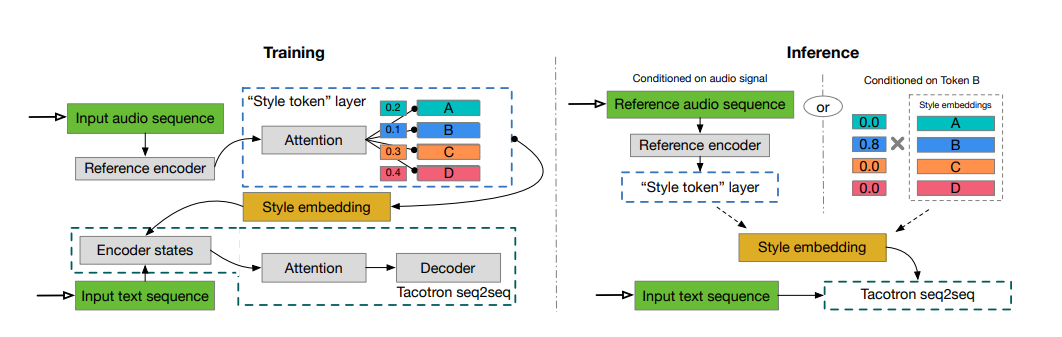
GST Tacotron
1.0.0
Uma implementação de Pytorch de tokens de estilo: modelagem de estilo, controle e transferência de estilo não supervisionado na síntese de fala de ponta a ponta
Adicione suporte ao conjunto de dados da Blizzard.
pip3 install -r requirements.txtHyperparameters.py --- HyperparametersNetwork.py --- codificador e decodificadorModules.py --- alguns módulos para tacotronLoss.py --- Função de perdaData.py --- carregador de dadosutils.py --- algumas funções utilizadas para E/S de dadosSynthesis.py --- geração de fala get_XX_data em Data.pyHyperparameters.pylog da seguinte forma: --- log
| |
| --- log[log_number]
|
--- code
|
--- Tacotron
|
--- train.py
|
--- Network.py
|
......
python3 train.py [log_number] [dataset_size] [start_epoch]
[log_number]: the log directory number
[dataset_size]: int or all
[start_epoch]: which epoch start to train (0 if start from scratch )
for example:
python3 train.py 0 all 0 Executar generate.py . Substitua o text em generate.py por qualquer frase chinesa como você quiser antes de correr
O modelo preso fornecido é treinado no conjunto de dados chinês, por isso suporta apenas chinês agora.


