AVIDa SARS CoV 2
1.0.0
Este repositorio contiene el material complementario que acompaña al documento "un conjunto de datos de interacción SARS-CoV-2 y Corpus de secuencia VHH para modelos de lenguaje de anticuerpos". En este documento, introdujimos AVIDA-SARS-COV-2, un conjunto de datos etiquetado de interacciones SARS-CoV-2-VHH, y VHHCorpus-2M, que contiene más de dos millones de secuencias VHH, proporcionando conjuntos de datos novedosos para la evaluación y la capacitación previa de modelos de lenguaje de anticuerpos. Los conjuntos de datos están disponibles en https://datasets.cognanous.com bajo una licencia CC BY-NC 4.0.
Para comenzar, clone este repositorio y ejecute el siguiente comando para crear un entorno virtual.
python -m venv ./venv
source ./venv/bin/activate
pip install -r requirements.txt| Conjunto de datos | Campo de golf |
|---|---|
| Vhhcorpus-2m | Página del proyecto de abrazo de cara de Face |
| Avida-sars-cov-2 | Página del proyecto de abrazo de cara de Face |
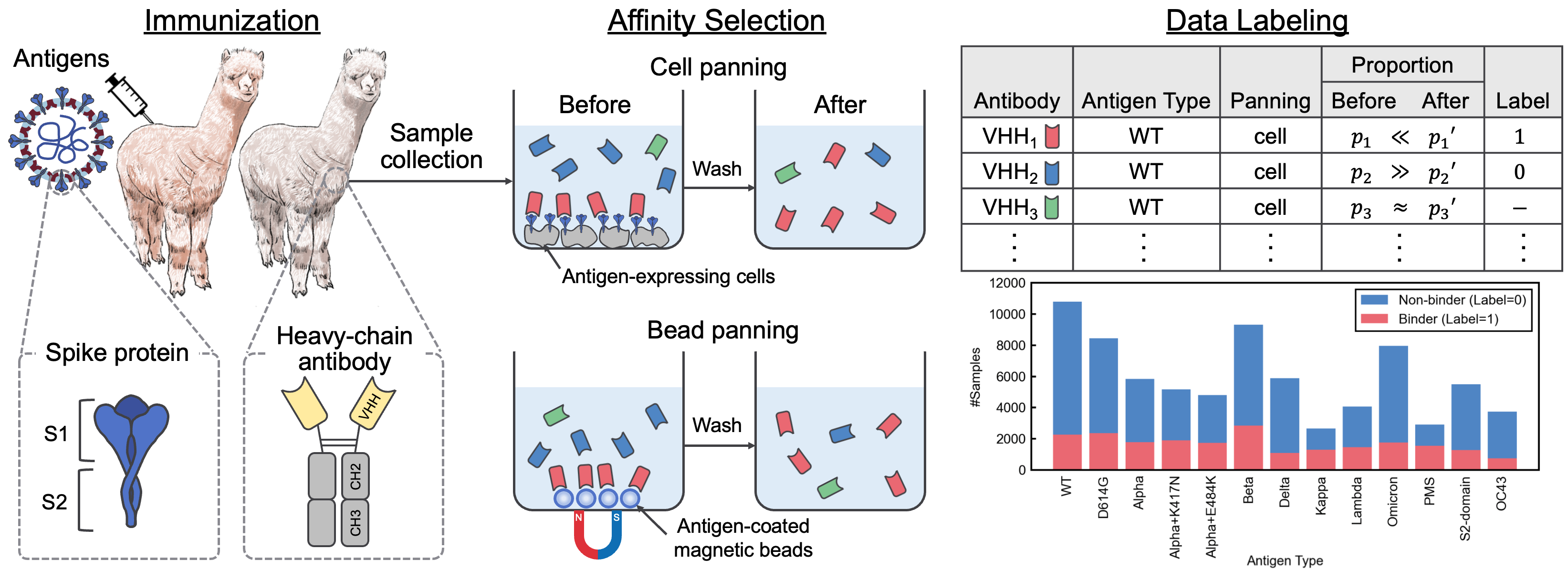
El código para convertir los datos sin procesar (archivo FASTQ) obtenido de la secuenciación de próxima generación (NGS) en el conjunto de datos etiquetado, AVIDA-SARS-CoV-2, se puede encontrar en ./dataset . Lanzamos los archivos FASTQ para el tipo de antígeno "OC43" aquí para que se pueda reproducir el procesamiento de datos.
Primero, debe crear una imagen Docker.
docker build -t vhh_constructor:latest ./dataset/vhh_constructor Después de colocar los archivos FASTQ en dataset/raw/fastq , ejecute el siguiente comando para emitir un archivo CSV etiquetado.
bash ./dataset/preprocess.shVhhbert es un modelo con sede en Roberta previamente entrenado en dos millones de secuencias VHH en VHHCorpus-2M. Vhhbert se puede capacitar previamente con los siguientes comandos.
python benchmarks/pretrain.py --vocab-file " benchmarks/data/vocab_vhhbert.txt "
--epochs 20
--batch-size 128
--save-dir " outputs "Argumentos:
| Argumento | Requerido | Por defecto | Descripción |
|---|---|---|---|
| -vocab-archivo | Sí | Ruta del archivo de vocabulario | |
| -epochs | No | 20 | Número de épocas |
| --m.datess | No | 128 | Tamaño de mini lote |
| --semilla | No | 123 | Semilla aleatoria |
| --save-dirir | No | ./ | Ruta del directorio de guardado |
El Vhhbert previamente entrenado, lanzado bajo la licencia MIT, está disponible en el Hub de la cara abrazada.
Para evaluar el rendimiento de varios modelos de lenguaje previamente capacitados para el descubrimiento de anticuerpos, definimos una tarea de clasificación binaria para predecir la unión o no vinculante de anticuerpos desconocidos a 13 antígenos utilizando AVIDA-SARS-CoV-2. Para obtener más información sobre la tarea de evaluación comparativa, consulte el documento.
El ajuste de los modelos de lenguaje se puede realizar utilizando el siguiente comando.
python benchmarks/finetune.py --palm-type " VHHBERT "
--epochs 30
--batch-size 32
--save-dir " outputs " palm-type debe ser uno de los siguientes:
VHHBERTVHHBERT-w/o-PTAbLangAntiBERTa2AntiBERTa2-CSSPIgBertProtBertESM-2-150MESM-2-650MArgumentos:
| Argumento | Requerido | Por defecto | Descripción |
|---|---|---|---|
| --lipal | No | Vhhbert | Nombre del modelo |
| --Imbeddings-File | No | ./benchmarks/data/antigen_embeddings.pkl | Ruta del archivo de incrustaciones para antígenos |
| -epochs | No | 20 | Número de épocas |
| --m.datess | No | 128 | Tamaño de mini lote |
| --semilla | No | 123 | Semilla aleatoria |
| --save-dirir | No | ./ | Ruta del directorio de guardado |
Si usa Avida-Sars-Cov-2, Vhhcorpus-2m o Vhhbert en su investigación, utilice la siguiente cita.
@inproceedings { tsuruta2024sars ,
title = { A {SARS}-{C}o{V}-2 Interaction Dataset and {VHH} Sequence Corpus for Antibody Language Models } ,
author = { Hirofumi Tsuruta and Hiroyuki Yamazaki and Ryota Maeda and Ryotaro Tamura and Akihiro Imura } ,
booktitle = { Advances in Neural Information Processing Systems 37 } ,
year = { 2024 }
}

