GST Tacotron
1.0.0
Una implementación de Pytorch de tokens de estilo: modelado de estilo no supervisado, control y transferencia en síntesis de habla de extremo a extremo
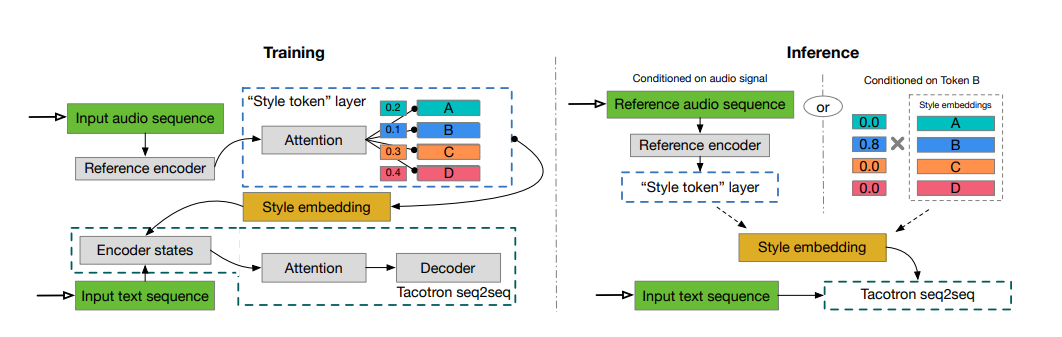
Agregue soporte para el conjunto de datos de Blizzard.
pip3 install -r requirements.txtHyperparameters.py --- HyperparametersNetwork.py --- codificador y decodificadorModules.py --- algunos módulos para tacotrónLoss.py --- función de pérdidaData.py --- cargador de conjunto de datosutils.py --- algunas funciones de Util para E/S de datosSynthesis.py --- Generación del habla get_XX_data en Data.pyHyperparameters.pylog de la siguiente manera: --- log
| |
| --- log[log_number]
|
--- code
|
--- Tacotron
|
--- train.py
|
--- Network.py
|
......
python3 train.py [log_number] [dataset_size] [start_epoch]
[log_number]: the log directory number
[dataset_size]: int or all
[start_epoch]: which epoch start to train (0 if start from scratch )
for example:
python3 train.py 0 all 0 Ejecutar generate.py . Reemplace el text en generate.py con cualquier oración china como desee antes de correr
El modelo pretendido proporcionado está capacitado en el conjunto de datos chino, por lo que ahora solo admite chino.


