Chinese Mixtral 8x7B
1.0.0

This project is based on the model Mixtral-8x7B released by Mistral, and is expected to further promote the study of MoE model by the Chinese natural language processing community. Our expanded vocabulary list significantly improves the model's encoding and decoding efficiency of Chinese, and performs incremental pre-training of the expanded vocabulary list model through large-scale open source corpus, so that the model has strong Chinese generation and understanding capabilities.
Project open source content:
Please note that Chinese-Mixtral-8x7B may still generate misleading replies containing factual errors or harmful content containing bias/discrimination. Please be careful to identify and use the generated content and do not spread the generated harmful content to the Internet.
This project is trained using QLoRA. The LoRA weight and the combined weight model are open source respectively. You can choose to download according to your needs:
| Model name | Model size | Download address | Remark |
|---|---|---|---|
| Chinese-Mixtral-8x7B | 88GB | HuggingFace ModelScope | Complete Chinese word list model, can be used directly |
| Chinese-Mixtral-8x7B-adapter | 2.7GB | HuggingFace | LoRA weights need to be merged with the original Mixtral-8x7B before they can be used. Please refer to the merge script here. |
Chinese-Mixtral-8x7B supports the complete Mixtral-8x7B model ecosystem, including using vLLM and Flash Attention 2 for acceleration, using bitsandbytes for model quantization, etc. Here is a code example for reasoning using Chinese-Mixtral-8x7B.
Using Flash Attention 2:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , attn_implementation = "flash_attention_2" , torch_dtype = torch . bfloat16 , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Quantification using 4bit:
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_4bit = True , device_map = "auto" )
text = "我的名字是"
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate ( ** inputs , max_new_tokens = 20 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Please note that Chinese-Mixtral-8x7B is a base model and has not been fine-tuned by instructions, so the instruction compliance capabilities are limited. You can refer to the fine-tuning section to fine-tune the model.
We used the following evaluation datasets to evaluate Chinese-Mixtral-8x7B separately:
According to a technical report released by Mistral, the Mixtral-8x7B will activate the 13B parameter when inference. The following table shows the 5-shot results of Chinese-Mixtral-8x7B and other 13B-scale Chinese word expansion models on each evaluation dataset:
| Model name | Incremental training material | C-Eval (Chinese) | CMMLU (Chinese) | MMLU (English) | HellaSwag (English) |
|---|---|---|---|---|---|
| IDEA-CCNL/Ziya2-13B-Base | 650B Token | 59.29 | 60.93 | 59.86 | 58.90 |
| TigerResearch/tigerbot-13b-base-v3 | 500B Token | 50.52 | 51.65 | 53.46 | 59.16 |
| Linly-AI/Chinese-LLaMA-2-13B-hf | 11B Token | 42.57 | 41.95 | 51.32 | 59.05 |
| hfl/chinese-llama-2-13b | About 30B Token(120GB) | 41.90 | 42.08 | 51.92 | 59.28 |
| Chinese-Mixtral-8x7B (this project) | 42B Token | 52.08 | 51.08 | 69.80 | 65.69 |
In terms of Chinese knowledge and understanding, our Chinese-Mixtral-8x7B is comparable to TigerBot-13B-Base-v3 performance. Since the amount of training data of Chinese-Mixtral-8x7B is only 8% of that of TigerBot-13B-Base-v3, our model still has room for further improvement. At the same time, thanks to the powerful performance of the original Mixtral-8x7B model, our Chinese-Mixtral-8x7B has reached the strongest English level of each word list model.
Due to the subtle differences in the implementation details of the evaluation scripts in different versions, in order to ensure the consistency and fairness of the evaluation results, our evaluation scripts use the lm-evaluation-harness released by EleutherAI, and the commit hash is 28ec7fa.
The following table shows the generation effects of each word expansion model. Since the pre-trained corpus of some models is not separated by eos_token , we use max_tokens = 100 to truncate the generated text. Our sampling parameters are temperature = 0.8, top_p = 0.9 .

For Chinese encoding and decoding efficiency, we used the word segmenter of each word list model to encode a slice of the SkyPile dataset (2023-06_zh_head_0000.jsonl) and compared the Chinese text token amount output by each word segmenter:
| Model name | Model Category | Vocabulary size | Token quantity in Chinese text | Codec efficiency |
|---|---|---|---|---|
| meta-llama/Llama-2-13B-hf | LLaMA | 32000 | 780M | Low |
| mistralai/Mixtral-8x7B-v0.1 | Mixtral | 32000 | 606M | Low |
| Linly-AI/Chinese-LLaMA-2-13B-hf | LLaMA | 40076 | 532M | middle |
| IDEA-CCNL/Ziya2-13B-Base | LLaMA | 39424 | 532M | middle |
| hfl/chinese-llama-2-13b | LLaMA | 55296 | 365M | high |
| TigerResearch/tigerbot-13b-base-v3 | LLaMA | 65112 | 342M | high |
| Chinese-Mixtral-8x7B (this project) | Mixtral | 57000 | 355M | high |
Among the test text of about 1.4GB, our Chinese-Mixtral-8x7B Chinese codec efficiency is second only to TigerBot-13B-Base-v3, which is 41.5% higher than the original model. This is conducive to accelerating the inference speed of Chinese texts, and saving sequence length in scenarios such as In-Context Learning and Chain-of-Thought, which is conducive to improving the performance of complex inference tasks.
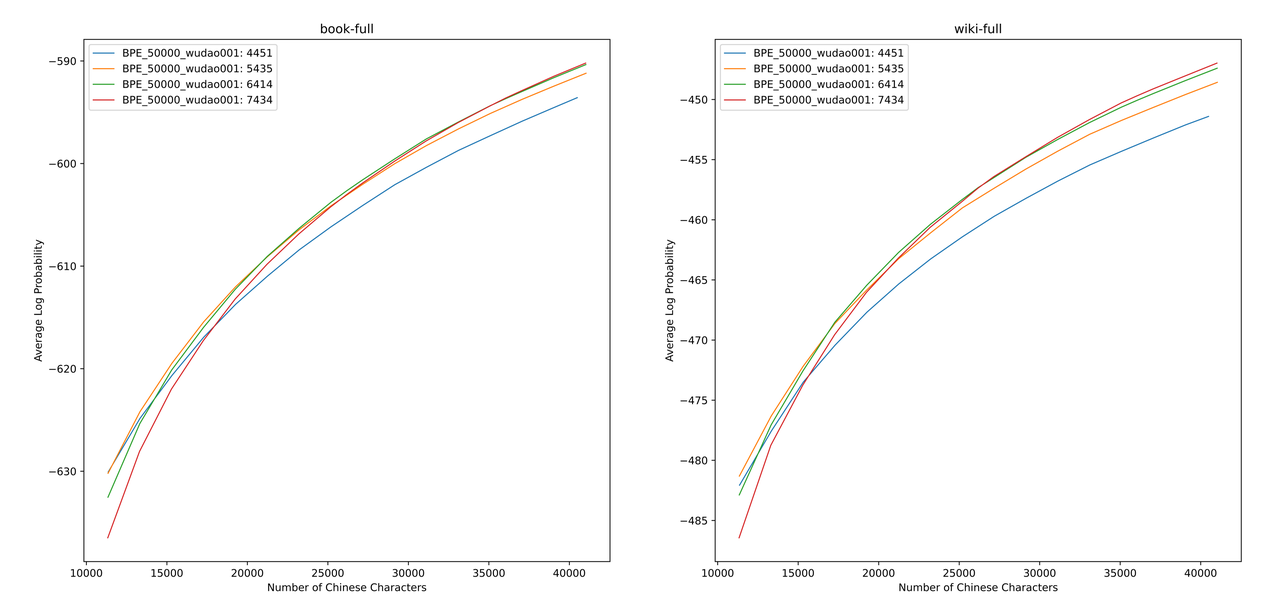
We use sentencepiece to train the Chinese BPE vocabulary on 12G Zhihu data and 2G enlightenment data. When training the vocabulary list, we enumerated the number of Chinese single-word tokens and the total number of Chinese tokens, and combined the two to obtain hundreds of vocabulary lists with different sizes and contents. In order to obtain the most suitable vocabulary list, we calculated the Chinese vocabulary ability of these vocabulary lists through ALP proposed by Zheng Bo et al. ALP is a convenient and quick indicator to measure the vocabulary ability of a specific language by calculating the granularity of subwords in a specific language and punishing the middle and low frequency subwords of the vocabulary list.
We evaluated the ALP values for different vocabulary lists on books and encyclopedia corpus. In the illustration, the four curves represent the word list of four Chinese single-word tokens (4451, 5435, 6414 and 7434). In order to avoid the Chinese compression rate that is too small, and the embedding layer that is too sparse, we select the inflection point of the ALP curve, which will add 25,000 Chinese tokens to the vocabulary list. On this basis, we selected the largest ALP among the four curves, that is, the vocabulary list of 6414 Chinese single-word Tokens was added as the final vocabulary list selected by Chinese-Mixtral-8x7B.
After obtaining the new vocabulary, we need to expand and initialize the embedding and lm_head layers. We initialize the expansion using the word embedding average of the new token in the old embedding layer. In our previous experiments, this approach is slightly better than HuggingFace's default implementation, i.e. initialization is performed using a fixed normal distribution.
The Mixtral-8x7B model has a parameter volume of 46.7B. Full parameter training requires the use of multiple parallel strategies at the same time. The time cost is too high when training resources are limited. Therefore, we use the method officially recommended by HuggingFace to train the model using QLoRA. Based on LoRA low-rank decomposition, QLoRA further reduces the video memory required for training and maintains performance comparable to full-parameter training by introducing 4-bit quantization, dual quantization and using NVIDIA unified memory for paging.
We refer to the settings of LoRA by Yiming Cui et al., apply low-rank decomposition to all Linear layers of the original model, and set the parameters of the amplified embedding and lm_head layers to be trainable. For the model body, we use the NF4 format for quantization, which can make the quantized data have the same data distribution as before quantization, and the model's weight information loss is less.
We recommend using Python 3.10 + torch 2.0.1
# Pytorch + Transformers
$ pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
$ pip install transformers==4.36.2 datasets evaluate peft accelerate gradio optimum sentencepiece trl
$ pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge bitsandbytes fire
# CUDA Toolkit
$ conda install nvidia/label/cuda-11.7.1::cuda
# DeepSpeed
$ git clone https://github.com/microsoft/DeepSpeed.git
$ cd DeepSpeed
$ DS_BUILD_FUSED_ADAM=1 pip3 install .
# Flash Attention
$ pip install flash-attn --no-build-isolationWe trained Chinese-Mixtral-8x7B based on the existing open source dataset, which includes:
| Dataset name | Dataset Language | The amount of data used | Remark |
|---|---|---|---|
| Skywork/SkyPile-150B | Chinese | 30B | Use only data from 2022 + 2023 |
| DKYoon/SlimPajama-6B | English | 12B | Dataset duplication 2 Epoch |
Download the dataset into data via data/download.py . For Slimpajama dataset, you need to use data/parquet2jsonl.py to convert the original dataset to jsonl format.
The downloaded dataset is a shard of multiple jsonl files. Use cat to merge multiple shards into one jsonl file.
$ cat * .jsonl > all.jsonl split jsonl into train and valid collections. The ratio of train and valid lines in this project is 999:1.
$ wc -l all.jsonl # 计算数据集总行数
$ split -l < lines > all.jsonl # 按999:1计算train/valid行数,进行切分
$ mv xaa DKYoon-SlimPajama-6B-train.jsonl # 重命名
$ mv xab DKYoon-SlimPajama-6B-dev.jsonl Register the dataset name and path into data/datasets.toml :
[ DKYoon-SlimPajama-6B ] # 数据集名称
splits = [ " train " , " dev " ] # 数据集train/valid集合
root = " {DATA_DIR}/en/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名
encoded = " encoded-{name}-{split} " # 预处理保存位置Use data/preprocess_datasets.py to subword segment the dataset to speed up training.
$ python data/preprocess_datasets.py --ds_name SkyPile-150B-2023 --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab
$ python data/preprocess_datasets.py --ds_name DKYoon-SlimPajama-6B --tokenizer_name_or_path tokenizer/Mixtral-8x7B-v0.1-vocab After performing subword segmentation, you can use data/utils.py to view the total tokens of each dataset:
$ python data/utils.py The training startup script is scripts/train.sh . The training dataset and dataset ratio can be modified by modifying TRAIN_DATASETS :
TRAIN_DATASETS=(
1:SkyPile-150B-2022 # 使用全量SkyPile-150B-2022
0.1:SkyPile-150B-2023 # 使用SkyPile-150B-2023的10%数据
1:DKYoon-SlimPajama-6B # 使用全量DKYoon-SlimPajama-6B
) If you use SLURM cluster management system, you can submit it through sbatch :
$ sbatch scripts/train-pt.sh If you don't have SLURM or want to start training via the command line, you can directly extract torchrun in scripts/train-pt.sh to start training.
The dataset format required for fine-tuning is similar to pre-training. The dataset file needs to be in jsonl format: one json per line, which needs to contain the "text" field, and splice the instruction, input and output according to the template you need.
Then you need to register the dataset name and path into data/datasets.toml :
[ ShareGPT-Chinese ] # 数据集名称
splits = [ " train " ] # 数据集train/valid集合
root = " {DATA_DIR}/sft/{name} " # 数据集根目录
doc = " {name}-{split} " # 数据集文件名 The training startup script is scripts/train-sft.sh . The training dataset and dataset ratio can be modified by modifying TRAIN_DATASETS :
TRAIN_DATASETS=(
1.0:ShareGPT-Chinese # 使用全量ShareGPT-Chinese
0.5:ShareGPT-English # 使用ShareGPT-English的50%数据
) If you use SLURM cluster management system, you can submit it through sbatch :
$ sbatch scripts/train-sft.sh If you don't have SLURM or want to start training via the command line, you can directly extract torchrun in scripts/train-sft.sh to start training.
If you feel this project is helpful to your research or use the code of this project, please refer to this project:
@misc { Chinese-Mixtral-8x7B ,
author = { HIT-SCIR } ,
title = { Chinese-Mixtral-8x7B: An Open-Source Mixture-of-Experts LLM } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B} }
}

