airgapped offfline rag
v1.0.0

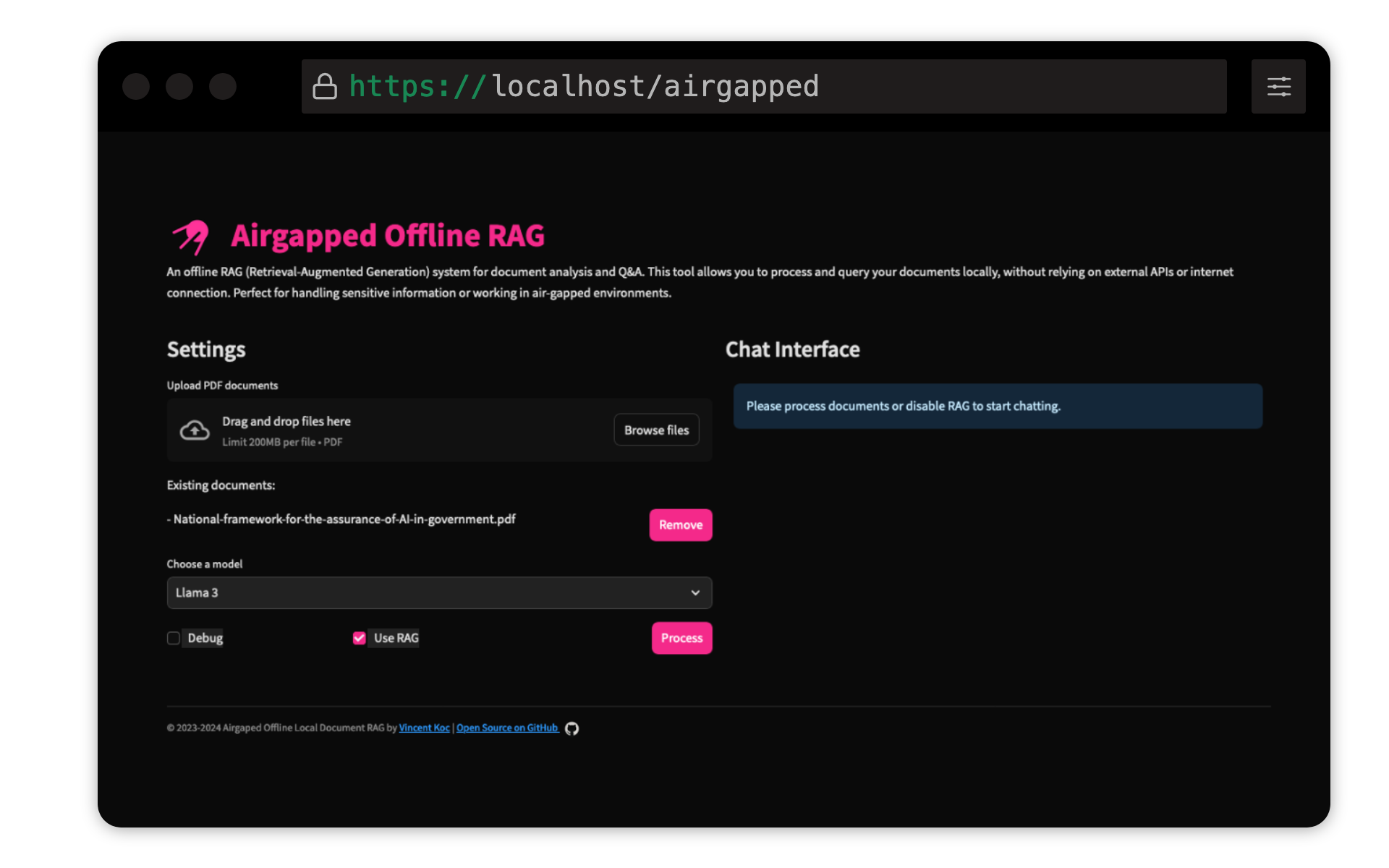
Este proyecto de Vincent Koc implementa un sistema de respuesta de preguntas de generación de recuperación (RAG) para documentos. Utiliza modelos LLAMA 3, Mistral y Gemini para la inferencia local con Llama C ++, Langchain para orquestación, ChromAdB para el almacenamiento vectorial y Strewlit para la interfaz de usuario.
Asegúrese de que esté instalado Python 3.9 : puede usar pyenv :
pyenv install 3.9.16
pyenv local 3.9.16
pyenv rehash
Crear un entorno virtual e instalar dependencias :
make setup
Descargue modelos : descargue los modelos Llama 3 (8b) y Mistral (7b) en formato GGUF y colóquelos en los models/ directorio. TheBloke on Hugging Face ha compartido las modelos aquí:
Los modelos de unsloth también se han probado y se pueden encontrar aquí:
Modelo de transformador de oración Qdrant : esto se descargará automáticamente en la primera ejecución. Si ejecuta el trapo de airepapado localmente, es mejor ejecutar la base de código con acceso a Internet inicialmente para descargar el modelo.
make run
make docker-build
make docker-run
Ajuste la configuración en config.yaml para modificar las rutas del modelo, los tamaños de los fragmentos y otros parámetros.
¡Las contribuciones son bienvenidas! Haga la bifurcación del repositorio y envíe una solicitud de extracción. Para cambios importantes, abra primero un problema para discutir lo que le gustaría cambiar.
Este proyecto tiene licencia bajo la Licencia Pública General de GNU v3.0 (GPLV3). Consulte el archivo de licencia para obtener más detalles.
Esto significa:
Para obtener más información, visite GNU GPL V3.


