airgapped offfline rag
v1.0.0

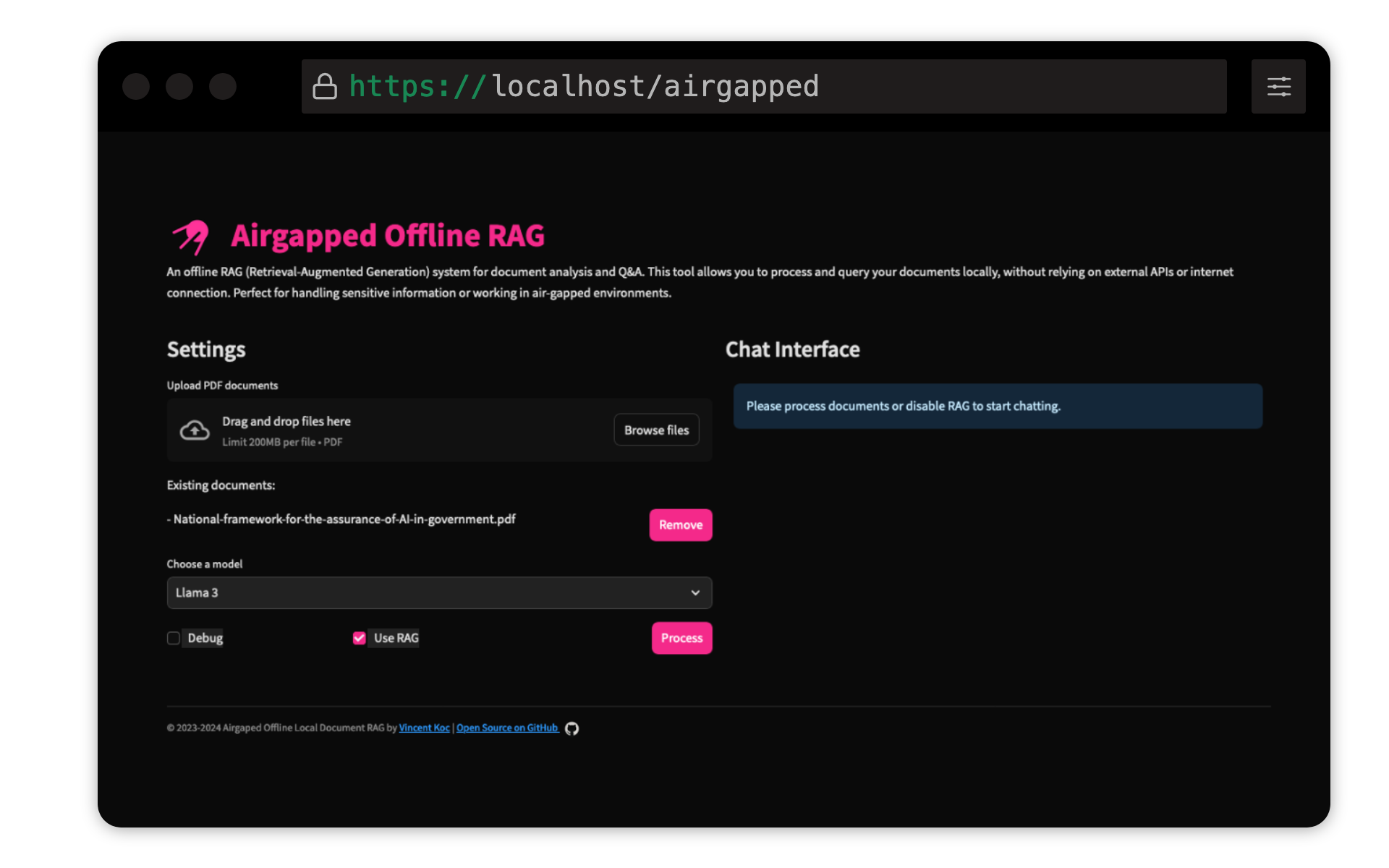
This project by Vincent Koc implements a Retrieval-Augmented Generation (RAG) based Question-Answering system for documents. It uses Llama 3, Mistral, and Gemini models for local inference with LlaMa c++, langchain for orchestration, chromadb for vector storage, and Streamlit for the user interface.
Ensure Python 3.9 is installed: You can use pyenv:
pyenv install 3.9.16
pyenv local 3.9.16
pyenv rehash
Create a virtual environment and install dependencies:
make setup
Download Models: Download the Llama 3 (8B) and Mistral (7B) models in GGUF format and place them in the models/ directory. TheBloke on Hugging Face has shared the models here:
The models from unsloth have also been tested and can be found here:
Qdrant Sentence Transformer Model: This will be downloaded automatically on the first run. If running the airgapped RAG locally, it's best to run the codebase with internet access initially to download the model.
make run
make docker-build
make docker-run
Adjust settings in config.yaml to modify model paths, chunk sizes, and other parameters.
Contributions are welcome! Please fork the repository and submit a pull request. For major changes, please open an issue first to discuss what you would like to change.
This project is licensed under the GNU General Public License v3.0 (GPLv3). See the LICENSE file for details.
This means:
For more information, visit GNU GPL v3.


