Jlama
v0.8.3

Soporte del modelo:
Implementos:
JLama requiere Java 20 o posterior y utiliza la nueva API de vector para una inferencia más rápida.
Agregue la inferencia LLM directamente a su aplicación Java.
JLama incluye una herramienta de línea de comandos que facilita el uso.
El CLI se puede ejecutar con JBang.
# Install jbang (or https://www.jbang.dev/download/)
curl -Ls https://sh.jbang.dev | bash -s - app setup
# Install Jlama CLI (will ask if you trust the source)
jbang app install --force jlama@tjakeAhora que tiene instalado JLama, puede descargar un modelo de Huggingface y chatear con él. Tenga en cuenta que tengo modelos pre-cantizados disponibles en https://hf.co/tjake
# Run the openai chat api and UI on a model
jlama restapi tjake/Llama-3.2-1B-Instruct-JQ4 --auto-downloadAbra el navegador a http: // localhost: 8080/
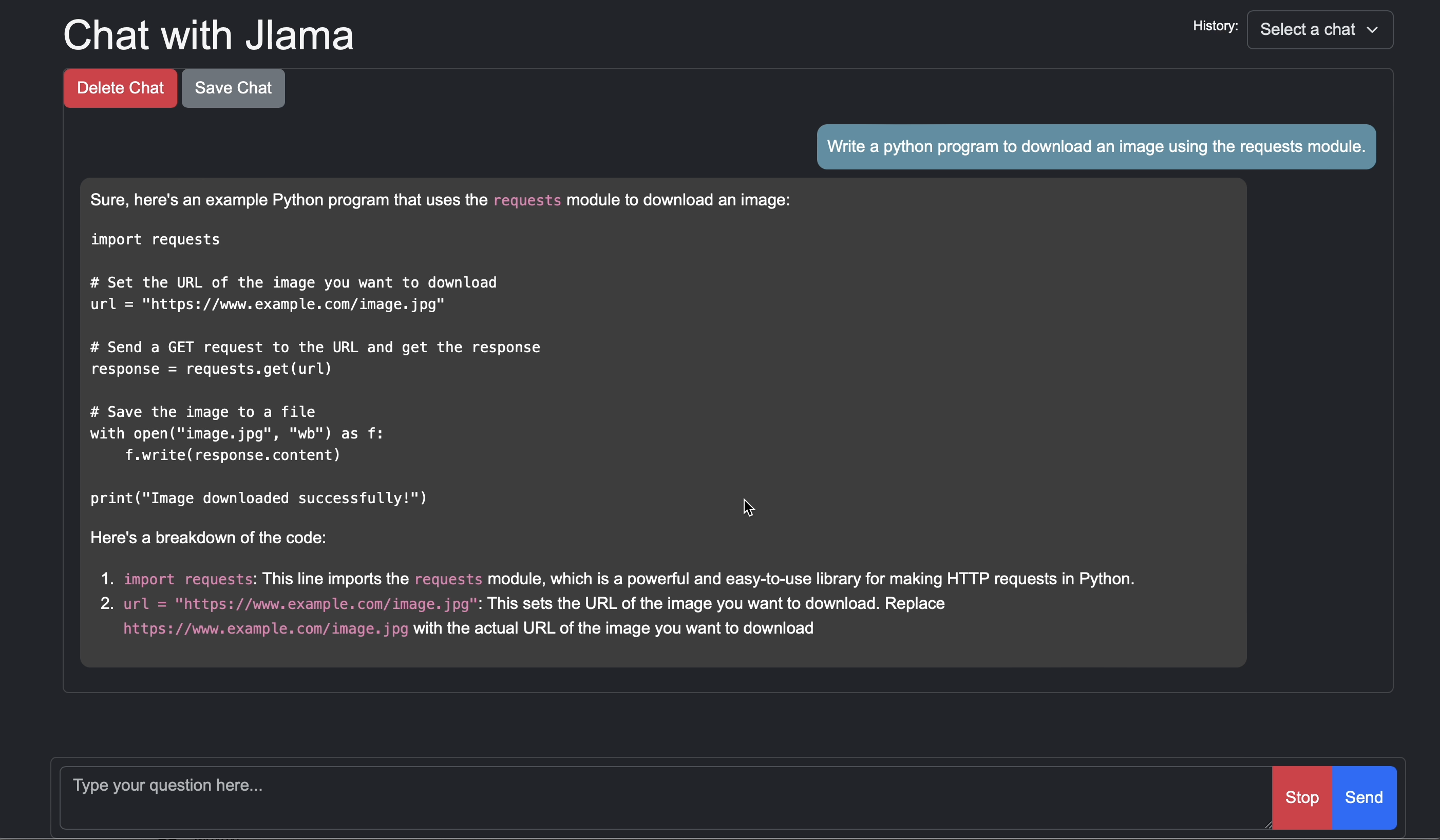
Usage:
jlama [COMMAND]
Description:
Jlama is a modern LLM inference engine for Java !
Quantized models are maintained at https://hf.co/tjake
Choose from the available commands:
Inference:
chat Interact with the specified model
restapi Starts a openai compatible rest api for interacting with this model
complete Completes a prompt using the specified model
Distributed Inference:
cluster-coordinator Starts a distributed rest api for a model using cluster workers
cluster-worker Connects to a cluster coordinator to perform distributed inference
Other:
download Downloads a HuggingFace model - use owner/name format
list Lists local models
quantize Quantize the specified modelEl objetivo principal de JLama es proporcionar una forma simple de usar modelos de idiomas grandes en Java.
La forma más sencilla de incrustar a Jlama en su aplicación es con la integración Langchain4j.
Si desea incrustar a JLama sin LangChain4J, agregue las siguientes dependencias de Maven a su proyecto:
< dependency >
< groupId >com.github.tjake</ groupId >
< artifactId >jlama-core</ artifactId >
< version >${jlama.version}</ version >
</ dependency >
< dependency >
< groupId >com.github.tjake</ groupId >
< artifactId >jlama-native</ artifactId >
<!-- supports linux-x86_64, macos-x86_64/aarch_64, windows-x86_64
Use https://github.com/trustin/os-maven-plugin to detect os and arch -->
< classifier >${os.detected.name}-${os.detected.arch}</ classifier >
< version >${jlama.version}</ version >
</ dependency >
JLama utiliza funciones de vista previa de Java 21. Puede habilitar las características a nivel mundial con:
export JDK_JAVA_OPTIONS= " --add-modules jdk.incubator.vector --enable-preview "o habilite las funciones de vista previa configurando los complementos del compilador Maven y FailsSafe.
Luego puede usar las clases de modelos para ejecutar modelos:
public void sample () throws IOException {
String model = "tjake/Llama-3.2-1B-Instruct-JQ4" ;
String workingDirectory = "./models" ;
String prompt = "What is the best season to plant avocados?" ;
// Downloads the model or just returns the local path if it's already downloaded
File localModelPath = new Downloader ( workingDirectory , model ). huggingFaceModel ();
// Loads the quantized model and specified use of quantized memory
AbstractModel m = ModelSupport . loadModel ( localModelPath , DType . F32 , DType . I8 );
PromptContext ctx ;
// Checks if the model supports chat prompting and adds prompt in the expected format for this model
if ( m . promptSupport (). isPresent ()) {
ctx = m . promptSupport ()
. get ()
. builder ()
. addSystemMessage ( "You are a helpful chatbot who writes short responses." )
. addUserMessage ( prompt )
. build ();
} else {
ctx = PromptContext . of ( prompt );
}
System . out . println ( "Prompt: " + ctx . getPrompt () + " n " );
// Generates a response to the prompt and prints it
// The api allows for streaming or non-streaming responses
// The response is generated with a temperature of 0.7 and a max token length of 256
Generator . Response r = m . generate ( UUID . randomUUID (), ctx , 0.0f , 256 , ( s , f ) -> {});
System . out . println ( r . responseText );
}Si desea o está utilizando este proyecto para construir el suyo, danos una estrella. Es una forma gratuita de mostrar su apoyo.
El código está disponible bajo la licencia Apache.
Si encuentra útil este proyecto en su investigación, cite este trabajo en
@misc{jlama2024,
title = {Jlama: A modern Java inference engine for large language models},
url = {https://github.com/tjake/jlama},
author = {T Jake Luciani},
month = {January},
year = {2024}
}


