AVIDa SARS CoV 2
1.0.0
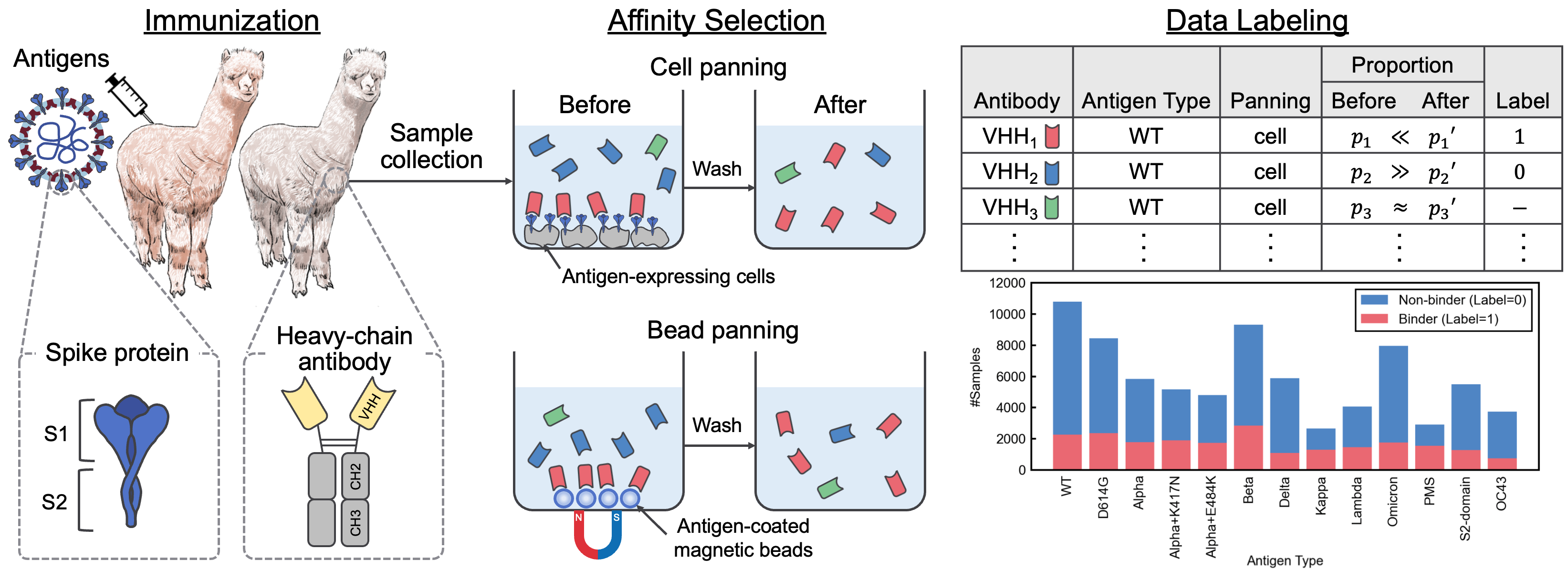
Este repositório contém o material suplementar que acompanha o artigo "Um conjunto de dados de interação SARS-CoV-2 e corpus de sequência VHH para modelos de linguagem de anticorpos". Neste artigo, introduzimos o AVIDA-SARS-COV-2, um conjunto de dados rotulado de interações SARS-CoV-2-VHH, e VHHCorpus-2M, que contém mais de dois milhões de sequências VHH, fornecendo novos conjuntos de dados para a avaliação e pré-treinamento de modelos de linguagem de anticorpos. Os conjuntos de dados estão disponíveis em https://datasets.cognansous.com sob uma licença CC BY-NC 4.0.
Para começar, clone este repositório e execute o comando a seguir para criar um ambiente virtual.
python -m venv ./venv
source ./venv/bin/activate
pip install -r requirements.txt| Conjunto de dados | Links |
|---|---|
| Vhhcorpus-2m | Hub de abraçar a página do projeto do hub |
| AVIDA-SARS-COV-2 | Hub de abraçar a página do projeto do hub |
O código para converter os dados brutos (arquivo FastQ) obtido do sequenciamento de próxima geração (NGS) no conjunto de dados rotulado, Avida-SARS-Cov-2, pode ser encontrado em ./dataset . Lançamos os arquivos FastQ para o tipo de antígeno "OC43" aqui para que o processamento de dados possa ser reproduzido.
Primeiro, você precisa criar uma imagem do Docker.
docker build -t vhh_constructor:latest ./dataset/vhh_constructor Depois de colocar os arquivos FastQ em dataset/raw/fastq , execute o comando a seguir para produzir um arquivo CSV rotulado.
bash ./dataset/preprocess.shVhhbert é um modelo baseado em Roberta pré-treinado em dois milhões de sequências VHH em VHHCorpus-2M. Vhhbert pode ser pré-treinado com os seguintes comandos.
python benchmarks/pretrain.py --vocab-file " benchmarks/data/vocab_vhhbert.txt "
--epochs 20
--batch-size 128
--save-dir " outputs "Argumentos:
| Argumento | Obrigatório | Padrão | Descrição |
|---|---|---|---|
| -File-vocab | Sim | Caminho do arquivo de vocabulário | |
| --epochs | Não | 20 | Número de épocas |
| -tamanho do lote | Não | 128 | Tamanho do mini-lote |
| --semente | Não | 123 | Semente aleatória |
| --save-Dir | Não | ./Saved | Caminho do diretório salvo |
O Vhhbert pré-treinado, divulgado sob a licença do MIT, está disponível no Hugging Face Hub.
Para avaliar o desempenho de vários modelos de idiomas pré-treinados para a descoberta de anticorpos, definimos uma tarefa de classificação binária para prever a ligação ou a não ligação de anticorpos desconhecidos a 13 antígenos usando AVIDA-SARS-COV-2. Para obter mais informações sobre a tarefa de benchmarking, consulte o artigo.
O ajuste fino dos modelos de idiomas pode ser executado usando o seguinte comando.
python benchmarks/finetune.py --palm-type " VHHBERT "
--epochs 30
--batch-size 32
--save-dir " outputs " palm-type deve ser um dos seguintes:
VHHBERTVHHBERT-w/o-PTAbLangAntiBERTa2AntiBERTa2-CSSPIgBertProtBertESM-2-150MESM-2-650MArgumentos:
| Argumento | Obrigatório | Padrão | Descrição |
|---|---|---|---|
| --Palm-tipo | Não | Vhhbert | Nome do modelo |
| -Eembeddings-File | Não | ./benchmarks/data/antigen_embeddings.pkl | Caminho do arquivo de incorporação para antígenos |
| --epochs | Não | 20 | Número de épocas |
| -tamanho do lote | Não | 128 | Tamanho do mini-lote |
| --semente | Não | 123 | Semente aleatória |
| --save-Dir | Não | ./Saved | Caminho do diretório salvo |
Se você usar Avida-SARS-Cov-2, VHHCorpus-2M ou Vhhbert em sua pesquisa, use a seguinte citação.
@inproceedings { tsuruta2024sars ,
title = { A {SARS}-{C}o{V}-2 Interaction Dataset and {VHH} Sequence Corpus for Antibody Language Models } ,
author = { Hirofumi Tsuruta and Hiroyuki Yamazaki and Ryota Maeda and Ryotaro Tamura and Akihiro Imura } ,
booktitle = { Advances in Neural Information Processing Systems 37 } ,
year = { 2024 }
}

