airgapped offfline rag
v1.0.0

Vincent KOCによるこのプロジェクトは、ドキュメント用の検索された高級世代(RAG)ベースの質問回答システムを実装しています。 Llama 3、Mistral、およびGeminiモデルを使用して、Llama C ++、オーケストレーション用のLangchain、ベクトルストレージ用のChromadb、およびユーザーインターフェイス用の合理化を使用します。
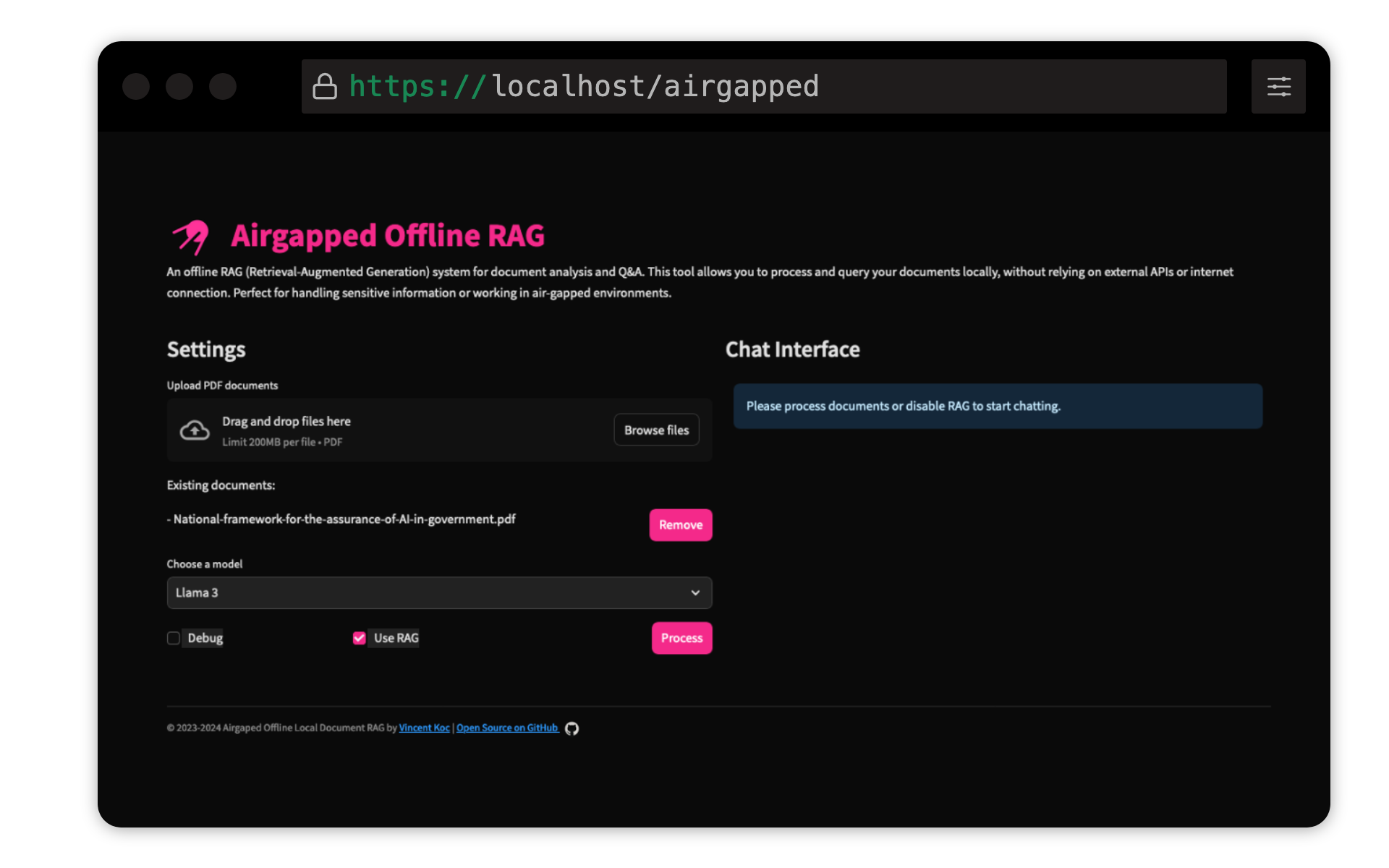
Python 3.9がインストールされていることを確認してくださいpyenvを使用できます。
pyenv install 3.9.16
pyenv local 3.9.16
pyenv rehash
仮想環境を作成し、依存関係をインストールします。
make setup
モデルのダウンロード:Llama 3(8b)およびMistral(7b)モデルをGGUF形式でダウンロードし、 models/ディレクトリに配置します。抱きしめる顔のTheBlokeは、ここでモデルを共有しています:
unslothのモデルもテストされており、ここで見つけることができます。
QDRANT文トランスモデル:これは、最初の実行時に自動的にダウンロードされます。エアギャップされたRAGをローカルで実行する場合、最初にインターネットアクセスを使用してコードベースを実行してモデルをダウンロードするのが最善です。
make run
make docker-build
make docker-run
config.yamlの設定を調整して、モデルパス、チャンクサイズ、その他のパラメーターを変更します。
貢献は大歓迎です!リポジトリをフォークして、プルリクエストを送信してください。大きな変更については、最初に問題を開いて、何を変えたいかを議論してください。
このプロジェクトは、GNU General Public License v3.0(GPLV3)に基づいてライセンスされています。詳細については、ライセンスファイルを参照してください。
これはつまり:
詳細については、GNU GPL V3をご覧ください。


