Chinese Mixtral 8x7B
1.0.0

Ce projet est basé sur le modèle mixtral-8x7b publié par Mistral, et devrait promouvoir davantage l'étude du modèle MOE par la communauté de traitement du langage naturel chinois. Notre liste de vocabulaire élargie améliore considérablement l'efficacité du codage et du décodage du modèle et effectue une pré-formation incrémentielle du modèle de liste de vocabulaire élargi par le corpus open source à grande échelle, afin que le modèle ait de fortes capacités de génération et de compréhension chinoises.
Projet de contenu open source:
Veuillez noter que le chinois-mixtral-8x7b peut encore générer des réponses trompeuses contenant des erreurs factuelles ou un contenu nuisible contenant un biais / discrimination. Veuillez veiller à identifier et à utiliser le contenu généré et ne pas répartir le contenu nocif généré sur Internet.
Ce projet est formé à l'aide de Qlora. Le poids LORA et le modèle de poids combiné sont respectivement open source. Vous pouvez choisir de télécharger en fonction de vos besoins:
| Nom du modèle | Taille du modèle | Adresse de téléchargement | Remarque |
|---|---|---|---|
| Chinois-mixtral-8x7b | 88 Go | Étreinte Modelcope | Modèle complet de liste de mots chinois, peut être utilisé directement |
| Chinois-mixtral-8x7b-adapter | 2,7 Go | Étreinte | Les poids LORA doivent être fusionnés avec le mélange d'origine-8x7b avant de pouvoir être utilisés. Veuillez vous référer au script de fusion ici. |
Chinese-MIXTRAL-8X7B prend en charge l'écosystème complet du modèle Mixtral-8x7b, y compris en utilisant vLLM et Flash Attention 2 pour l'accélération, en utilisant bitsandbytes pour la quantification du modèle, etc. Voici un exemple de code pour le raisonnement en utilisant le chinois-mixtral-8x7b.
Utilisation de l'attention du flash 2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Quantification à l'aide de 4 bits:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Veuillez noter que le chinois-mixtral-8x7b est un modèle de base et n'a pas été affiné par les instructions, de sorte que les capacités de conformité des instructions sont limitées. Vous pouvez vous référer à la section de réglage fin pour affiner le modèle.
Nous avons utilisé les ensembles de données d'évaluation suivants pour évaluer séparément le chinois-mixtral-8x7b:
Selon un rapport technique publié par Mistral, le mixtral-8x7b activera le paramètre 13B lors de l'inférence. Le tableau suivant montre les résultats à 5 coups de chinois-mixtral-8x7b et d'autres modèles d'extension de mot chinois à l'échelle 13B sur chaque ensemble de données d'évaluation:
| Nom du modèle | Matériel de formation incrémentiel | C-Eval (Chinois) | Cmmlu (Chinois) | MMLU (Anglais) | Hellaswag (Anglais) |
|---|---|---|---|---|---|
| IDEA-CCNL / ZIYA2-13B-base | Jeton 650B | 59.29 | 60,93 | 59.86 | 58,90 |
| TigerResearch / Tigerbot-13b-Base-V3 | Jeton 500B | 50,52 | 51,65 | 53.46 | 59.16 |
| Linly-ai / chinois-llama-2-13b-hf | Token 11b | 42.57 | 41.95 | 51.32 | 59.05 |
| HFL / Chinese-Llama-2-13B | Environ 30B jeton (120 Go) | 41.90 | 42.08 | 51,92 | 59.28 |
| Chinois-mixtral-8x7b (ce projet) | Jeton 42B | 52.08 | 51.08 | 69.80 | 65.69 |
En termes de connaissances et de compréhension chinoises, notre chinois-mixtral-8x7b est comparable à la performance Tigerbot-13b-Base-V3. Étant donné que la quantité de données de formation de chinois-mixtral-8x7b ne représente que 8% de celle de Tigerbot-13b-Base-V3, notre modèle a toujours de la place pour une amélioration supplémentaire. Dans le même temps, grâce aux performances puissantes du modèle MIXTRAL-8X7B d'origine, notre chinois-Mixtral-8x7b a atteint le niveau d'anglais le plus fort de chaque modèle de liste de mots.
En raison des différences subtiles dans les détails de mise en œuvre des scripts d'évaluation dans différentes versions, afin d'assurer la cohérence et l'équité des résultats de l'évaluation, nos scripts d'évaluation utilisent le lm-évaluation de l'elev.
Le tableau suivant montre les effets de génération de chaque modèle d'extension de mot. Étant donné que le corpus pré-formé de certains modèles n'est pas séparé par eos_token , nous utilisons max_tokens = 100 pour tronquer le texte généré. Nos paramètres d'échantillonnage sont temperature = 0.8, top_p = 0.9 .

Pour l'efficacité du codage et du décodage chinois, nous avons utilisé le segment de mot de chaque modèle de liste de mots pour coder une tranche de l'ensemble de données Skypile (2023-06_ZH_HEAD_0000.jsonl) et comparé la sortie de la quantité de jeton de texte chinois par chaque segment de mot:
| Nom du modèle | Catégorie de modèle | Taille de vocabulaire | Quantité de jeton dans le texte chinois | Efficacité du codec |
|---|---|---|---|---|
| méta-llama / lama-2-13b-hf | Lama | 32000 | 780m | Faible |
| Mistralai / mixtral-8x7b-v0.1 | Mixtral | 32000 | 606m | Faible |
| Linly-ai / chinois-llama-2-13b-hf | Lama | 40076 | 532m | milieu |
| IDEA-CCNL / ZIYA2-13B-base | Lama | 39424 | 532m | milieu |
| HFL / Chinese-Llama-2-13B | Lama | 55296 | 365m | haut |
| TigerResearch / Tigerbot-13b-Base-V3 | Lama | 65112 | 342m | haut |
| Chinois-mixtral-8x7b (ce projet) | Mixtral | 57000 | 355m | haut |
Parmi le texte d'essai d'environ 1,4 Go, notre efficacité chinoise chinoise chinoise du codec chinois est la seconde derrière Tigerbot-13B-Base-V3, qui est 41,5% plus élevée que le modèle d'origine. Ceci est propice à l'accélération de la vitesse d'inférence des textes chinois et à la longueur de la séquence d'économie dans des scénarios tels que l'apprentissage dans le contexte et la chaîne de pensées, ce qui est propice à l'amélioration des performances des tâches d'inférence complexes.
Nous utilisons sentencepiece pour former le vocabulaire chinois du BPE sur les données de la Zhihu 12G et les données d'illumination 2G. Lors de la formation de la liste de vocabulaire, nous avons énuméré le nombre de jetons de mot unique chinois et le nombre total de jetons chinois, et combiné les deux pour obtenir des centaines de listes de vocabulaire avec différentes tailles et contenus. Afin d'obtenir la liste de vocabulaire la plus appropriée, nous avons calculé la capacité de vocabulaire chinoise de ces listes de vocabulaire via l'ALP proposé par Zheng Bo et al. L'ALP est un indicateur pratique et rapide pour mesurer la capacité de vocabulaire d'un langage spécifique en calculant la granularité des sous-mots dans une langue spécifique et en punissant les sous-mots moyens et basse fréquence de la liste de vocabulaire.
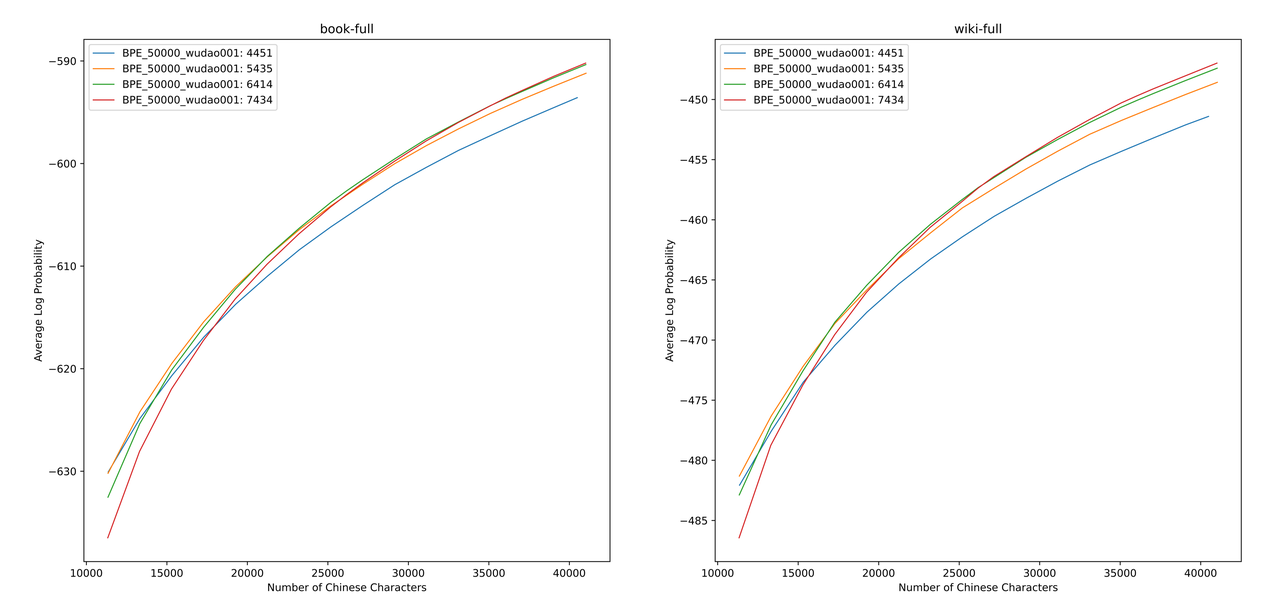
Nous avons évalué les valeurs ALP pour différentes listes de vocabulaire sur les livres et l'Encyclopedia Corpus. Dans l'illustration, les quatre courbes représentent la liste des mots de quatre jetons chinois simples (4451, 5435, 6414 et 7434). Afin d'éviter le taux de compression chinois trop petit et la couche d'incorporation trop clairsemée, nous sélectionnons le point d'inflexion de la courbe ALP, qui ajoutera 25 000 jetons chinois à la liste de vocabulaire. Sur cette base, nous avons sélectionné le plus grand ALP parmi les quatre courbes, c'est-à-dire que la liste de vocabulaire de 6414 jetons chinois à seul mot a été ajoutée comme la liste de vocabulaire finale sélectionnée par le chinois-Mixtral-8x7b.
Après avoir obtenu le nouveau vocabulaire, nous devons développer et initialiser les couches d'incorporation et LM_HEAD. Nous initialisons l'expansion en utilisant le mot intégralité de la moyenne du nouveau jeton dans l'ancienne couche d'incorporation. Dans nos expériences précédentes, cette approche est légèrement meilleure que la mise en œuvre par défaut de HuggingFace, c'est-à-dire que l'initialisation est effectuée en utilisant une distribution normale fixe.
Le modèle mixtral-8x7b a un volume de paramètres de 46,7b. La formation complète des paramètres nécessite l'utilisation de plusieurs stratégies parallèles en même temps. Le coût du temps est trop élevé lorsque les ressources de formation sont limitées. Par conséquent, nous utilisons la méthode officiellement recommandée en étreignant pour former le modèle à l'aide de Qlora. Sur la base de la décomposition de faible rang LORA, le QLORA réduit en outre la mémoire vidéo requise pour la formation et maintient les performances comparables à la formation à paramètre complet en introduisant la quantification 4 bits, la double quantification et l'utilisation de la mémoire unifiée NVIDIA pour la pagination.
Nous nous référons aux paramètres de LORA par Yiming Cui et al., Appliquer une décomposition de faible rang à toutes les couches linéaires du modèle d'origine et définir les paramètres de l'incorporation amplifiée et les couches LM_HEAD pour être formées. Pour le corps du modèle, nous utilisons le format NF4 pour la quantification, ce qui peut faire en sorte que les données quantifiées aient la même distribution de données qu'avant la quantification, et la perte d'informations de poids du modèle est moindre.
Nous vous recommandons d'utiliser Python 3.10 + Torch 2.0.1
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolationNous avons formé le chinois-mixtral-8x7b sur la base de l'ensemble de données open source existant, qui comprend:
| Nom de l'ensemble de données | Langue de données | La quantité de données utilisées | Remarque |
|---|---|---|---|
| Skywork / Skypile-150b | Chinois | 30b | Utilisez uniquement les données de 2022 + 2023 |
| Dkyoon / smpajama-6b | Anglais | 12b | Duplication de jeu de données 2 époque |
Téléchargez l'ensemble de données dans data via data/download.py . Pour l'ensemble de données Slimpajama, vous devez utiliser data/parquet2jsonl.py pour convertir l'ensemble de données d'origine au format jsonl .
L'ensemble de données téléchargé est un éclat de plusieurs fichiers JSONL. Utilisez cat pour fusionner plusieurs éclats dans un fichier JSONL.
$ cat * .jsonl > all.jsonl split JSONL en train et collections valides. Le rapport entre les lignes de train et valides dans ce projet est de 999: 1.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl Enregistrez le nom et le chemin du jeu de données dans data/datasets.toml :
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置Utilisez data/preprocess_datasets.py pour segmenter le segment de la réduction de l'ensemble de données pour accélérer la formation.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab Après avoir effectué une segmentation des sous-mots, vous pouvez utiliser data/utils.py pour afficher les jetons totaux de chaque ensemble de données:
$ python data/utils.py Le script de démarrage de formation est scripts/train.sh . L'ensemble de données de formation et le rapport de jeu de données peuvent être modifiés en modifiant TRAIN_DATASETS :
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) Si vous utilisez Slurm Cluster Management System, vous pouvez le soumettre via sbatch :
$ sbatch scripts/train-pt.sh Si vous n'avez pas Slurm ou que vous souhaitez commencer à vous entraîner via la ligne de commande, vous pouvez extraire directement torchrun dans scripts/train-pt.sh pour commencer la formation.
Le format de jeu de données requis pour le réglage fin est similaire à la pré-formation. Le fichier d'ensemble de données doit être au format JSONL: un JSON par ligne, qui doit contenir le champ "text" et épisser l'instruction, l'entrée et la sortie en fonction du modèle dont vous avez besoin.
Ensuite, vous devez enregistrer le nom de l'ensemble de données et le chemin du chemin dans data/datasets.toml :
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 Le script de démarrage de formation est scripts/train-sft.sh . L'ensemble de données de formation et le rapport de jeu de données peuvent être modifiés en modifiant TRAIN_DATASETS :
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) Si vous utilisez Slurm Cluster Management System, vous pouvez le soumettre via sbatch :
$ sbatch scripts/train-sft.sh Si vous n'avez pas de slurm ou que vous souhaitez commencer à vous entraîner via la ligne de commande, vous pouvez extraire directement torchrun dans scripts/train-sft.sh pour commencer la formation.
Si vous pensez que ce projet est utile à vos recherches ou utilisez le code de ce projet, veuillez vous référer à ce projet:
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

