من تحديد المحتوى الذي تم إنشاؤه واستخدامه وعدم نشر المحتوى الضار الذي تم إنشاؤه على الإنترنت.
تم تدريب هذا المشروع باستخدام Qlora. وزن Lora ونموذج الوزن المشترك مفتوح المصدر على التوالي. يمكنك اختيار التنزيل وفقًا لاحتياجاتك:
| اسم النموذج | حجم النموذج | تنزيل عنوان | ملاحظة |
|---|---|---|---|
| صينية ميكرول -8 × 7 ب | 88 جيجابايت | luggingface موديلات | إكمال نموذج قائمة الكلمات الصينية ، يمكن استخدامه مباشرة |
| صينية ميلاطال -8 × 7B-ADAPTER | 2.7 جيجابايت | luggingface | يجب دمج أوزان Lora مع Mixtral-8x7B الأصلي قبل استخدامها. يرجى الرجوع إلى البرنامج النصي دمج هنا. |
يدعم الصينية-mixtral-8x7b النظام الإيكولوجي الكامل Mixtral-8x7B ، بما في ذلك استخدام vLLM و Flash Attention 2 للتسارع ، باستخدام bitsandbytes لتحديد الكميات النموذجية ، وما إلى ذلك ، فيما يلي مثال على الكود للاستفادة من استخدام mixtral-8x7b.
باستخدام انتباه الفلاش 2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))الكمية باستخدام 4bit:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))يرجى ملاحظة أن الصينيين-mixtral-8x7b هو نموذج أساسي ولم يتم ضبطه من خلال الإرشادات ، وبالتالي فإن إمكانات الامتثال للتعليمات محدودة. يمكنك الرجوع إلى قسم الضبط لضبط النموذج.
استخدمنا مجموعات بيانات التقييم التالية لتقييم صيني-ixtral-8x7b بشكل منفصل:
وفقًا لتقرير فني أصدرته MISTRAL ، سيقوم Mixtral-8x7B بتنشيط المعلمة 13B عند الاستدلال. يوضح الجدول التالي نتائج 5 طلقات من النماذج الصينية-8x7b ونماذج توسيع الكلمات الصينية الأخرى على نطاق 13B على كل مجموعة بيانات تقييم:
| اسم النموذج | مواد التدريب الإضافي | ج (الصينية) | CMMLU (الصينية) | mmlu (إنجليزي) | Hellaswag (إنجليزي) |
|---|---|---|---|---|---|
| IDEA-CCNL/ZIYA2-13B-base | رمز 650B | 59.29 | 60.93 | 59.86 | 58.90 |
| Tigerresearch/Tigerbot-13B-Base-V3 | رمز 500B | 50.52 | 51.65 | 53.46 | 59.16 |
| Linly-AI/الصينية-لاما 2-13B-HF | رمز 11B | 42.57 | 41.95 | 51.32 | 59.05 |
| HFL/الصينية لاما 2-13B | حوالي 30B رمزية (120 جيجابايت) | 41.90 | 42.08 | 51.92 | 59.28 |
| صيني ميكسترال -8x7b (هذا المشروع) | الرمز المميز 42B | 52.08 | 51.08 | 69.80 | 65.69 |
فيما يتعلق بالمعرفة الصينية والتفاهم ، فإن صينينا-8x7b قابلة للمقارنة مع أداء Tigerbot-13B-Base-V3. نظرًا لأن كمية التدريب على بيانات التدريب الخاصة بـ Mixtral-8x7B هي 8 ٪ فقط من Tigerbot-13B-Base-V3 ، لا يزال نموذجنا لديه مجال لمزيد من التحسن. في الوقت نفسه ، وذلك بفضل الأداء القوي لنموذج Mixtral-8x7B الأصلي ، وصلنا الصيني Mixtral-8x7B إلى أقوى مستوى إنجليزي لكل نموذج قائمة الكلمات.
نظرًا للاختلافات الدقيقة في تفاصيل تنفيذ البرامج النصية للتقييم في إصدارات مختلفة ، من أجل ضمان اتساق نتائج التقييم والإنصاف ، تستخدم نصوص التقييم الخاصة بنا خلاصة التقييم LM الصادرة عن Eleutherai ، وتجزئة الالتزام 28ec7fa.
يوضح الجدول التالي تأثيرات توليد كل نموذج توسيع كلمة. نظرًا لأن المجموعة التي تم تدريبها مسبقًا لبعض النماذج لا يتم فصلها بواسطة eos_token ، فإننا نستخدم max_tokens = 100 لاقتطاع النص الذي تم إنشاؤه. معلمات أخذ العينات لدينا هي temperature = 0.8, top_p = 0.9 .

بالنسبة لكفاءة الترميز الصينية وفك التشفير ، استخدمنا مقطع الكلمات لكل نموذج قائمة كلمات لترميز شريحة من مجموعة بيانات Skypile (2023-06_zh_head_0000.jsonl) ومقارنة إخراج رمز النص الصيني بواسطة كل قطعة كلمة:
| اسم النموذج | فئة النموذج | حجم المفردات | كمية رمزية في النص الصيني | كفاءة الترميز |
|---|---|---|---|---|
| meta-llama/llama-2-13b-hf | لاما | 32000 | 780 م | قليل |
| MISTRALAI/MIXTRAL-8X7B-V0.1 | mixtral | 32000 | 606m | قليل |
| Linly-AI/الصينية-لاما 2-13B-HF | لاما | 40076 | 532M | وسط |
| IDEA-CCNL/ZIYA2-13B-base | لاما | 39424 | 532M | وسط |
| HFL/الصينية لاما 2-13B | لاما | 55296 | 365m | عالي |
| Tigerresearch/Tigerbot-13B-Base-V3 | لاما | 65112 | 342 متر | عالي |
| صيني ميكسترال -8x7b (هذا المشروع) | mixtral | 57000 | 355 م | عالي |
من بين نص الاختبار الذي يبلغ حوالي 1.4 جيجابايت ، فإن كفاءة الترميز الصينية الصينية -8 × 7 ب هي المرتبة الثانية بعد Tigerbot-13B-Base-V3 ، وهو أعلى بنسبة 41.5 ٪ من النموذج الأصلي. هذا يفضي إلى تسريع سرعة الاستدلال للنصوص الصينية ، وتوفير طول التسلسل في سيناريوهات مثل التعلم داخل السياق وسلسلة الفكرة ، والتي تفضي إلى تحسين أداء مهام الاستدلال المعقدة.
نستخدم sentencepiece لتدريب المفردات الصينية BPE على بيانات Zhihu 12G وبيانات التنوير 2G. عند تدريب قائمة المفردات ، قمنا بتعيين عدد الرموز المفردة من كلمة واحدة والعدد الإجمالي للرموز الصينية ، ونجمع بين الاثنين للحصول على مئات من قوائم المفردات بأحجام ومحتويات مختلفة. من أجل الحصول على قائمة المفردات الأنسب ، قمنا بحساب قدرة المفردات الصينية لقوائم المفردات هذه من خلال ALP التي اقترحها Zheng Bo et al. ALP هو مؤشر مناسب وسريع لقياس قدرة المفردات للغة المحددة من خلال حساب تفريغ الكلمات الفرعية بلغة معينة ومعاقبة الكلمات الفرعية المتوسطة والمنخفضة في قائمة المفردات.
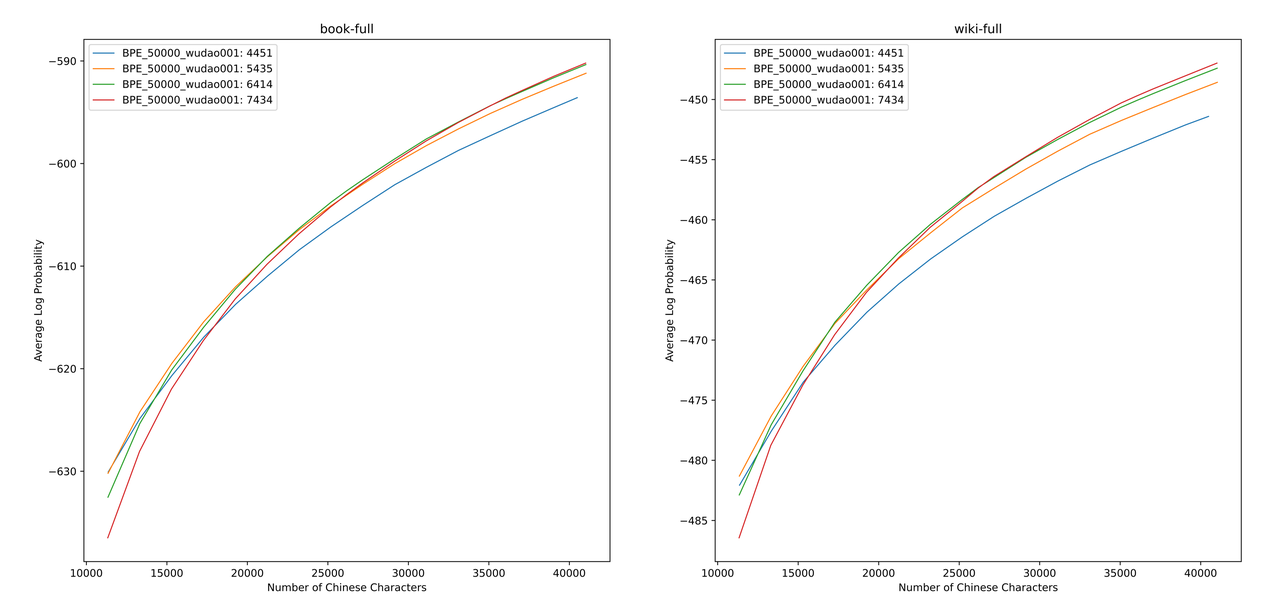
قمنا بتقييم قيم ALP لقوائم المفردات المختلفة على الكتب و Encyclopedia Corpus. في الرسم التوضيحي ، تمثل المنحنيات الأربعة قائمة الكلمات المكونة من أربعة رموز صينية واحدة (4451 و 5435 و 6414 و 7434). من أجل تجنب معدل الضغط الصيني الذي يكون صغيرًا جدًا ، وطبقة التضمين المتفرقة للغاية ، نختار نقطة انعطاف منحنى ALP ، والتي ستضيف 25000 رمز صيني إلى قائمة المفردات. على هذا الأساس ، اخترنا أكبر ALP من بين المنحنيات الأربعة ، أي قائمة المفردات التي تضم 6414 رموز كلمة واحدة صينية واحدة تم إضافة قائمة المفردات النهائية التي تم اختيارها بواسطة صيني Mixtral-8x7B.
بعد الحصول على المفردات الجديدة ، نحتاج إلى توسيع وتهيئة طبقات التضمين و LM_HEAD. نقوم بتهيئة التوسع باستخدام كلمة تضمين متوسط الرمز الجديد في طبقة التضمين القديمة. في تجاربنا السابقة ، يكون هذا النهج أفضل قليلاً من التنفيذ الافتراضي لـ Huggingface ، أي يتم تنفيذ التهيئة باستخدام توزيع طبيعي ثابت.
يحتوي نموذج Mixtral-8x7B على حجم المعلمة 46.7 ب. يتطلب التدريب الكامل للمعلمة استخدام استراتيجيات متوازية متعددة في نفس الوقت. تكلفة الوقت مرتفعة للغاية عندما تكون موارد التدريب محدودة. لذلك ، نستخدم الطريقة الموصى بها رسميًا من خلال Huggingface لتدريب النموذج باستخدام Qlora. استنادًا إلى تحلل LORA منخفضة الرتبة ، يقلل Qlora من ذاكرة الفيديو المطلوبة للتدريب والحفاظ على الأداء المشابه للتدريب الكامل المعمداني من خلال تقديم كمية 4 بت ، والتكميات المزدوجة واستخدام الذاكرة الموحدة NVIDIA للترحيل.
نشير إلى إعدادات Lora بواسطة Yiming Cui et al. ، ونطبق التحلل المنخفض على الرتبة على جميع الطبقات الخطية للنموذج الأصلي ، وضبط معلمات التضخيم المتضخمة وطبقات LM_Head لتكون قابلة للتدريب. بالنسبة لجسم النموذج ، نستخدم تنسيق NF4 للتحديد الكمي ، والذي يمكن أن يجعل البيانات الكمية لها نفس توزيع البيانات كما كان من قبل ، وفقد معلومات وزن النموذج أقل.
نوصي باستخدام Python 3.10 + Torch 2.0.1
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolationلقد قمنا بتدريب الصينيين-ميكسترال -8x7b استنادًا إلى مجموعة البيانات المفتوحة المصدر الحالية ، والتي تشمل:
| اسم مجموعة البيانات | لغة مجموعة البيانات | كمية البيانات المستخدمة | ملاحظة |
|---|---|---|---|
| Skywork/Skypile-150b | الصينية | 30 ب | استخدم البيانات فقط من 2022 + 2023 |
| Dkyoon/Slimpajama-6b | إنجليزي | 12 ب | تكرار مجموعة البيانات 2 عصر |
قم بتنزيل مجموعة البيانات في data عبر data/download.py . بالنسبة لمجموعة بيانات Slimpajama ، تحتاج إلى استخدام data/parquet2jsonl.py لتحويل مجموعة البيانات الأصلية إلى تنسيق jsonl .
مجموعة البيانات التي تم تنزيلها هي Shard من ملفات JSONL المتعددة. استخدم cat لدمج شظايا متعددة في ملف JSONL واحد.
$ cat * .jsonl > all.jsonl split JSONL في قطار ومجموعات صالحة. نسبة القطار والخطوط الصالحة في هذا المشروع هي 999: 1.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl قم بتسجيل اسم مجموعة البيانات والمسار في data/datasets.toml :
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置استخدم data/preprocess_datasets.py لقطاع مجموعة البيانات الفرعية لتسريع التدريب.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab بعد إجراء تجزئة الكلمات الفرعية ، يمكنك استخدام data/utils.py لعرض إجمالي الرموز المميزة لكل مجموعة بيانات:
$ python data/utils.py البرنامج النصي بدء التشغيل التدريبي هو scripts/train.sh . يمكن تعديل مجموعة بيانات التدريب ونسبة مجموعة البيانات عن طريق تعديل TRAIN_DATASETS :
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) إذا كنت تستخدم نظام إدارة Cluster Slurm ، فيمكنك إرساله من خلال sbatch :
$ sbatch scripts/train-pt.sh إذا لم يكن لديك slurm أو ترغب في البدء في التدريب عبر سطر الأوامر ، فيمكنك استخراج torchrun مباشرة في scripts/train-pt.sh لبدء التدريب.
يشبه تنسيق مجموعة البيانات المطلوبة لضبط الدقة المسبقة. يجب أن يكون ملف مجموعة البيانات بتنسيق JSONL: JSON واحد لكل سطر ، والذي يحتاج إلى احتواء حقل "text" ، وربط التعليمات والإدخال والإخراج وفقًا للقالب الذي تحتاجه.
ثم تحتاج إلى تسجيل اسم مجموعة البيانات والمسار في data/datasets.toml :
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 البرنامج النصي لبدء التشغيل التدريبي هو scripts/train-sft.sh . يمكن تعديل مجموعة بيانات التدريب ونسبة مجموعة البيانات عن طريق تعديل TRAIN_DATASETS :
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) إذا كنت تستخدم نظام إدارة Cluster Slurm ، فيمكنك إرساله من خلال sbatch :
$ sbatch scripts/train-sft.sh إذا لم يكن لديك slurm أو ترغب في البدء في التدريب عبر سطر الأوامر ، فيمكنك استخراج torchrun مباشرة في scripts/train-sft.sh لبدء التدريب.
إذا شعرت أن هذا المشروع مفيد لبحثك أو استخدم رمز هذا المشروع ، فيرجى الرجوع إلى هذا المشروع:
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

