minigpt4.cpp
v1.0.0
Вывод Minigpt4 в чистом C/C ++.
Основная цель minigpt4.cpp -запустить Minigpt4 с использованием 4-битного квантования с использованием библиотеки GGML.
Требования : git
git clone --recursive https://github.com/Maknee/minigpt4.cpp
cd minigpt4.cpp Перейдите к выпускам и извлеките файл библиотеки minigpt4 в каталог репозитория.
Требования : Cmake, Visual Studio и Git
cmake .
cmake --build . --config Release
binReleaseminigpt4.dll должен быть сгенерирован
Требования : Cmake (Ubuntu: sudo apt install cmake )
cmake .
cmake --build . --config Release minigpt4.so Так должно быть получено
Требования : Cmake (MacOS: brew install cmake )
cmake .
cmake --build . --config Release minigpt4.dylib должен быть получен
Примечание. Если вы строите с помощью OpenCV (позволяя таким функциям, как загрузка и предварительная обработка изображения в самой библиотеке), установите MINIGPT4_BUILD_WITH_OPENCV на ON CMakeLists.txt или построить с -DMINIGPT4_BUILD_WITH_OPENCV=ON как параметр для CMAKE CLI.
Предварительные модели доступны на обнимании лица ~ 7b или 13b.
Рекомендуется для надежных результатов, но медленная скорость вывода: minigpt4-13b-f16.bin
Требования : Python 3.x и Pytorch.
Клонировать хранилище Minigpt-4 и выполните установку
cd minigpt4
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4 Загрузите предварительную контрольную точку в репозитории Minigpt-4 в Checkpoint Aligned with Vicuna 7B или Checkpoint Aligned with Vicuna 13B или загрузите их по ссылке HuggingFace для 7b или 13b
Преобразовать веса модели в формат GGML
7b модель
cd minigpt4
python convert.py C:pretrained_minigpt4_7b.pth --ftype=f16
13b модель
cd minigpt4
python convert.py C:pretrained_minigpt4.pth --ftype=f16
7b модель
python convert.py ~ /Downloads/pretrained_minigpt4_7b.pth --outtype f1613b модель
python convert.py ~ /Downloads/pretrained_minigpt4.pth --outtype f16 minigpt4-7B-f16.bin или minigpt4-13B-f16.bin должен быть получен
Предварительные модели доступны для обнимающего лица
Рекомендуется для надежных результатов и достойной скорости вывода: GGML-Vicuna-13B-V0-Q5_K.BIN
Требования : Python 3.x и Pytorch.
Следуйте руководству от Minigpt4, чтобы получить модель Vicuna-V0.
Затем клон llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake .
cmake --build . --config ReleaseПреобразовать модель в GGML
python convert.py < path-to-model >Квантовать модель
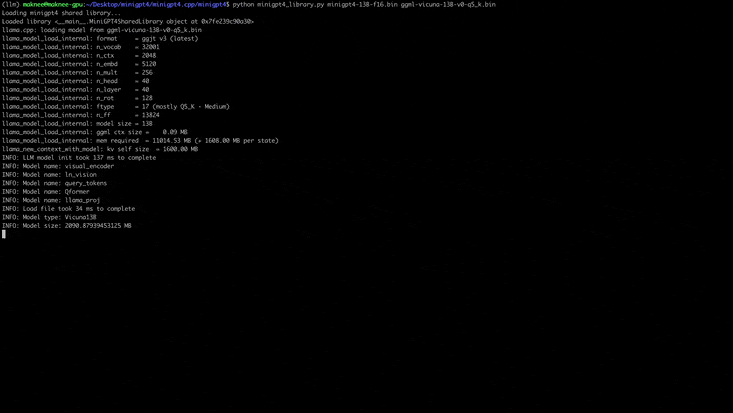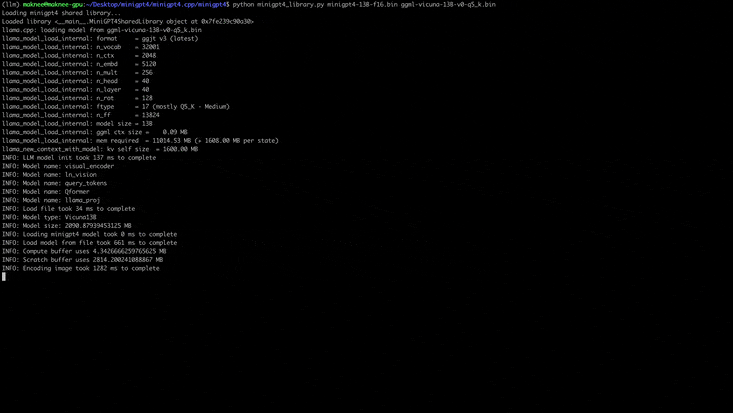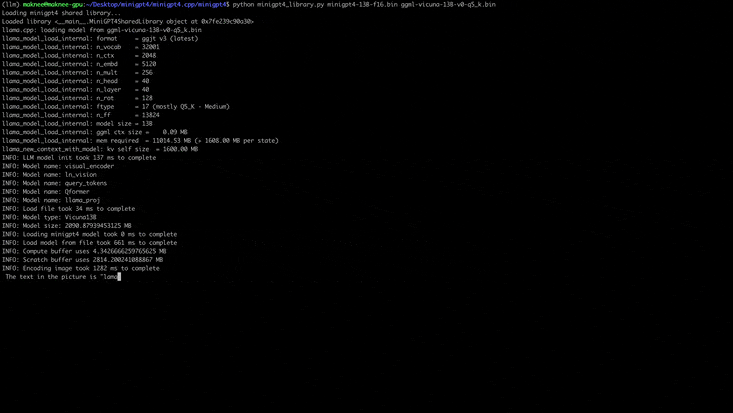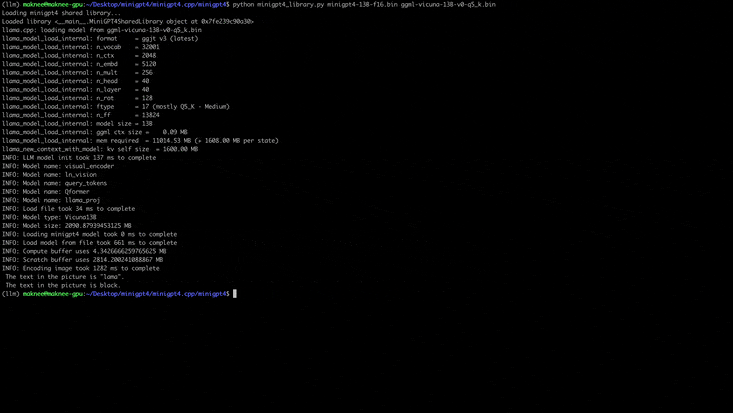
python quanitize < path-to-model > < output-model > Q4_1 Проверьте, работает ли Minigpt4, вызывая следующее, заменив minigpt4-13B-f16.bin и ggml-vicuna-13B-v0-q5_k.bin с вашими соответствующими моделями
cd minigpt4
python minigpt4_library.py minigpt4-13B-f16.bin ggml-vicuna-13B-v0-q5_k.binУстановите требования для WebUI
pip install -r requirements.txt Затем запустите WebUI, заменив minigpt4-13B-f16.bin и ggml-vicuna-13B-v0-q5_k.bin с вашими соответствующими моделями
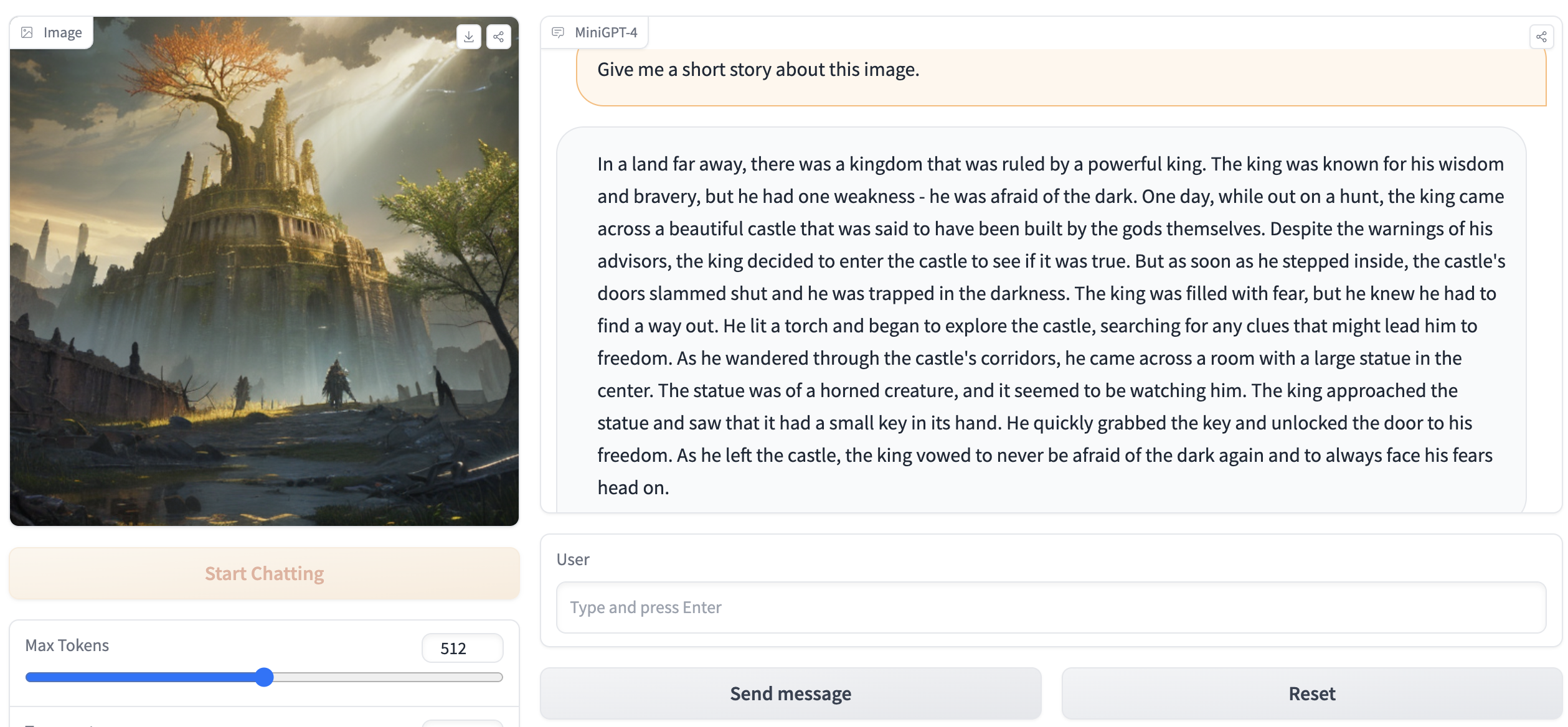
python webui.py minigpt4-13B-f16.bin ggml-vicuna-13B-v0-q5_k.binВывод должен содержать что -то вроде следующего:
Running on local URL: http://127.0.0.1:7860
To create a public link, set ` share=True ` in `launch () ` . Зайдите на http://127.0.0.1:7860 в вашем браузере, и вы сможете взаимодействовать с Webui.


