GST Tacotron
1.0.0
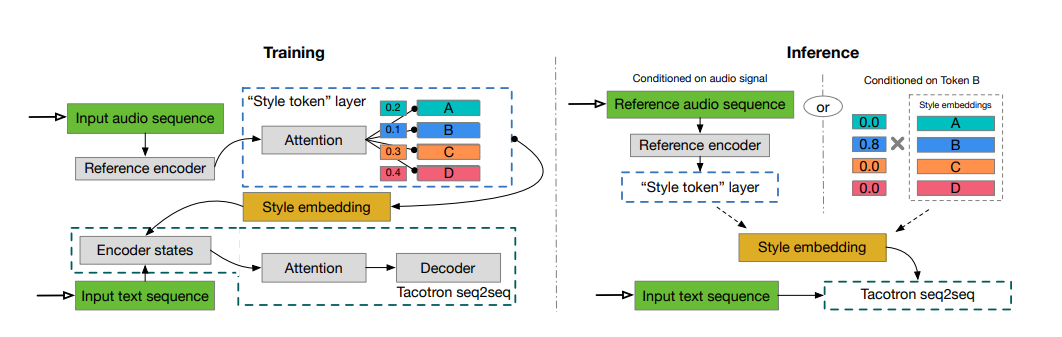
A PyTorch implementation of Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
Add support for blizzard dataset.
pip3 install -r requirements.txtHyperparameters.py --- hyperparametersNetwork.py --- encoder and decoderModules.py --- some modules for tacotronLoss.py --- loss functionData.py --- dataset loaderutils.py --- some util functions for data I/OSynthesis.py --- speech generationget_XX_data function in Data.pyHyperparameters.pylog as follow:--- log
| |
| --- log[log_number]
|
--- code
|
--- Tacotron
|
--- train.py
|
--- Network.py
|
......
python3 train.py [log_number] [dataset_size] [start_epoch]
[log_number]: the log directory number
[dataset_size]: int or all
[start_epoch]: which epoch start to train (0 if start from scratch )
for example:
python3 train.py 0 all 0Rungenerate.py. Replace the text in generate.py with any chinese sentences as you like before running
The pretained model provided is trained on Chinese dataset, so it only supports chinese now.


