gollama
v1.27.23

Gollama ist ein MacOS / Linux -Tool zum Verwalten von Ollama -Modellen.
Es bietet eine TUI (Text -Benutzeroberfläche) zum Auflisten, Inspektieren, Löschen, Kopieren und Schieben von Ollama -Modellen sowie optional mit LM Studio*.
Mit der Anwendung können Benutzer interaktiv Modelle auswählen, sortieren, filtern, bearbeiten, ausführen, ausführen, entladen und mithilfe von Hotkeys auf diese ausführen.
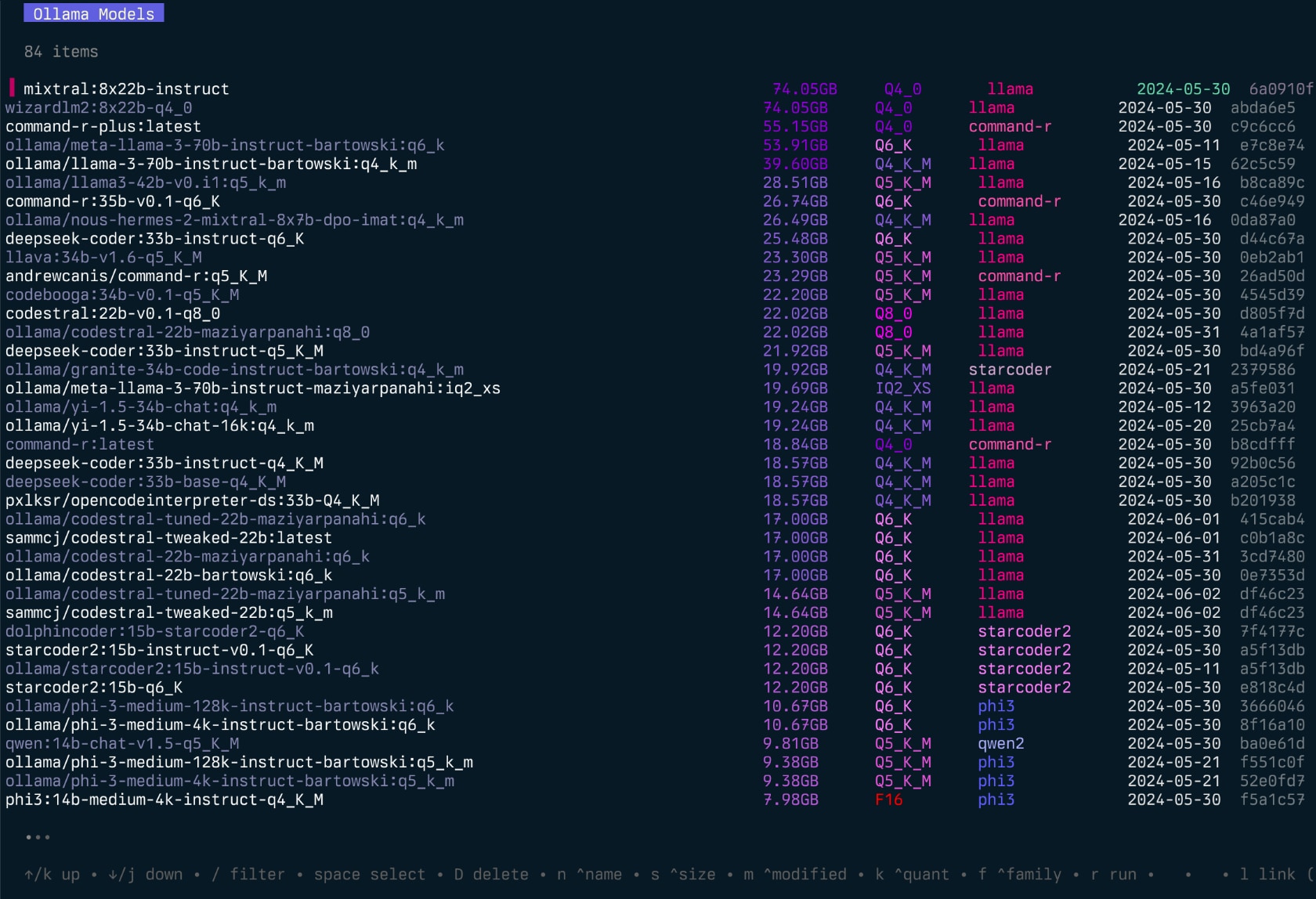
Das Projekt begann als Umschreiben meines Lamalink-Projekts, aber ich habe mich entschlossen, es so zu erweitern, dass es mehr Funktionen einbezieht und benutzerfreundlicher wird.
Es befindet sich in aktiver Entwicklung, daher gibt es einige Fehler und fehlende Funktionen, aber ich finde es nützlich, um meine Modelle jeden Tag zu verwalten, insbesondere für die Reinigung alter Modelle.
Siehe auch - Einnahme für die Übergabe von Verzeichnissen/Repos von Code in die für LLM formatierte Markdown -Formatierung.
Gollama Intro ("Podcast" -Episode):
go install github.com/sammcj/gollama@HEADIch empfehle diese Methode nicht, da sie nicht so einfach zu aktualisieren ist, aber Sie können den folgenden Befehl verwenden:
curl -sL https://raw.githubusercontent.com/sammcj/gollama/refs/heads/main/scripts/install.sh | bashLaden Sie die neueste Veröffentlichung von der Releases -Seite herunter und extrahieren Sie das Binärdatum in einem Verzeichnis auf Ihrem Weg.
zB zip -d gollama*.zip -d gollama && mv gollama /usr/local/bin
Verwenden Sie den folgenden Befehl, um die gollama -Anwendung auszuführen:
gollama Tipp : Ich mag es, Gollama zu g zu gilt, um einen schnellen Zugang zu erhalten:
echo " alias g=gollama " >> ~ /.zshrcSpace : SelectEnter : Run -Modell (Ollama Run)i : Modell inspizierent : Top (Running Models anzeigen)D : Modell löschene : Modell neu bearbeitenc : ModellkopierenU : Alle Modelle entladenp : Ziehen Sie ein vorhandenes Modell neug : Ziehen (Get) Neues Modell NeuP : Push -Modelln : sortieren nach Namens : Sortieren nach Größem : Sortieren nach modifiziertk : Sortieren durch Quantisierungf : Sortieren nach Familiel : Linkmodell mit LM StudioL : Verknüpfen Sie alle Modelle mit LM Studior : Modell umbenennen (in Arbeit)q : Kündigen Top ( t )
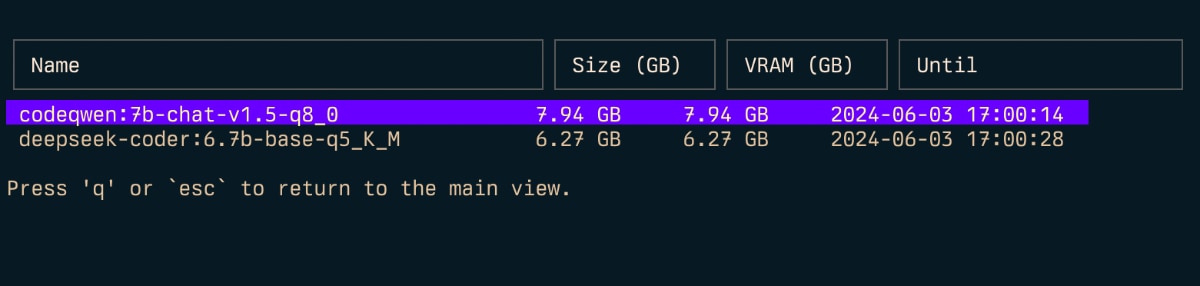
Inspizieren ( i )
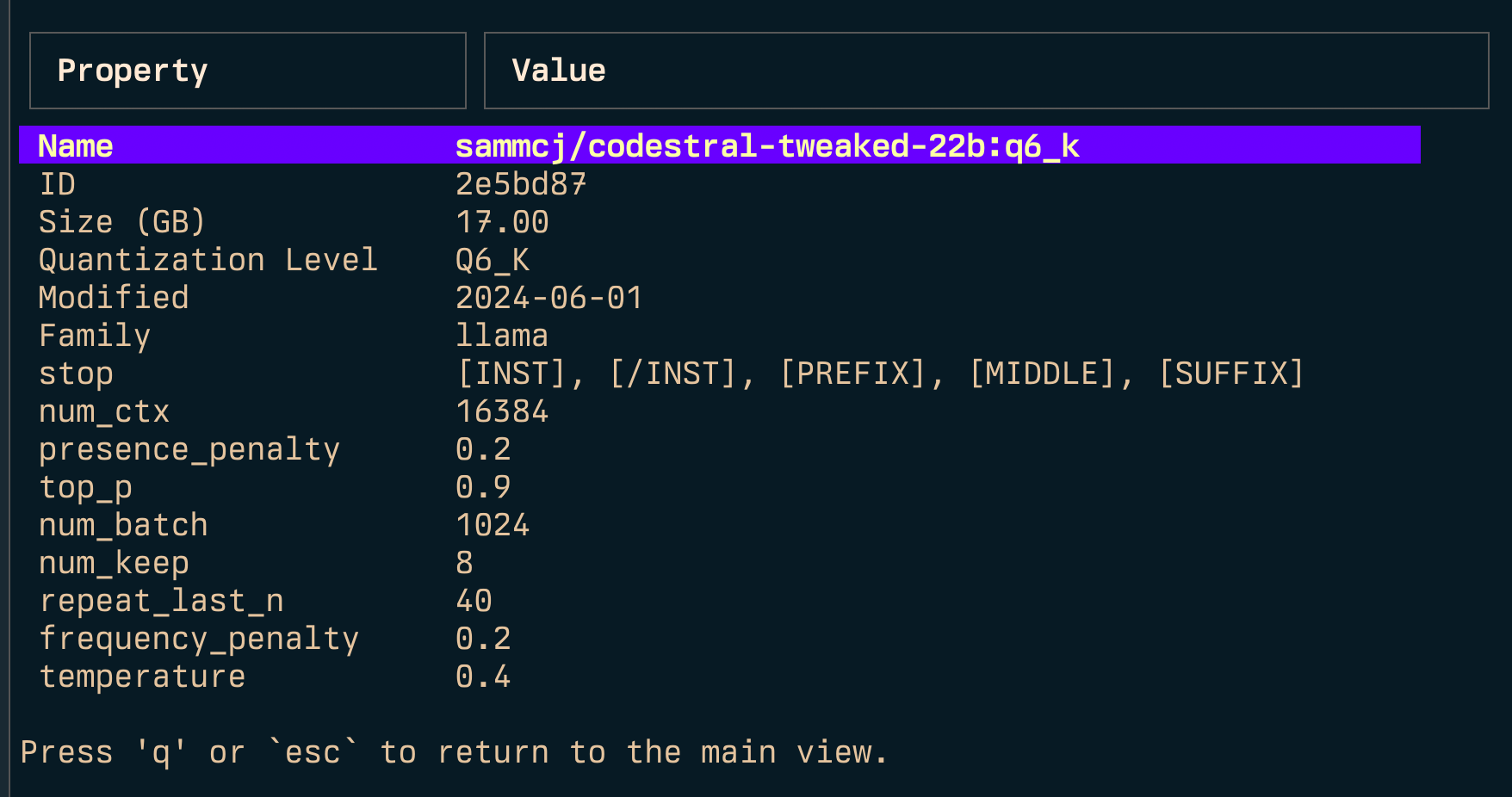
Link ( l ) und Link alle ( L )
Hinweis: Erfordert Administratorrechte, wenn Sie Windows ausführen.
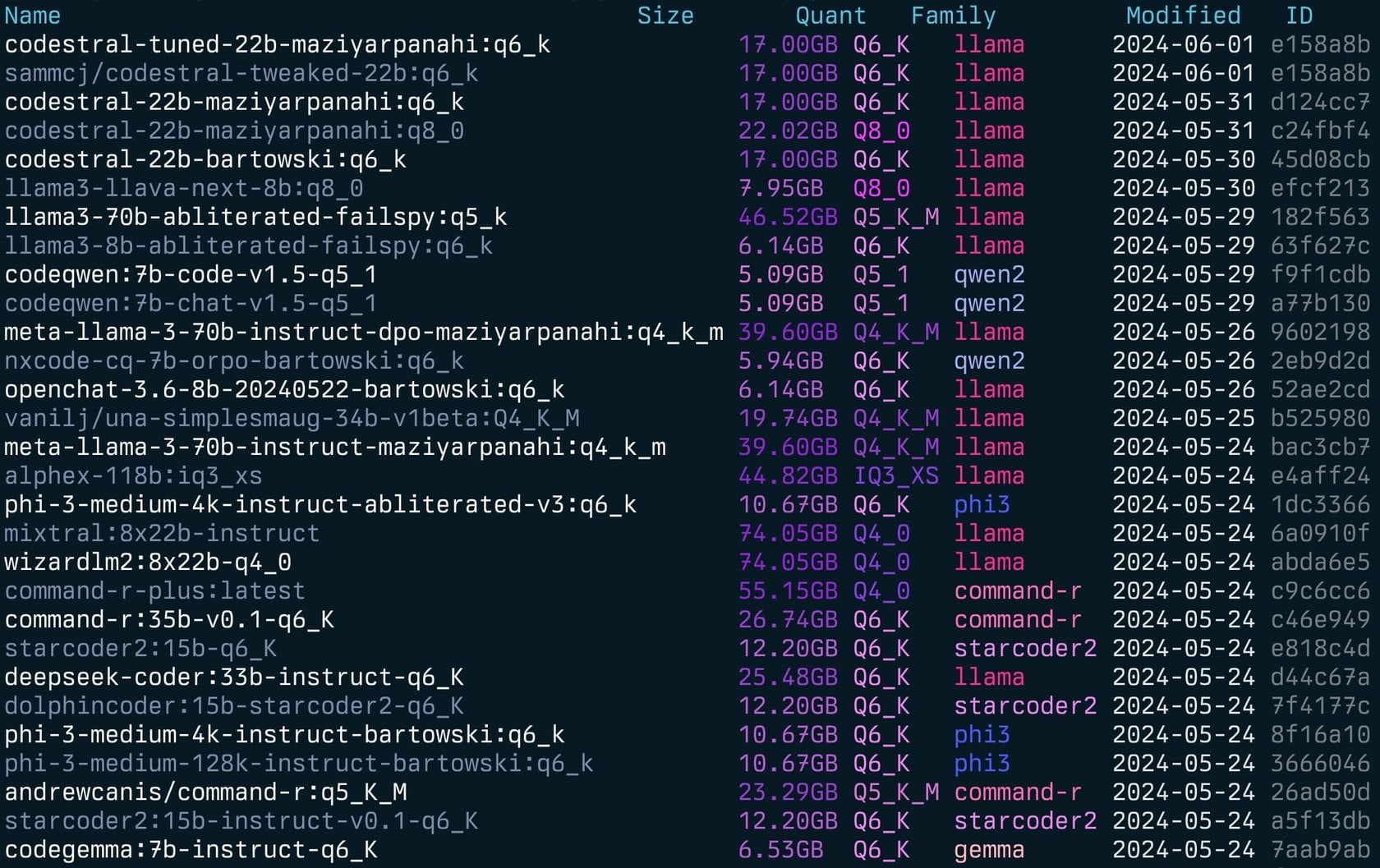
-l : Listen Sie alle verfügbaren Ollama -Modelle auf und beenden Sie-L : Verknüpfen Sie alle verfügbaren Ollama -Modelle mit LM Studio und Ausgang-s <search term> : Suchen Sie nach Modellen nach Namen'term1|term2' ) gibt Modelle zurück, die den beiden Begriffen entsprechen'term1&term2' ) gibt Modelle zurück, die beide Begriffe entsprechen-e <model> : Bearbeiten Sie das Modelfile für ein Modell-ollama-dir : Custom Ollama Models Directory-lm-dir : Custom LM Studio Models Verzeichnis-cleanup : Entfernen Sie alle symlinierten Modelle und leeren Verzeichnisse und beenden Sie-no-cleanup : Nicht aufgebrochene Symlinks aufräumen-u : Entladen Sie alle laufenden Modelle-v : Drucken Sie die Version und beenden Sie aus-h oder --host : Geben Sie den Host für die Ollama -API an-H : Verknüpfung für -h http://localhost:11434 (Verbindung zu lokaler Ollama -API) Neu--vram : Schätzen Sie die VRAM-Verwendung für ein Modell. Akzeptiert:qwen2:14b-q4_0 z llama3.1:8b-instruct-q6_KNousResearch/Hermes-2-Theta-Llama-3-8B--fits : Verfügbarer Speicher in GB für die Kontextberechnung (z. B. 6 für 6 GB)--vram-to-nth oder --context : Maximale Kontextlänge zu analysieren (z. B. 32k oder 128k )--quant : Überschreibung der Quantisierung (z. B. Q4_0 , Q5_K_M ) Gollama kann auch mit -l aufgerufen werden, um Modelle ohne TUI aufzulisten.
gollama -l Liste ( gollama -l ):
Gollama kann mit -e aufgerufen werden, um das Modelfile für ein Modell zu bearbeiten.
gollama -e my-model Gollama kann mit -s aufgerufen werden, um nach Models nach Namen zu suchen.
gollama -s my-model # returns models that contain 'my-model'
gollama -s ' my-model|my-other-model ' # returns models that contain either 'my-model' or 'my-other-model'
gollama -s ' my-model&instruct ' # returns models that contain both 'my-model' and 'instruct' Gollama enthält eine umfassende VRAM -Schätzfunktion:
my-model:mytag ) oder Huggingface-Modell-ID (z. B. author/name )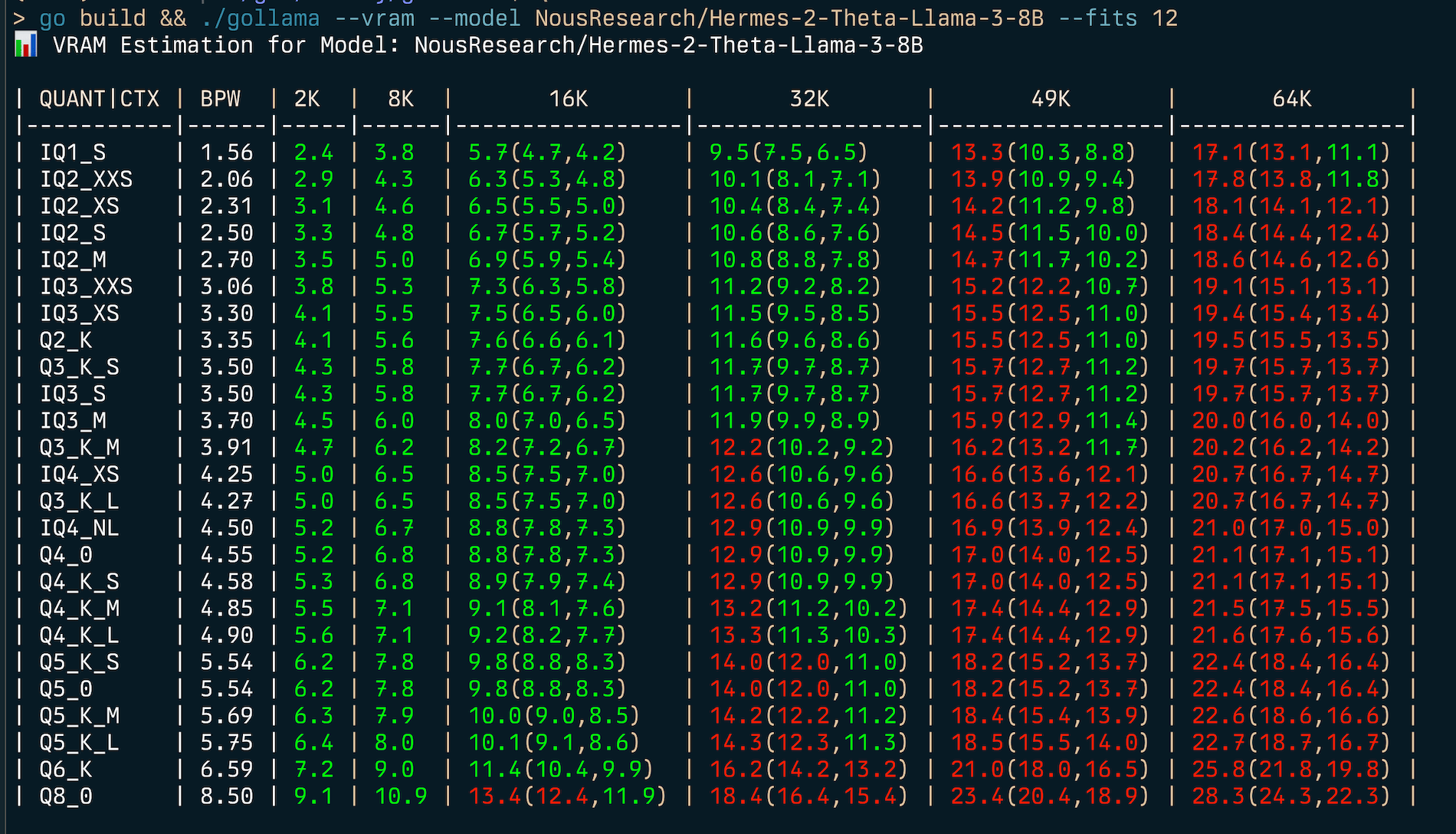
Schätzen Sie (v) RAM -Nutzung:
gollama --vram llama3.1:8b-instruct-q6_K
VRAM Estimation for Model: llama3.1:8b-instruct-q6_K
| QUANT | CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| ------- | ---- | --- | --- | --------------- | --------------- | --------------- | --------------- |
| IQ1_S | 1.56 | 2.2 | 2.8 | 3.7(3.7,3.7) | 5.5(5.5,5.5) | 7.3(7.3,7.3) | 9.1(9.1,9.1) |
| IQ2_XXS | 2.06 | 2.6 | 3.3 | 4.3(4.3,4.3) | 6.1(6.1,6.1) | 7.9(7.9,7.9) | 9.8(9.8,9.8) |
| IQ2_XS | 2.31 | 2.9 | 3.6 | 4.5(4.5,4.5) | 6.4(6.4,6.4) | 8.2(8.2,8.2) | 10.1(10.1,10.1) |
| IQ2_S | 2.50 | 3.1 | 3.8 | 4.7(4.7,4.7) | 6.6(6.6,6.6) | 8.5(8.5,8.5) | 10.4(10.4,10.4) |
| IQ2_M | 2.70 | 3.2 | 4.0 | 4.9(4.9,4.9) | 6.8(6.8,6.8) | 8.7(8.7,8.7) | 10.6(10.6,10.6) |
| IQ3_XXS | 3.06 | 3.6 | 4.3 | 5.3(5.3,5.3) | 7.2(7.2,7.2) | 9.2(9.2,9.2) | 11.1(11.1,11.1) |
| IQ3_XS | 3.30 | 3.8 | 4.5 | 5.5(5.5,5.5) | 7.5(7.5,7.5) | 9.5(9.5,9.5) | 11.4(11.4,11.4) |
| Q2_K | 3.35 | 3.9 | 4.6 | 5.6(5.6,5.6) | 7.6(7.6,7.6) | 9.5(9.5,9.5) | 11.5(11.5,11.5) |
| Q3_K_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_M | 3.70 | 4.2 | 5.0 | 6.0(6.0,6.0) | 8.0(8.0,8.0) | 9.9(9.9,9.9) | 12.0(12.0,12.0) |
| Q3_K_M | 3.91 | 4.4 | 5.2 | 6.2(6.2,6.2) | 8.2(8.2,8.2) | 10.2(10.2,10.2) | 12.2(12.2,12.2) |
| IQ4_XS | 4.25 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.6(10.6,10.6) | 12.7(12.7,12.7) |
| Q3_K_L | 4.27 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.7(10.7,10.7) | 12.7(12.7,12.7) |
| IQ4_NL | 4.50 | 5.0 | 5.7 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 10.9(10.9,10.9) | 13.0(13.0,13.0) |
| Q4_0 | 4.55 | 5.0 | 5.8 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_S | 4.58 | 5.0 | 5.8 | 6.9(6.9,6.9) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_M | 4.85 | 5.3 | 6.1 | 7.1(7.1,7.1) | 9.2(9.2,9.2) | 11.4(11.4,11.4) | 13.5(13.5,13.5) |
| Q4_K_L | 4.90 | 5.3 | 6.1 | 7.2(7.2,7.2) | 9.3(9.3,9.3) | 11.4(11.4,11.4) | 13.6(13.6,13.6) |
| Q5_K_S | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_0 | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_K_M | 5.69 | 6.1 | 6.9 | 8.0(8.0,8.0) | 10.2(10.2,10.2) | 12.4(12.4,12.4) | 14.6(14.6,14.6) |
| Q5_K_L | 5.75 | 6.1 | 7.0 | 8.1(8.1,8.1) | 10.3(10.3,10.3) | 12.5(12.5,12.5) | 14.7(14.7,14.7) |
| Q6_K | 6.59 | 7.0 | 8.0 | 9.4(9.4,9.4) | 12.2(12.2,12.2) | 15.0(15.0,15.0) | 17.8(17.8,17.8) |
| Q8_0 | 8.50 | 8.8 | 9.9 | 11.4(11.4,11.4) | 14.4(14.4,14.4) | 17.4(17.4,17.4) | 20.3(20.3,20.3) | Um den besten Quantisierungstyp für eine bestimmte Speicherbeschränkung (z. B. 6 GB) zu finden, können Sie --fits <number of GB> angeben:
gollama --vram NousResearch/Hermes-2-Theta-Llama-3-8B --fits 6
VRAM Estimation for Model: NousResearch/Hermes-2-Theta-Llama-3-8B
| QUANT/CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| --------- | ---- | --- | --- | ------------ | ------------- | -------------- | --------------- |
| IQ1_S | 1.56 | 2.4 | 3.8 | 5.7(4.7,4.2) | 9.5(7.5,6.5) | 13.3(10.3,8.8) | 17.1(13.1,11.1) |
| IQ2_XXS | 2.06 | 2.9 | 4.3 | 6.3(5.3,4.8) | 10.1(8.1,7.1) | 13.9(10.9,9.4) | 17.8(13.8,11.8) |
...Dadurch wird eine Tabelle angezeigt, die die VRAM -Verwendung für verschiedene Quantisierungstypen und Kontextgrößen zeigt.
Der VRAM -Schätzer funktioniert von:
HINWEIS: Der Schätzer versucht, CUDA VRAM zu verwenden, falls verfügbar, andernfalls fällt er für Berechnungen auf den System -RAM zurück.
Gollama verwendet eine JSON -Konfigurationsdatei unter ~/.config/gollama/config.json . Die Konfigurationsdatei enthält Optionen zum Sortieren, Spalten, API -Schlüssel, Protokollebenen usw.
Beispielkonfiguration:
{
"default_sort" : " modified " ,
"columns" : [
" Name " ,
" Size " ,
" Quant " ,
" Family " ,
" Modified " ,
" ID "
],
"ollama_api_key" : " " ,
"ollama_api_url" : " http://localhost:11434 " ,
"lm_studio_file_paths" : " " ,
"log_level" : " info " ,
"log_file_path" : " /Users/username/.config/gollama/gollama.log " ,
"sort_order" : " Size " ,
"strip_string" : " my-private-registry.internal/ " ,
"editor" : " " ,
"docker_container" : " "
}strip_string können ein Präfix aus Modellnamen entfernt werden, wie sie in der TUI angezeigt werden. Dies kann nützlich sein, wenn Sie ein gemeinsames Präfix haben, z. B. eine private Registrierung, die Sie für Anzeigezwecke entfernen möchten.docker_container - Experimental - Wenn Gollama festgelegt wird, versucht Gollama, Run -Operationen im angegebenen Container auszuführen.editor - Experimental - Wenn festgelegt wird, wird Gollama diesen Editor verwenden, um das Modelfile für die Bearbeitung zu öffnen. Klonen Sie das Repository:
git clone https://github.com/sammcj/gollama.git
cd gollamaBauen:
go get
make buildLaufen:
./gollama Protokolle finden Sie im gollama.log , das standardmäßig in $HOME/.config/gollama/gollama.log gespeichert ist. Die Protokollebene kann in der Konfigurationsdatei eingestellt werden.
Beiträge sind willkommen! Bitte geben Sie das Repository aus und erstellen Sie eine Pull -Anfrage mit Ihren Änderungen.
Sam | Jose Almaraz | Jose Roberto Almaraz | Olekii Filonenko | Südwolf | anrgct |
Vielen Dank an Leute wie Matt Williams, Fahd Mirza und AI Code King, dass sie dies einen Schuss gegeben und Feedback gegeben haben.
Copyright © 2024 Sam McLeod
Dieses Projekt ist unter der MIT -Lizenz lizenziert. Weitere Informationen finden Sie in der Lizenzdatei.
<script src = "http://api.html5media.info/1.1.8/html5media.min.js"> </script>

