gollama
v1.27.23

Gollama é uma ferramenta MacOS / Linux para gerenciar os modelos Ollama.
Ele fornece uma TUI (interface do usuário de texto) para listagem, inspeção, exclusão, copia e empurrando os modelos Ollama, além de vinculá -los opcionalmente ao LM Studio*.
O aplicativo permite que os usuários selecionem modelos, classifiquem, classifiquem, filtem, editem, executem, descarreguem e executem ações de forma interativa usando teclas de atalho.
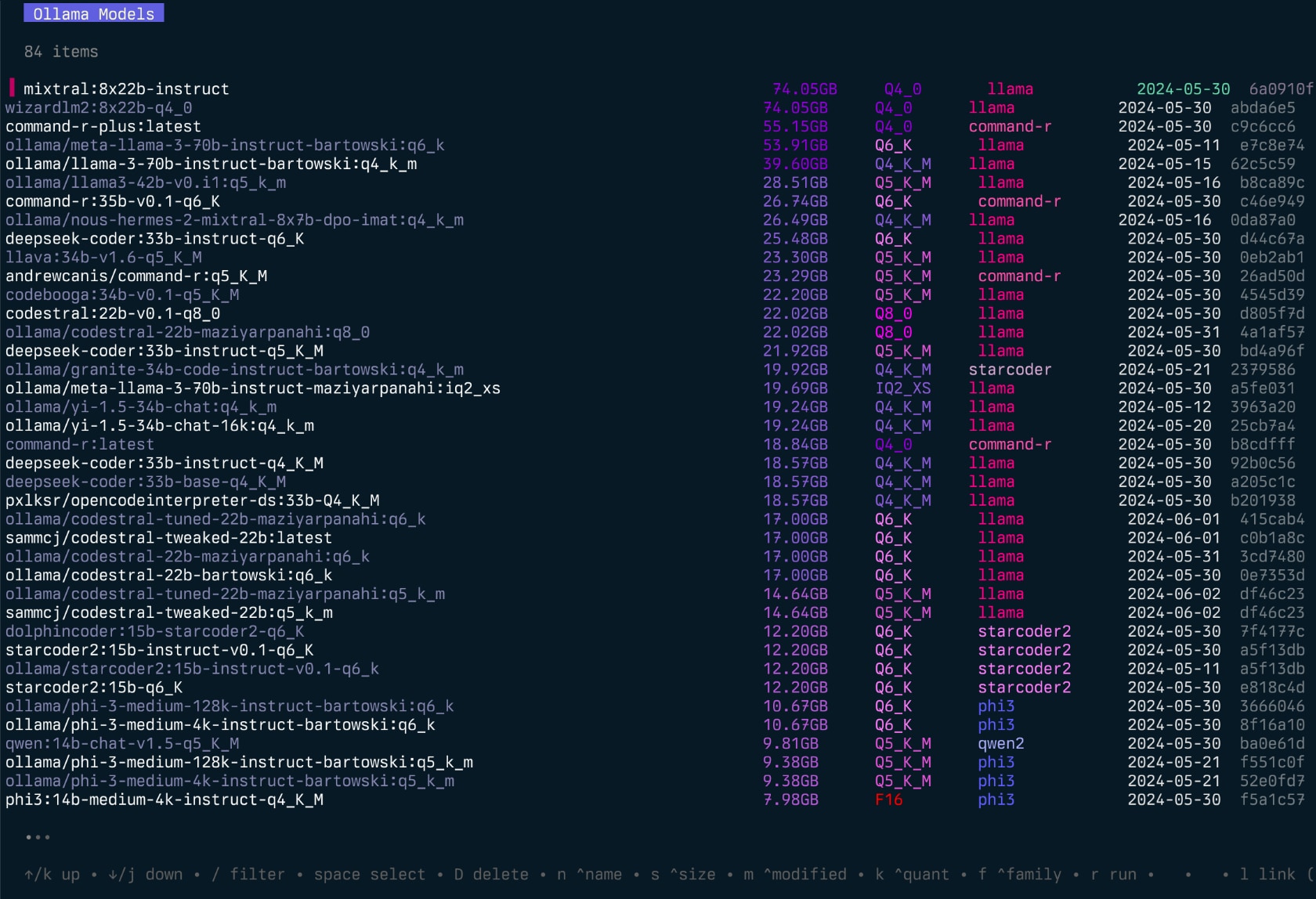
O projeto começou como uma reescrita do meu projeto Llamalink, mas decidi expandi-lo para incluir mais recursos e torná-lo mais fácil de usar.
Está em desenvolvimento ativo, portanto, existem alguns bugs e recursos ausentes, no entanto, estou achando útil para gerenciar meus modelos todos os dias, especialmente para limpar modelos antigos.
Veja também - ingestão para aprovar diretórios/repositórios de código para marcar formatados para LLMS.
Episódio de Intro Gollama ("Podcast"):
go install github.com/sammcj/gollama@HEADNão recomendo este método, pois não é tão fácil de atualizar, mas você pode usar o seguinte comando:
curl -sL https://raw.githubusercontent.com/sammcj/gollama/refs/heads/main/scripts/install.sh | bashFaça o download do lançamento mais recente da página de lançamentos e extraia o binário para um diretório em seu caminho.
por exemplo, zip -d gollama*.zip -d gollama && mv gollama /usr/local/bin
Para executar o aplicativo gollama , use o seguinte comando:
gollama Dica : eu gosto de pseudônimo Gollama para g para acesso rápido:
echo " alias g=gollama " >> ~ /.zshrcSpace : SelecioneEnter : Run Model (Ollama Run)i : Inspecione o modelot : TOP (Mostrar modelos em execução)D : Modelo de exclusãoe : editar modelo novoc : Modelo de cópiaU : descarregue todos os modelosp : Puxe um modelo existente novog : puxe (obtenha) novo modelo novoP : Push Modeln : classificar pelo nomes : classificar por tamanhom : classificar por modificadok : classificar por quantizaçãof : classificar por famílial : Link Model to LM StudioL : vincular todos os modelos ao LM Studior : Renomear o modelo (trabalho em andamento)q : Pare Top ( t )
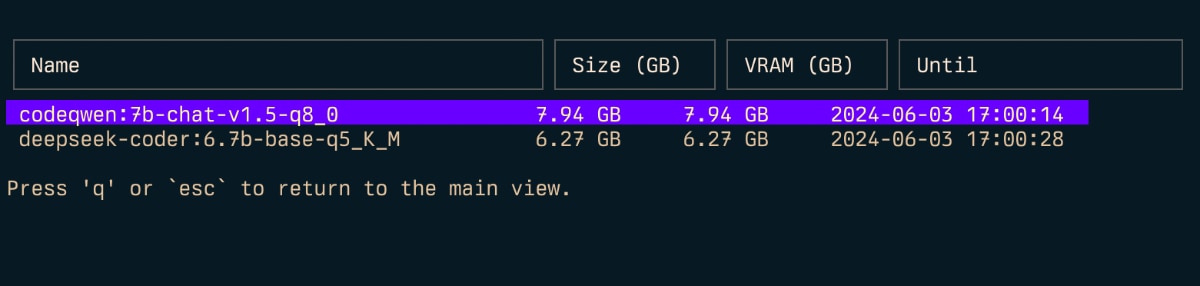
Inspecionar ( i )
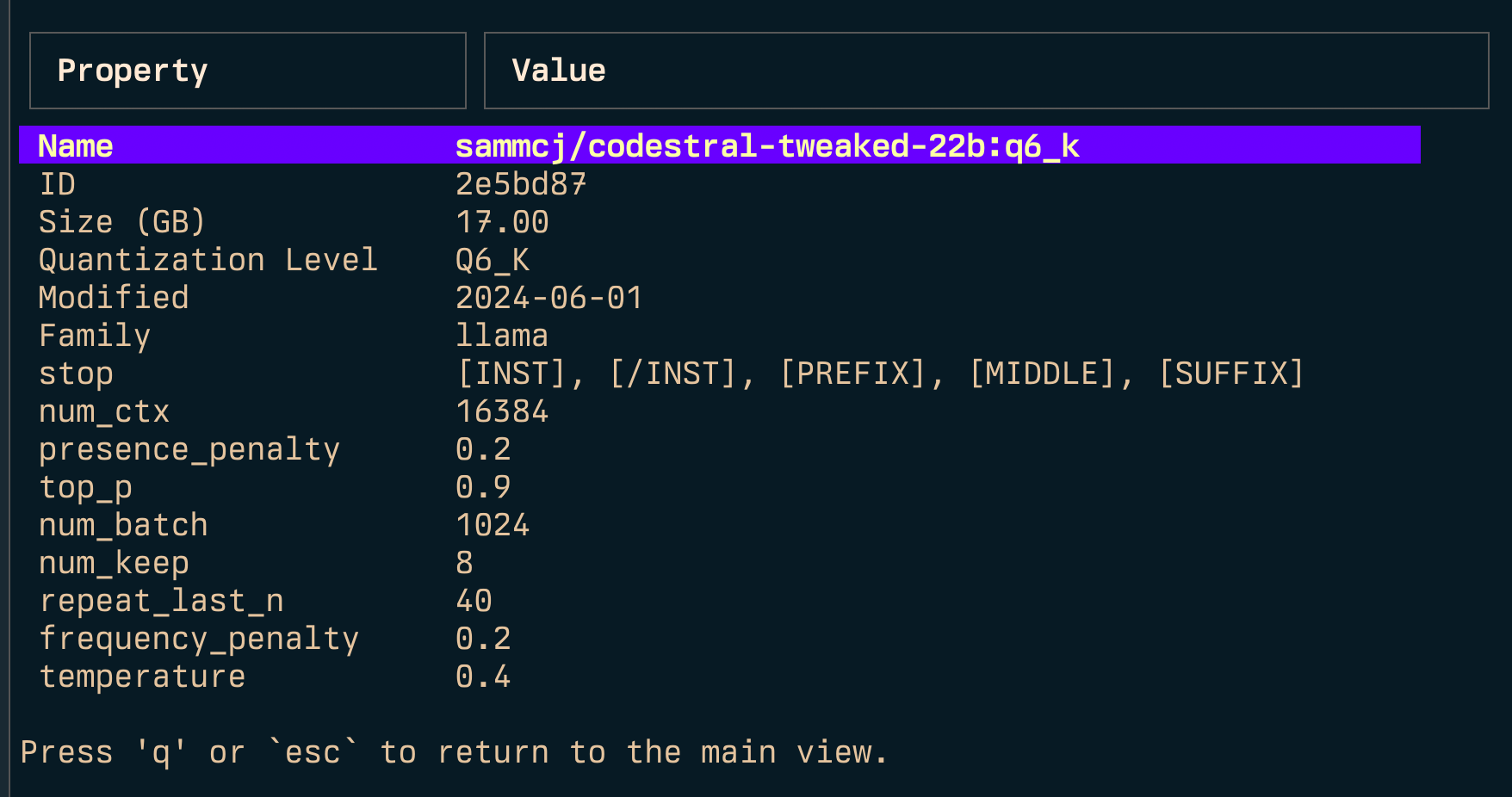
Link ( l ) e vincular tudo ( L )
Nota: requer privilégios de administrador se você estiver executando o Windows.
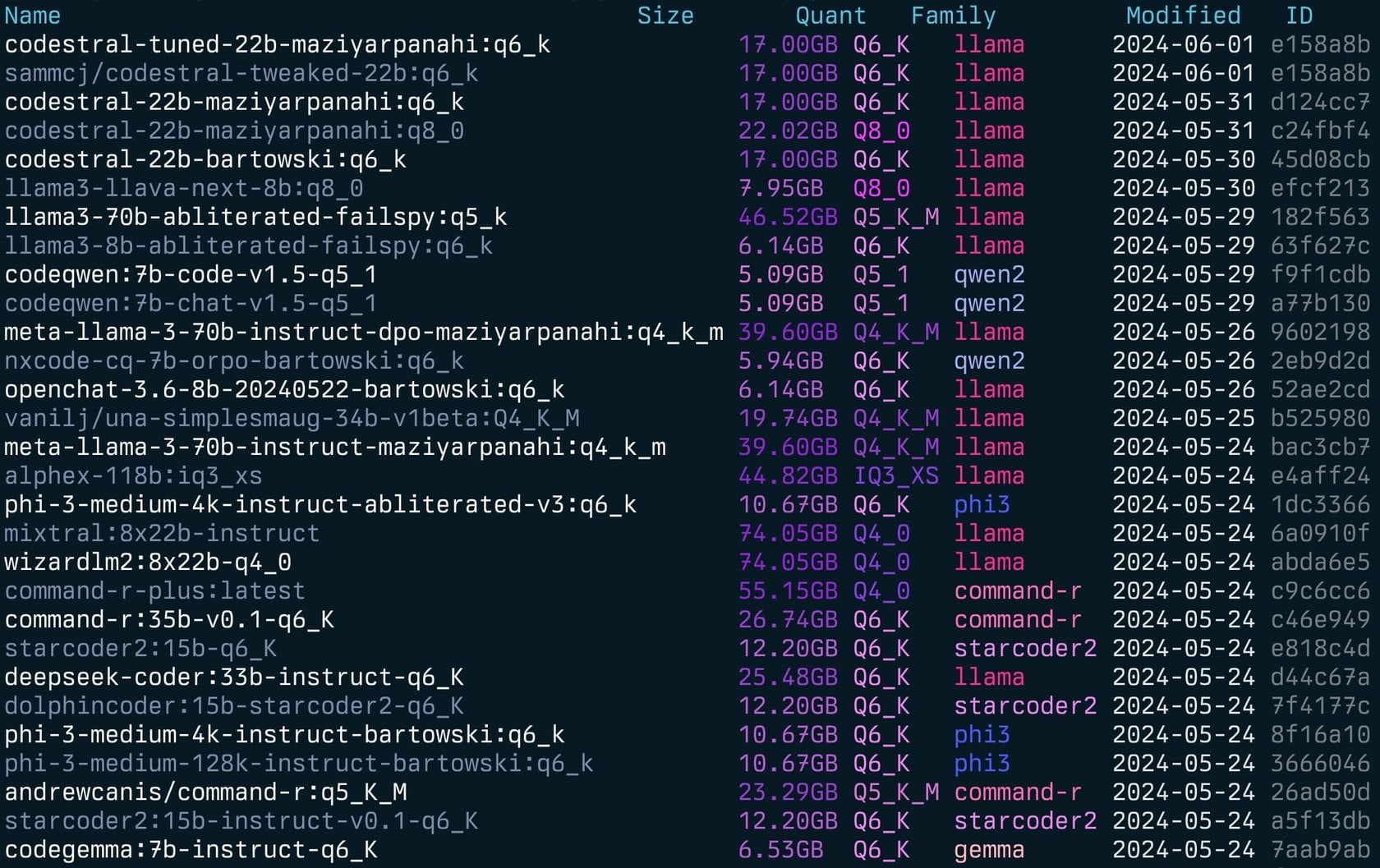
-l : Liste todos os modelos de Ollama disponíveis e saída-L : vincular todos os modelos de Ollama disponíveis ao LM Studio e saída-s <search term> : Pesquise modelos por nome'term1|term2' ) retorna modelos que correspondem a qualquer termo'term1&term2' ) retorna modelos que correspondem aos dois termos-e <model> : edite o modelfile para um modelo-ollama-dir : diretório de modelos de Ollama personalizado-lm-dir : Diretório de modelos de estúdio LM personalizado-cleanup : Remova todos os modelos simplificados e diretórios vazios e saída-no-cleanup : Não limpe os symblinks quebrados-u : descarregar todos os modelos em execução-v : imprima a versão e saia-h , ou --host : especifique o host para a API Ollama-H : atalho para -h http://localhost:11434 (conecte -se à API da Ollama local) Novo--vram : estimar o uso do VRAM para um modelo. Aceita:llama3.1:8b-instruct-q6_K , qwen2:14b-q4_0 )NousResearch/Hermes-2-Theta-Llama-3-8B )--fits : Memória disponível em GB para cálculo de contexto (por exemplo, 6 para 6 GB)--vram-to-nth ou --context : Comprimento máximo de contexto para analisar (por exemplo, 32k ou 128k )--quant : Substitua o nível de quantização (por exemplo, Q4_0 , Q5_K_M ) Gollama também pode ser chamado com -l para listar modelos sem o TUI.
gollama -l Lista ( gollama -l ):
Gollama pode ser chamado com -e para editar o modelfile para um modelo.
gollama -e my-model Gollama pode ser chamado com -s para procurar modelos pelo nome.
gollama -s my-model # returns models that contain 'my-model'
gollama -s ' my-model|my-other-model ' # returns models that contain either 'my-model' or 'my-other-model'
gollama -s ' my-model&instruct ' # returns models that contain both 'my-model' and 'instruct' Gollama inclui um recurso abrangente de estimativa de VRAM:
my-model:mytag ), ou ID do modelo HuggingFace (por exemplo, author/name )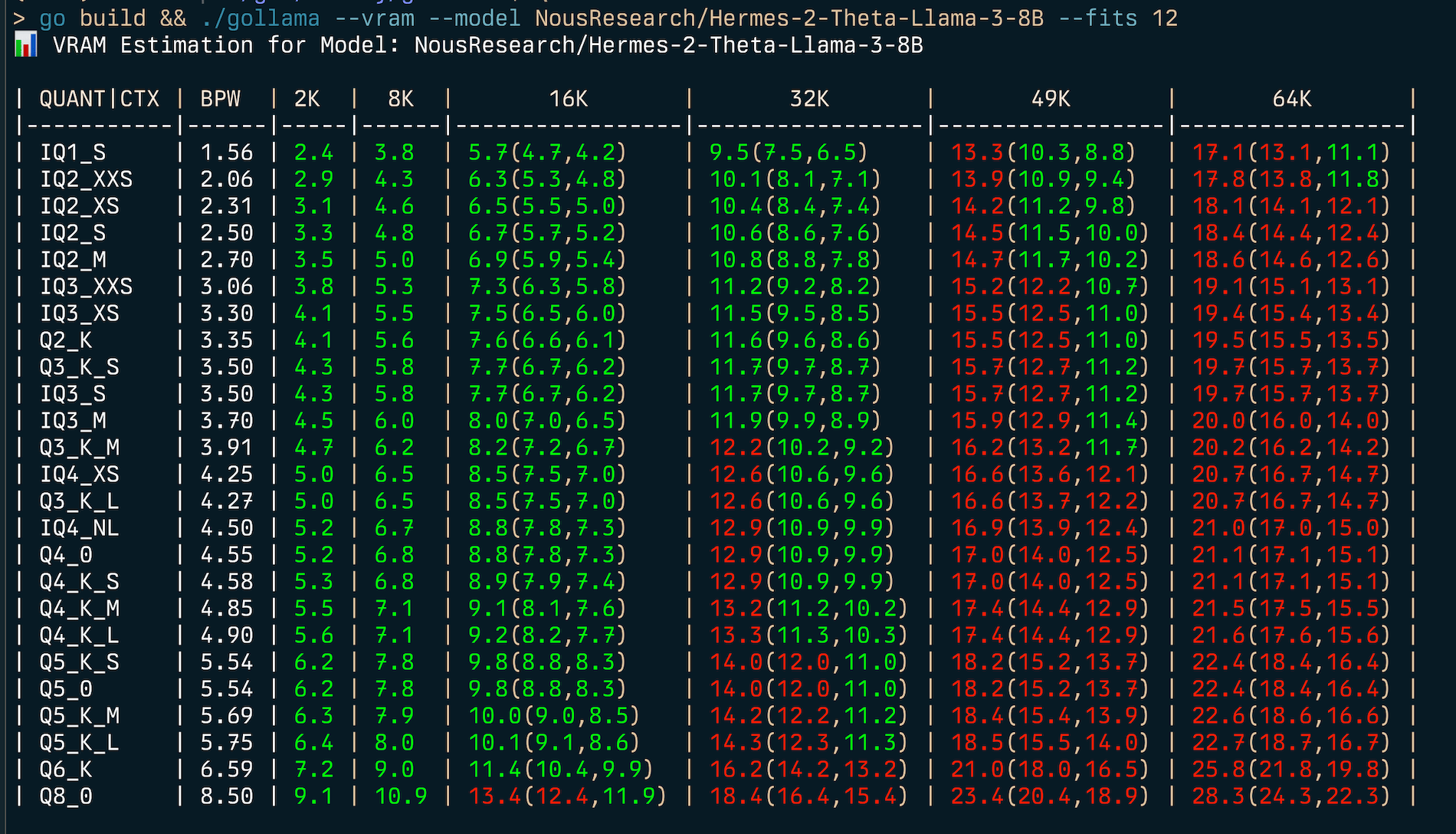
Para estimar (v) uso de RAM:
gollama --vram llama3.1:8b-instruct-q6_K
VRAM Estimation for Model: llama3.1:8b-instruct-q6_K
| QUANT | CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| ------- | ---- | --- | --- | --------------- | --------------- | --------------- | --------------- |
| IQ1_S | 1.56 | 2.2 | 2.8 | 3.7(3.7,3.7) | 5.5(5.5,5.5) | 7.3(7.3,7.3) | 9.1(9.1,9.1) |
| IQ2_XXS | 2.06 | 2.6 | 3.3 | 4.3(4.3,4.3) | 6.1(6.1,6.1) | 7.9(7.9,7.9) | 9.8(9.8,9.8) |
| IQ2_XS | 2.31 | 2.9 | 3.6 | 4.5(4.5,4.5) | 6.4(6.4,6.4) | 8.2(8.2,8.2) | 10.1(10.1,10.1) |
| IQ2_S | 2.50 | 3.1 | 3.8 | 4.7(4.7,4.7) | 6.6(6.6,6.6) | 8.5(8.5,8.5) | 10.4(10.4,10.4) |
| IQ2_M | 2.70 | 3.2 | 4.0 | 4.9(4.9,4.9) | 6.8(6.8,6.8) | 8.7(8.7,8.7) | 10.6(10.6,10.6) |
| IQ3_XXS | 3.06 | 3.6 | 4.3 | 5.3(5.3,5.3) | 7.2(7.2,7.2) | 9.2(9.2,9.2) | 11.1(11.1,11.1) |
| IQ3_XS | 3.30 | 3.8 | 4.5 | 5.5(5.5,5.5) | 7.5(7.5,7.5) | 9.5(9.5,9.5) | 11.4(11.4,11.4) |
| Q2_K | 3.35 | 3.9 | 4.6 | 5.6(5.6,5.6) | 7.6(7.6,7.6) | 9.5(9.5,9.5) | 11.5(11.5,11.5) |
| Q3_K_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_M | 3.70 | 4.2 | 5.0 | 6.0(6.0,6.0) | 8.0(8.0,8.0) | 9.9(9.9,9.9) | 12.0(12.0,12.0) |
| Q3_K_M | 3.91 | 4.4 | 5.2 | 6.2(6.2,6.2) | 8.2(8.2,8.2) | 10.2(10.2,10.2) | 12.2(12.2,12.2) |
| IQ4_XS | 4.25 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.6(10.6,10.6) | 12.7(12.7,12.7) |
| Q3_K_L | 4.27 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.7(10.7,10.7) | 12.7(12.7,12.7) |
| IQ4_NL | 4.50 | 5.0 | 5.7 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 10.9(10.9,10.9) | 13.0(13.0,13.0) |
| Q4_0 | 4.55 | 5.0 | 5.8 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_S | 4.58 | 5.0 | 5.8 | 6.9(6.9,6.9) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_M | 4.85 | 5.3 | 6.1 | 7.1(7.1,7.1) | 9.2(9.2,9.2) | 11.4(11.4,11.4) | 13.5(13.5,13.5) |
| Q4_K_L | 4.90 | 5.3 | 6.1 | 7.2(7.2,7.2) | 9.3(9.3,9.3) | 11.4(11.4,11.4) | 13.6(13.6,13.6) |
| Q5_K_S | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_0 | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_K_M | 5.69 | 6.1 | 6.9 | 8.0(8.0,8.0) | 10.2(10.2,10.2) | 12.4(12.4,12.4) | 14.6(14.6,14.6) |
| Q5_K_L | 5.75 | 6.1 | 7.0 | 8.1(8.1,8.1) | 10.3(10.3,10.3) | 12.5(12.5,12.5) | 14.7(14.7,14.7) |
| Q6_K | 6.59 | 7.0 | 8.0 | 9.4(9.4,9.4) | 12.2(12.2,12.2) | 15.0(15.0,15.0) | 17.8(17.8,17.8) |
| Q8_0 | 8.50 | 8.8 | 9.9 | 11.4(11.4,11.4) | 14.4(14.4,14.4) | 17.4(17.4,17.4) | 20.3(20.3,20.3) | Para encontrar o melhor tipo de quantização para uma determinada restrição de memória (por exemplo, 6 GB), você pode fornecer --fits <number of GB> :
gollama --vram NousResearch/Hermes-2-Theta-Llama-3-8B --fits 6
VRAM Estimation for Model: NousResearch/Hermes-2-Theta-Llama-3-8B
| QUANT/CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| --------- | ---- | --- | --- | ------------ | ------------- | -------------- | --------------- |
| IQ1_S | 1.56 | 2.4 | 3.8 | 5.7(4.7,4.2) | 9.5(7.5,6.5) | 13.3(10.3,8.8) | 17.1(13.1,11.1) |
| IQ2_XXS | 2.06 | 2.9 | 4.3 | 6.3(5.3,4.8) | 10.1(8.1,7.1) | 13.9(10.9,9.4) | 17.8(13.8,11.8) |
...Isso exibirá uma tabela mostrando o uso do VRAM para vários tipos de quantização e tamanhos de contexto.
O estimador VRAM funciona por:
Nota: O estimador tentará usar o CUDA VRAM, se disponível, caso contrário, ele voltará à RAM do sistema para cálculos.
Gollama usa um arquivo de configuração JSON localizado em ~/.config/gollama/config.json . O arquivo de configuração inclui opções para classificação, colunas, chaves da API, níveis de log etc ...
Exemplo de configuração:
{
"default_sort" : " modified " ,
"columns" : [
" Name " ,
" Size " ,
" Quant " ,
" Family " ,
" Modified " ,
" ID "
],
"ollama_api_key" : " " ,
"ollama_api_url" : " http://localhost:11434 " ,
"lm_studio_file_paths" : " " ,
"log_level" : " info " ,
"log_file_path" : " /Users/username/.config/gollama/gollama.log " ,
"sort_order" : " Size " ,
"strip_string" : " my-private-registry.internal/ " ,
"editor" : " " ,
"docker_container" : " "
}strip_string pode ser usado para remover um prefixo dos nomes de modelos, conforme eles são exibidos no TUI. Isso pode ser útil se você tiver um prefixo comum, como um registro privado que deseja remover para fins de exibição.docker_container - Experimental - Se definido, o Gollama tentará executar qualquer operações de execução dentro do contêiner especificado.editor - Experimental - Se definido, Gollama usará este editor para abrir o Modelfile para edição. Clone o repositório:
git clone https://github.com/sammcj/gollama.git
cd gollamaConstruir:
go get
make buildCorrer:
./gollama Os logs podem ser encontrados no gollama.log , que é armazenado em $HOME/.config/gollama/gollama.log por padrão. O nível de log pode ser definido no arquivo de configuração.
As contribuições são bem -vindas! Por favor, pegue o repositório e crie uma solicitação de tração com suas alterações.
Sam | Jose Almaraz | Jose Roberto Almaraz | Oleksii Filonenko | Southwolf | ANRGCT |
Obrigado a pessoas como Matt Williams, Fahd Mirza e AI Code King por dar uma chance e fornecer feedback.
Copyright © 2024 Sam McLeod
Este projeto está licenciado sob a licença do MIT. Consulte o arquivo de licença para obter detalhes.
<script src = "http://api.html5media.info/1.1.8/html5media.min.js"> </script>

