airgapped offfline rag
v1.0.0

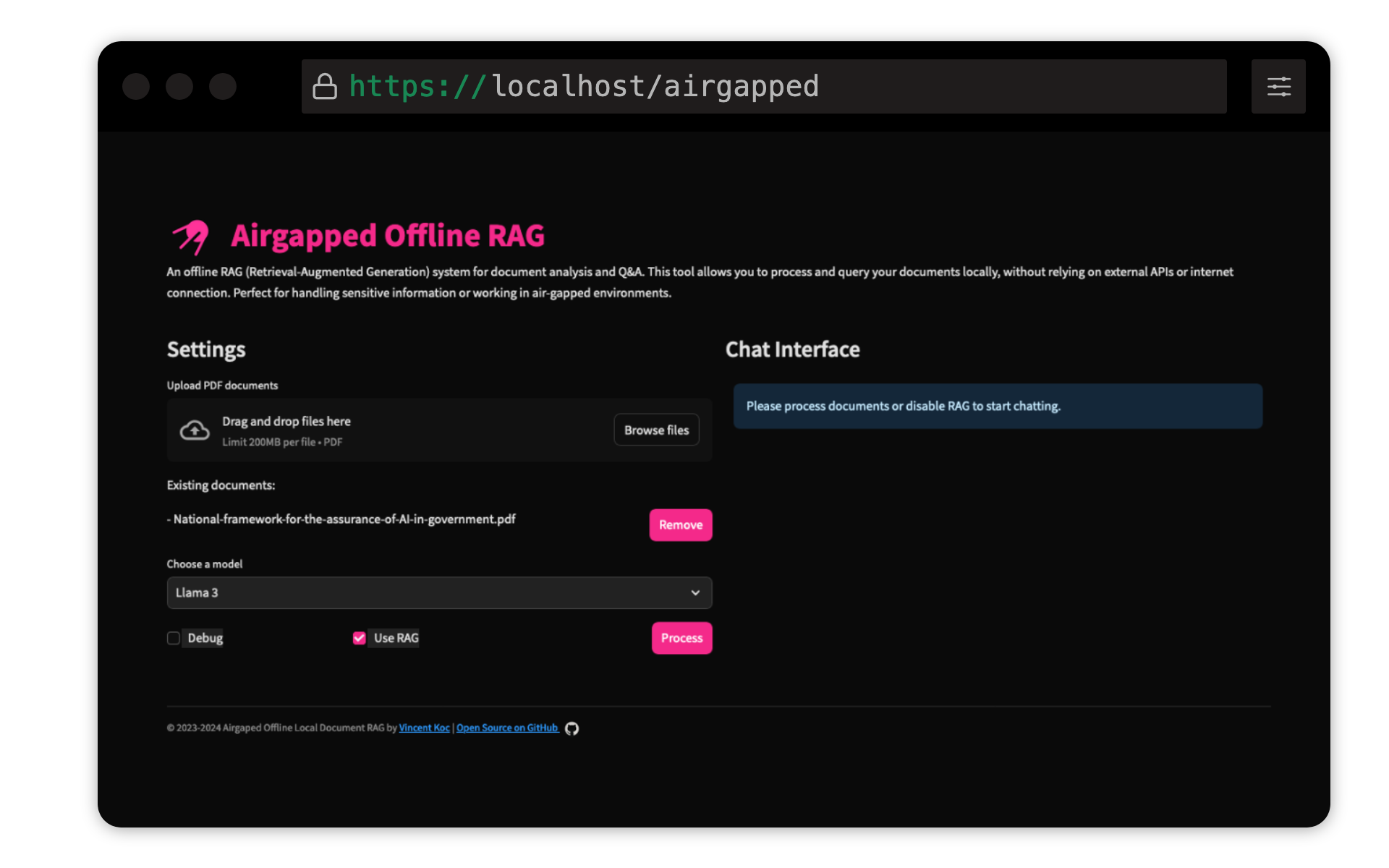
Ce projet de Vincent KOC met en œuvre un système de réponses basé sur la génération (RAG) de la génération (RAG) pour les documents. Il utilise des modèles LLAMA 3, Mistral et Gemini pour l'inférence locale avec Llama C ++, Langchain pour l'orchestration, ChromAdB pour le stockage vectoriel et rationalisation pour l'interface utilisateur.
Assurez-vous que Python 3.9 est installé : vous pouvez utiliser pyenv :
pyenv install 3.9.16
pyenv local 3.9.16
pyenv rehash
Créez un environnement virtuel et installez les dépendances :
make setup
Téléchargez les modèles : Téléchargez les modèles LLAMA 3 (8B) et Mistral (7B) au format GGUF et placez-les dans les models/ répertoire. TheBloke on Hugging Face a partagé les modèles ici:
Les modèles de unsloth ont également été testés et peuvent être trouvés ici:
Modèle de transformateur de phrase QDRANT : Ceci sera téléchargé automatiquement lors de la première exécution. Si l'exécution du chiffon aérégé localement, il est préférable d'exécuter la base de code avec un accès Internet initialement pour télécharger le modèle.
make run
make docker-build
make docker-run
Ajustez les paramètres de config.yaml pour modifier les chemins de modèle, les tailles de morceaux et autres paramètres.
Les contributions sont les bienvenues! Veuillez débarquer le référentiel et soumettre une demande de traction. Pour les changements majeurs, veuillez d'abord ouvrir un problème pour discuter de ce que vous souhaitez changer.
Ce projet est autorisé en vertu de la licence publique générale GNU v3.0 (GPLV3). Voir le fichier de licence pour plus de détails.
Cela signifie:
Pour plus d'informations, visitez GNU GPL V3.


