gollama
v1.27.23

Gollama est un outil macOS / Linux pour gérer les modèles Olllama.
Il fournit un TUI (interface utilisateur de texte) pour la liste, l'inspection, la suppression, la copie et la poussée des modèles Olllama ainsi que les liant éventuellement à LM Studio *.
L'application permet aux utilisateurs de sélectionner interactivement les modèles, trier, filtrer, modifier, exécuter, décharger et effectuer des actions sur eux à l'aide de raccourcis clavier.
Le projet a commencé comme une réécriture de mon projet Llamalink, mais j'ai décidé de l'étendre pour inclure plus de fonctionnalités et de le rendre plus convivial.
C'est en développement actif, il y a donc des bogues et des fonctionnalités manquantes, mais je le trouve utile pour gérer mes modèles tous les jours, en particulier pour le nettoyage des anciens modèles.
Voir aussi - Ingérer pour passer des répertoires / reposs de code à la mise en forme de marquage pour les LLM.
Gollama Intro (épisode "podcast"):
go install github.com/sammcj/gollama@HEADJe ne recommande pas cette méthode car elle n'est pas aussi facile à mettre à jour, mais vous pouvez utiliser la commande suivante:
curl -sL https://raw.githubusercontent.com/sammcj/gollama/refs/heads/main/scripts/install.sh | bashTéléchargez la version la plus récente de la page des versions et extraire le binaire dans un répertoire sur votre chemin.
par exemple zip -d gollama*.zip -d gollama && mv gollama /usr/local/bin
Pour exécuter l'application gollama , utilisez la commande suivante:
gollama Astuce : j'aime alias Gollama à g pour un accès rapide:
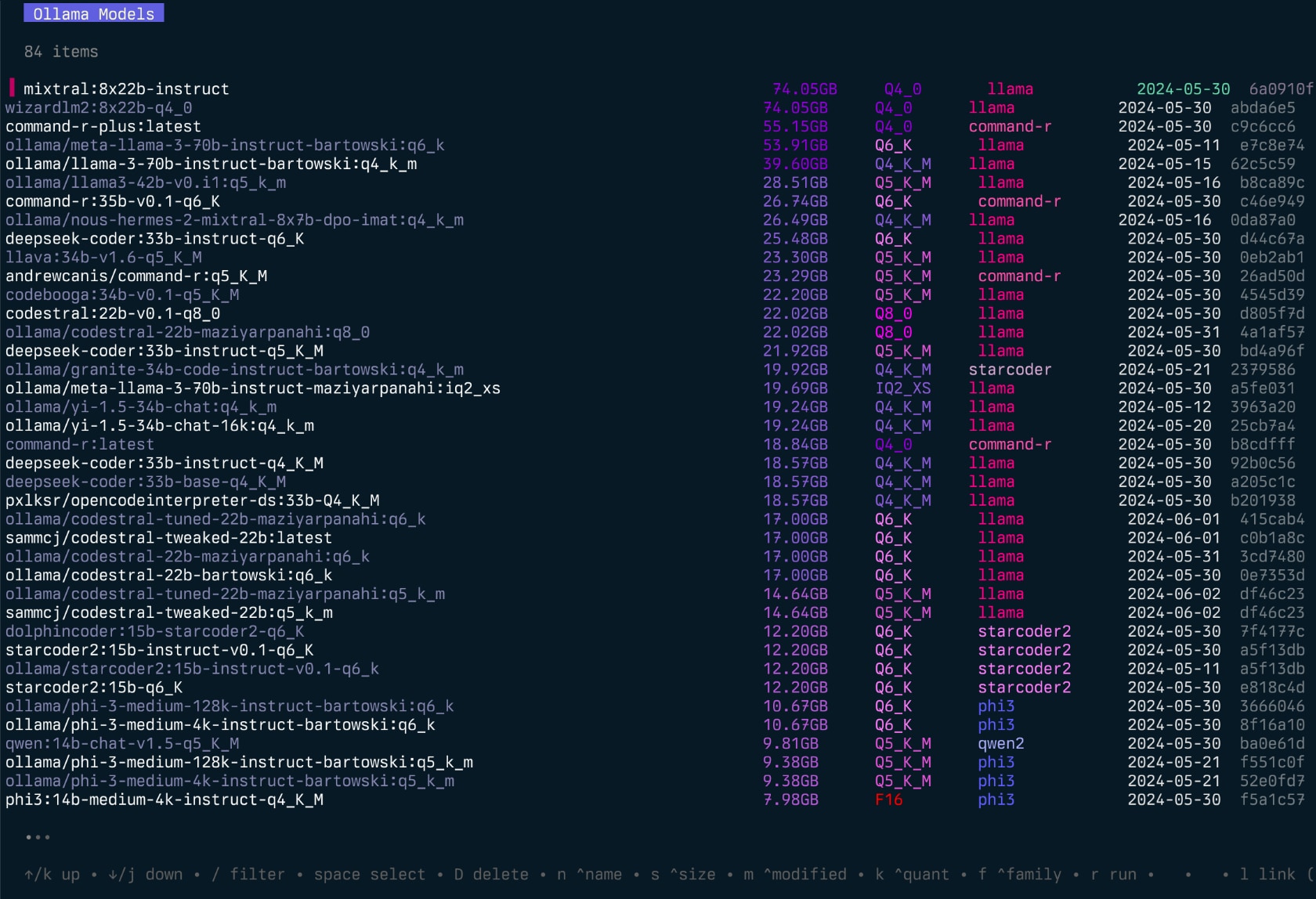
echo " alias g=gollama " >> ~ /.zshrcSpace : sélectionnerEnter : Run Model (Olllama Run)i : Inspecter le modèlet : TOP (Show Running Models)D : Supprimer le modèlee : Modifier le modèle nouveauc : Modèle de copieU : Déchargez tous les modèlesp : Tirez un modèle existant nouveaug : Pull (Obtenez) nouveau modèle nouveauP : modèle pushn : trier par noms : Trier par taillem : Trier par modificationk : Trier par quantificationf : Trier par famillel : Modèle de lien vers LM StudioL : lier tous les modèles à LM Studior : Renommer le modèle (travail en cours)q : Quitter Haut ( t )
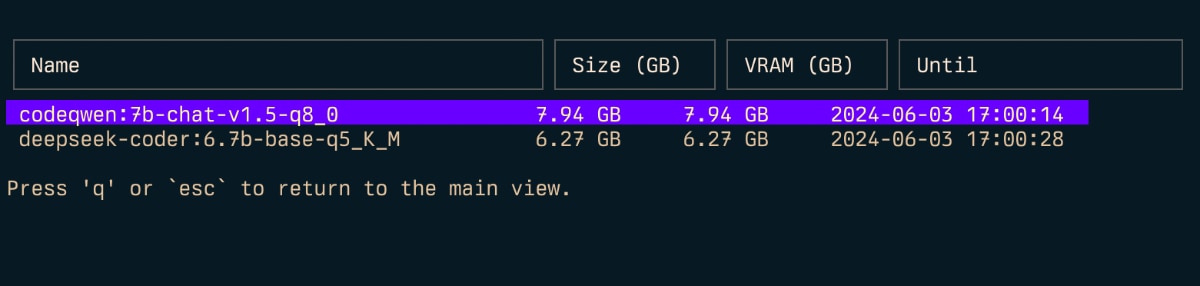
Inspecter ( i )
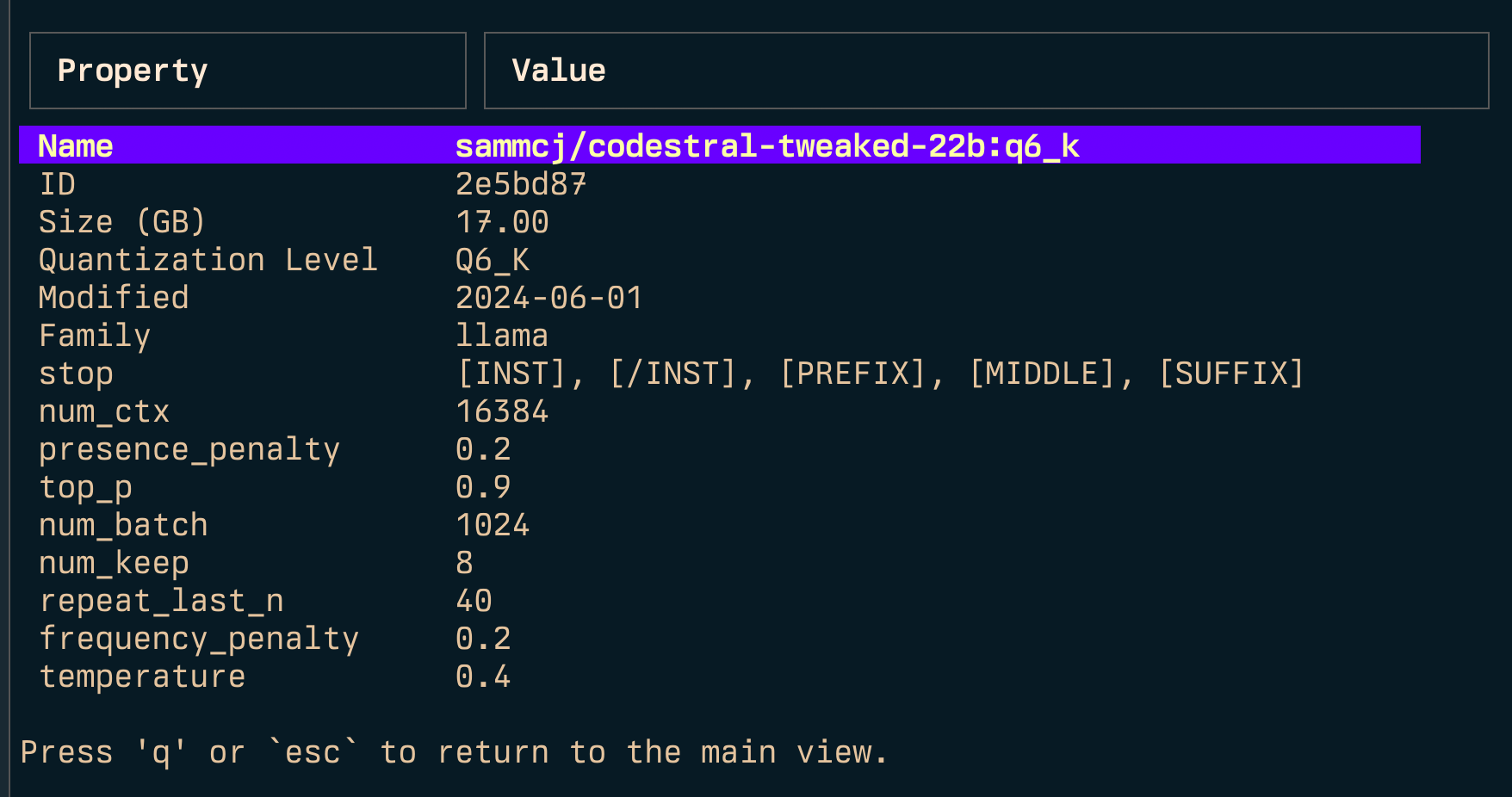
Lien ( l ) et lien all ( L )
Remarque: nécessite des privilèges d'administration si vous exécutez des fenêtres.
-l : Liste tous les modèles Olllama disponibles et sortez-L : Lien de tous les modèles Olllama disponibles à LM Studio et sortez-s <search term> : Rechercher des modèles par nom'term1|term2' ) renvoie des modèles qui correspondent à l'un ou l'autre terme'term1&term2' ) renvoie des modèles qui correspondent aux deux termes-e <model> : modifier le modelfile pour un modèle-ollama-dir : Répertoire des modèles Olllama personnalisés-lm-dir : Répertoire des modèles Studio LM personnalisés-cleanup : supprimez tous les modèles symbolisés et les répertoires vides et sortez-no-cleanup : Ne nettoyez pas les liens de synthèse cassés-u : déchargez tous les modèles en cours d'exécution-v : Imprimez la version et sortez-h , ou --host : spécifiez l'hôte de l'API Olllama-H : raccourci pour -h http://localhost:11434 (connecter à l'API local olllaa) Nouveau--vram : estimer l'utilisation de VRAM pour un modèle. Accepte:llama3.1:8b-instruct-q6_K , qwen2:14b-q4_0 )NousResearch/Hermes-2-Theta-Llama-3-8B )--fits : Mémoire disponible en GB pour le calcul du contexte (par exemple 6 pour 6 Go)--vram-to-nth ou --context : longueur de contexte maximale à analyser (par exemple 32k ou 128k )--quant : remplacer le niveau de quantification (par exemple Q4_0 , Q5_K_M ) Gollama peut également être appelé avec -l pour énumérer les modèles sans le TUI.
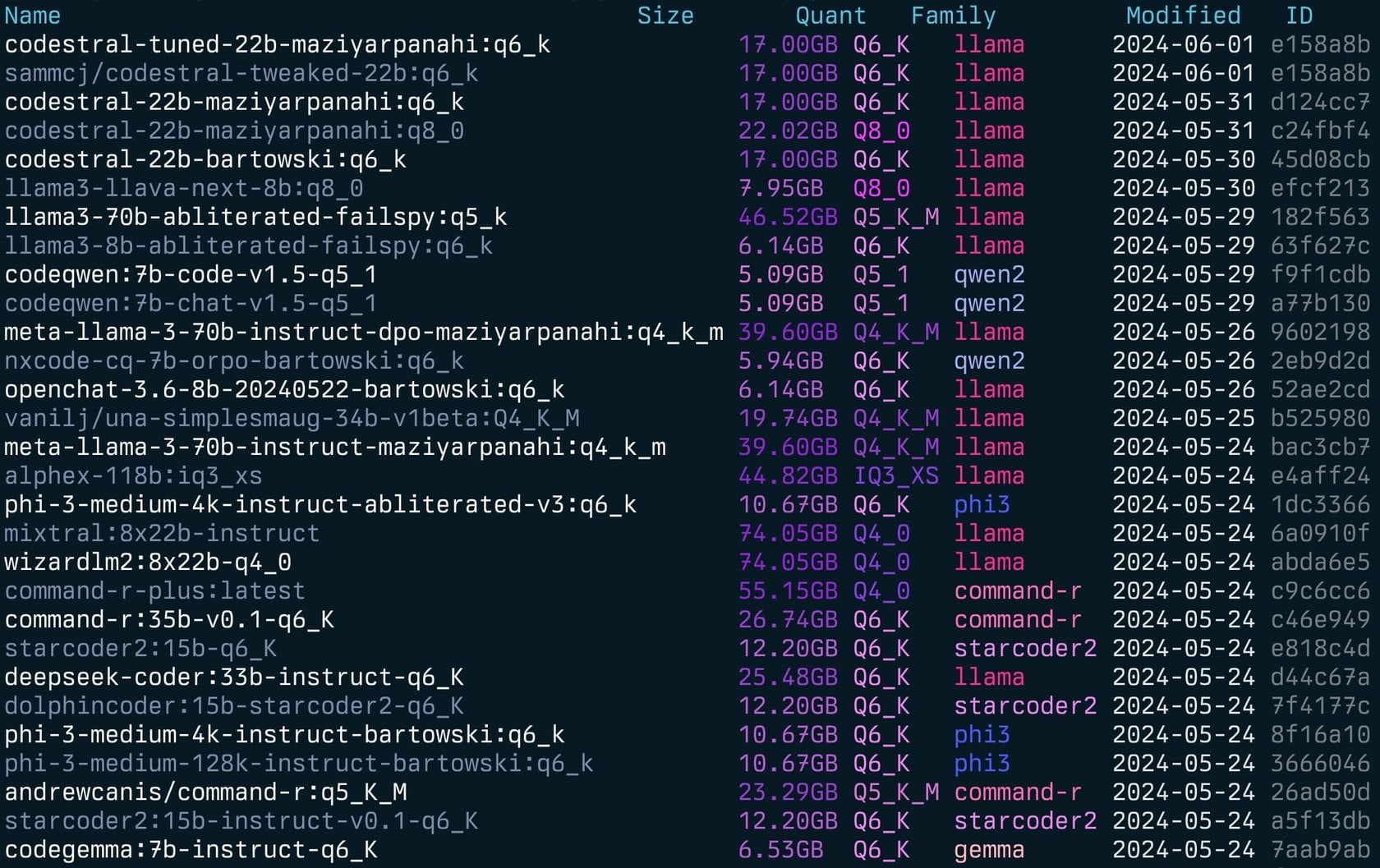
gollama -l Liste ( gollama -l ):
Gollama peut être appelé avec -e pour modifier le modelfile pour un modèle.
gollama -e my-model Gollama peut être appelé avec -s pour rechercher des modèles par son nom.
gollama -s my-model # returns models that contain 'my-model'
gollama -s ' my-model|my-other-model ' # returns models that contain either 'my-model' or 'my-other-model'
gollama -s ' my-model&instruct ' # returns models that contain both 'my-model' and 'instruct' Gollama comprend une caractéristique complète d'estimation VRAM:
my-model:mytag ), ou ID de modèle HuggingFace (par exemple, author/name )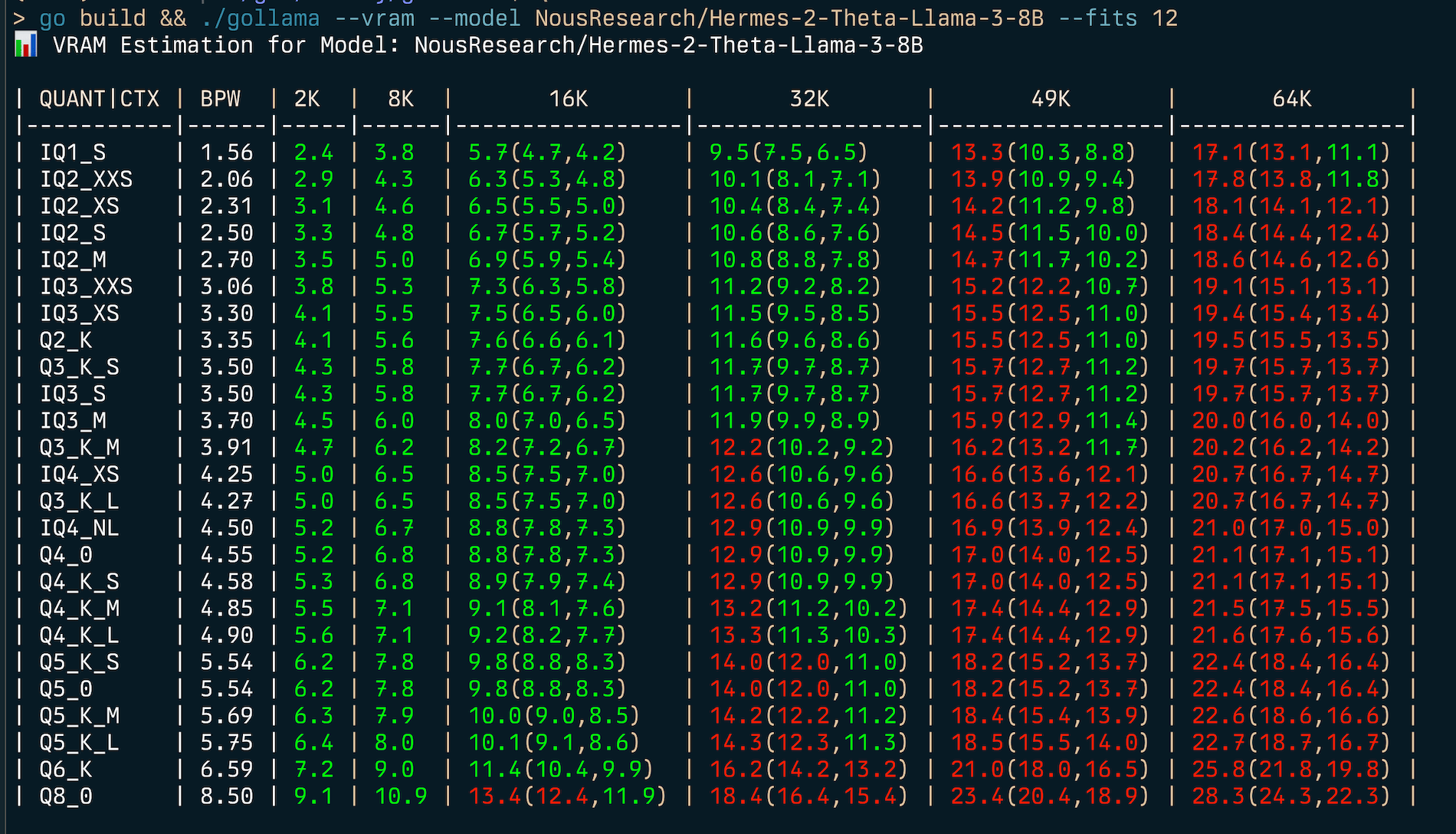
Pour estimer (v) Utilisation de la RAM:
gollama --vram llama3.1:8b-instruct-q6_K
VRAM Estimation for Model: llama3.1:8b-instruct-q6_K
| QUANT | CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| ------- | ---- | --- | --- | --------------- | --------------- | --------------- | --------------- |
| IQ1_S | 1.56 | 2.2 | 2.8 | 3.7(3.7,3.7) | 5.5(5.5,5.5) | 7.3(7.3,7.3) | 9.1(9.1,9.1) |
| IQ2_XXS | 2.06 | 2.6 | 3.3 | 4.3(4.3,4.3) | 6.1(6.1,6.1) | 7.9(7.9,7.9) | 9.8(9.8,9.8) |
| IQ2_XS | 2.31 | 2.9 | 3.6 | 4.5(4.5,4.5) | 6.4(6.4,6.4) | 8.2(8.2,8.2) | 10.1(10.1,10.1) |
| IQ2_S | 2.50 | 3.1 | 3.8 | 4.7(4.7,4.7) | 6.6(6.6,6.6) | 8.5(8.5,8.5) | 10.4(10.4,10.4) |
| IQ2_M | 2.70 | 3.2 | 4.0 | 4.9(4.9,4.9) | 6.8(6.8,6.8) | 8.7(8.7,8.7) | 10.6(10.6,10.6) |
| IQ3_XXS | 3.06 | 3.6 | 4.3 | 5.3(5.3,5.3) | 7.2(7.2,7.2) | 9.2(9.2,9.2) | 11.1(11.1,11.1) |
| IQ3_XS | 3.30 | 3.8 | 4.5 | 5.5(5.5,5.5) | 7.5(7.5,7.5) | 9.5(9.5,9.5) | 11.4(11.4,11.4) |
| Q2_K | 3.35 | 3.9 | 4.6 | 5.6(5.6,5.6) | 7.6(7.6,7.6) | 9.5(9.5,9.5) | 11.5(11.5,11.5) |
| Q3_K_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_M | 3.70 | 4.2 | 5.0 | 6.0(6.0,6.0) | 8.0(8.0,8.0) | 9.9(9.9,9.9) | 12.0(12.0,12.0) |
| Q3_K_M | 3.91 | 4.4 | 5.2 | 6.2(6.2,6.2) | 8.2(8.2,8.2) | 10.2(10.2,10.2) | 12.2(12.2,12.2) |
| IQ4_XS | 4.25 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.6(10.6,10.6) | 12.7(12.7,12.7) |
| Q3_K_L | 4.27 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.7(10.7,10.7) | 12.7(12.7,12.7) |
| IQ4_NL | 4.50 | 5.0 | 5.7 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 10.9(10.9,10.9) | 13.0(13.0,13.0) |
| Q4_0 | 4.55 | 5.0 | 5.8 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_S | 4.58 | 5.0 | 5.8 | 6.9(6.9,6.9) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_M | 4.85 | 5.3 | 6.1 | 7.1(7.1,7.1) | 9.2(9.2,9.2) | 11.4(11.4,11.4) | 13.5(13.5,13.5) |
| Q4_K_L | 4.90 | 5.3 | 6.1 | 7.2(7.2,7.2) | 9.3(9.3,9.3) | 11.4(11.4,11.4) | 13.6(13.6,13.6) |
| Q5_K_S | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_0 | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_K_M | 5.69 | 6.1 | 6.9 | 8.0(8.0,8.0) | 10.2(10.2,10.2) | 12.4(12.4,12.4) | 14.6(14.6,14.6) |
| Q5_K_L | 5.75 | 6.1 | 7.0 | 8.1(8.1,8.1) | 10.3(10.3,10.3) | 12.5(12.5,12.5) | 14.7(14.7,14.7) |
| Q6_K | 6.59 | 7.0 | 8.0 | 9.4(9.4,9.4) | 12.2(12.2,12.2) | 15.0(15.0,15.0) | 17.8(17.8,17.8) |
| Q8_0 | 8.50 | 8.8 | 9.9 | 11.4(11.4,11.4) | 14.4(14.4,14.4) | 17.4(17.4,17.4) | 20.3(20.3,20.3) | Pour trouver le meilleur type de quantification pour une contrainte de mémoire donnée (par exemple 6 Go), vous pouvez fournir --fits <number of GB> :
gollama --vram NousResearch/Hermes-2-Theta-Llama-3-8B --fits 6
VRAM Estimation for Model: NousResearch/Hermes-2-Theta-Llama-3-8B
| QUANT/CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| --------- | ---- | --- | --- | ------------ | ------------- | -------------- | --------------- |
| IQ1_S | 1.56 | 2.4 | 3.8 | 5.7(4.7,4.2) | 9.5(7.5,6.5) | 13.3(10.3,8.8) | 17.1(13.1,11.1) |
| IQ2_XXS | 2.06 | 2.9 | 4.3 | 6.3(5.3,4.8) | 10.1(8.1,7.1) | 13.9(10.9,9.4) | 17.8(13.8,11.8) |
...Cela affichera un tableau montrant l'utilisation VRAM pour divers types de quantification et tailles de contexte.
L'estimateur VRAM fonctionne par:
Remarque: L'estimateur tentera d'utiliser CUDA VRAM s'il est disponible, sinon il retombera à la RAM du système pour les calculs.
Gollama utilise un fichier de configuration JSON situé à ~/.config/gollama/config.json . Le fichier de configuration comprend des options de tri, des colonnes, des clés d'API, des niveaux de journal, etc.
Exemple de configuration:
{
"default_sort" : " modified " ,
"columns" : [
" Name " ,
" Size " ,
" Quant " ,
" Family " ,
" Modified " ,
" ID "
],
"ollama_api_key" : " " ,
"ollama_api_url" : " http://localhost:11434 " ,
"lm_studio_file_paths" : " " ,
"log_level" : " info " ,
"log_file_path" : " /Users/username/.config/gollama/gollama.log " ,
"sort_order" : " Size " ,
"strip_string" : " my-private-registry.internal/ " ,
"editor" : " " ,
"docker_container" : " "
}strip_string peut être utilisé pour supprimer un préfixe des noms de modèle tels qu'ils sont affichés dans le TUI. Cela peut être utile si vous avez un préfixe commun tel qu'un registre privé que vous souhaitez supprimer à des fins d'affichage.docker_container - Experimental - Si défini, Gollama tentera d'effectuer toutes les opérations d'exécution à l'intérieur du conteneur spécifié.editor - Expérimental - Si défini, Gollama utilisera cet éditeur pour ouvrir le modelfile pour l'édition. Clone le référentiel:
git clone https://github.com/sammcj/gollama.git
cd gollamaConstruire:
go get
make buildCourir:
./gollama Les journaux peuvent être trouvés dans le gollama.log qui est stocké dans $HOME/.config/gollama/gollama.log par défaut. Le niveau de journal peut être défini dans le fichier de configuration.
Les contributions sont les bienvenues! Veuillez débarquer le référentiel et créer une demande de traction avec vos modifications.
Sam | Jose Almaraz | Jose Roberto Almaraz | Oleksii Filonenko | Sud-loup | anrgct |
Merci à des gens tels que Matt Williams, Fahd Mirza et AI Code King pour avoir donné une chance et fournir des commentaires.
Copyright © 2024 Sam McLeod
Ce projet est autorisé sous la licence du MIT. Voir le fichier de licence pour plus de détails.
<script src = "http://api.html5media.info/1.1.8/html5media.min.js"> </ script>

