AVIDa SARS CoV 2
1.0.0
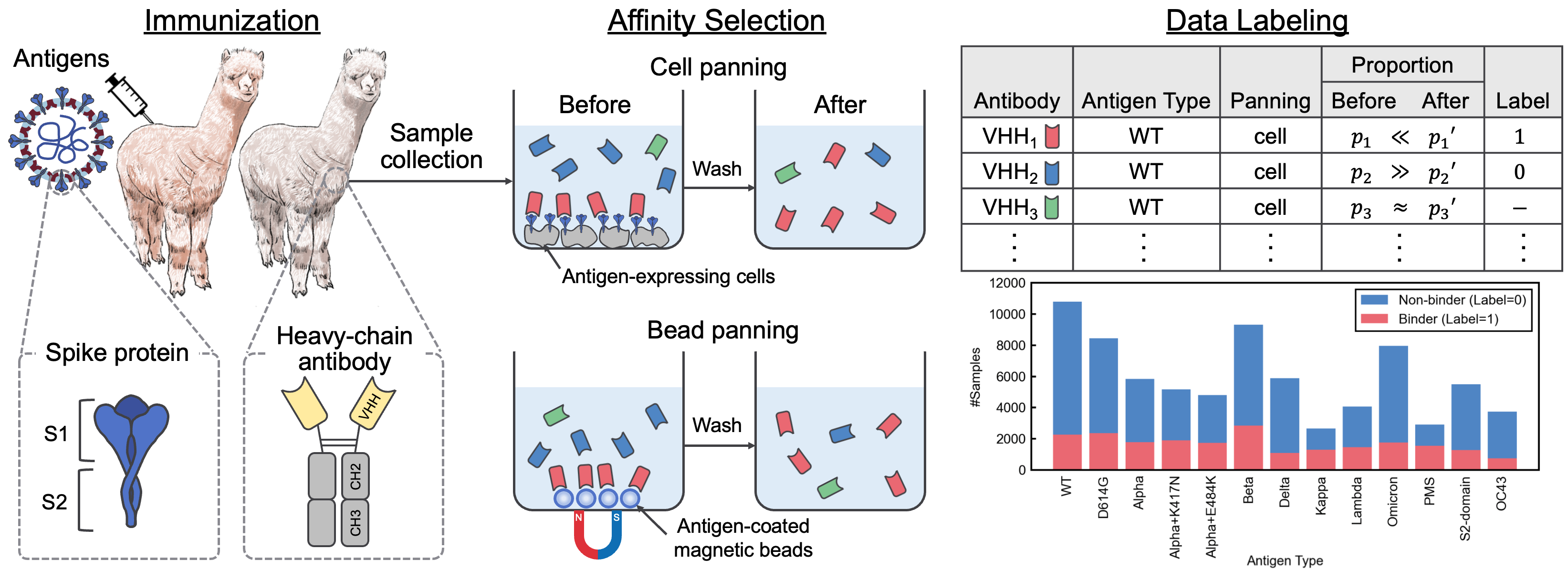
이 저장소에는 "항체 언어 모델에 대한 SARS-COV-2 상호 작용 데이터 세트 및 VHH 서열 코퍼스"와 함께 제공되는 보충 자료가 포함되어 있습니다. 이 논문에서, 본 발명자들은 SARS-COV-2-VHH 상호 작용의 라벨링 된 데이터 세트 인 Avida-SARS-COV-2 및 2 백만 개 이상의 VHH 서열을 포함하는 VHHCORPUS-2M을 도입하여 항체 언어 모델의 평가 및 사전 훈련을위한 새로운 데이터 세트를 제공했다. 데이터 세트는 https://datasets.cognanous.com에서 CC By-NC 4.0 라이센스로 제공됩니다.
시작하려면이 저장소를 복제하고 다음 명령을 실행하여 가상 환경을 만듭니다.
python -m venv ./venv
source ./venv/bin/activate
pip install -r requirements.txt| 데이터 세트 | 모래밭 |
|---|---|
| VHHCORPUS-2M | 포옹 얼굴 허브 프로젝트 페이지 |
| Avida-Sars-Cov-2 | 포옹 얼굴 허브 프로젝트 페이지 |
차세대 시퀀싱 (NGS)에서 얻은 원시 데이터 (FASTQ 파일)를 라벨이 붙은 데이터 세트 인 Avida-Sars-Cov-2로 변환하는 코드는 ./dataset 에서 찾을 수 있습니다. 데이터 처리를 재현 할 수 있도록 항원 유형 "OC43"에 대한 FASTQ 파일을 여기에서 출시했습니다.
먼저 Docker 이미지를 만들어야합니다.
docker build -t vhh_constructor:latest ./dataset/vhh_constructor dataset/raw/fastq 에 FastQ 파일을 배치 한 후 다음 명령을 실행하여 레이블이 지정된 CSV 파일을 출력하십시오.
bash ./dataset/preprocess.shVHHBERT는 VHHCORPUS-2M에서 2 백만 VHH 서열에서 미리 훈련 된 Roberta 기반 모델입니다. VHHBERT는 다음 명령으로 미리 훈련 할 수 있습니다.
python benchmarks/pretrain.py --vocab-file " benchmarks/data/vocab_vhhbert.txt "
--epochs 20
--batch-size 128
--save-dir " outputs "논쟁 :
| 논쟁 | 필수의 | 기본 | 설명 |
|---|---|---|---|
| -Vocab-file | 예 | 어휘 파일의 경로 | |
| --epochs | 아니요 | 20 | 에포크 수 |
| -배치 크기 | 아니요 | 128 | 미니 배치의 크기 |
| --씨앗 | 아니요 | 123 | 임의의 씨앗 |
| -Save-Dir | 아니요 | ./saved | 저장 디렉토리의 경로 |
MIT 라이센스에 따라 출시 된 미리 훈련 된 VHHBERT는 Hugging Face Hub에서 사용할 수 있습니다.
항체 발견에 대한 다양한 미리 훈련 된 언어 모델의 성능을 평가하기 위해, 본 발명자들은 Avida-SARS-COV-2를 사용하여 13 개의 항원에 알려지지 않은 항체의 결합 또는 결합을 예측하기 위해 이진 분류 작업을 정의했습니다. 벤치마킹 작업에 대한 자세한 내용은 논문을 참조하십시오.
언어 모델의 미세 조정은 다음 명령을 사용하여 수행 할 수 있습니다.
python benchmarks/finetune.py --palm-type " VHHBERT "
--epochs 30
--batch-size 32
--save-dir " outputs " palm-type 다음 중 하나 여야합니다.
VHHBERTVHHBERT-w/o-PTAbLangAntiBERTa2AntiBERTa2-CSSPIgBertProtBertESM-2-150MESM-2-650M논쟁 :
| 논쟁 | 필수의 | 기본 | 설명 |
|---|---|---|---|
| -팔름 형 | 아니요 | vhhbert | 모델 이름 |
| --embeddings-file | 아니요 | ./benchmarks/data/antigen_embeddings.pkl | 항원에 대한 임베딩 파일 |
| --epochs | 아니요 | 20 | 에포크 수 |
| -배치 크기 | 아니요 | 128 | 미니 배치의 크기 |
| --씨앗 | 아니요 | 123 | 임의의 씨앗 |
| -Save-Dir | 아니요 | ./saved | 저장 디렉토리의 경로 |
연구에서 avida-sars-cov-2, vhhcorpus-2m 또는 vhhbert를 사용하는 경우 다음 인용을 사용하십시오.
@inproceedings { tsuruta2024sars ,
title = { A {SARS}-{C}o{V}-2 Interaction Dataset and {VHH} Sequence Corpus for Antibody Language Models } ,
author = { Hirofumi Tsuruta and Hiroyuki Yamazaki and Ryota Maeda and Ryotaro Tamura and Akihiro Imura } ,
booktitle = { Advances in Neural Information Processing Systems 37 } ,
year = { 2024 }
}

