minigpt4.cpp
v1.0.0
Inférence de MINIGPT4 en pur C / C ++.
L'objectif principal de minigpt4.cpp est d'exécuter MINIGPT4 en utilisant la quantification 4 bits avec l'utilisation de la bibliothèque GGML.
Exigences : Git
git clone --recursive https://github.com/Maknee/minigpt4.cpp
cd minigpt4.cpp Accédez à Release et extraire le fichier de bibliothèque minigpt4 dans le répertoire du référentiel.
Exigences : CMake, Visual Studio et Git
cmake .
cmake --build . --config Release
binReleaseminigpt4.dll doit être généré
Exigences : CMake (Ubuntu: sudo apt install cmake )
cmake .
cmake --build . --config Release minigpt4.so doit être généré
Exigences : CMake (macOS: brew install cmake )
cmake .
cmake --build . --config Release minigpt4.dylib doit être généré
Remarque: Si vous construisez avec OpenCV (permettant des fonctionnalités telles que le chargement et l'image de prétraitement au sein CMakeLists.txt la bibliothèque elle-même), définissez MINIGPT4_BUILD_WITH_OPENCV sur ON ou construisez avec -DMINIGPT4_BUILD_WITH_OPENCV=ON en tant que paramètre de la Cmeke Cli.
Des modèles pré-qualifiés sont disponibles sur une face étreinte ~ 7b ou 13b.
Recommandé pour des résultats fiables, mais une vitesse d'inférence lente: minigpt4-13b-f16.bin
Exigences : Python 3.x et Pytorch.
Clone le référentiel minigpt-4 et effectuez la configuration
cd minigpt4
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4 Téléchargez le point de contrôle pré-entraîné dans le référentiel Minigpt-4 sous Checkpoint Aligned with Vicuna 7B ou Checkpoint Aligned with Vicuna 13B ou téléchargez-les à partir du lien HuggingFace pour 7b ou 13B
Convertir les poids du modèle en format GGML
Modèle 7B
cd minigpt4
python convert.py C:pretrained_minigpt4_7b.pth --ftype=f16
Modèle 13B
cd minigpt4
python convert.py C:pretrained_minigpt4.pth --ftype=f16
Modèle 7B
python convert.py ~ /Downloads/pretrained_minigpt4_7b.pth --outtype f16Modèle 13B
python convert.py ~ /Downloads/pretrained_minigpt4.pth --outtype f16 minigpt4-7B-f16.bin ou minigpt4-13B-f16.bin doit être généré
Des modèles pré-qualifiés sont disponibles sur un visage étreint
Recommandé pour des résultats fiables et une vitesse d'inférence décente: GGML-vicuna-13b-v0-Q5_K.Bin
Exigences : Python 3.x et Pytorch.
Suivez le guide du minigpt4 pour obtenir le modèle Vicuna-V0.
Ensuite, clone lama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake .
cmake --build . --config ReleaseConvertir le modèle en GGML
python convert.py < path-to-model >Quantifier le modèle
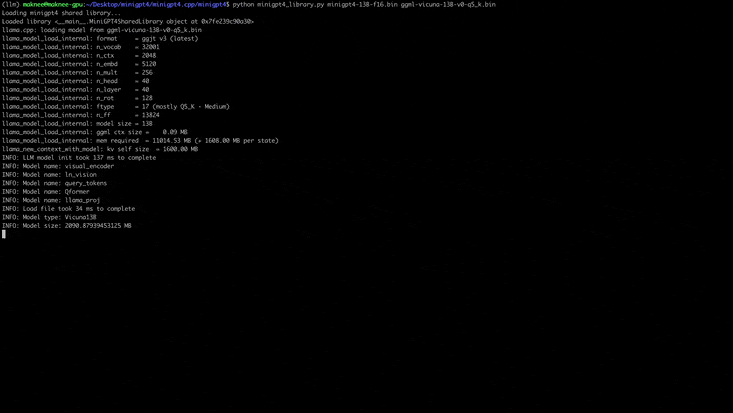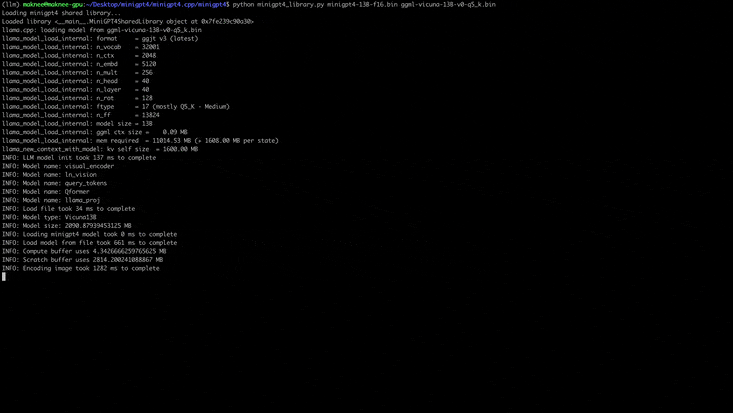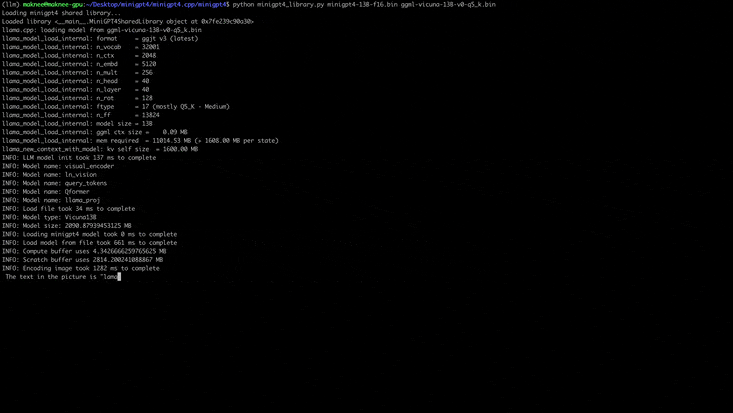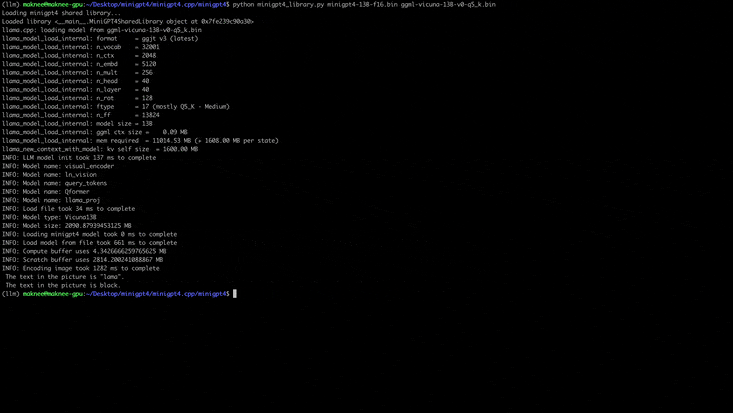
python quanitize < path-to-model > < output-model > Q4_1 Testez si MiniGpt4 fonctionne en appelant ce qui suit, en remplaçant minigpt4-13B-f16.bin et ggml-vicuna-13B-v0-q5_k.bin avec votre modèle respectif
cd minigpt4
python minigpt4_library.py minigpt4-13B-f16.bin ggml-vicuna-13B-v0-q5_k.binInstallez les exigences pour le webui
pip install -r requirements.txt Ensuite, exécutez le webui, en remplaçant minigpt4-13B-f16.bin et ggml-vicuna-13B-v0-q5_k.bin avec vos modèles respectifs
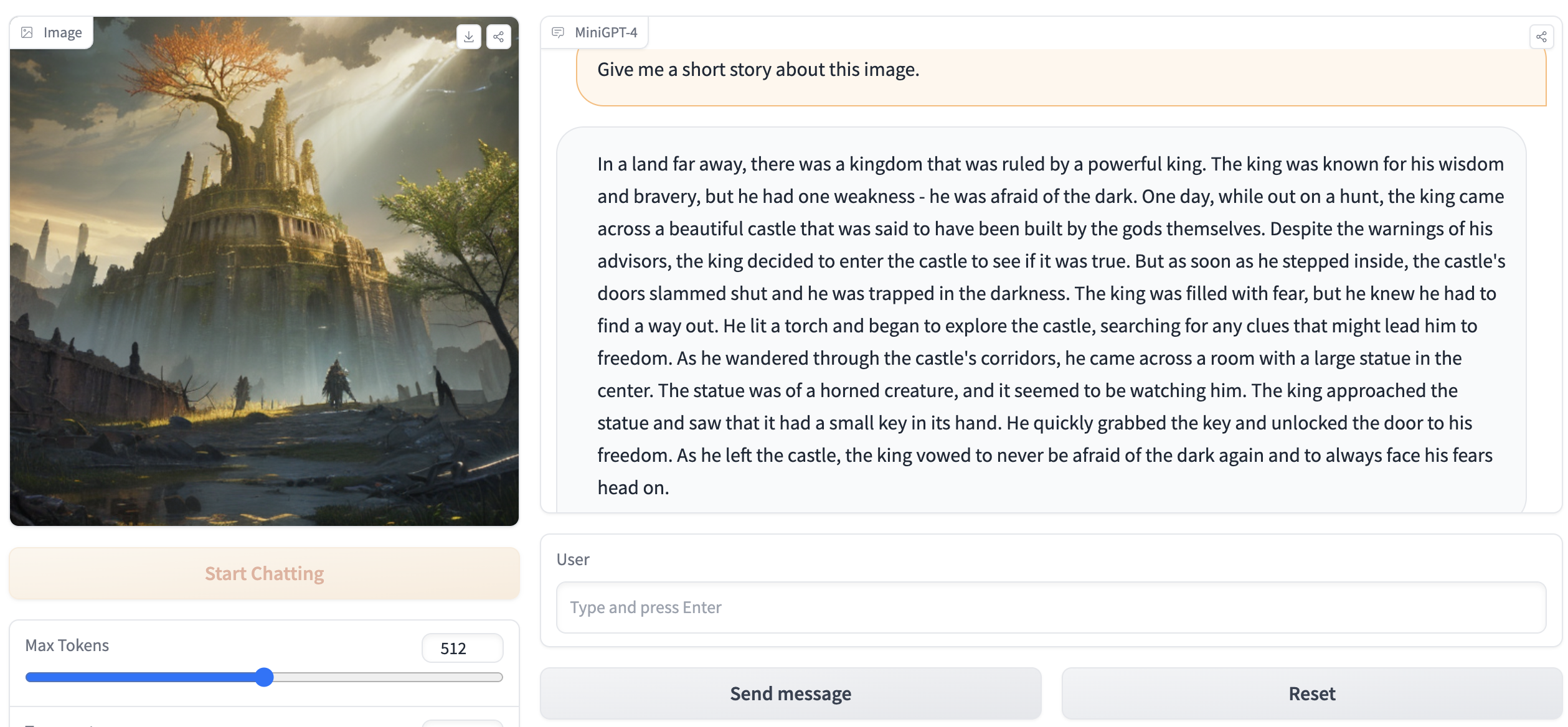
python webui.py minigpt4-13B-f16.bin ggml-vicuna-13B-v0-q5_k.binLa sortie doit contenir quelque chose comme ce qui suit:
Running on local URL: http://127.0.0.1:7860
To create a public link, set ` share=True ` in `launch () ` . Allez sur http://127.0.0.1:7860 dans votre navigateur et vous devriez pouvoir interagir avec le webui.


