gollama
v1.27.23

Gollama es una herramienta MacOS / Linux para administrar modelos Ollama.
Proporciona un TUI (interfaz de usuario de texto) para listar, inspeccionar, eliminar, copiar y empujar los modelos Ollama, así como para vincularlos opcionalmente a LM Studio*.
La aplicación permite a los usuarios seleccionar interactivamente modelos, ordenar, filtrar, editar, ejecutar, descargar y realizar acciones en ellos con teclas de acceso rápido.
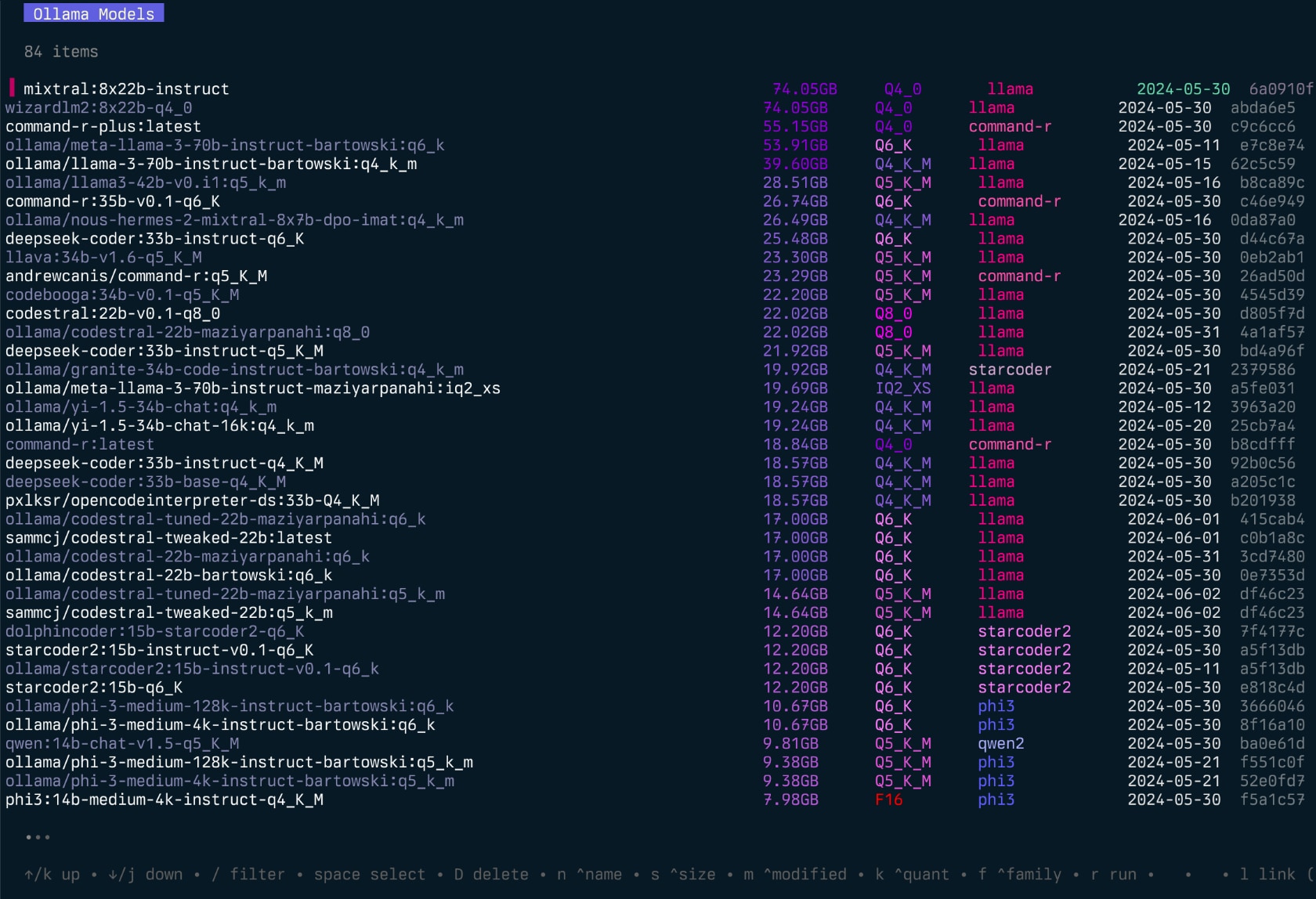
El proyecto comenzó como una reescritura de mi proyecto Llamalink, pero decidí expandirlo para incluir más funciones y hacerlo más fácil de usar.
Está en el desarrollo activo, por lo que hay algunos errores y características faltantes, sin embargo, me parece útil para administrar mis modelos todos los días, especialmente para limpiar modelos antiguos.
Ver también - Ingest para aprobar directorios/reposadores de código a Markdown formateado para LLMS.
Introducción de Gollama (episodio "Podcast"):
go install github.com/sammcj/gollama@HEADNo recomiendo este método, ya que no es tan fácil de actualizar, pero puede usar el siguiente comando:
curl -sL https://raw.githubusercontent.com/sammcj/gollama/refs/heads/main/scripts/install.sh | bashDescargue la versión más reciente de la página de lanzamientos y extraiga el binario a un directorio en su camino.
por ejemplo, zip -d gollama*.zip -d gollama && mv gollama /usr/local/bin
Para ejecutar la aplicación gollama , use el siguiente comando:
gollama Consejo : Me gusta alias Gollama a g para un acceso rápido:
echo " alias g=gollama " >> ~ /.zshrcSpace : SeleccionarEnter : Run Model (Ollama Run)i : modelo inspeccionart : Top (Show Running Models)D : Modelo Eliminare : Editar modelo nuevoc : modelo de copiaU : descarga todos los modelosp : Tire de un modelo nuevo existenteg : Pull (Get) Nuevo modelo nuevoP : modelo de empujen : Ordenar por nombres : Ordenar por tamañom : ordenar por modificadok : Ordenar por cuantizaciónf : Ordenar por familial : modelo de enlace a LM StudioL : Enlace todos los modelos a LM Studior : Modelo de cambio de nombre (trabajo en progreso)q : Salir Arriba ( t )
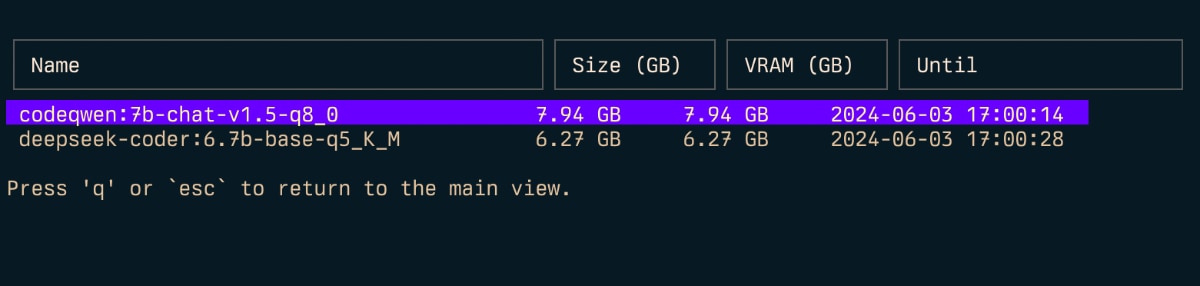
Inspeccionar ( i )
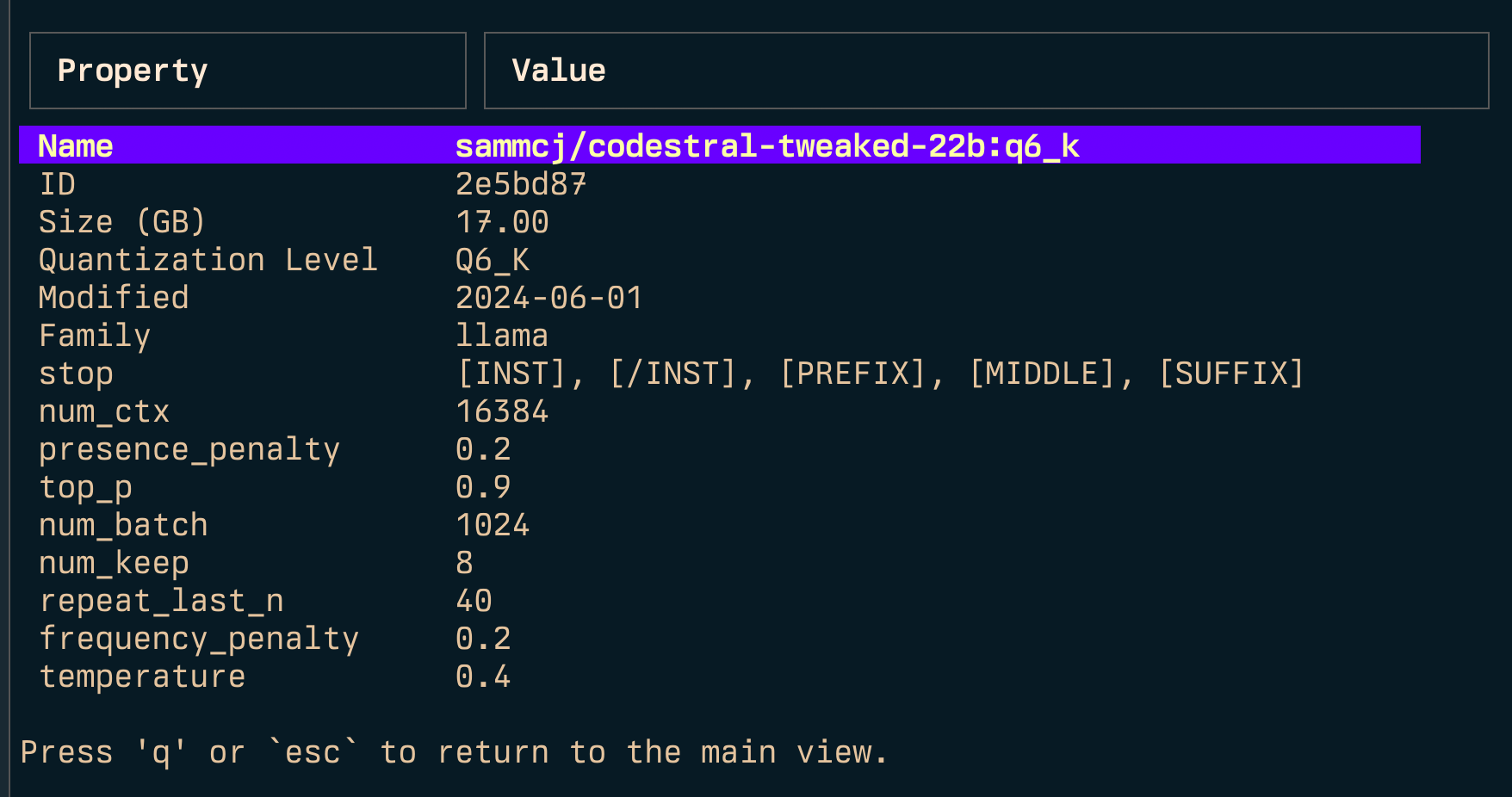
Enlace ( l ) y enlace todos ( L )
Nota: Requiere privilegios de administración si está ejecutando Windows.
-l : Lista todos los modelos Ollama disponibles y la salida-L : enlace todos los modelos Ollama disponibles para LM Studio y Salida-s <search term> : buscar modelos por nombre'term1|term2' ) devuelve modelos que coinciden con cualquier término'term1&term2' ) devuelve modelos que coinciden con ambos términos-e <model> : edite el modelfile para un modelo-ollama-dir : directorio de modelos Ollama personalizados-lm-dir : directorio de modelos de estudio LM personalizado-cleanup : elimine todos los modelos simulados y directorios vacíos y salga-no-cleanup : No limpie los enlaces simbólicos rotos-u : descargar todos los modelos en ejecución-v : imprima la versión y salga-h , o --host : especifique el anfitrión de la API Ollama-H : atajo para -h http://localhost:11434 (conectarse a la API local de ollama) Nuevo--vram : estimar el uso de VRAM para un modelo. Acepta:llama3.1:8b-instruct-q6_K , qwen2:14b-q4_0 )NousResearch/Hermes-2-Theta-Llama-3-8B )--fits : memoria disponible en GB para el cálculo del contexto (por ejemplo, 6 para 6 GB)--vram-to-nth o --context : longitud máxima de contexto para analizar (por ejemplo, 32k o 128k )--quant : anular el nivel de cuantificación (por ejemplo, Q4_0 , Q5_K_M ) Gollama también se puede llamar con -l para enumerar los modelos sin el TUI.
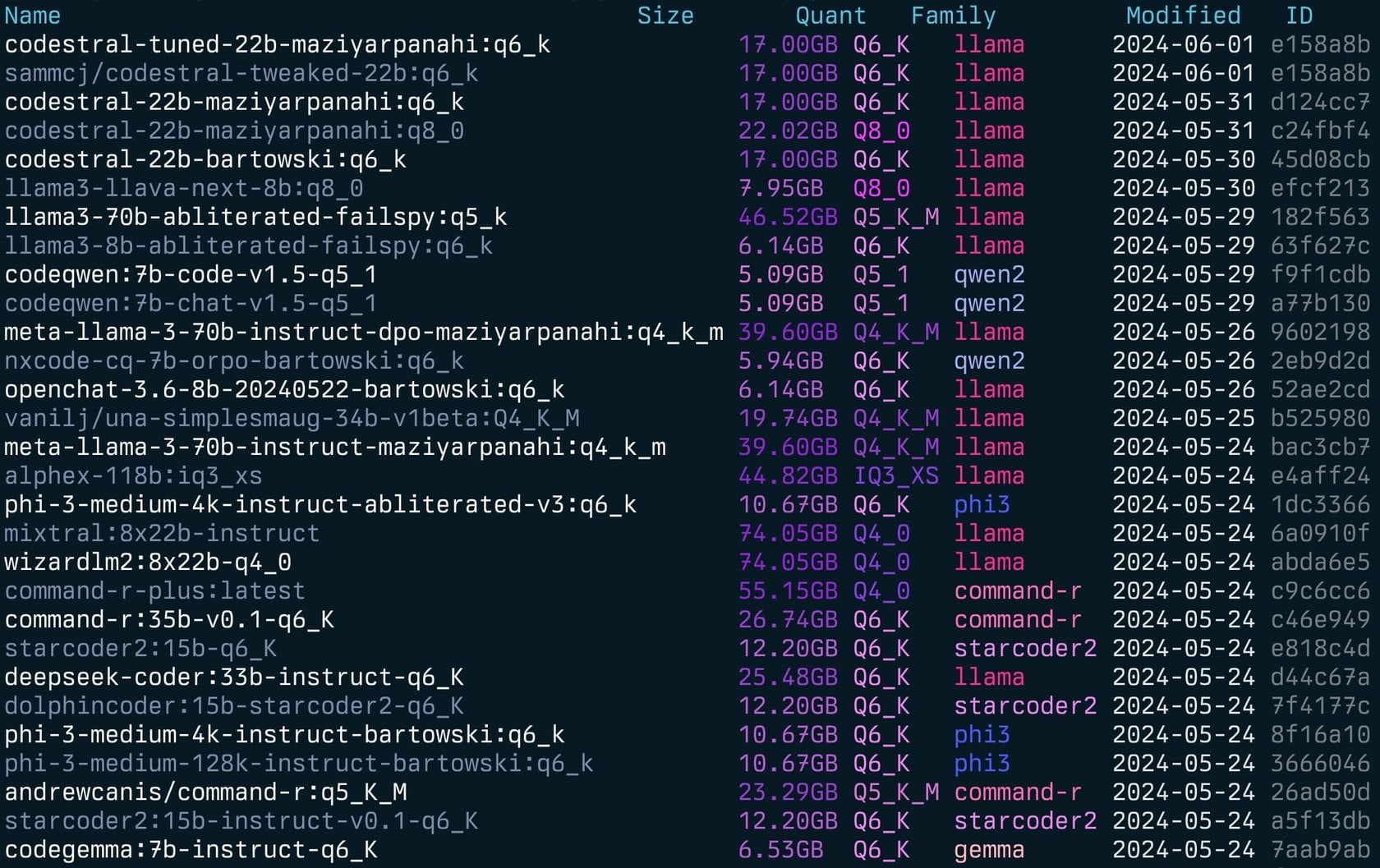
gollama -l Lista ( gollama -l ):
Se puede llamar a Gollama con -e para editar el ModelFile para un modelo.
gollama -e my-model Se puede llamar a Gollama con -s para buscar modelos por su nombre.
gollama -s my-model # returns models that contain 'my-model'
gollama -s ' my-model|my-other-model ' # returns models that contain either 'my-model' or 'my-other-model'
gollama -s ' my-model&instruct ' # returns models that contain both 'my-model' and 'instruct' Gollama incluye una función completa de estimación de VRAM:
my-model:mytag ) o Huggingface Model ID (por ejemplo, author/name )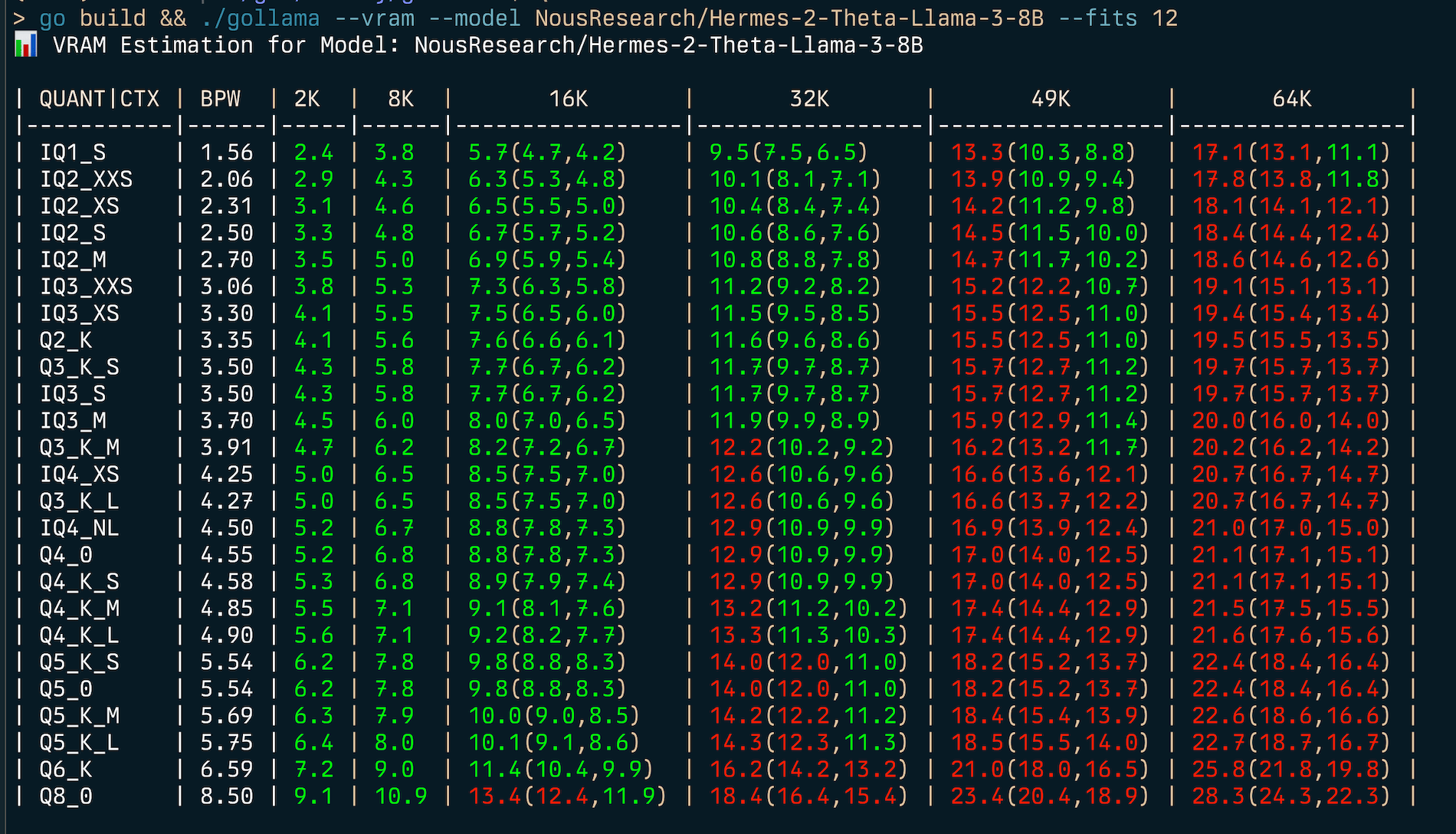
Para estimar (v) Uso de RAM:
gollama --vram llama3.1:8b-instruct-q6_K
VRAM Estimation for Model: llama3.1:8b-instruct-q6_K
| QUANT | CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| ------- | ---- | --- | --- | --------------- | --------------- | --------------- | --------------- |
| IQ1_S | 1.56 | 2.2 | 2.8 | 3.7(3.7,3.7) | 5.5(5.5,5.5) | 7.3(7.3,7.3) | 9.1(9.1,9.1) |
| IQ2_XXS | 2.06 | 2.6 | 3.3 | 4.3(4.3,4.3) | 6.1(6.1,6.1) | 7.9(7.9,7.9) | 9.8(9.8,9.8) |
| IQ2_XS | 2.31 | 2.9 | 3.6 | 4.5(4.5,4.5) | 6.4(6.4,6.4) | 8.2(8.2,8.2) | 10.1(10.1,10.1) |
| IQ2_S | 2.50 | 3.1 | 3.8 | 4.7(4.7,4.7) | 6.6(6.6,6.6) | 8.5(8.5,8.5) | 10.4(10.4,10.4) |
| IQ2_M | 2.70 | 3.2 | 4.0 | 4.9(4.9,4.9) | 6.8(6.8,6.8) | 8.7(8.7,8.7) | 10.6(10.6,10.6) |
| IQ3_XXS | 3.06 | 3.6 | 4.3 | 5.3(5.3,5.3) | 7.2(7.2,7.2) | 9.2(9.2,9.2) | 11.1(11.1,11.1) |
| IQ3_XS | 3.30 | 3.8 | 4.5 | 5.5(5.5,5.5) | 7.5(7.5,7.5) | 9.5(9.5,9.5) | 11.4(11.4,11.4) |
| Q2_K | 3.35 | 3.9 | 4.6 | 5.6(5.6,5.6) | 7.6(7.6,7.6) | 9.5(9.5,9.5) | 11.5(11.5,11.5) |
| Q3_K_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_M | 3.70 | 4.2 | 5.0 | 6.0(6.0,6.0) | 8.0(8.0,8.0) | 9.9(9.9,9.9) | 12.0(12.0,12.0) |
| Q3_K_M | 3.91 | 4.4 | 5.2 | 6.2(6.2,6.2) | 8.2(8.2,8.2) | 10.2(10.2,10.2) | 12.2(12.2,12.2) |
| IQ4_XS | 4.25 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.6(10.6,10.6) | 12.7(12.7,12.7) |
| Q3_K_L | 4.27 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.7(10.7,10.7) | 12.7(12.7,12.7) |
| IQ4_NL | 4.50 | 5.0 | 5.7 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 10.9(10.9,10.9) | 13.0(13.0,13.0) |
| Q4_0 | 4.55 | 5.0 | 5.8 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_S | 4.58 | 5.0 | 5.8 | 6.9(6.9,6.9) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_M | 4.85 | 5.3 | 6.1 | 7.1(7.1,7.1) | 9.2(9.2,9.2) | 11.4(11.4,11.4) | 13.5(13.5,13.5) |
| Q4_K_L | 4.90 | 5.3 | 6.1 | 7.2(7.2,7.2) | 9.3(9.3,9.3) | 11.4(11.4,11.4) | 13.6(13.6,13.6) |
| Q5_K_S | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_0 | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_K_M | 5.69 | 6.1 | 6.9 | 8.0(8.0,8.0) | 10.2(10.2,10.2) | 12.4(12.4,12.4) | 14.6(14.6,14.6) |
| Q5_K_L | 5.75 | 6.1 | 7.0 | 8.1(8.1,8.1) | 10.3(10.3,10.3) | 12.5(12.5,12.5) | 14.7(14.7,14.7) |
| Q6_K | 6.59 | 7.0 | 8.0 | 9.4(9.4,9.4) | 12.2(12.2,12.2) | 15.0(15.0,15.0) | 17.8(17.8,17.8) |
| Q8_0 | 8.50 | 8.8 | 9.9 | 11.4(11.4,11.4) | 14.4(14.4,14.4) | 17.4(17.4,17.4) | 20.3(20.3,20.3) | Para encontrar el mejor tipo de cuantización para una restricción de memoria dada (por ejemplo, 6GB), puede proporcionar --fits <number of GB> :
gollama --vram NousResearch/Hermes-2-Theta-Llama-3-8B --fits 6
VRAM Estimation for Model: NousResearch/Hermes-2-Theta-Llama-3-8B
| QUANT/CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| --------- | ---- | --- | --- | ------------ | ------------- | -------------- | --------------- |
| IQ1_S | 1.56 | 2.4 | 3.8 | 5.7(4.7,4.2) | 9.5(7.5,6.5) | 13.3(10.3,8.8) | 17.1(13.1,11.1) |
| IQ2_XXS | 2.06 | 2.9 | 4.3 | 6.3(5.3,4.8) | 10.1(8.1,7.1) | 13.9(10.9,9.4) | 17.8(13.8,11.8) |
...Esto mostrará una tabla que muestra el uso de VRAM para varios tipos de cuantización y tamaños de contexto.
El estimador VRAM funciona por:
Nota: El estimador intentará usar CUDA VRAM si está disponible, de lo contrario volverá a la RAM del sistema para los cálculos.
Gollama utiliza un archivo de configuración JSON ubicado en ~/.config/gollama/config.json . El archivo de configuración incluye opciones para clasificar, columnas, claves API, niveles de registro, etc.
Configuración de ejemplo:
{
"default_sort" : " modified " ,
"columns" : [
" Name " ,
" Size " ,
" Quant " ,
" Family " ,
" Modified " ,
" ID "
],
"ollama_api_key" : " " ,
"ollama_api_url" : " http://localhost:11434 " ,
"lm_studio_file_paths" : " " ,
"log_level" : " info " ,
"log_file_path" : " /Users/username/.config/gollama/gollama.log " ,
"sort_order" : " Size " ,
"strip_string" : " my-private-registry.internal/ " ,
"editor" : " " ,
"docker_container" : " "
}strip_string se puede usar para eliminar un prefijo de los nombres de modelos tal como se muestran en el TUI. Esto puede ser útil si tiene un prefijo común, como un registro privado que desea eliminar para fines de visualización.docker_container - experimental - si se establece, Gollama intentará realizar cualquier operación de ejecución dentro del contenedor especificado.editor - Experimental - Si se establece, Gollama usará este editor para abrir el ModelFile para la edición. Clon el repositorio:
git clone https://github.com/sammcj/gollama.git
cd gollamaConstruir:
go get
make buildCorrer:
./gollama Los registros se pueden encontrar en gollama.log que se almacena en $HOME/.config/gollama/gollama.log por defecto. El nivel de registro se puede configurar en el archivo de configuración.
¡Las contribuciones son bienvenidas! Hace el repositorio y cree una solicitud de extracción con sus cambios.
Sam | José Almaraz | José Roberto Almaraz | Oleksii filonenko | Suroeste | anrgct |
Gracias a personas como Matt Williams, Fahd Mirza y AI Code King por darle una oportunidad y proporcionar comentarios.
Copyright © 2024 Sam McLeod
Este proyecto tiene licencia bajo la licencia MIT. Consulte el archivo de licencia para obtener más detalles.
<script src = "http://api.html5media.info/1.1.8/html5media.min.js"> </script>

