AVIDa SARS CoV 2
1.0.0
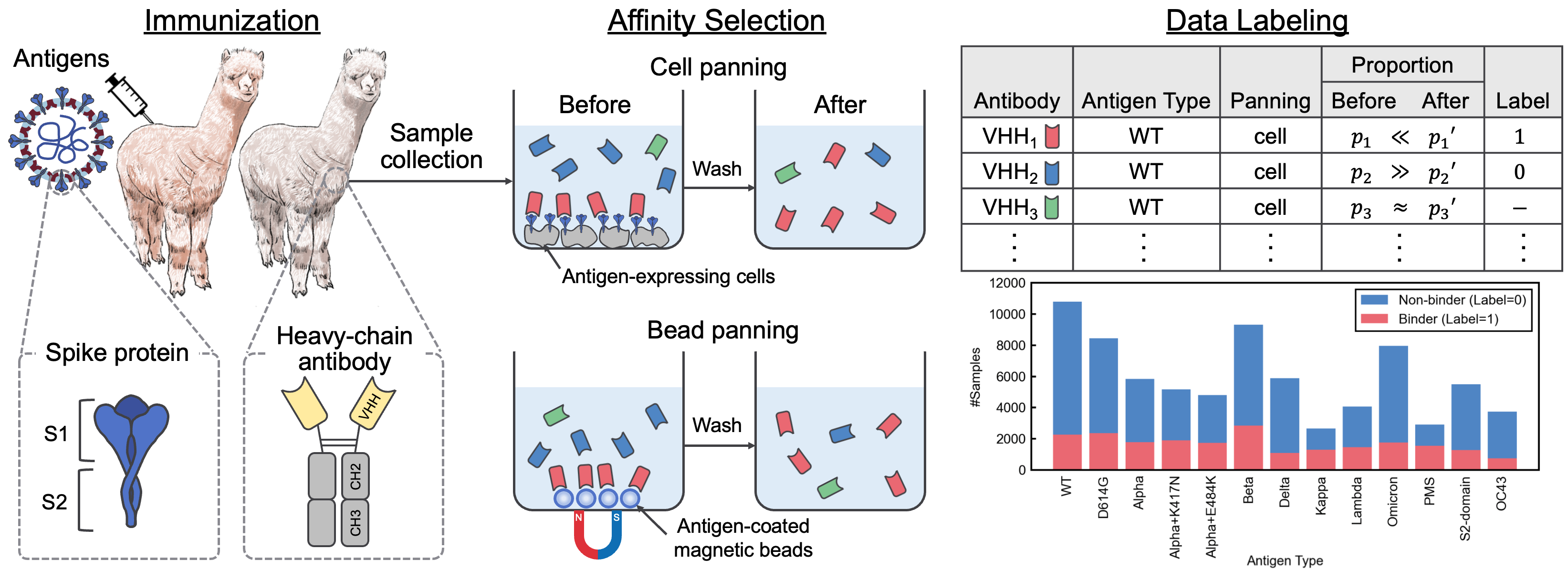
Repositori ini berisi materi tambahan yang menyertai kertas "SARS-COV-2 Interaction Dataset dan VHH Sequence Corpus untuk model bahasa antibodi." Dalam makalah ini, kami memperkenalkan Avida-SARS-COV-2, dataset berlabel interaksi SARS-COV-2-VHH, dan VHHCORPUS-2M, yang berisi lebih dari dua juta sekuens VHH, memberikan dataset baru untuk evaluasi dan pelatihan model bahasa antibodi. Dataset tersedia di https://datasets.cognanous.com di bawah lisensi CC BY-NC 4.0.
Untuk memulai, klon repositori ini dan jalankan perintah berikut untuk menciptakan lingkungan virtual.
python -m venv ./venv
source ./venv/bin/activate
pip install -r requirements.txt| Dataset | Tautan |
|---|---|
| VHHCORPUS-2M | HUKUR HUBUNGI HUB HUB FACE |
| Avida-Sars-Cov-2 | HUKUR HUBUNGI HUB HUB FACE |
Kode untuk mengonversi data mentah (file FastQ) yang diperoleh dari sequencing generasi berikutnya (NGS) ke dalam dataset berlabel, Avida-SARS-COV-2, dapat ditemukan di bawah ./dataset . Kami merilis file FastQ untuk jenis antigen "OC43" di sini sehingga pemrosesan data dapat direproduksi.
Pertama, Anda perlu membuat gambar Docker.
docker build -t vhh_constructor:latest ./dataset/vhh_constructor Setelah menempatkan file FASTQ di bawah dataset/raw/fastq , jalankan perintah berikut untuk mengeluarkan file CSV berlabel.
bash ./dataset/preprocess.shVhhbert adalah model yang berbasis di Roberta yang pra-terlatih pada dua juta urutan VHH di VHHCORPUS-2M. Vhhbert dapat dilatih sebelumnya dengan perintah berikut.
python benchmarks/pretrain.py --vocab-file " benchmarks/data/vocab_vhhbert.txt "
--epochs 20
--batch-size 128
--save-dir " outputs "Argumen:
| Argumen | Diperlukan | Bawaan | Keterangan |
|---|---|---|---|
| --Vocab-File | Ya | Jalur file kosa kata | |
| --epochs | TIDAK | 20 | Jumlah zaman |
| --Batch-size | TIDAK | 128 | Ukuran mini-batch |
| --benih | TIDAK | 123 | Benih acak |
| -Save-Dir | TIDAK | ./saved | Jalur Direktori Simpan |
Vhhbert pra-terlatih, yang dirilis di bawah lisensi MIT, tersedia di Hugging Face Hub.
Untuk mengevaluasi kinerja berbagai model bahasa pra-terlatih untuk penemuan antibodi, kami mendefinisikan tugas klasifikasi biner untuk memprediksi pengikatan atau pengikatan antibodi yang tidak diketahui dengan 13 antigen menggunakan Avida-SARS-COV-2. Untuk informasi lebih lanjut tentang tugas pembandingan, lihat koran.
Penyesuaian model bahasa dapat dilakukan dengan menggunakan perintah berikut.
python benchmarks/finetune.py --palm-type " VHHBERT "
--epochs 30
--batch-size 32
--save-dir " outputs " palm-type harus menjadi salah satu dari yang berikut:
VHHBERTVHHBERT-w/o-PTAbLangAntiBERTa2AntiBERTa2-CSSPIgBertProtBertESM-2-150MESM-2-650MArgumen:
| Argumen | Diperlukan | Bawaan | Keterangan |
|---|---|---|---|
| --Palm-Type | TIDAK | Vhhbert | Nama model |
| -Meddings-File | TIDAK | ./benchmarks/data/antigen_embeddings.pkl | Jalur file embeddings untuk antigen |
| --epochs | TIDAK | 20 | Jumlah zaman |
| --Batch-size | TIDAK | 128 | Ukuran mini-batch |
| --benih | TIDAK | 123 | Benih acak |
| -Save-Dir | TIDAK | ./saved | Jalur Direktori Simpan |
Jika Anda menggunakan Avida-Sars-Cov-2, Vhhcorpus-2m, atau Vhhbert dalam penelitian Anda, silakan gunakan kutipan berikut.
@inproceedings { tsuruta2024sars ,
title = { A {SARS}-{C}o{V}-2 Interaction Dataset and {VHH} Sequence Corpus for Antibody Language Models } ,
author = { Hirofumi Tsuruta and Hiroyuki Yamazaki and Ryota Maeda and Ryotaro Tamura and Akihiro Imura } ,
booktitle = { Advances in Neural Information Processing Systems 37 } ,
year = { 2024 }
}

