Jlama
v0.8.3

모델 지원 :
구현 :
JLAMA는 Java 20 이상이 필요하며 새로운 벡터 API를 사용하여 더 빠른 추론을합니다.
Java 응용 프로그램에 LLM 추론을 직접 추가하십시오.
JLAMA에는 사용하기 쉬운 명령 줄 도구가 포함되어 있습니다.
CLI는 jbang으로 실행할 수 있습니다.
# Install jbang (or https://www.jbang.dev/download/)
curl -Ls https://sh.jbang.dev | bash -s - app setup
# Install Jlama CLI (will ask if you trust the source)
jbang app install --force jlama@tjakeJlama가 설치되었으므로 Huggingface에서 모델을 다운로드하여 채팅 할 수 있습니다. 참고 https://hf.co/tjake에서 사용할 수있는 사전 정량화 된 모델이 있습니다
# Run the openai chat api and UI on a model
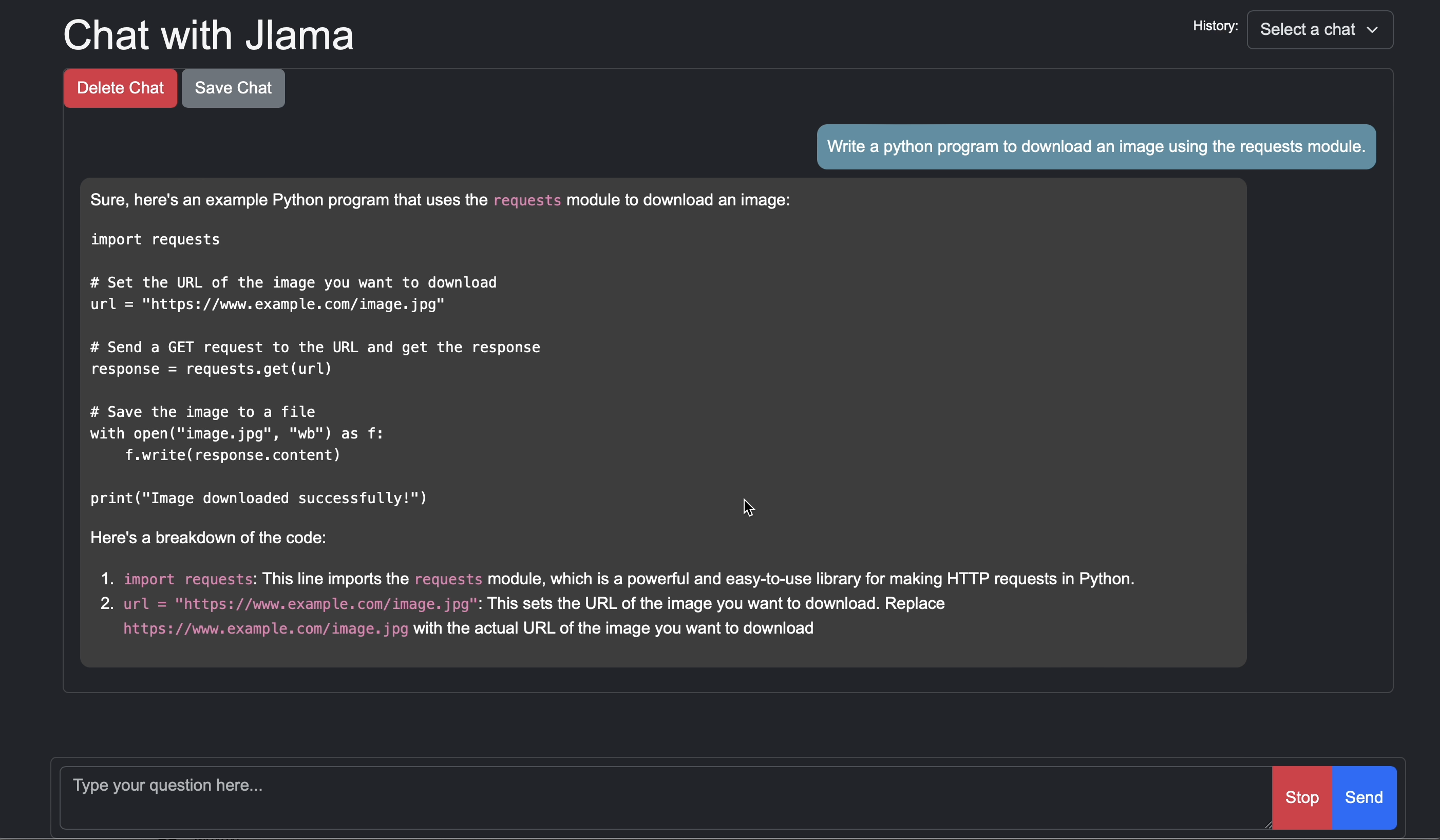
jlama restapi tjake/Llama-3.2-1B-Instruct-JQ4 --auto-downloadhttp : // localhost : 8080/에 브라우저 오픈
Usage:
jlama [COMMAND]
Description:
Jlama is a modern LLM inference engine for Java !
Quantized models are maintained at https://hf.co/tjake
Choose from the available commands:
Inference:
chat Interact with the specified model
restapi Starts a openai compatible rest api for interacting with this model
complete Completes a prompt using the specified model
Distributed Inference:
cluster-coordinator Starts a distributed rest api for a model using cluster workers
cluster-worker Connects to a cluster coordinator to perform distributed inference
Other:
download Downloads a HuggingFace model - use owner/name format
list Lists local models
quantize Quantize the specified modelJLAMA의 주요 목적은 Java에서 큰 언어 모델을 사용하는 간단한 방법을 제공하는 것입니다.
앱에 JLAMA를 포함시키는 가장 간단한 방법은 Langchain4J 통합입니다.
Langchain4J없이 JLAMA를 포함시키려면 다음 Maven 의존성을 프로젝트에 추가하십시오.
< dependency >
< groupId >com.github.tjake</ groupId >
< artifactId >jlama-core</ artifactId >
< version >${jlama.version}</ version >
</ dependency >
< dependency >
< groupId >com.github.tjake</ groupId >
< artifactId >jlama-native</ artifactId >
<!-- supports linux-x86_64, macos-x86_64/aarch_64, windows-x86_64
Use https://github.com/trustin/os-maven-plugin to detect os and arch -->
< classifier >${os.detected.name}-${os.detected.arch}</ classifier >
< version >${jlama.version}</ version >
</ dependency >
JLAMA는 Java 21 미리보기 기능을 사용합니다. 전 세계적으로 기능을 활성화 할 수 있습니다.
export JDK_JAVA_OPTIONS= " --add-modules jdk.incubator.vector --enable-preview "또는 Maven Compiler 및 FailSafe 플러그인을 구성하여 미리보기 기능을 활성화하십시오.
그런 다음 모델 클래스를 사용하여 모델을 실행할 수 있습니다.
public void sample () throws IOException {
String model = "tjake/Llama-3.2-1B-Instruct-JQ4" ;
String workingDirectory = "./models" ;
String prompt = "What is the best season to plant avocados?" ;
// Downloads the model or just returns the local path if it's already downloaded
File localModelPath = new Downloader ( workingDirectory , model ). huggingFaceModel ();
// Loads the quantized model and specified use of quantized memory
AbstractModel m = ModelSupport . loadModel ( localModelPath , DType . F32 , DType . I8 );
PromptContext ctx ;
// Checks if the model supports chat prompting and adds prompt in the expected format for this model
if ( m . promptSupport (). isPresent ()) {
ctx = m . promptSupport ()
. get ()
. builder ()
. addSystemMessage ( "You are a helpful chatbot who writes short responses." )
. addUserMessage ( prompt )
. build ();
} else {
ctx = PromptContext . of ( prompt );
}
System . out . println ( "Prompt: " + ctx . getPrompt () + " n " );
// Generates a response to the prompt and prints it
// The api allows for streaming or non-streaming responses
// The response is generated with a temperature of 0.7 and a max token length of 256
Generator . Response r = m . generate ( UUID . randomUUID (), ctx , 0.0f , 256 , ( s , f ) -> {});
System . out . println ( r . responseText );
}이 프로젝트를 좋아하거나 사용하여 직접 구축하는 경우 스타를 알려주십시오. 지원을 보여주는 무료 방법입니다.
이 코드는 Apache 라이센스에 따라 사용할 수 있습니다.
이 프로젝트가 연구에 도움이된다면이 작업을 인용하십시오.
@misc{jlama2024,
title = {Jlama: A modern Java inference engine for large language models},
url = {https://github.com/tjake/jlama},
author = {T Jake Luciani},
month = {January},
year = {2024}
}


