minigpt4.cpp
v1.0.0
Inferência de Minigpt4 em C/C ++ puro.
O principal objetivo do minigpt4.cpp é executar o Minigpt4 usando quantização de 4 bits com o uso da biblioteca GGML.
Requisitos : Git
git clone --recursive https://github.com/Maknee/minigpt4.cpp
cd minigpt4.cpp Vá para lançamentos e extrair arquivo da biblioteca minigpt4 no diretório do repositório.
Requisitos : Cmake, Visual Studio e Git
cmake .
cmake --build . --config Release
binReleaseminigpt4.dll deve ser gerado
Requisitos : CMake (Ubuntu: sudo apt install cmake )
cmake .
cmake --build . --config Release minigpt4.so deve ser gerado
Requisitos : CMake (MacOS: brew install cmake )
cmake .
cmake --build . --config Release minigpt4.dylib deve ser gerado
NOTA: Se você construir com o OpenCV (permitindo recursos como carregamento e pré ON na própria biblioteca), defina MINIGPT4_BUILD_WITH_OPENCV em CMakeLists.txt ou construir com -DMINIGPT4_BUILD_WITH_OPENCV=ON como um parâmetro para o Cmake.
Modelos pré-quantizados estão disponíveis para abraçar o rosto ~ 7b ou 13b.
Recomendado para resultados confiáveis, mas lenta velocidade de inferência: minigpt4-13b-f16.bin
Requisitos : Python 3.x e Pytorch.
Clone o repositório Minigpt-4 e execute a configuração
cd minigpt4
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4 Faça o download do ponto de verificação pré-treinado no repositório Minigpt-4 em Checkpoint Aligned with Vicuna 7B ou Checkpoint Aligned with Vicuna 13B ou faça o download do link HuggingFace para 7b ou 13b
Converta os pesos do modelo em formato GGML
Modelo 7b
cd minigpt4
python convert.py C:pretrained_minigpt4_7b.pth --ftype=f16
Modelo 13b
cd minigpt4
python convert.py C:pretrained_minigpt4.pth --ftype=f16
Modelo 7b
python convert.py ~ /Downloads/pretrained_minigpt4_7b.pth --outtype f16Modelo 13b
python convert.py ~ /Downloads/pretrained_minigpt4.pth --outtype f16 minigpt4-7B-f16.bin ou minigpt4-13B-f16.bin devem ser gerados
Modelos pré-Quantizados estão disponíveis para abraçar o rosto
Recomendado para resultados confiáveis e velocidade de inferência decente: ggml-vicuna-13b-v0-q5_k.bin
Requisitos : Python 3.x e Pytorch.
Siga o guia do minigpt4 para obter o modelo Vicuna-V0.
Então, clone llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake .
cmake --build . --config ReleaseConverta o modelo em GGML
python convert.py < path-to-model >Quantize o modelo
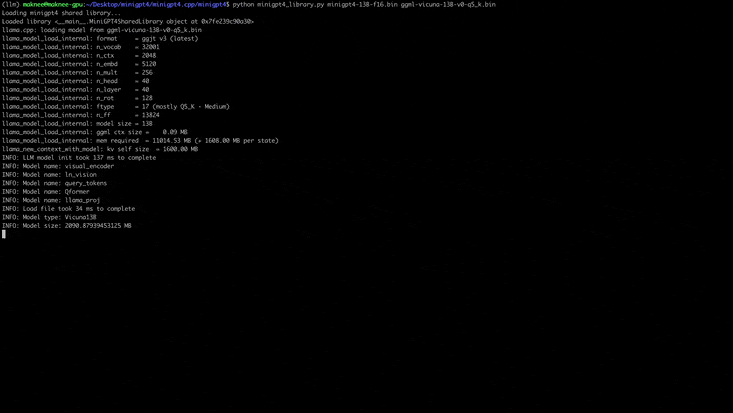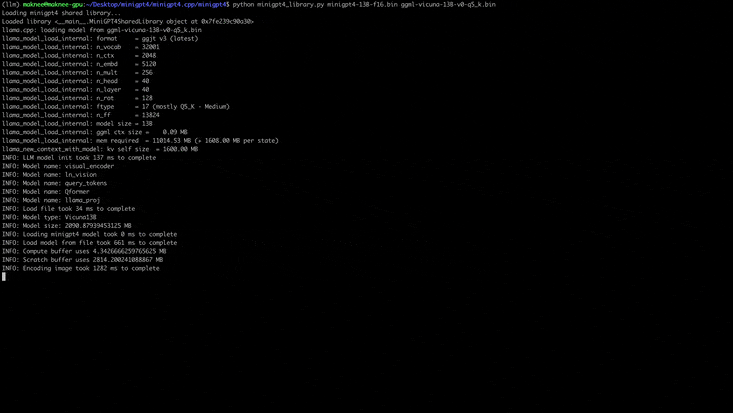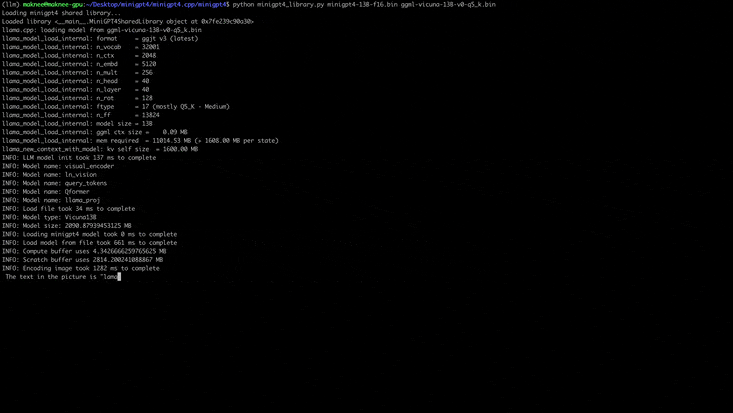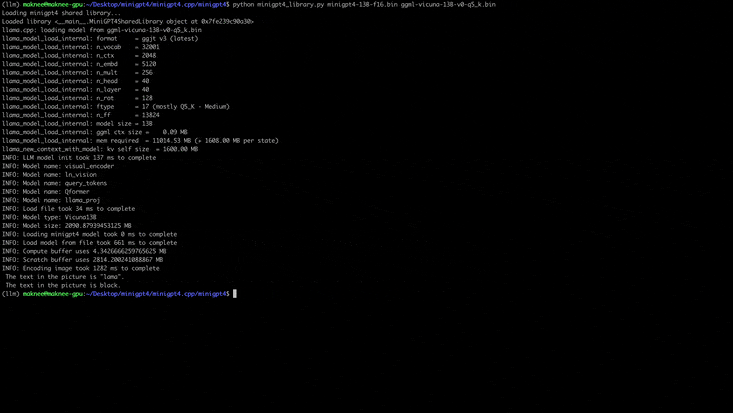
python quanitize < path-to-model > < output-model > Q4_1 Teste se o Minigpt4 funciona ligando para o seguinte, substituindo minigpt4-13B-f16.bin e ggml-vicuna-13B-v0-q5_k.bin com seus respectivos modelos
cd minigpt4
python minigpt4_library.py minigpt4-13B-f16.bin ggml-vicuna-13B-v0-q5_k.binInstale os requisitos para o webui
pip install -r requirements.txt Em seguida, execute o webui, substituindo minigpt4-13B-f16.bin e ggml-vicuna-13B-v0-q5_k.bin com seus respectivos modelos
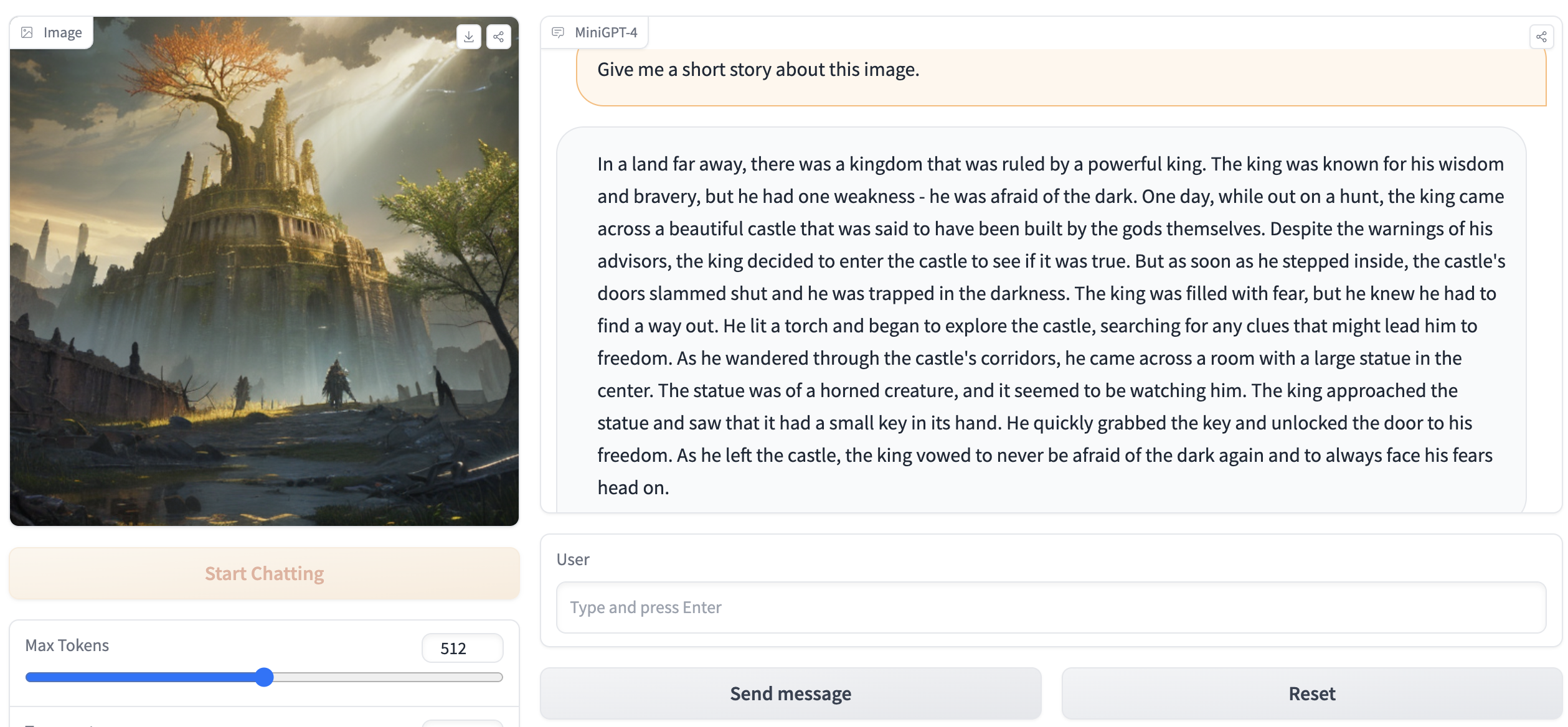
python webui.py minigpt4-13B-f16.bin ggml-vicuna-13B-v0-q5_k.binA saída deve conter algo como o seguinte:
Running on local URL: http://127.0.0.1:7860
To create a public link, set ` share=True ` in `launch () ` . Vá para http://127.0.0.1:7860 no seu navegador e você poderá interagir com o webui.


