AVIDa SARS CoV 2
1.0.0
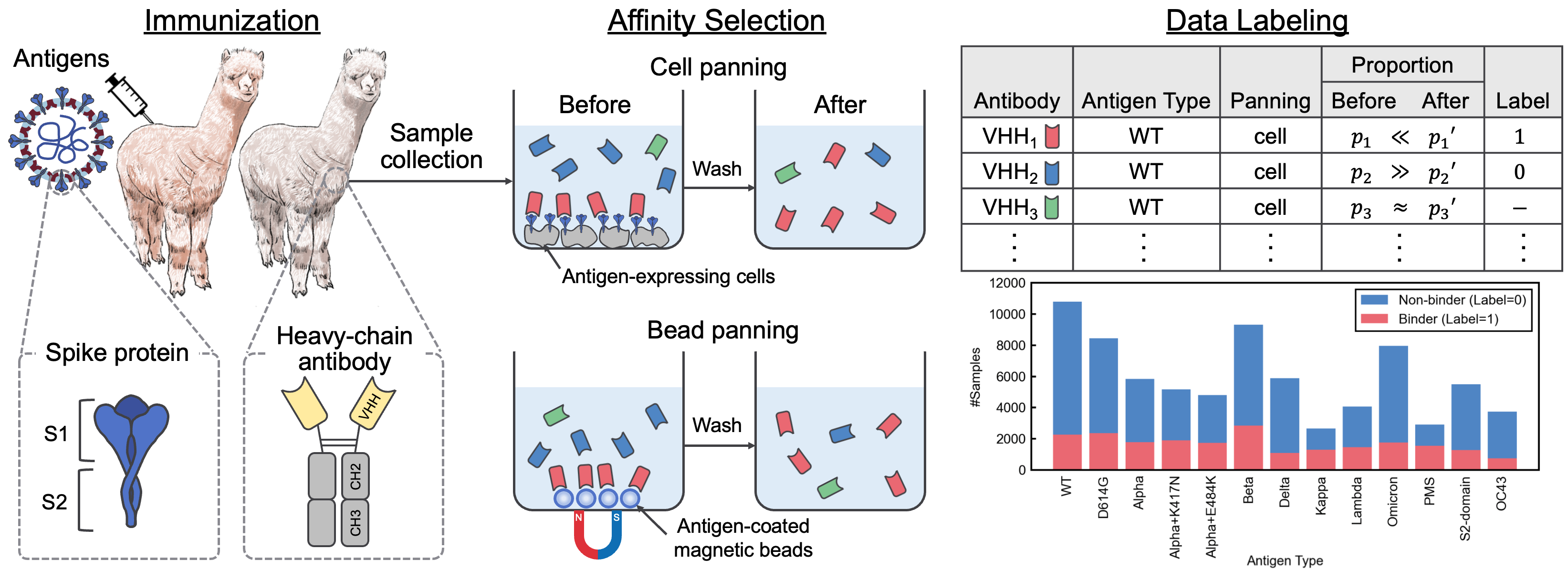
このリポジトリには、「抗体言語モデル用のSARS-COV-2インタラクションデータセットとVHHシーケンスコーパス」という論文に付随する補足資料が含まれています。この論文では、SARS-COV-2-VHH相互作用のラベル付きデータセットであるAvida-SARS-COV-2と、200万を超えるVHHシーケンスを含むVHHCORPUS-2Mを導入し、抗体言語モデルの評価と事前トレーニングのための新しいデータセットを提供しました。データセットは、CC BY-NC 4.0ライセンスの下でhttps://datasets.cognanous.comで入手できます。
開始するには、このリポジトリをクローンし、次のコマンドを実行して仮想環境を作成します。
python -m venv ./venv
source ./venv/bin/activate
pip install -r requirements.txt| データセット | リンク |
|---|---|
| vhhcorpus-2m | フェイスハブプロジェクトの抱き合ったページ |
| Avida-Sars-Cov-2 | フェイスハブプロジェクトの抱き合ったページ |
次世代シーケンス(NGS)から取得した生データ(FASTQファイル)をラベル付きデータセットであるAvida-Sars-Cov-2に変換するためのコードは、 ./datasetの下にあります。ここでは、抗原タイプ「OC43」のFastQファイルをリリースして、データ処理を再現できるようにしました。
まず、Docker画像を作成する必要があります。
docker build -t vhh_constructor:latest ./dataset/vhh_constructor fastQファイルをdataset/raw/fastqの下に配置した後、次のコマンドを実行して、ラベル付きのCSVファイルを出力します。
bash ./dataset/preprocess.shVHHBERTは、VHHCORPUS-2Mの200万VHHシーケンスで事前に訓練されたロバータに拠点を置くモデルです。 VHHBERTは、次のコマンドで事前に訓練できます。
python benchmarks/pretrain.py --vocab-file " benchmarks/data/vocab_vhhbert.txt "
--epochs 20
--batch-size 128
--save-dir " outputs "議論:
| 口論 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| --vocab-file | はい | 語彙ファイルのパス | |
| -epochs | いいえ | 20 | 時代の数 |
| - バッチサイズ | いいえ | 128 | ミニバッチのサイズ |
| - シード | いいえ | 123 | ランダムシード |
| -Save-Dir | いいえ | ./saved | 保存ディレクトリのパス |
MITライセンスの下でリリースされた事前に訓練されたVHHBERTは、抱きしめるフェイスハブで入手できます。
抗体発見のためのさまざまな事前訓練を受けた言語モデルのパフォーマンスを評価するために、Avida-SARS-COV-2を使用して、13の抗原に対する未知の抗体の結合または非結合を予測するバイナリ分類タスクを定義しました。ベンチマークタスクの詳細については、論文を参照してください。
言語モデルの微調整は、次のコマンドを使用して実行できます。
python benchmarks/finetune.py --palm-type " VHHBERT "
--epochs 30
--batch-size 32
--save-dir " outputs " palm-type次のいずれかでなければなりません。
VHHBERTVHHBERT-w/o-PTAbLangAntiBERTa2AntiBERTa2-CSSPIgBertProtBertESM-2-150MESM-2-650M議論:
| 口論 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| - パルムタイプ | いいえ | vhhbert | モデル名 |
| -embeddings-file | いいえ | ./benchmarks/data/antigen_embeddings.pkl | 抗原の埋め込みパスファイル |
| -epochs | いいえ | 20 | 時代の数 |
| - バッチサイズ | いいえ | 128 | ミニバッチのサイズ |
| - シード | いいえ | 123 | ランダムシード |
| -Save-Dir | いいえ | ./saved | 保存ディレクトリのパス |
Avida-Sars-Cov-2、vhhcorpus-2m、またはvhhbertを使用している場合は、以下の引用を使用してください。
@inproceedings { tsuruta2024sars ,
title = { A {SARS}-{C}o{V}-2 Interaction Dataset and {VHH} Sequence Corpus for Antibody Language Models } ,
author = { Hirofumi Tsuruta and Hiroyuki Yamazaki and Ryota Maeda and Ryotaro Tamura and Akihiro Imura } ,
booktitle = { Advances in Neural Information Processing Systems 37 } ,
year = { 2024 }
}

