airgapped offfline rag
v1.0.0

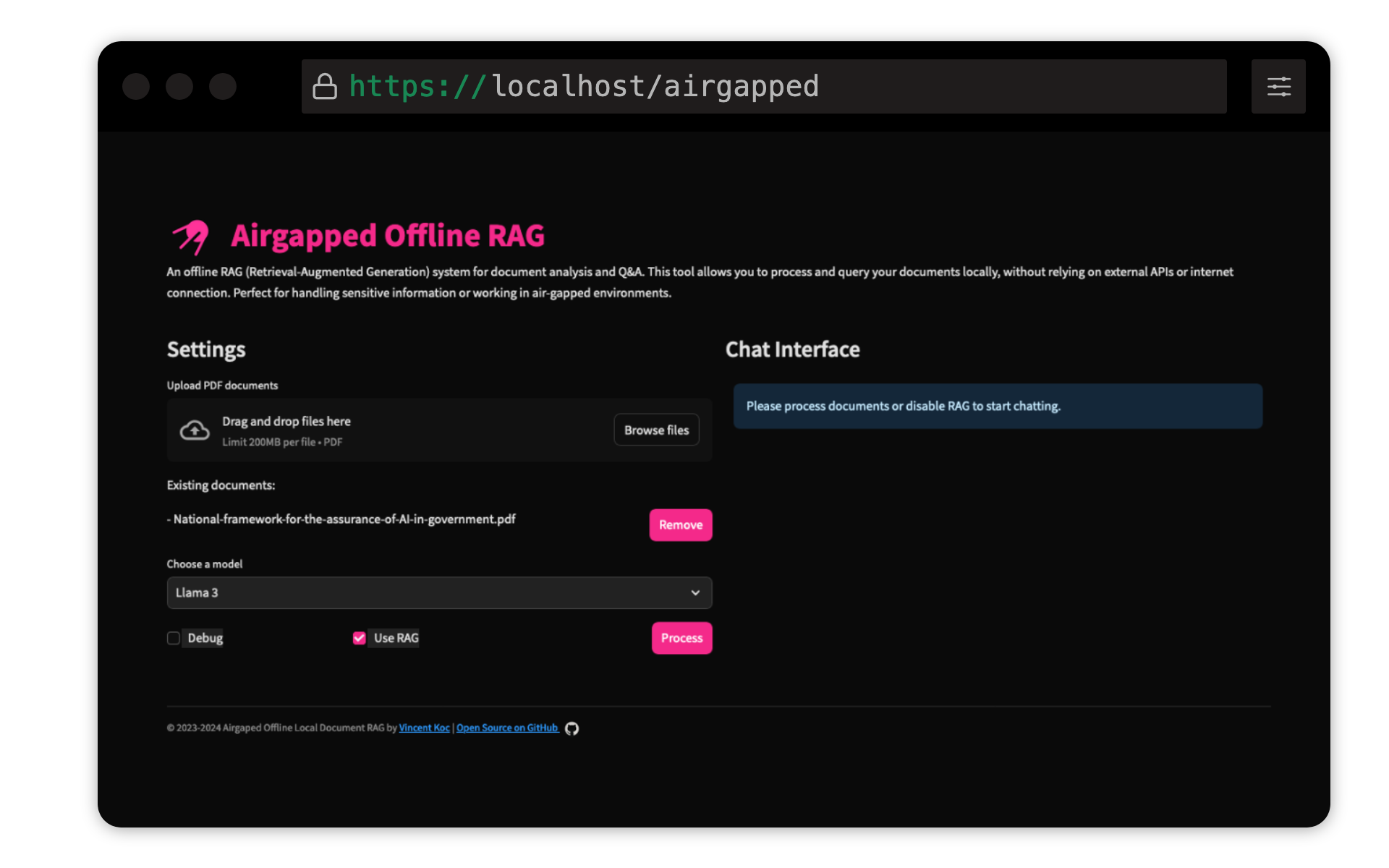
Este projeto de Vincent Koc implementa um sistema de resposta à imposição de perguntas baseadas em geração de recuperação (RAG) para documentos. Ele usa modelos LLAMA 3, Mistral e Gemini para inferência local com llama C ++, Langchain para orquestração, Chromadb para armazenamento vetorial e simplidades para a interface do usuário.
Verifique se o Python 3.9 está instalado : você pode usar pyenv :
pyenv install 3.9.16
pyenv local 3.9.16
pyenv rehash
Crie um ambiente virtual e instale dependências :
make setup
Download Modelos : Faça o download dos modelos LLAMA 3 (8B) e MISTRAL (7B) no formato GGUF e coloque -os nos models/ diretórios. TheBloke On Hugging Face compartilhou os modelos aqui:
Os modelos da unsloth também foram testados e podem ser encontrados aqui:
Modelo de transformador de sentença QDRANT : Isso será baixado automaticamente na primeira execução. Se estiver executando o pano de ar localmente, é melhor executar a base de código com acesso à Internet inicialmente para baixar o modelo.
make run
make docker-build
make docker-run
Ajuste as configurações no config.yaml para modificar os caminhos do modelo, tamanhos de bloco e outros parâmetros.
As contribuições são bem -vindas! Por favor, pegue o repositório e envie uma solicitação de tração. Para grandes mudanças, abra um problema primeiro para discutir o que você gostaria de mudar.
Este projeto está licenciado sob a licença pública geral da GNU v3.0 (GPLV3). Consulte o arquivo de licença para obter detalhes.
Isso significa:
Para mais informações, visite GNU GPL V3.


