minigpt4.cpp
v1.0.0
Inferenz von Minigpt4 in reinem C/C ++.
Das Hauptziel von minigpt4.cpp ist es, Minigpt4 mit der 4-Bit-Quantisierung unter Verwendung der GGML-Bibliothek auszuführen.
Anforderungen : Git
git clone --recursive https://github.com/Maknee/minigpt4.cpp
cd minigpt4.cpp Gehen Sie zu Releases und extrahieren Sie minigpt4 -Bibliotheksdatei in das Repository -Verzeichnis.
Anforderungen : CMake, Visual Studio und Git
cmake .
cmake --build . --config Release
binReleaseminigpt4.dll sollte generiert werden
Anforderungen : CMake (Ubuntu: sudo apt install cmake )
cmake .
cmake --build . --config Release minigpt4.so so sollte generiert werden
Anforderungen : CMake (macOS: brew install cmake )
cmake .
cmake --build . --config Release minigpt4.dylib sollte erzeugt werden
HINWEIS: Wenn Sie mit OpenCV erstellt werden (und Funktionen wie das Laden und Vorverarbeitung in der Bibliothek selbst ermöglichen), setzen Sie MINIGPT4_BUILD_WITH_OPENCV in ON oder erstellen Sie mit -DMINIGPT4_BUILD_WITH_OPENCV=ON CMakeLists.txt Parameter als Parameter zum CMake -CLI.
Vor-quantisierte Modelle sind auf dem Umarmungsgesicht ~ 7b oder 13b erhältlich.
Empfohlen für zuverlässige Ergebnisse, aber langsame Inferenzgeschwindigkeit: Minigpt4-13b-F16.bin
Anforderungen : Python 3.x und Pytorch.
Klonen Sie das Minigpt-4-Repository und führen Sie das Setup aus
cd minigpt4
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4 Laden Sie den vorgezogenen Checkpoint im Minigpt-4-Repository unter Checkpoint Aligned with Vicuna 7B oder Checkpoint Aligned with Vicuna 13B ausgerichtet ist, herunter, oder laden Sie sie vom Huggingface-Link für 7B oder 13B herunter
Umwandeln Sie die Modellgewichte in das GGML -Format
7B -Modell
cd minigpt4
python convert.py C:pretrained_minigpt4_7b.pth --ftype=f16
13B -Modell
cd minigpt4
python convert.py C:pretrained_minigpt4.pth --ftype=f16
7B -Modell
python convert.py ~ /Downloads/pretrained_minigpt4_7b.pth --outtype f1613B -Modell
python convert.py ~ /Downloads/pretrained_minigpt4.pth --outtype f16 minigpt4-7B-f16.bin oder minigpt4-13B-f16.bin sollte generiert werden
Vor-quantisierte Modelle sind auf dem Umarmungsgesicht erhältlich
Empfohlen für zuverlässige Ergebnisse und anständige Inferenzgeschwindigkeit: GGML-VICUNA-13B-V0-Q5_K.bin
Anforderungen : Python 3.x und Pytorch.
Befolgen Sie die Anleitung vom Minigpt4, um das Vicuna-V0-Modell zu erhalten.
Dann klonen lama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake .
cmake --build . --config ReleaseKonvertieren Sie das Modell in GGML
python convert.py < path-to-model >Quantisieren Sie das Modell
python quanitize < path-to-model > < output-model > Q4_1 Testen Sie, wenn Minigpt4 funktioniert, indem Sie Folgendes anrufen und minigpt4-13B-f16.bin und ggml-vicuna-13B-v0-q5_k.bin mit Ihren jeweiligen Modellen ersetzen
cd minigpt4
python minigpt4_library.py minigpt4-13B-f16.bin ggml-vicuna-13B-v0-q5_k.binInstallieren Sie die Anforderungen für das Webui
pip install -r requirements.txt Dann führen Sie das Webui aus und ersetzen Sie minigpt4-13B-f16.bin und ggml-vicuna-13B-v0-q5_k.bin mit Ihren jeweiligen Modellen
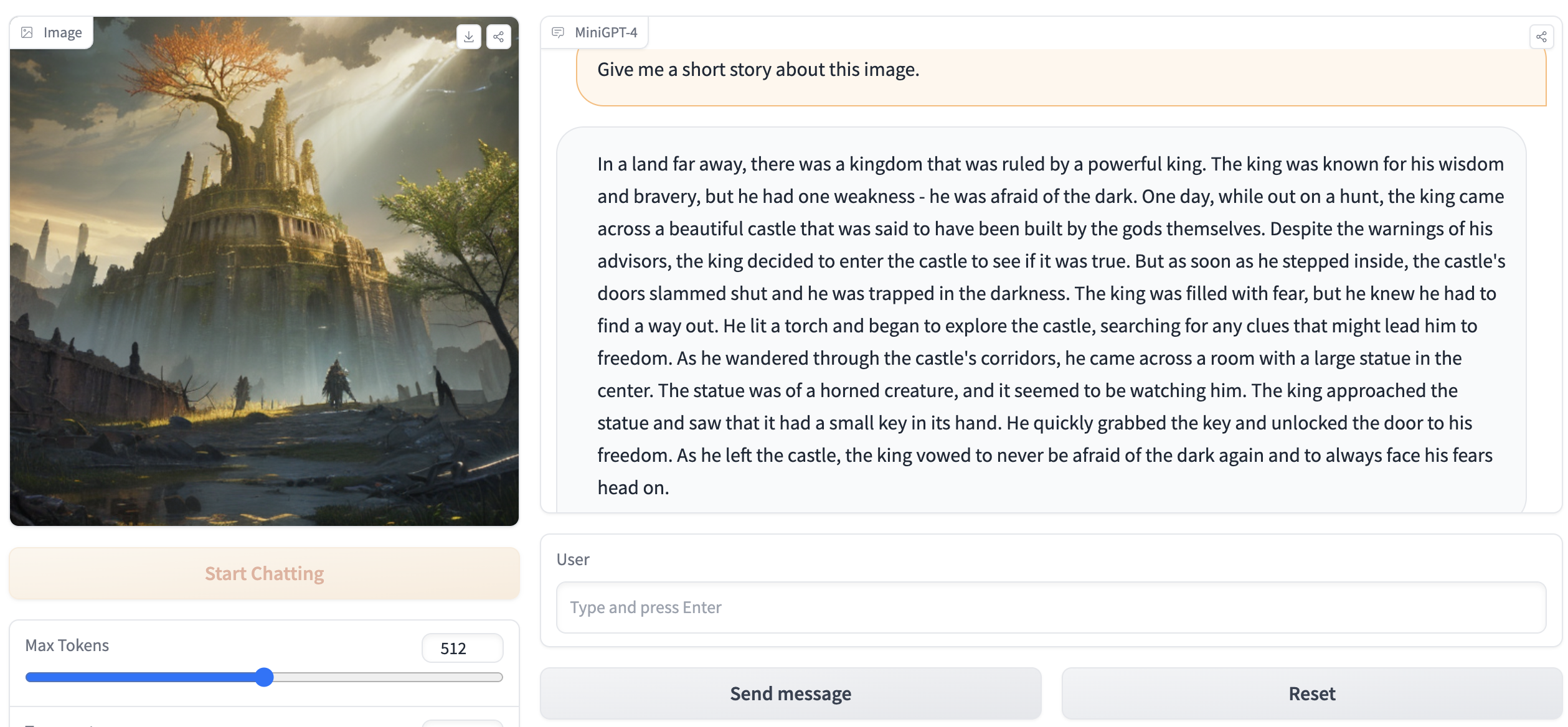
python webui.py minigpt4-13B-f16.bin ggml-vicuna-13B-v0-q5_k.binDie Ausgabe sollte so etwas wie folgt enthalten:
Running on local URL: http://127.0.0.1:7860
To create a public link, set ` share=True ` in `launch () ` . Gehen Sie in Ihrem Browser zu http://127.0.0.1:7860 und Sie sollten in der Lage sein, mit dem Webui zu interagieren.


