GST Tacotron
1.0.0
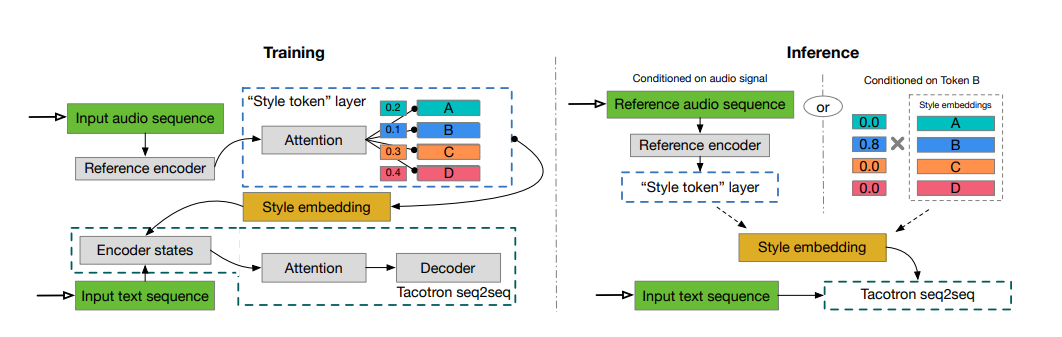
Eine Pytorch-Implementierung von Style-Token: unbeaufsichtigte Modellierung, Kontrolle und Übertragung in der End-to-End-Sprachsynthese
Fügen Sie Unterstützung für Blizzard -Datensatz hinzu.
pip3 install -r requirements.txtHyperparameters.py --- HyperparameterNetwork.py --- Encoder und DecoderModules.py --- Einige Module für TacotronLoss.py --- VerlustfunktionData.py --- Datensatzladerutils.py --- Einige Util-Funktionen für die Daten i/oSynthesis.py --- Sprachgenerierung get_XX_data in Data.pyHyperparameters.py einstellen.pylog : --- log
| |
| --- log[log_number]
|
--- code
|
--- Tacotron
|
--- train.py
|
--- Network.py
|
......
python3 train.py [log_number] [dataset_size] [start_epoch]
[log_number]: the log directory number
[dataset_size]: int or all
[start_epoch]: which epoch start to train (0 if start from scratch )
for example:
python3 train.py 0 all 0 Run generate.py . Ersetzen Sie den text in generate.py durch alle chinesischen Sätze, wie Sie möchten
Das vorgelagerte Modell wird auf dem chinesischen Datensatz geschult und unterstützt daher nur Chinesisch.


